参考资料:活用pandas库
逻辑回归
当响应变量为二值响应变量时,经常使用逻辑回归对数据建模。
# 导入pandas库
import pandas as pd
# 导入数据集
acs=pd.read_csv(r"...\data\acs_ny.csv")
# 展示数据列
print(acs.columns)
# 展示数据集
print(acs.head())
acs['ge150k']=pd.cut(acs['FamilyIncome'],
[0,150000,acs['FamilyIncome'].max()],labels=[0,1])
acs['ge150k_i']=acs['ge150k'].astype(int)
print(acs['ge150k_i'].value_counts())
print(acs.info())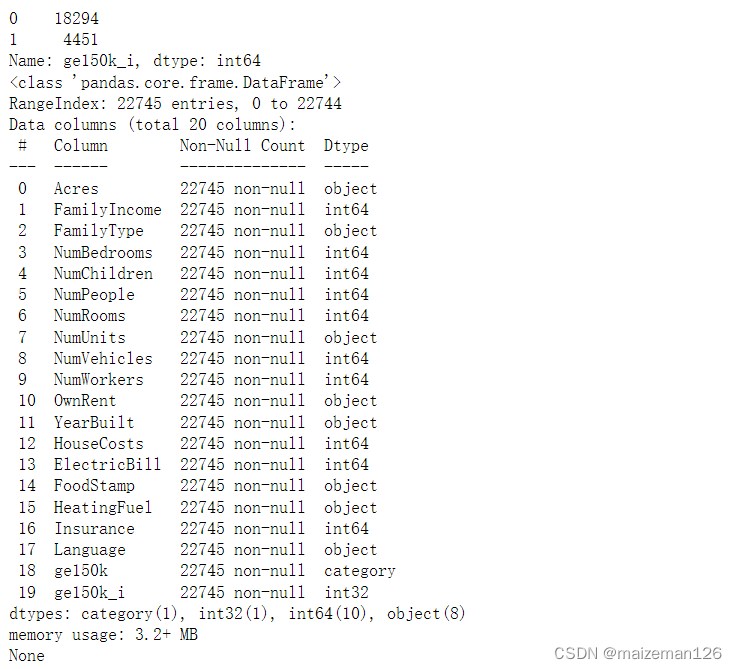
(1)使用statsmodels
可以使用logit函数执行逻辑回归。解释逻辑回归的结果并不像解释线性回归那样简单。在逻辑回归中,与所有广义线性模型一样,都需要使用连接函数执行一定的转换,而解释结果时需要回到转换之前的状态。
# 导入formula.api模块
import statsmodels.formula.api as smf
# 逻辑回归拟合
model=smf.logit("ge150k_i~HouseCosts+ NumWorkers+ "\
"OwnRent+ NumBedrooms+ FamilyType"
,data=acs)
results=model.fit()
print(results.summary())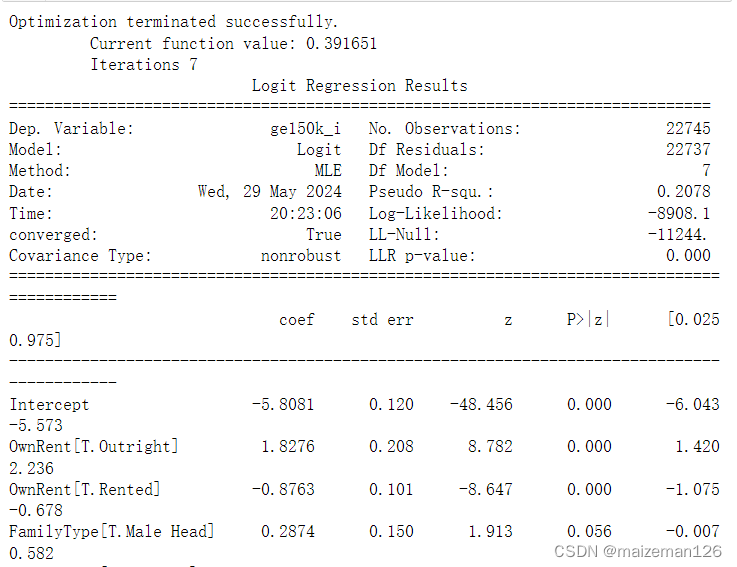
# 导入numpy库
import numpy as np
# 为了解释逻辑模型,首先需要把结果指数化
odds_ratios=np.exp(results.params)
print(odds_ratios)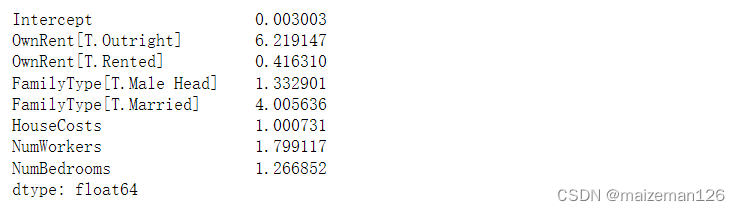
对于这些数字的解释:NumBedrooms每增加一个单元,FamilyIncome超过150000的概率就会增加1.27倍。也可以如此解释分类变量。
(2)使用sklearn
使用sklearn时,需要手动创建虚拟变量。
# 用get_dummies函数对分类变量创建虚拟变量
predictors=pd.get_dummies(
acs[['HouseCosts','NumWorkers','OwnRent','NumBedrooms','FamilyType']],
drop_first=True)
# 导入linear_model模块
from sklearn import linear_model
# 逻辑回归拟合
lm=linear_model.LogisticRegression()
results=lm.fit(X=predictors,y=acs['ge150k_i'])
# 查看系数
print(results.coef_)
print(results.intercept_)
# 调整系数的输出格式
values=np.append(results.intercept_,results.coef_)
names=np.append("intercept",predictors.columns)
results=pd.DataFrame(values,index=names,columns=['coef'])
print(results)
# 为了解释系数,还需要把值指数化
results['or']=np.exp(results['coef'])
print(results)