一、MySQL主从复制
MySQL数据库默认是支持主从复制的,不需要借助于其他的技术,我们只需要在数据库中简单的配置即可。
1. MySQL主从复制概述
MySQL主从复制是一个异步的复制过程,底层是基于MySQL数据库自带的 二进制日志 功能。就是一台或多台MySQL数据库(slave,即从库)从另一台MySQL数据库(master,即主库)进行日志的复制,然后再解析日志并应用到自身,最终实现 从库 的数据和 主库 的数据保持一致。MySQL主从复制是MySQL数据库自带功能,无需借助第三方工具。
二进制日志
二进制日志(BINLOG):记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但是不包括数据查询语句。此日志对于灾难时的数据恢复起着极其重要的作用,MySQL的主从复制, 就是通过该binlog实现的。默认MySQL是未开启该日志的。
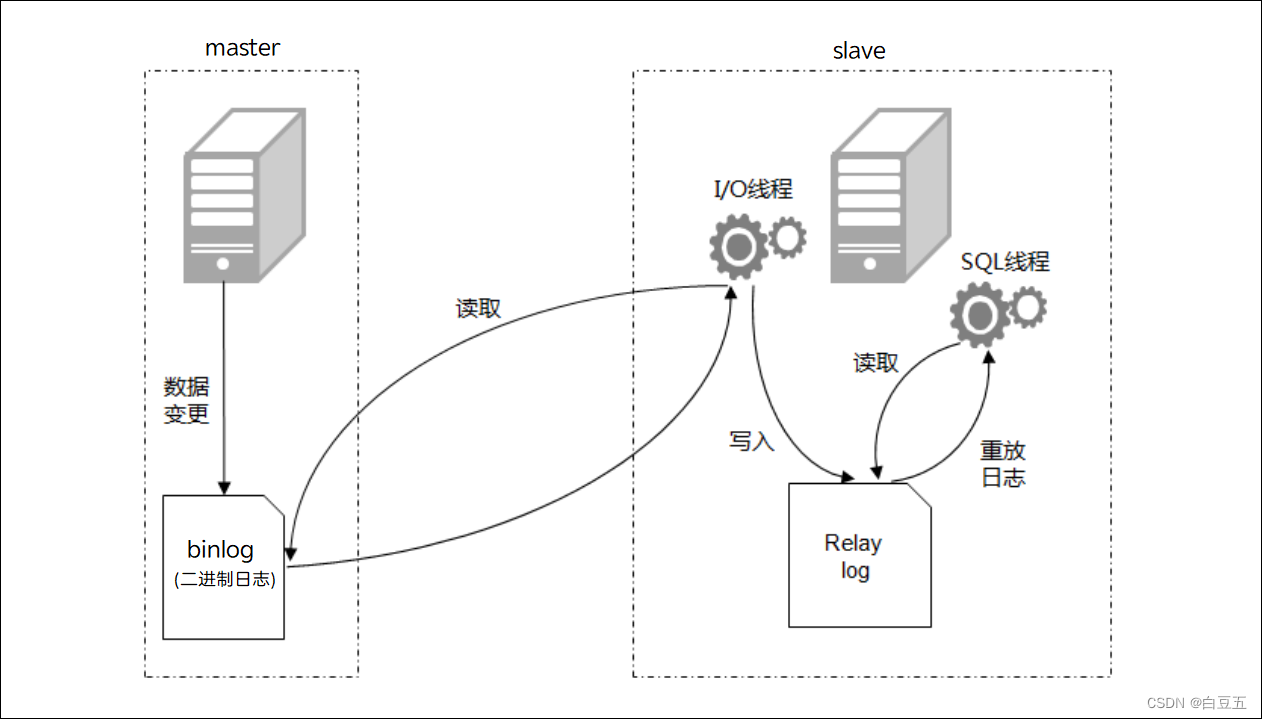
MySQL主从复制的操作过程:
1、master数据库:将数据变更写入二进制日志( binary log)。
2、slave数据库:将master的binary log拷贝到它的中继日志(relay log)。
3、slave重做中继日志中的事件,将数据变更反映它自己的数据。
我们需要做的事情:
- 在主库中开启binlog,设置
server_id,且创建一个拥有副本复制权限的用户。 - 查看主库状态,就是看日志文件和日志的偏移量(开始位置)。
- 在从库上设置
server_id,使用主库提供的用户监听主库日志,开启监听即可。
2. 环境搭建
2.1 前期准备
1、提供两台虚拟机,ip在同一网段,并且都装上MySQL:
| 数据库 | IP | 数据库版本 |
|---|---|---|
| Master(主库) | 192.168.203.128 | 5.7.25 |
| Slave(从库) | 192.168.203.129 | 5.7.25 |
注意:如果虚拟机是克隆的,需要修改ip,以及 /var/lib/mysql/auto.cnf文件中server_uuid的值(网上随便复制一个uuid值即可),最后重启网卡和mysql服务。
- 重启网卡:systemctl restart network。
- 重启mysql:systemctl restart mysqld。
2、将两台虚拟机进行端口配置:
- 方案一:防火墙开放3306端口号
- 开放3306端口:firewall-cmd --zone=public --add-port=3306/tcp --permanent
- 更新防火墙规则:firewall-cmd --zone=public --list-ports
- 方案二:关闭防火墙
- 停止防火墙:systemctl stop firewalld
- 关闭开机自启:systemctl disable firewalld
3、启动这两台机器上的MySQL数据库,登录MySQL,验证是否正常启动。
systemctl status mysqld #查看mysql的运行状态
systemctl start mysqld
mysql -uroot -p123456
2.2 MySQL主库配置
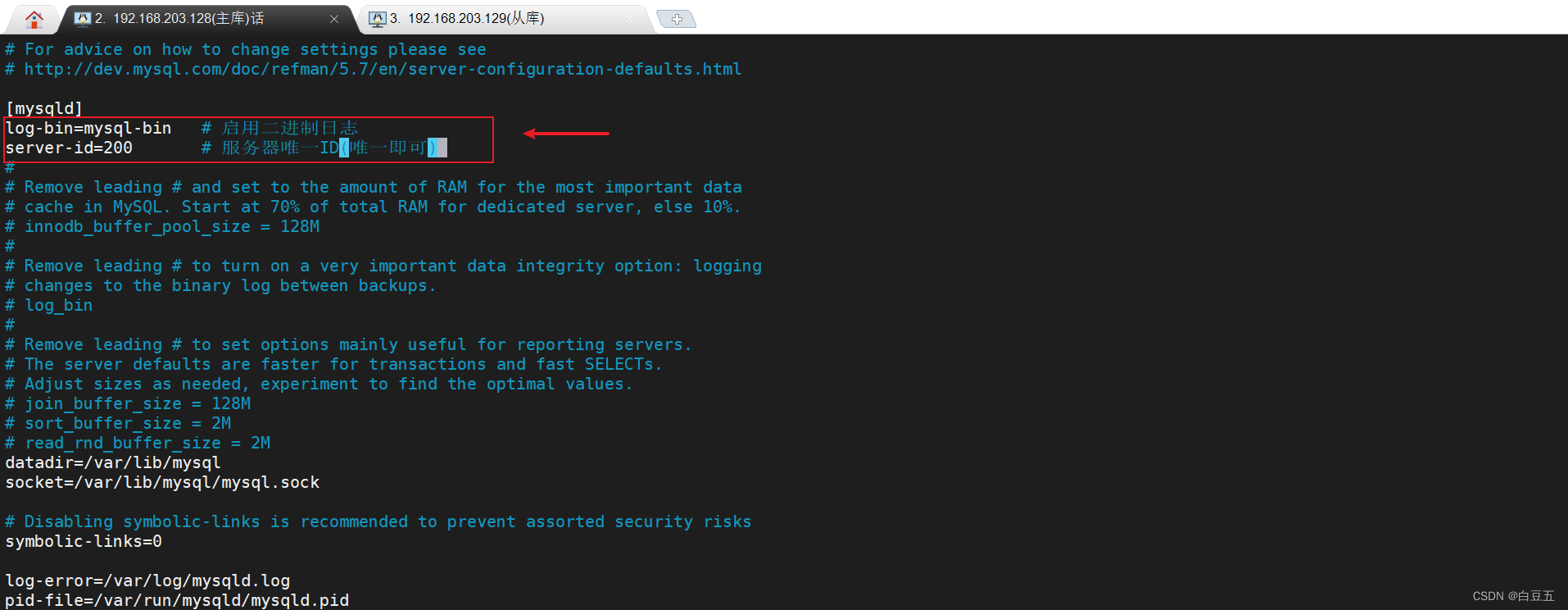
