第一章 redis简介
第1节 NoSQL
1.1 NoSQL简介
NoSQL,泛指非关系型的数据库,NoSQL即Not-Only SQL,它可以作为关系型数据库的良好补充。随着互联网web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速。
1.2 NoSQL类别
- 键值(Key-Value)存储数据库
1 2 3 4 5
相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB 典型应用: 内容缓存,主要用于处理大量数据的高访问负载 数据模型: 一系列键值对 优势: 快速查询 劣势: 存储的数据缺少结构化
- 列存储数据库
1 2 3 4
相关产品:Cassandra, HBase, Riak 典型应用:分布式的文件系统 数据模型:以列簇式存储,将同一列数据存在一起 优势:查找速度快,可扩展性强,更容易进行分布式扩展 劣势:功能相对局限
- 文档型数据库
1 2 3 4 5
相关产品:CouchDB、MongoDB 典型应用:Web应用(与Key-Value类似,Value是结构化的) 数据模型: 一系列键值对 优势:数据结构要求不严格 劣势:查询性能不高,而且缺乏统一的查询语法
- 图形(Graph)数据库
1 2 3 4
相关数据库:Neo4J、InfoGrid、Infinite Graph 典型应用:社交网络 数据模型:图结构 优势:利用图结构相关算法 劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案
1.3 redis简介
2008年,意大利的一家创业公司Merzia推出了一款基于MySQL的网站实时统计系统LLOOGG,然而没过多久该公司的创始人 Salvatore Sanfilippo(萨尔瓦托桑菲利波)便对MySQL的性能感到失望,于是他决定亲自为LLOOGG量身定做一个数据库,并于2009年开发完 成,这个数据库就是Redis。不过Salvatore Sanfilippo并不满足只将Redis用于LLOOGG这一款产品,而是希望更多的人使用它,于是在同一年Salvatore Sanfilippo将Redis开源发布,并开始和Redis的另一名主要的代码贡献者Pieter Noordhuis(皮耶特诺德休斯)一起继续着Redis的开发,直到今天。
1.4 redis支持的数据类型
1 2 3 4 5 6 | Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库。它通过提供多种键值数据类型来适应不同场景下的 存储需求,目前为止Redis支持的键值数据类型如下: 字符串类型 散列类型 列表类型 集合类型 有序集合类型 |
1.5 redis特点
1 2 3 4 5 | Redis 与其他 key - value 缓存产品有以下三个特点: - Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。 - Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。 - Redis支持数据的备份,即master-slave模式的数据备份。 Redis 提供的API支持:C、C++、C#、Clojure、Java、JavaScript、Lua、PHP、Python、Ruby、Go、Scala、 Perl等多种语言 |
1.6 redis使用场景
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | 1、缓存 缓存现在几乎是所有中大型网站都在用的必杀技,合理的利用缓存不仅能够提 升网站访问速度,还能大大降低数据库的压力。Redis提供了键过期功能,也 提供了灵活的键淘汰策略,所以,现在Redis用在缓存的场合非常多。 2、排行榜 很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行 榜等。Redis提供的有序集合数据类构能实现各 种复杂的排行榜应用 3、计数器 什么是计数器,如电商网站商品的浏览量、视频网站视频的播放数等。为了保 证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无 疑是种挑战和压力。Redis提供的incr命令来实现计数器功能,内存操作,性 能非常好,非常适 用于这些计数场景。 等等.... |
1.7 redis的优缺点
- 优点
1 2 3 4 5
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行(事务) 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性
- 缺点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
(一)缓存和数据库双写一致性问题 分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。 数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个 前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只 能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低 不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放 缓存 回答:《分布式之数据库和缓存双写一致性方案解析》给出了详细的分析,在 这里简单的说一说。首先,采取正确更新策略,先更新数据库,再删缓存。 其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利 用消息队列. (二)缓存雪崩问题、缓存穿透 分析:这两个问题,一般中小型传统软件企业,很难碰到这个问题。如果有大 并发的项目,日流量有KW级上。这两个问题一定要深刻考虑。缓存穿透,即 黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从 而数据库连接异常.
