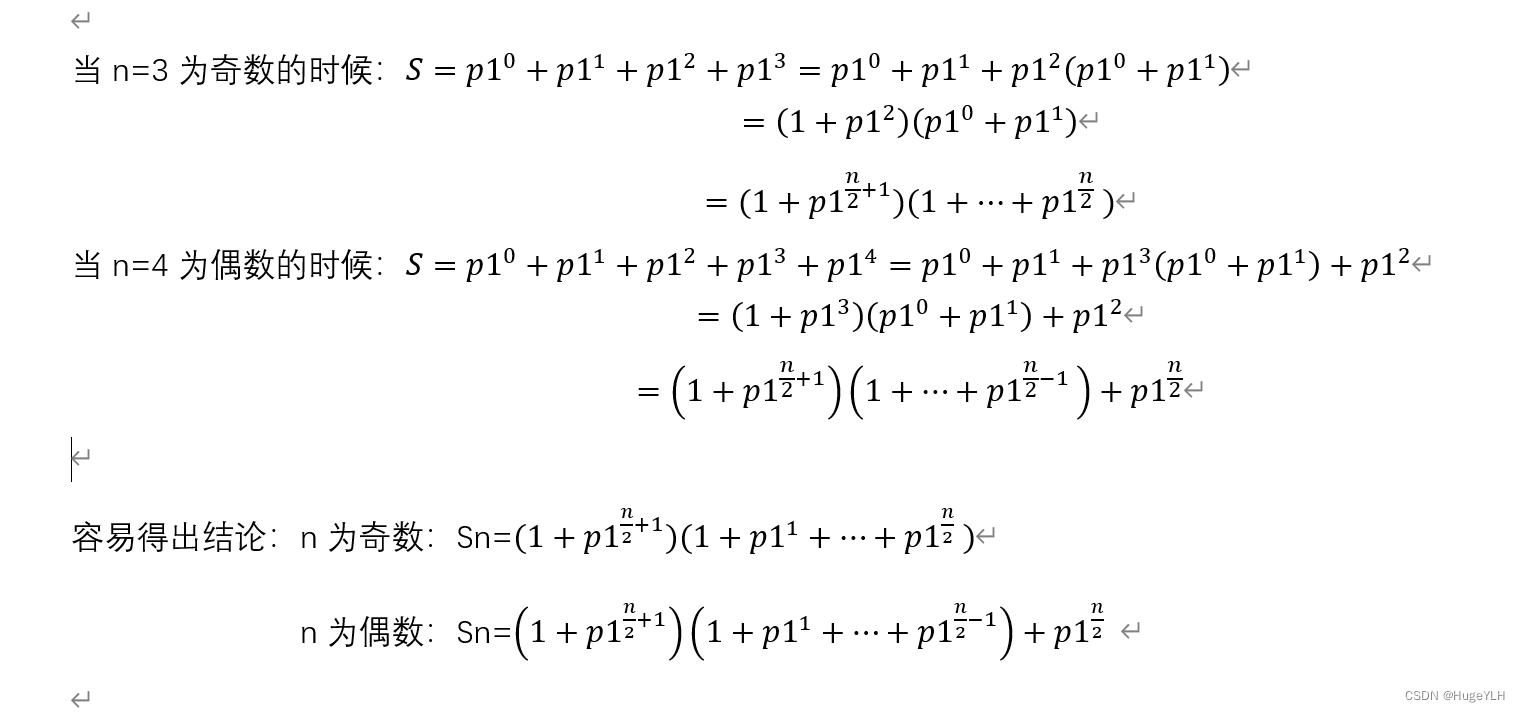目录
回顾缓冲区
标准错误流的理解
文件系统
Inode VS 文件名
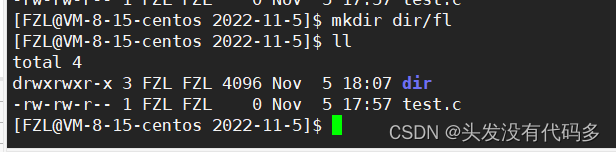
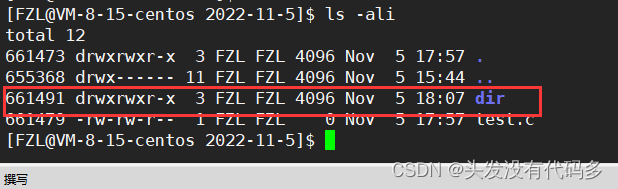
创建/删除/查看文件系统做了什么
软硬链接
动静态库
习题
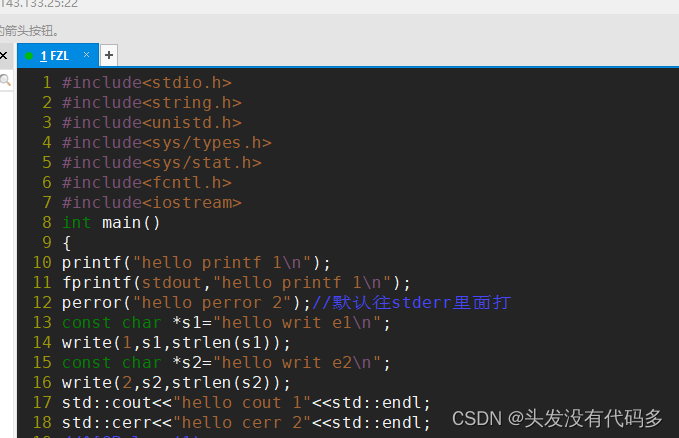