1、修改mysql数据库配置文件==/etc/my.cnf==:
log-bin=mysql-bin # 启用二进制日志
server-id=200 # 服务器唯一ID(唯一即可)
2、重启Mysql服务:
systemctl restart mysqld
3、登录Mysql数据库,创建数据同步的用户,并对该用户授权。

执行如下命令,创建用户并授权:
# 创建用户并授予REPLICATION SLAVE权限,用于建立复制时所需要用到的用户权限
# 主库授权 从库可以使用xiaoming这个用户访问主库进行所有数据库下的所有表的数据备份
GRANT REPLICATION SLAVE ON *.* to 'xiaoming'@'%' identified by 'Root@123';
# 刷新权限
flush privileges;

4、查看master同步状态:(记录下结果中File和Position的值)
show master status;
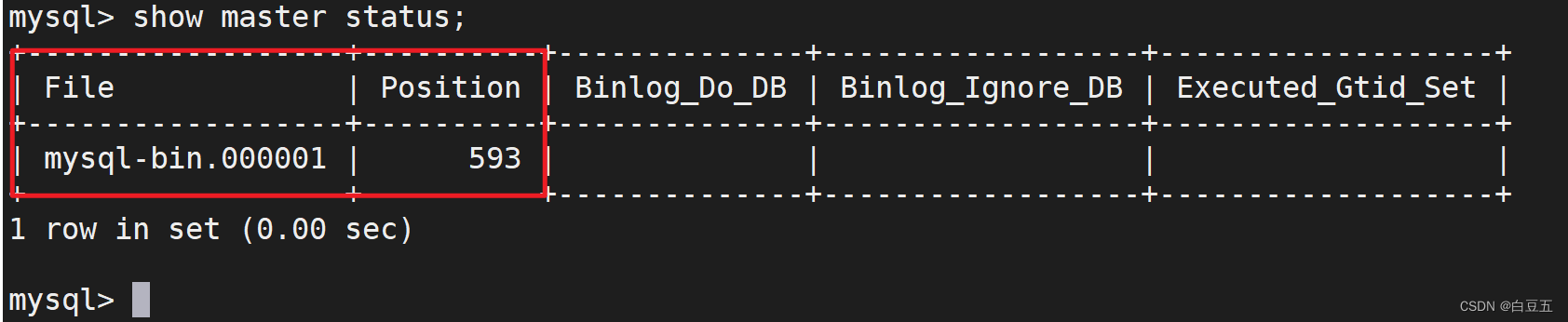
注:上面SQL的作用是查看Master的状态,执行完此SQL后不要再执行任何操作。
2.3 MySQL从库配置
1、修改mysql数据库配置文件==/etc/my.cnf==:
server-id=201 #服务器唯一ID
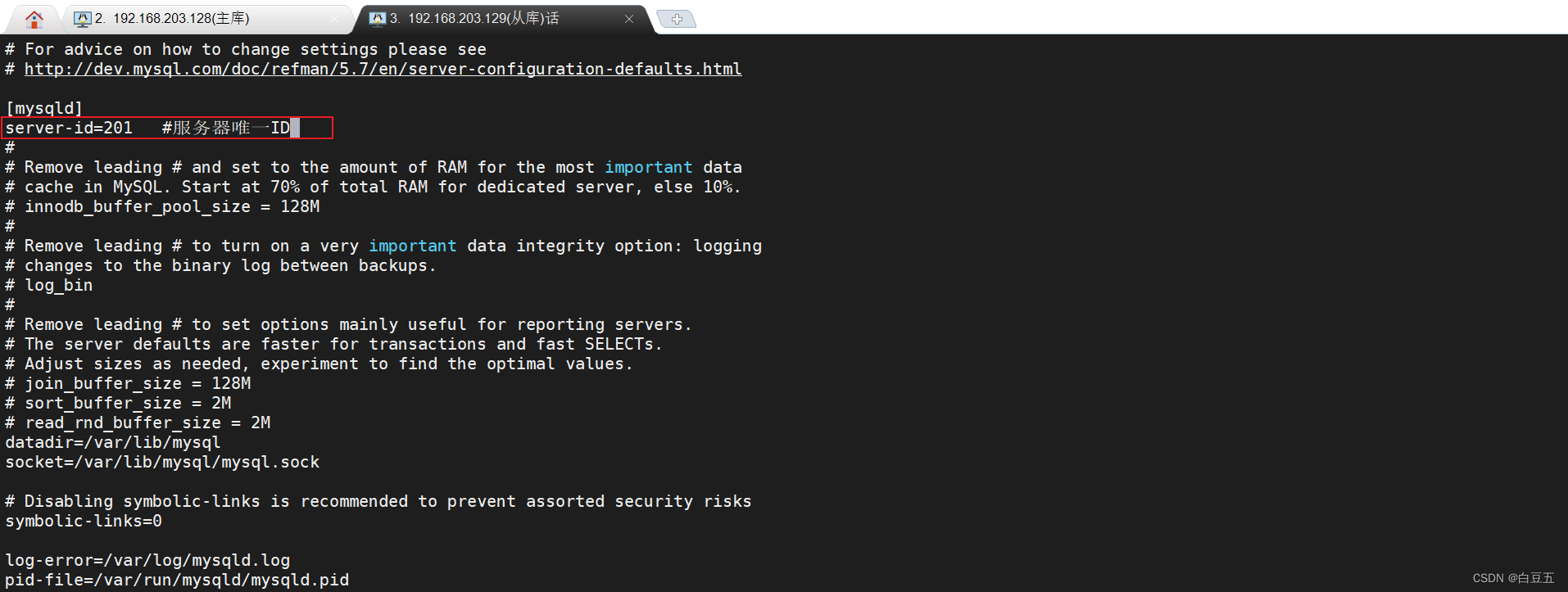
注意: 由于linux虚拟机是克隆出来的,mysql中还有一个server_uuid是一样的,我们需要对其修改。
vim /var/lib/mysql/auto.cnf

2、重启mysql服务
systemctl restart mysqld
3、登录MySQL数据库,设置当前从库所关联的主数据库:
# 设置主库地址以及同步位置
change master to master_host='192.168.203.128',master_user='xiaoming',master_password='Root@123',master_log_file='mysql-bin.000001',master_log_pos=593;
# 启动从库
start slave;

参数说明:
-
master_host : 主库的IP地址。
-
master_user : 访问主库进行主从复制的用户名(上面在主库创建的)。
-
master_password : 访问主库进行主从复制的用户名对应的密码。
-
master_log_file : 从哪个日志文件开始同步(上述查询master状态中有该内容:ysql-bin.000001)。
-
master_log_pos : 从指定日志文件的哪个位置开始同步(上述查询master状态有该内容:position:593)。
4、查看从数据库的状态
show slave status\G;
通过状态信息中的 Slave_IO_running 和 Slave_SQL_running 可以看出主从同步是否就绪,如果这两个参数全为Yes,表示主从同步已经配置完成。

MySQL命令行技巧:
\G : 在MySQL的sql语句后加上\G,表示将查询结果进行按列打印,可以使每个字段打印到单独的行。即将查到的结构旋转90度变成纵向;
3. 测试