1.8 redis面向互联网的解决方案
1 2 3 4 5 6 7
- 主从:一主多从,主机可写,从机备份。类似于Mysql的读写分离,存在问 题是一但主节点down掉,整个Redis不可用 - 哨兵(2.x):启用一个哨兵程序(节点),监控其余节点的状态,根据选举策 略,进行主从切换。缺点:每个节点的数据依旧是一致的,仍无法实现分布式 的数据库 - 集群(3.x):结合上述两种模式,多主多从,实现高可用、分布式数据存储( 绝大部分的使用集群)
第二章 redis单机安装(linux)
第1节 在linux安装
第1步: 使用 wget 命令获取redis安装包
wget http://download.redis.io/releases/redis-5.0.0.tar.gz
如果wget命令不存在使用此命令安装 yum install wget
第2步: 将下载的安装包解压到指定的位置 比如 /opt文件夹下
tar -xzvf redis-5.0.0.tar.gz -C /opt
第3步: 切换到解压之后的redis文件夹内,然后执行编译命令
make
如果报没有gcc编译器使用此命令安装gcc编译器 yum install gcc
第4步: 指定安装位置(将redis安装到/usr/local/redis目录下,方便我们以后查找)
make install PREFIX=/usr/local/redis
第5步: 拷贝安装目录下配置文件到 /usr/local/redis/etc
mkdir /usr/local/redis/etc/ 创建etc文件夹
cp /opt/redis-5.0.0/redis.conf /usr/local/redis/etc/ 将redis配置文件拷贝到我们自己定义的文件夹下方便查找第6步: 修改配置文件 /usr/local/redis/etc/redis.conf
vim /usr/local/redis/etc/redis.conf
如果vim命令不存在可以使用此命令安装
yum -y install vim*
yum install vim配置文件简答修改:
1、 protected-mode : yes/no 关闭保护模式(如果不关闭保护模式,外部机器访问此redis服务器时,必须指定bind属性绑定的主机才能访问) 外部网络可以直接访问
2、daemonize: no/yes 开启守护进程(开启守护进程redis可以后台运行)
3、bind 127.0.0.1:绑定本机ip,当保护模式关闭以后可以不用指定具体主机IP,但是设置为 0.0.0.0
4、pidfile /var/run/redis_6379.pid redis进程文件,当开启守护进程之后会在本地生成一个pid文件
5、logfile /var/log/redis_6379.log 配置redis服务器日志生成和保存位置
6、dir /usr/local/redis/data/ 快照数据存放目录
第7步: 启动redis服务器
redis启动命令在我们的安装目录下,当我们使用make install PREFIX=/usr/local/redis命令进行安装时
将redis安装到了/usr/local/redis目录下,在此目录下会自动生成一个bin目录,启动redis的脚本在这个目录下
启动命令: /usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf
ps aux | grep redis 命令查看redis服务器是否启动
第8步: 连接适应redis自带的客户端连接redis服务器
进入到我们redis安装目录下的bin目录,找到我们redis启动脚本
启动redis服务器使用 redis-server脚本
使用redis客户端连接redis服务器采用redis-cli脚本
连接方式: ./redis-cli -h 127.0.0.1 -p 6379
-h : 指定连接redis服务器主机地址
-p : 指定连接应用(redis服务器应用)的端口号
第三章 redis常用命令
第1节 字符串(String)
| 命令 | 描述 | 备注 |
|---|---|---|
| set key value | 想redis服务器中设置一个字符串 | set key01 value01 |
| get key | 通过key指从服务器中获取值 | get key01 |
| del key | 删除指定的key | del key01 |
| getset key value | 给指定的key赋值,并且返回旧值 | getset key01 value02 |
| mset key01 value01 key02 value02 | 同时设置一个或多个 key-value 对 | mset key04 value04 key05 value05 key06 value06 |
| mget key01 key02 … | 获取多个key值 | mget key01 key02 |
| setnx key value | 给不存在的key赋值,如果存在赋值失败 | setnx key03 value03 |
| msetnx key01 value01 key02 value02 | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在,如果有一个key存在,那么存储失败 | msetnx key04 value04 key07 value07 |
| setex key [时间以秒为单位] value | 给数据设置超时时间,如果key存在就覆盖 | setex key04 10 value04 |
| psetex key07 [毫秒值] value07 | 给数据设置超时时间,如果key存在就覆盖 | psetex key07 10000 value07 |
| strlen key | 获取指定字符串的长度 | strlen key06 |
第2节 哈希(Hash)
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)
| 命令 | 描述 | 备注 |
|---|---|---|
| hset hashname filed value | hset:设值命令;hashname:集合名称;field:集合中的属性名;value:集合中的属性值 | hset myhash hkey01 hvalue01 |
| hget hashname filed | hget:获取值命令;hashname:获取哪一个hash集合;field:获取哪一个hash集合中的属性 | hget myhash hkey01 |
