图机器学习-节点嵌入(Node Embedding)
Node Embedding简单点来说就是将一个node表示为一个 R d R^d Rd的向量。
Encoder+Decoder Framework
我们首先需要设计一个encoder对节点进行编码。既然要比较相似度那么我就需要定义节点的相似度。同时我们还需要定义一个decoder,它是一个从embedding space到相似度得分的映射。最后我们需要优化encoder的参数,使得nodes在embedding space的相似度和在原始图中的相似度尽量相近。
最简单的encoder是一个embedding-lookup

我们可以观察embedding matrix的结构,它的维度为(节点的维度,节点的个数)。
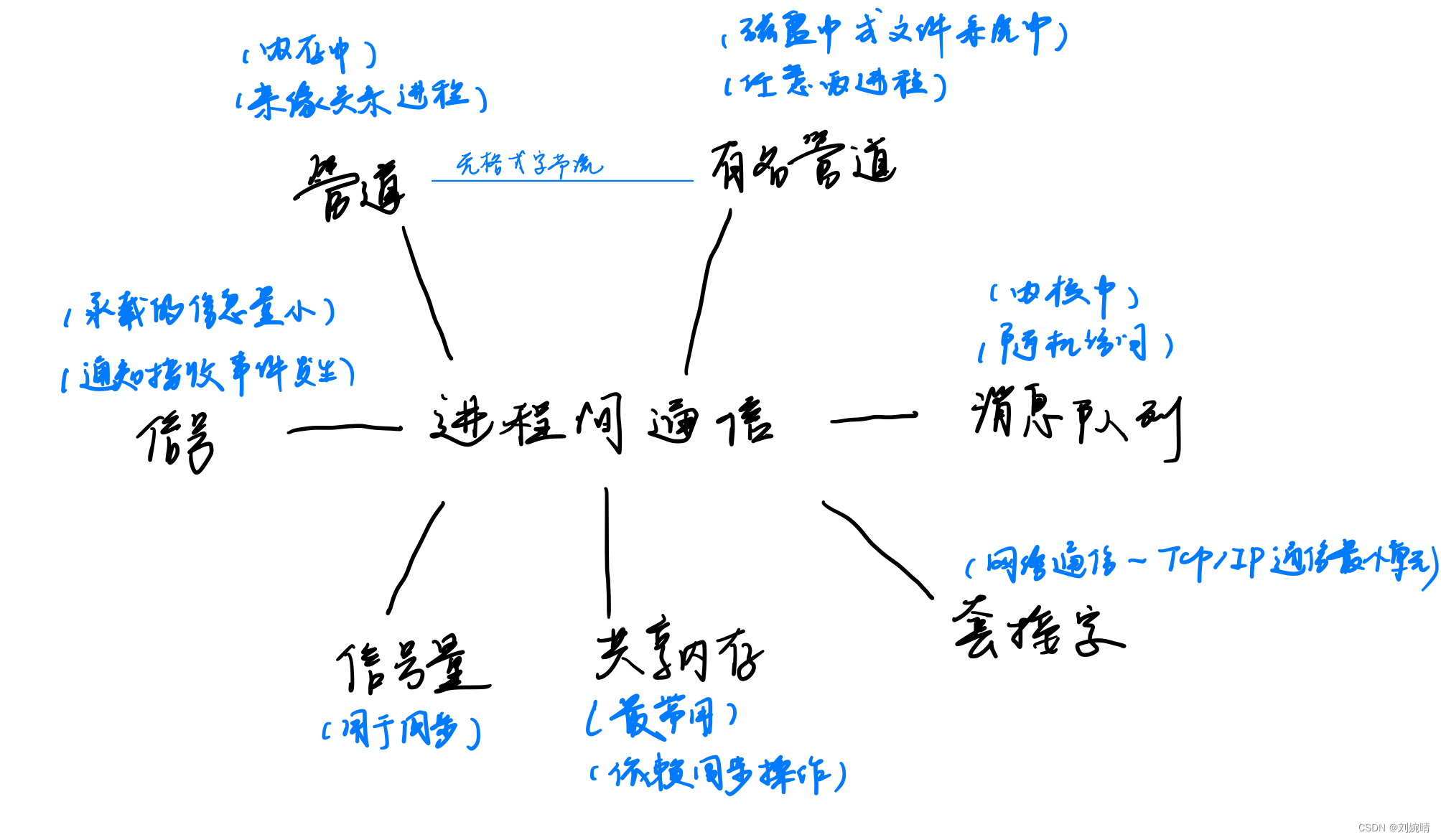
随机游走
如何定义节点的相似度是一个核心的问题。我们可以使用随机游走来帮助我们定义节点相似度。