主从复制的环境已经搭建好了,接下来我们可以通过可视化软件连接这两台MySQL服务器。测试时,我们只需在主库Master上执行操作,然后查看从库Slave中是否将数据同步过去。
注意:增删改的操作一定要在主库上操作,千万不要在从库操作,否则会导致Slave_SQL_Running线程会被终止的,从而导致主从复制失败了。解决方案:https://blog.csdn.net/u013829518/article/details/91869547
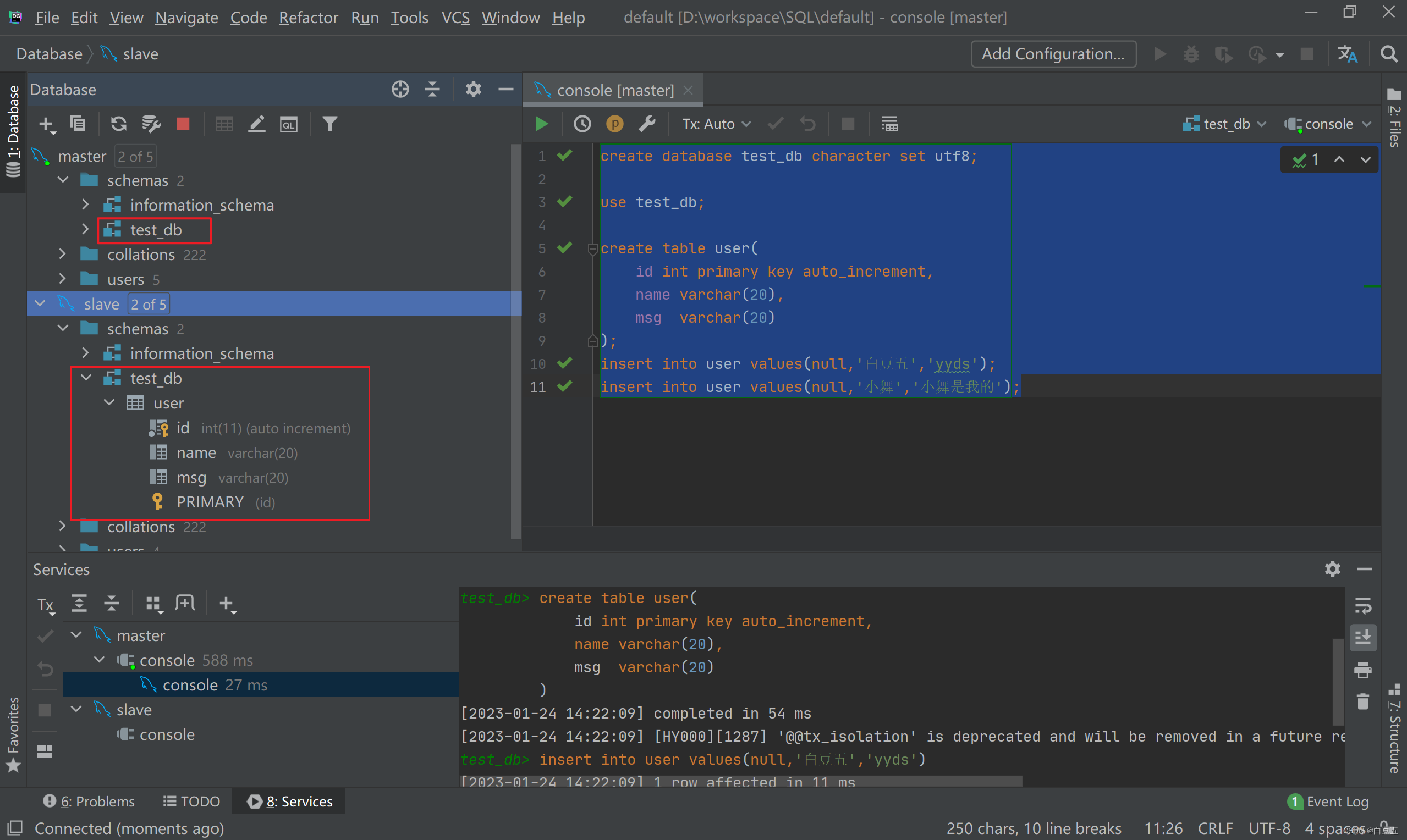
1、在master中,创建数据库、数据表、插入数据。

create database test_db character set utf8;
use test_db;
create table user(
id int primary key auto_increment,
name varchar(20),
msg varchar(20)
);
insert into user values(null,'白豆五','yyds');
insert into user values(null,'小舞','小舞是我的');
2、刷新slave查看是否可以同步过去。
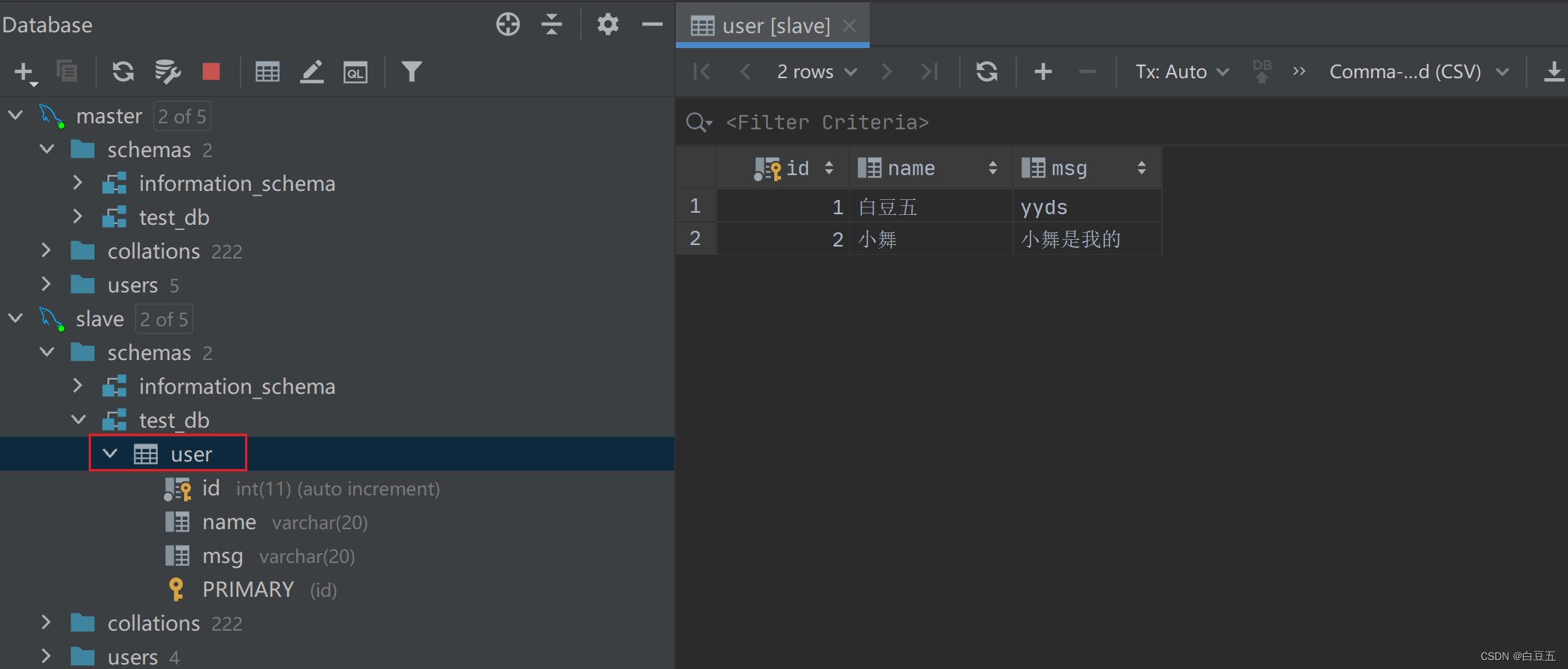
ok,主从复制就大功告成啦😊。
二、读写分离
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
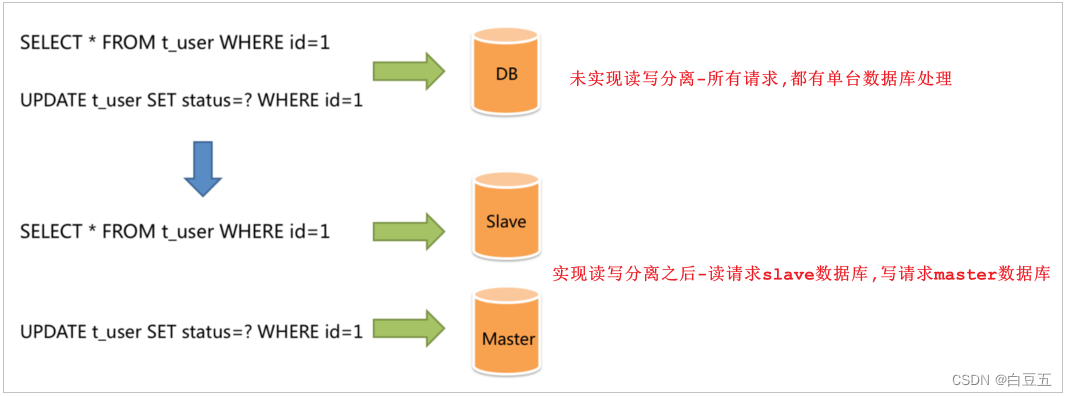
通过读写分离,就可以降低单台数据库的访问压力,提高访问效率,也可以避免单机故障。
1. ShardingJDBC
官网地址:http://shardingsphere.apache.org/index_zh.html
离线pdf文档下载:https://shardingsphere.apache.org/pdf/shardingsphere_docs_cn.pdf
快速入门:https://shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-jdbc-quick-start/
Sharding-JDBC(沙丁-JDBC,英语不好真难)定位于轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
Sharding-JDBC具有以下几个特点:
-
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
-
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
-
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
ShardingJDBC的依赖坐标:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2. 环境搭建
2.1 数据库环境
基于上面的MySQL主从复制实现。
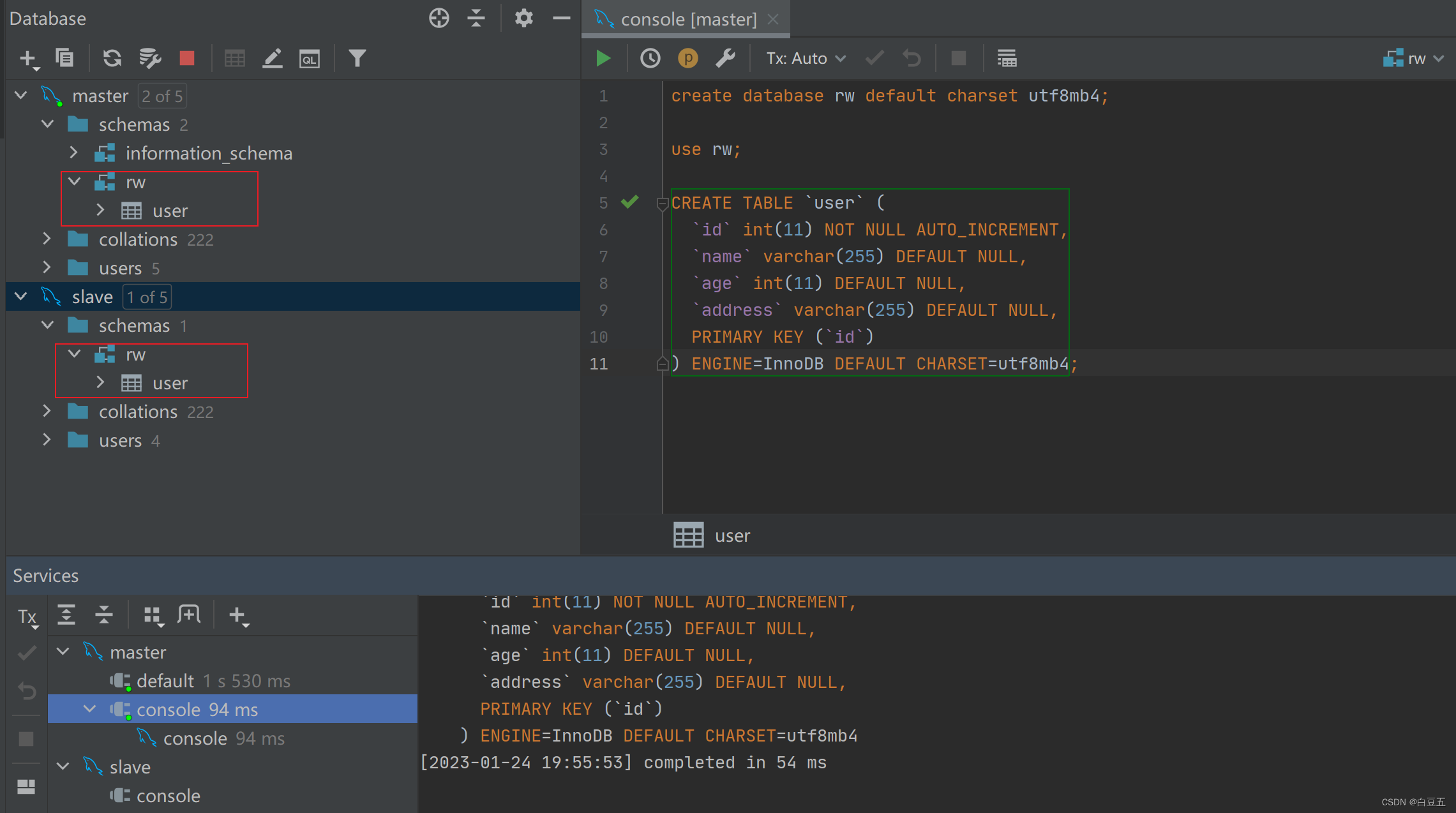
在主库中创建一个数据库rw, 并且创建一张表, 该数据库及表结构创建完毕后会自动同步到从库,SQL语句如下:
create database rw default charset utf8mb4;
use rw;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2.2 初始化项目环境
1、创建maven工程。
2、导入依赖:(pom.xml)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!--父工程-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
<relativePath/>
</parent>
<groupId>com.baidou</groupId>
<artifactId>rw_demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!--sharding-jdbc-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!--web场景开发-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<scope>compile</scope>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<!--fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
<!--工具类-->
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<!--mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!--mybatis起步依赖-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<!--druid起步依赖-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.23</version>
</dependency>
</dependencies>
<!--打包插件-->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3、创建application.yml文件。
server:
port: 8081
4、编写实体类
package com.baidou.entity;
import lombok.Data;
import java.io.Serializable;
@Data
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String name;
private int age;
private String address;
}
5、编写mapper接口
package com.baidou.mapper;
import com.baidou.entity.User;
import org.apache.ibatis.annotations.*;
import java.util.List;
@Mapper
public interface UserMapper {
@Select("select * from user where id=#{userId}")
public User findById(Long userId);
@Delete("delete from user where id=#{userId}")
public void removeById(Long userId);
@Insert("insert into user values(null,#{name},#{age},#{address})")
@Options(useGeneratedKeys = true,keyProperty = "id",keyColumn = "id")
public void save(User user);
@Update("update user set name=#{name},age=#{age},address=#{address} where id=#{id}")
@Options(useGeneratedKeys = true,keyProperty = "id",keyColumn = "id")
public void updateById(User user);
@Select("select * from user")
public List<User> findAll();
}
6、编写service接口
package com.baidou.service;
import com.baidou.entity.User;
import java.util.List;
public interface UserService {
public User findById(Long userId);
public void removeById(Long userId);
public void save(User user);
public void updateById(User user);
public List<User> findAll();
}
package com.baidou.service.impl;
import com.baidou.entity.User;
import com.baidou.mapper.UserMapper;
import com.baidou.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserServiceImpl implements UserService{
@Autowired(required = false)
private UserMapper userMapper;
@Override
public User findById(Long userId) {
User user = userMapper.findById(userId);
return user;
}
@Override
public void removeById(Long userId) {
userMapper.removeById(userId);
}
@Override
public void save(User user) {
userMapper.save(user);
}
@Override
public void updateById(User user) {