| hdel hashname filed1 [filed2] | 删除一个或多个哈希表字段 | hdel myhash hkey01 hkey02 |
| hexists hashname filed | 查看指定哈希表中,指定的字段是否存在 | hexists myhash hkey01 |
| hgetall hashname | 获取指定哈希表中所有字段和值 | hgetall myhash |
| hkeys hashname | 获取指定hash表中的所有field | hkeys myhash |
| hlen hashname | 获取哈希表中字段的数量 | hlen myhash |
| hmget hashname filed1 filed2 filed3 | 获取所有给定字段的值 | hmget myhash hkey01 hkey02 hkey03 |
| hmset hashname filed1 hvalue1 hkey2 hvalue2 | 同时将多个 field-value 设置到哈希表中 | hmset myhash hkey03 hvalue03 hkey04 hvalue04 hkey05 hvalue05 |
| hsetnx hashname filed value | 只有在字段 field 不存在时,设置哈希表字段的值 | hsetnx myhash hkey03 hvalue03 |
| hvals hashname | 获取哈希表中所有值 | hvals myhash |
第3节 列表(List)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边),一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)
| 语法 | 描述 | 备注 |
|---|---|---|
| lpush key value [value …] | 将一个或多个值插入到列表头部 | lpush mylist lvalue01 |
| lpushx key value | 将一个值插入到已存在的列表头部 | lpushx mylist value03 |
| lset key index value | 通过索引设置列表元素的值 | lset mylist 0 lvalue001 |
| rpushx key value | 为已存在的列表添加值 | rpushx mylist lvalue03 |
| rpushx key value1 value2[value…] | 在列表中添加一个或多个值 | rpush mylist lvalue04 lvalue05 |
| blpop key01 key02 100 | 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 | blpop mylist 100 |
| brpop key01 key02 100 | 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 | brpop mylist 200 |
| lindex key index | 通过索引获取列表中的元素 | lindex mylist 1 |
| llen key | 获取列表长度 | llen mylist |
| lpop key | 移出并获取列表的第一个元素 | lpop mylist |
| rpop key | 移除列表的最后一个元素,返回值为移除的元素 | rpop mylist |
第4节 集合(Set)
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)
| 命令 | 描述 | 备注 |
|---|---|---|
| sadd key value[value…] | 向集合添加一个或多个成员 | sadd myset1 myvalue01 myvalue02 |
| scard key | 获取集合的成员数 | scard myset1 |
| sinter key1 key2 | 返回给定所有集合的交集 | sinter myset1 myset2 |
| sismember key member | 判断 member 元素是否是集合 key 的成员 | sismember myset1 myvalue01 |
| smembers key | 返回集合中的所有成员 | smembers myset1 |
| srem key value | 移除集合中一个或多个成员 | srem myset2 myvalue01 |
| sunion key1 key2 | 返回所有给定集合的并集 | sunion myset1 myset2 |
第5节 有序集合(sorted set)
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序
有序集合的成员是唯一的,但分数(score)却可以重复
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)
| 语法 | 描述 | 备注 |
|---|---|---|
| ZADD key score1 zvalue01 score2 zvalue02 | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 | ZADD zset 1 zvalue01 2 zvalue02 |
| ZCARD key | 获取有序集合的成员数 | ZCARD zset |
| ZRANK key member | 返回有序集合中指定成员的索引 | ZRANK zset zvalue02 |
| ZREM key member [member …] | 移除有序集合中的一个或多个成员 | ZREM zset zvalue02 |
| ZSCORE key member | 返回有序集中,成员的分数值 | ZSCORE zset zvalue01 |
| ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合指定区间内的成员 | ZRANGE zset 0 -1 WITHSCORES |
第6节 Redis HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比
6.1 什么是基数
在数学上,基数(cardinal number)是集合论中刻画任意集合大小的一个概念 (集合长度)
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数
| 语法 | 描述 | 备注 |
|---|---|---|