随机游走,这个方法正如其名。假设我们有一个图和一个初始的节点,这个节点上有一个人,我们随机选择一个当前节点的邻居然后将人移动到我们选择的邻居节点然后我们继续从人所在节点的邻居节点随机选择一个,一直持续上述的动作。我们把经过的节点定义为random walk on the graph。(需要注意的是我们可以使用不同的随机游走策略)
假设我们使用了随机游走这个方法我们定义两个节点的相似度为两个节点出现在一个random walk on the graph的概率。
我们定义 N R ( u ) N_R(u) NR(u)为neighbourhood of 𝑢 obtained by some random walk strategy R
我们的目标是学习到一个映射
f
(
u
)
=
z
u
f(u)=\mathbf{z}_u
f(u)=zu,将一个节点映射到一个d维的向量空间。我们要求解如下的优化问题。
max
f
∑
u
∈
V
log
P
(
N
R
(
u
)
∣
z
u
)
\max _{f} \sum_{u \in V} \log \mathrm{P}\left(N_{\mathrm{R}}(u) \mid \mathbf{z}_{u}\right)
fmaxu∈V∑logP(NR(u)∣zu)
即我们希望在我们encoding一个节点之后,这个节点到达
N
R
(
u
)
N_R(u)
NR(u)的概率最大。
那么我们应该怎么优化呢?
首先我们需要使用某种随机游走策略进行短的定长的随机游走,对于每一个节点收集
N
R
(
u
)
N_R(u)
NR(u)。最大化上面这个问题等同于最小化
L
=
∑
u
∈
V
∑
v
∈
N
R
(
u
)
−
log
(
P
(
v
∣
z
u
)
)
\mathcal{L}=\sum_{u \in V} \sum_{v \in N_{R}(u)}-\log \left(P\left(v \mid \mathbf{z}_{u}\right)\right)
L=u∈V∑v∈NR(u)∑−log(P(v∣zu))
其中
P
(
v
∣
z
u
)
=
exp
(
z
u
T
z
v
)
∑
n
∈
V
exp
(
z
u
T
z
n
)
P\left(v \mid \mathbf{z}_{u}\right)=\frac{\exp \left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{v}\right)}{\sum_{n \in V} \exp \left(\mathbf{z}_{u}^{\mathrm{T}} \mathbf{z}_{n}\right)}
P(v∣zu)=∑n∈Vexp(zuTzn)exp(zuTzv)

但是在实际的计算中这样计算复杂度过高,我们可以使用negative sampling来做计算加速。

其中 n i n_i ni为negative samples。理论上来说 n i n_i ni应该选取为不在节点u的随机游走序列里面的节点,但实际中人们往往使用图中的任意节点。
当我们有了目标函数之后相当于需要求解一个无约束优化问题,所以我们可以使用随机梯度下降等一些优化方法对目标函数进行优化。
那我们可以有哪些随机游走的策略呢?
deep walk
只需要从每个节点开始进行固定长度、无偏倚的随机行走。
node2vec
这个方法希望使用灵活的、有偏差的随机行走,使得其可以在网络的局部和全局视图之间进行权衡。
我们可以使用广度优先搜索(BFS)和深度优先搜索(DFS)两个策略来定义节点的邻居 N R ( u ) N_R(u) NR(u)。node2vec方法中有两个参数需要调节
- returnparameter p:control probobility return back to the previous node
- in-out parameter q:Intuitively, 𝑞 is the “ratio” of BFS vs. DFS

假设有一个人上一步是从S1走到W,那么下一步走到各个节点的概率(没有归一化)如图所示。
对图做embedding
方法一:将(子)图上包含的节点的node embedding相加作为图的embedding
方法二:提出一个虚拟节点来表示子图,接着对这个虚拟节点做embedding
方法三:Anonymous Walk Embeddings, ICML 2018 https://arxiv.org/pdf/1805.11921.pdf
在方法三种Anonymous Walk中的状态为我们在随机行走中第一次访问该节点的索引

以这张图片为例子,random walk1和random walk2都是相同的anonymous walk。
我们可以先设定一个随机游走的长度l,比如设定l=3,此时只有5种可能,分别为:111, 112, 121, 122, 123。我们可以将图表示为一个5维的向量 z G \mathbf{z}_G zG。 z G \mathbf{z}_G zG表示出现anonymous walk w i w_i wi的概率
我们需要的随机游走数量可以由下面这个公式算出( η \eta η为随机游走长度为l时的可能总数)
We want the distribution to have error of more than 𝜀 with prob. less than 𝛿:
m
=
⌈
2
ε
2
(
log
(
2
η
−
2
)
−
log
(
δ
)
)
∣
m=\left\lceil\frac{2}{\varepsilon^{2}}\left(\log \left(2^{\eta}-2\right)-\log (\delta)\right) \mid\right.
m=⌈ε22(log(2η−2)−log(δ))∣
Reference:
1:Stanford CS224W
2:b站up主同济子豪兄








![[Linux]进程地址空间](https://img-blog.csdnimg.cn/980719c3338f4eea8c90e2219186019e.png)