userMapper.updateById(user);
}
@Override
public List<User> findAll() {
return userMapper.findAll();
}
}
7、编写controller
package com.baidou.controller;
import com.baidou.entity.User;
import com.baidou.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import javax.sql.DataSource;
import java.util.List;
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@Autowired(required = false)
private DataSource dataSource;
@Autowired
private UserService userService;
@PostMapping
public User save(@RequestBody User user){
userService.save(user);
return user;
}
@DeleteMapping("/{id}")
public void delete(@PathVariable Long id){
userService.removeById(id);
}
@PutMapping
public User update(@RequestBody User user){
userService.updateById(user);
return user;
}
@GetMapping("/{id}")
public User getById(@PathVariable Long id){
User user = userService.findById(id);
return user;
}
@GetMapping("/list")
public List<User> list(User user){ ;
List<User> list = userService.findAll();
return list;
}
}
8、编写启动类
@Slf4j
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
log.info("项目启动成功...");
}
}
2.3 读写分离配置
1、导入shardingJdbc依赖坐标
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2、在application.yml中配置数据源:
server:
# 项目端口号
port: 8081
spring:
main:
# 允许bean重复定义(当项目中存在同名的bean,后定义的bean会覆盖先定义的)
# 允许后面创建数据源覆盖前面创建的数据源
# 如果不配置该项,项目启动之后将会报错
allow-bean-definition-overriding: true
#sharding-jdbc的配置
shardingsphere:
datasource:
#给数据源起名字,名字随意,后面配置数据源要用到这些名字
names:
master,slave1
# 配置主数据源---master
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.203.128:3306/rw?characterEncoding=utf-8&useSSL=false
username: root
password: 123456
# 配置从数据源---slave1
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.203.129:3306/rw?characterEncoding=utf-8&useSSL=false
username: root
password: 123456
# 主从配置 (配置一主一从)
masterslave:
# 配置主从名称,名字随意
name: rw
# 主库数据源名称,对应datasource中某个数据源的配置
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave1 #配置多个从库写法: slave1,slave2
# 配置多个从服务器的负载均衡算法:random(随机)和round_robin(轮询)
# 以后使用会配置多个从库
load-balance-algorithm-type: round_robin
props:
sql:
show: true #开启SQL显示,默认false
mybatis:
configuration:
# 打印sql日志
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 开启驼峰命名
map-underscore-to-camel-case: true
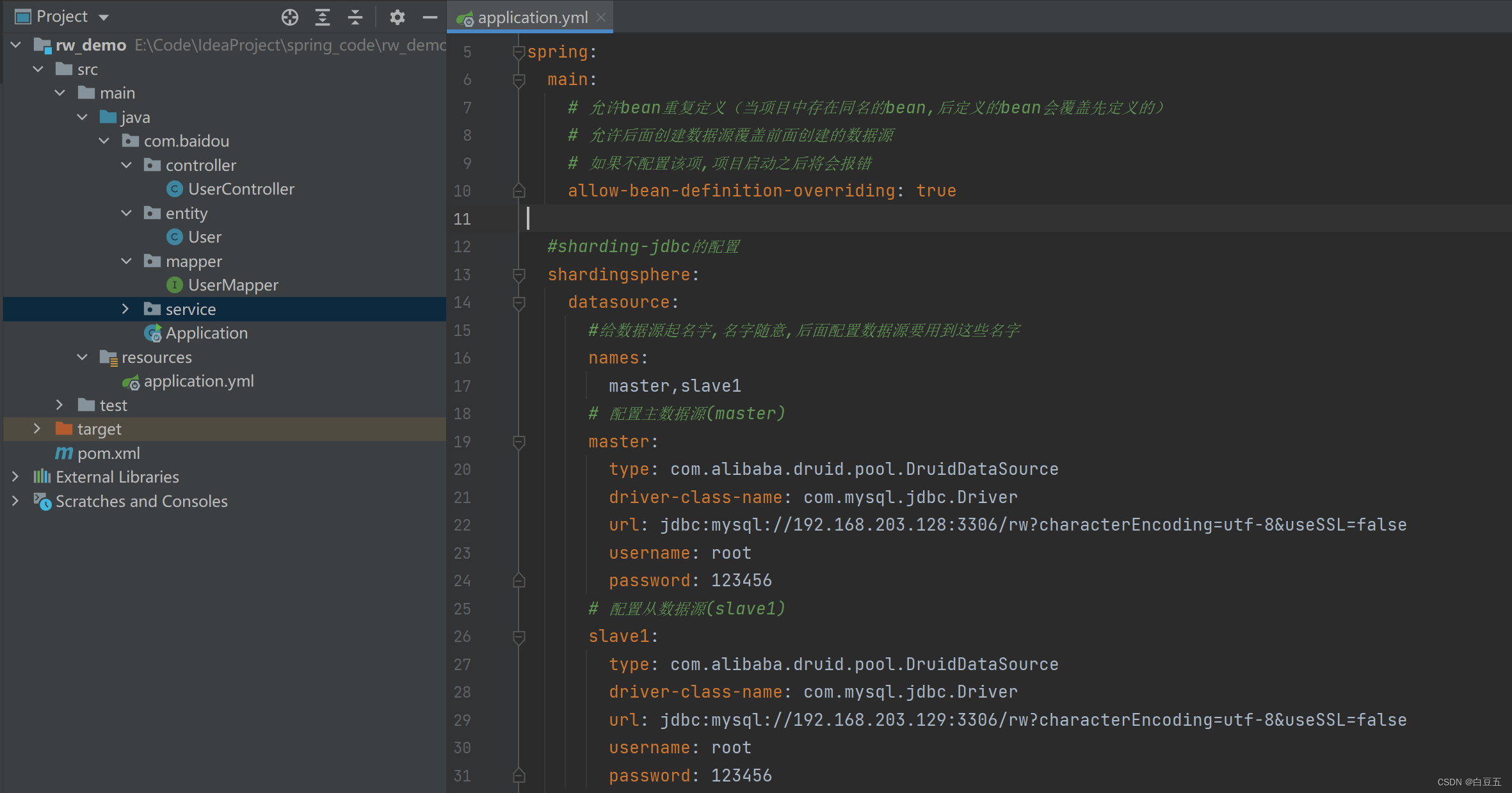
我们使用shardingjdbc来实现读写分离,直接通过上述简单的配置就可以了。配置完毕后重启服务,通过postman来访问controller的方法完成读写操作。(增删改是写操作,查询是读操作)
3、debug启动项目(通过debug及日志的方式查看每次执行增删改查操作,使用的是哪个数据源,连接的是哪个数据库)
2.4 测试访问
使用IDEA的RestfulTool插件测试接口:
1、添加数据(测试接口:http://localhost:8081/user/ )
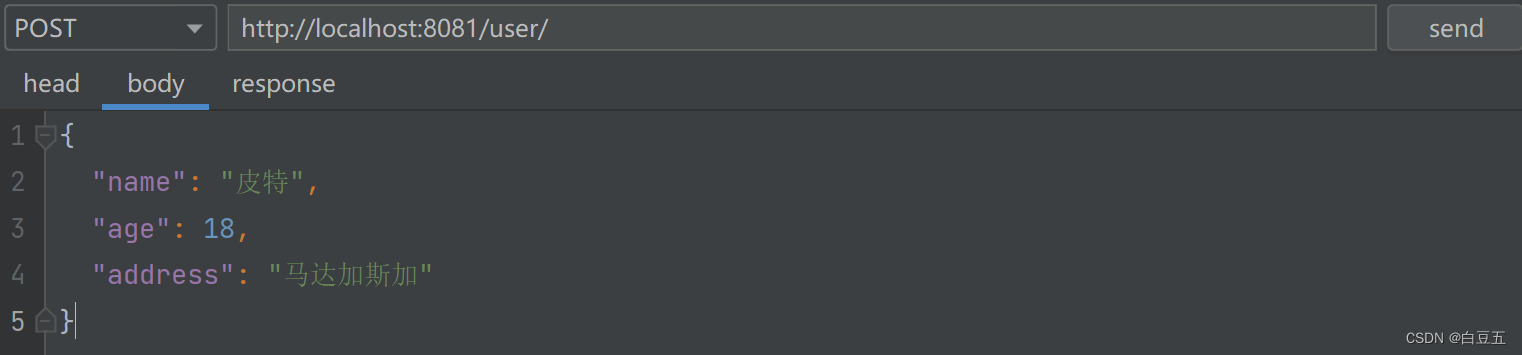
控制台输出日志,执行insert进入master库操作:

2、修改数据(测试接口:http://localhost:8081/user/)
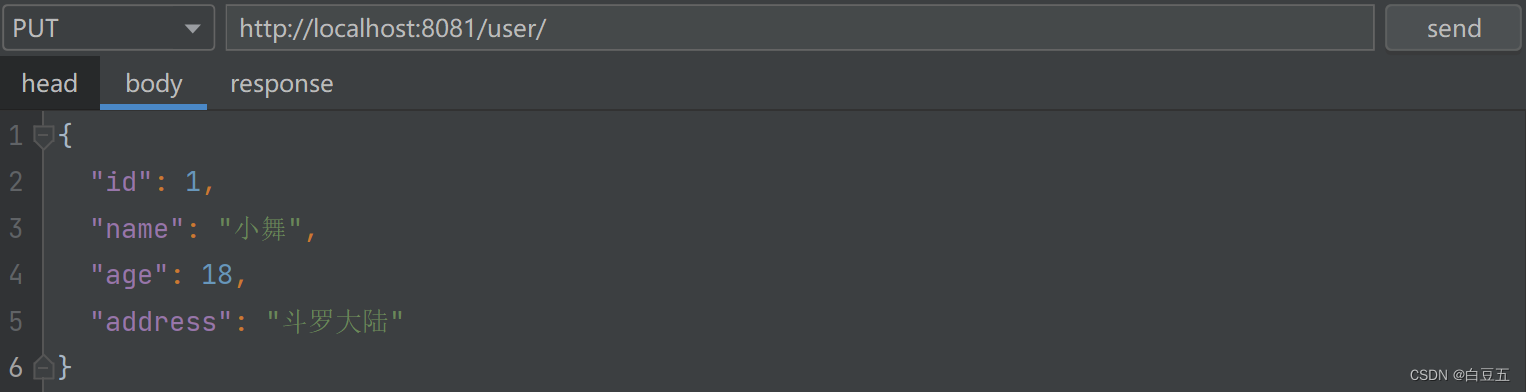
控制台输出日志,执行update进入master库操作:

3、查询数据(测试接口:http://localhost:8081/user/list)
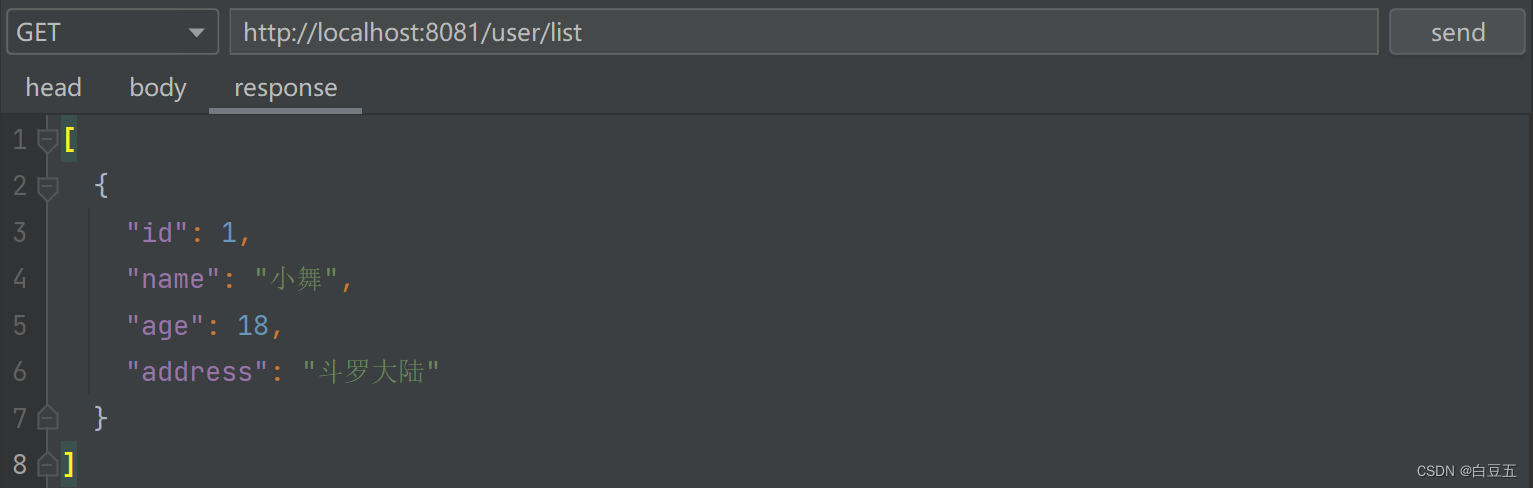
控制台输出日志,执行select进入slave1库操作:

4、删除数据(测试接口:http://localhost:8081/user/{id})

控制台输出日志,执行delete进入master库操作:

bean重复定义解决方案:
如果不配置下面的属性会出现什么问题?