| PFADD key element [element …] | 添加指定元素到 HyperLogLog 中 | PFADD ploglog a b c d |
| PFCOUNT key [key …] | 返回给定 HyperLogLog 的基数估算值 | PFCOUNT ploglog |
| PFMERGE destkey sourcekey [sourcekey …] | 将多个 HyperLogLog 合并为一个 HyperLogLog | PFMERGE hll3 hll1 hll2 |
第四章 redis集群
- redis的高级命令
1 2 3 4 5 6 7 8 9 10 11 12 13 | keys * : 返回满足的所有键 ,可以模糊匹配 比如 keys abc* 代表 abc 开头的key exists key :是否存在指定的key,存在返回1,不存在返回0 expire key second:设置某个key的过期时间 时间为秒 del key:删除某个key select : 选择数据库 数据库为0-15(默认一共16个数据库) 设计成多个数据库实际上是为了数据库安全和备份 move key dbindex : 将当前数据中的key转移到其他数据库 echo:打印命令 dbsize:查看数据库的key数量 info:查看数据库信息 flushdb :清空当前数据库 flushall :清空所有数据库 |
第1节 主从模式
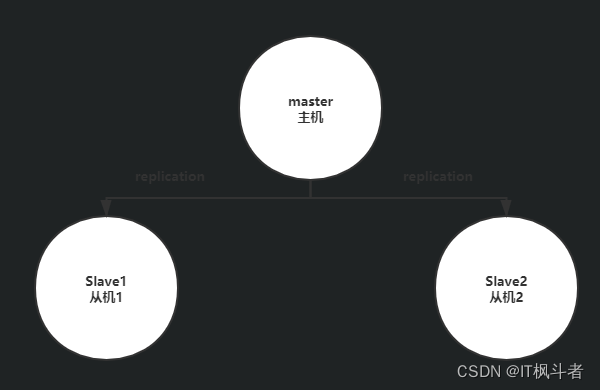
1.1 优点
- 高可靠性:一方面,采用双机主备架构,能够在主库出现故障时自动进行主备切换,从库提升为主库提供服
务,保证服务平稳运行;另一方面,开启数据持久化功能和配置合理的备份策略,能有效的解决数据误操作和
数据异常丢失的问题 - 读写分离策略:从节点可以扩展主库节点的读能力,有效应对大并发量的读操作
1.2 缺点
- 故障恢复复杂
- 当主库节点出现故障时,需要手动将一个从节点晋升为主节点,同时需要通知业务方变更配置,并且需要让其它从库节点去复制新主库节点,整个过程需要人为干预,比较繁琐.
- 应用较少
1.3 配置方式
-
配置文件master_6379
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# 外部访问设置 bind 0.0.0.0 #端口号 port 6379 # 开启守护进程 daemonize yes # 关闭保护模式,可以被外部主机访问 protected-mode no # 存储日志位置 logfile "./log/master_6379.log" # 指定数据库文件名 dbfilename master_dump_6379.rdb # 快照保存位置 dir ./data #数据是否压缩 rdbcompression yes
-
配置文件slave_6380
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# 外部访问设置 bind 0.0.0.0 #端口号 port 6380 # 开启守护进程 daemonize yes # 关闭保护模式,可以被外部主机访问 protected-mode no # 存储日志位置 logfile "./log/slave_6380.log" # 指定数据库文件名 dbfilename salve_dump_6380.rdb # 快照保存位置 dir ./data #数据是否压缩 rdbcompression yes # 复制主机位置 SLAVEOF 127.0.0.1 6379
-
配置文件slave_6381
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# 外部访问设置 bind 0.0.0.0 #端口号 port 6381 # 开启守护进程 daemonize yes # 关闭保护模式,可以被外部主机访问 protected-mode no # 存储日志位置 logfile "./log/slave_6381.log" # 指定数据库文件名 dbfilename salve_dump_6381.rdb # 快照保存位置 dir ./data #数据是否压缩 rdbcompression yes # 复制主机位置 SLAVEOF 127.0.0.1 6379
第2节 哨兵模式
Redis Sentinel是社区版本推出的原生高可用解决方案,其部署架构主要包括两部分:Redis Sentinel集群和Redis数据集群(略)
第3节 集群模式
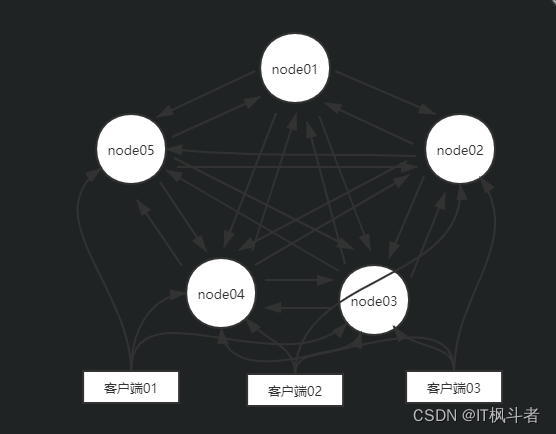
3.1 配置方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | 步骤: 第1步 创建一个文件夹取名为redis_cluster 第2步 在redis_cluster文件夹下创建六个文件夹 redis_7000 ~ redis_7006 第3步 拷贝redis_server和redis_cli脚本到分别到redis_7000 ~ redis_7006文件夹中 第4步 创建redis_7000.cnf~redis_7006.cnf配置文件 配置文件样例 # 外部访问设置 bind 0.0.0.0 #端口号 port 7001 # 开启守护进程 daemonize yes # 关闭保护模式,可以被外部主机访问 protected-mode no #数据是否压缩 rdbcompression yes # 是否开启集群 cluster-enabled yes # 群集节点每次发生更改时自动保留群集配置 cluster-config-file "node_7001.conf" # 设置超时时间 cluster-node-timeout 5000 第5步 将6个节点全部运行起来 |
3.2 启动集群
1 2 | 现在6个节点已经启动完成,这是需要一条命令将6个节点关联起来 redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1 |
3.3 使用客户端连接任意一个服务节点即可
1 | ./redis-cli -c -h [ip地址] -p [端口号] |
3.4 进行验证
1 2 | cluster info(查看集群信息) cluster nodes(查看节点列表) |
第五章 redis常见客户端
官网介绍
1 | http://www.redis.cn/ |
- Redisson
1 | Redisson:实现了分布式和可扩展的Java数据结构 |
- Jedis
1 | Jedis:是老牌的Redis的Java实现客户端,提供了比较全面的Redis命令的支持 |
- lettuce
1 | Lettuce:高级Redis客户端,用于线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器 |
-
优点
Jedis:比较全面的提供了Redis的操作特性
Redisson:促使使用者对Redis的关注分离,提供很多分布式相关操作服务,例如,分布式锁,分布式集合,可通过Redis支持延迟队列
Lettuce:基于Netty框架的事件驱动的通信层,其方法调用是异步的。Lettuce的API是线程安全的,所以可以操作单个Lettuce连接来完成各种操作
第六章 redis在项目中的应用
第1节 Jedis API操作
官网地址:
1 | https://github.com/xetorthio/jedis |
pom.xml
1 2 3 4 5 6 7 | <dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.1.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
|
1.1 单个节点
1 2 3 | Jedis jedis = new Jedis("localhost");
jedis.set("foo", "bar");
String value = jedis.get("foo");
|
1.2 jedis连接池
1 2 3 4 5 6 7 | //获取连接池
JedisPool pool = new JedisPool();
//获取jedis
Jedis jedis = pool.getResource();
//获取数据
String foo = jedis.get("foo");
System.out.println(foo);
|
1.3 集群使用
1 2 3 4 5 | Set<HostAndPort> jedisClusterNodes = new HashSet<HostAndPort>();
jedisClusterNodes.add(new HostAndPort("127.0.0.1", 7379));
JedisCluster jc = new JedisCluster(jedisClusterNodes);
jc.set("foo", "bar");
String value = jc.get("foo");
|
- 注意:使用集群模式一定要开启集群配置
第2节 与Spring框架整合(Jedis)
2.1 单节点连接池配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <!--导入外部属性资源文件-->
<context:property-placeholder location="classpath:redis.properties"></context:property-placeholder>
<!--连接池配置-->
<bean id="poolConfig" class="org.apache.commons.pool2.impl.GenericObjectPoolConfig">
<property name="maxTotal" value="${redis_max_total}"></property>
<property name="maxIdle" value="${redis_max_idle}"></property>
<property name="minIdle" value="${redis_min_idle}"></property>
</bean>
<!--配置jedis连接池jedispool-->
<bean id="jedisPool" class="redis.clients.jedis.JedisPool">
<constructor-arg index="0" ref="poolConfig"></constructor-arg>
<constructor-arg index="1" value="127.0.0.1" type="java.lang.String"></constructor-arg>
<constructor-arg index="2" value="6379" type="int"></constructor-arg>
</bean>
|
2.2 集群配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | <bean id="jedisCluster" class="redis.clients.jedis.JedisCluster"> <constructor-arg> <set> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg name="host" value="192.168.1.194"/> <constructor-arg name="port" value="6011"/> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg name="host" value="192.168.1.194"/> <constructor-arg name="port" value="6012"/> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg name="host" value="192.168.1.194"/> <constructor-arg name="port" value="6013"/> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg name="host" value="192.168.1.194"/> <constructor-arg name="port" value="6014"/> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg name="host" value="192.168.1.194"/> <constructor-arg name="port" value="6015"/> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg name="host" value="192.168.1.194"/> <constructor-arg name="port" value="6016"/> </bean> </set> </constructor-arg> </bean> |
- 注意: 在配置jedisPool时配置主机IP地址以及端口号要指定类型,否则可能报错.