spring:
main:
allow-bean-definition-overriding: true
重启项目后会报错:
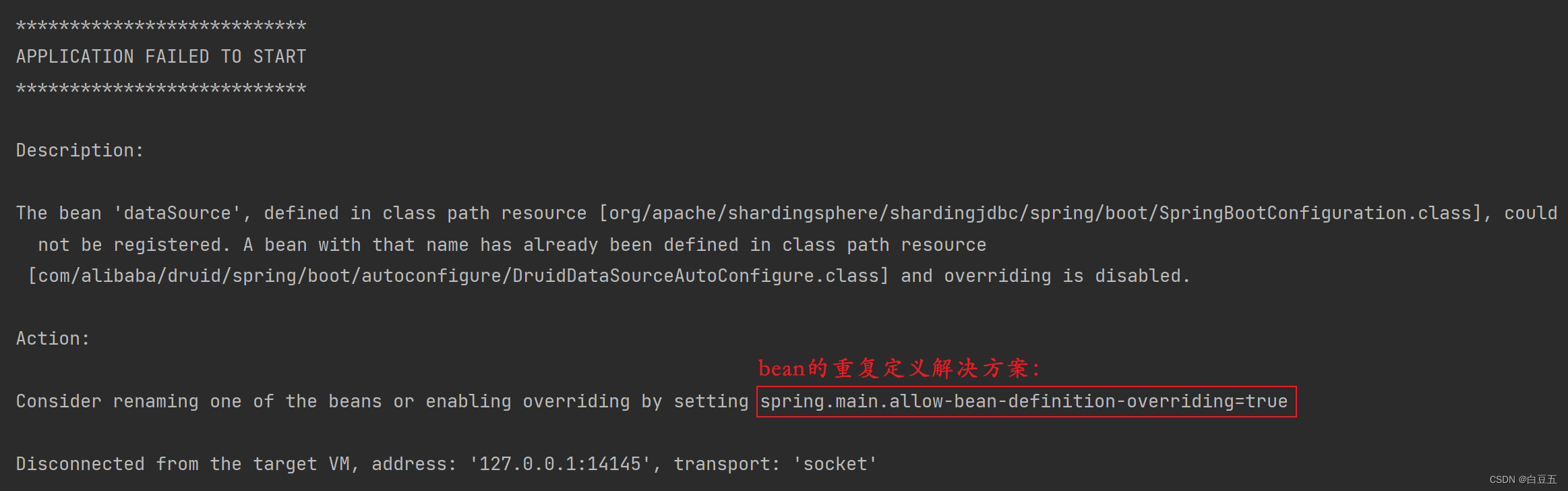
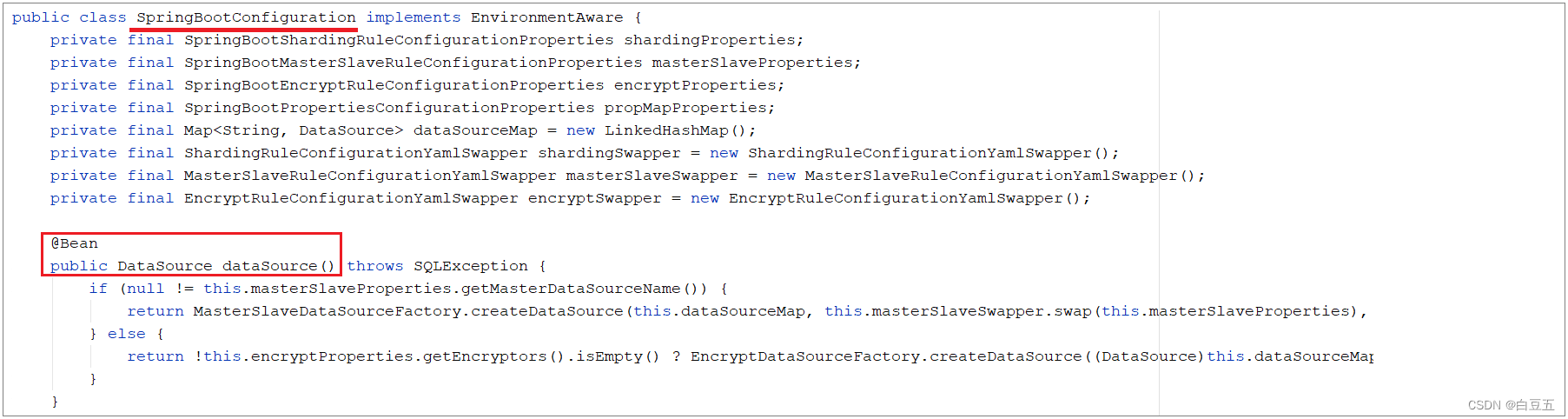
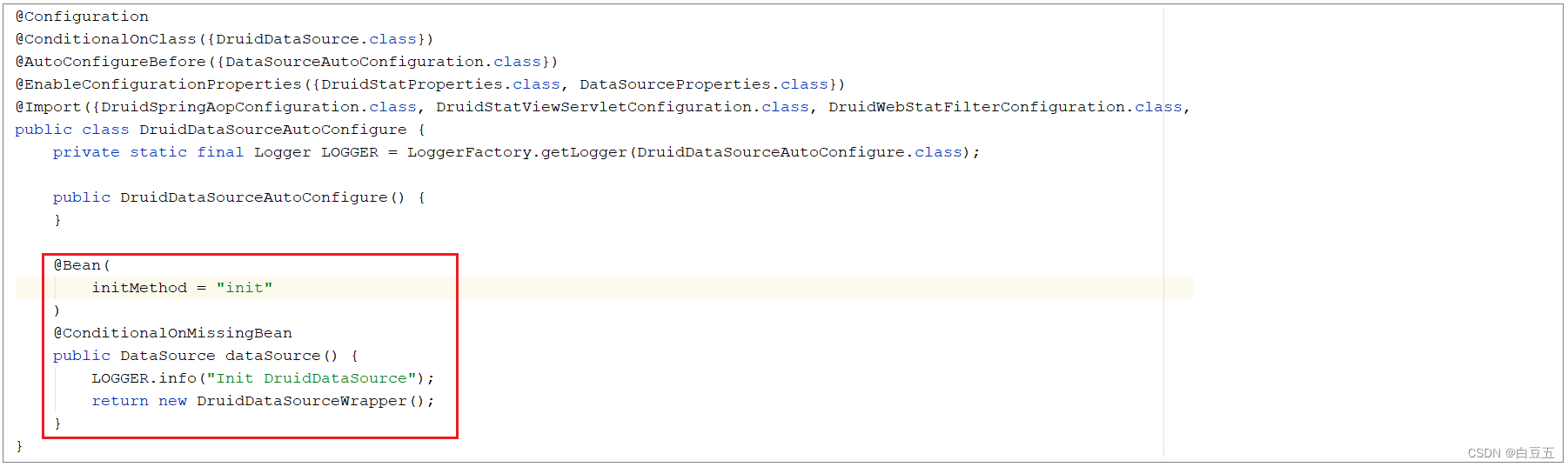
The bean 'dataSource', defined in class path resource
[org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class], could not
be registered. A bean with that name has already been defined in class path resource
[com/alibaba/druid/spring/boot/autoconfigure/DruidDataSourceAutoConfigure.class] and
overriding is disabled.
- shardingjdbc的bean(dataSource)不能被注册,出现同名的bean。
- springboot自动配置的时候就把DruidDataSourceAutoConfigure的dataSource声明了。
- 而我们需要用到的是shardingjdbc包下的dataSource,所以我们需要配置上述属性,让后加载的覆盖先加载的。