第3节 与SpringBoot框架整合(Jedis)
- 添加依赖
- 创建配置类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
@Configuration public class jedisConfiguration { private static final Logger LOGGER = LoggerFactory.getLogger(jedisConfiguration.class); @Value("${redis_host}") private String host; @Value("${redis_port}") private int port; /** * 配置JedisPool */ @Bean public JedisPool getJedisPool(){ GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig(); JedisPool jedisPool = new JedisPool(poolConfig,host,port); LOGGER.info("jedis pool 创建成功 地址={}==> 端口号={}",host,port); return jedisPool; } } - 测试是否配置成功
第4节 SpringBoot中操作redis(lettuce)
1 | 官网: https://lettuce.io/ |
-
SpringBoot整合lettuce(Springboot2.x版本默认提供了redis客户端为lettuce)
1 2 3 4 5 6 7 8 9 10
<!--默认是lettuce客户端--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!-- redis依赖commons-pool2 这个依赖一定要添加 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency> -
配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# redis数据库索引 spring.redis.database=0 #redis服务器地址 spring.redis.host=127.0.0.1 #redis服务器端口号 spring.redis.port=6379 # lettuce基本配置 # Lettuce连接池,最大连接数(如若为负值表示没有限制) spring.redis.lettuce.pool.max-active=8 # 连接池最大阻塞等待时间(使用负值表示没有限制) spring.redis.lettuce.pool.max-wait=10000ms # 连接池中的最大空闲连接 spring.redis.lettuce.pool.max-idle=8 # 连接池中的最小空闲连接 spring.redis.lettuce.pool.min-idle=0 # 关闭超时时间 spring.redis.lettuce.shutdown-timeout=100ms
-
lettuce使用
spring-boot-starter-data-redis2.x提供的客户端默认是lettuce,SpringBoot redis提供了两个比较常用的操作redis数据库的模板工具分别为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | 1、RedisTemplate:
1.1 操作对象的类
1.2 线程安全
1.3 使用Java自带的序列化方式(序列化和反序列化都采用Java再带的序列化/反序列化工具)
1.4 我们也可以自定义序列化方式
1.5 默认采用jdk序列化工具,会将key和value序列化为我们不可读的数据
2、StringRedisTemplate:
1.1 是RedisTemplate的子类
1.1 操作字符串
1.2 线程安全
1.3 存储数据易读(key value 不会序列化成用户不易读数据)
3、RedisTemplate和StringRedisTemplate区别
3.1 两者数据各自存,各自取,数据不互通。
RedisTemplate不能取StringRedisTemplate存入的数据
StringRedisTemplate不能取RedisTemplate存入的数据
3.2 序列化策略不同
RedisTemplate采用JDK的序列化策略
StringRedisTemplate采用String的序列化策略
4、使用
4.1 如果你操作的是字符串类型那么使用StringRedisTemplate
4.2 如果你操作的是复杂的对象类型,那么使用RedisTemplate
|
4.1 使用StringRedisTemplate操作字符串
1 2 3 4 5 6 7 | @Autowired private StringRedisTemplate stringRedisTemplate; StringRedisTemplate对象中提供了opsForValue()进行字符串操作 当然也提供了其他数据结构类型的操作 |
4.2 使用RedisTemplate操作对象
步骤:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | 第1步: 自定义RedisTemplate模板操作对象的类型
/**
* @Description: 配置需要保存的数据类型
*/
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Serializable> redisTemplate(LettuceConnectionFactory connectionFactory) {
RedisTemplate<String, Serializable> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
//key的序列化方式,使用string类型的序列化方式
redisTemplate.setKeySerializer(new StringRedisSerializer());
//value序列化方式 采用jackson
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return redisTemplate;
}
}
第2步:操作redis数据库
@Autowired
private RedisTemplate<String,Serializable> redisTemplate;
|