回顾缓冲区
关掉1,log.txt中没文件是因为,字符串在缓冲区当中,缓冲区还没刷新,我们把fd给关了,数据就无法刷新
刷新缓冲区
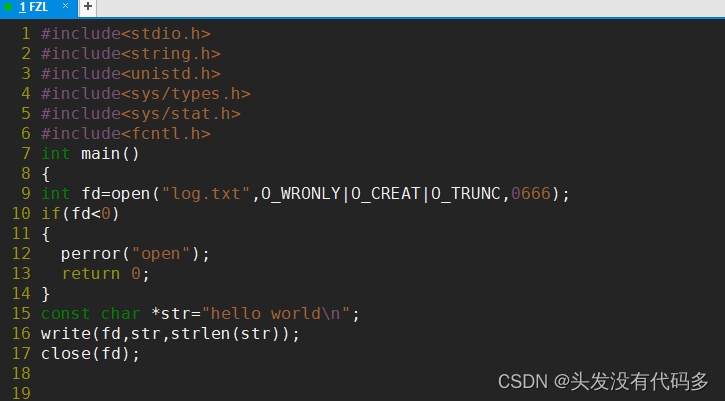
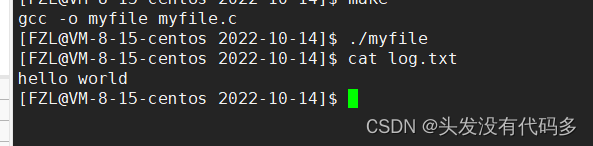
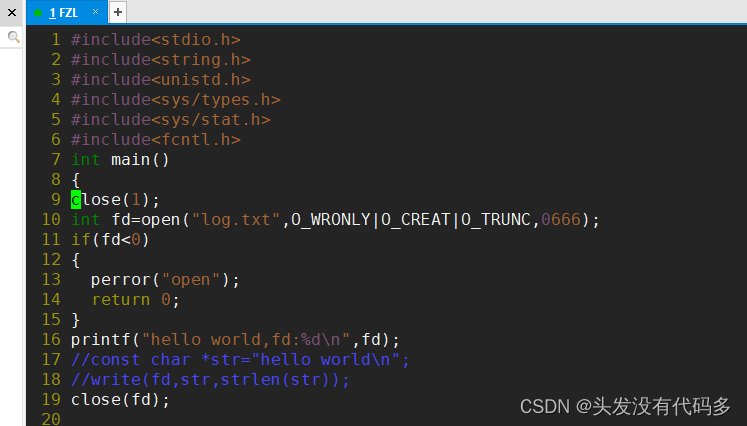

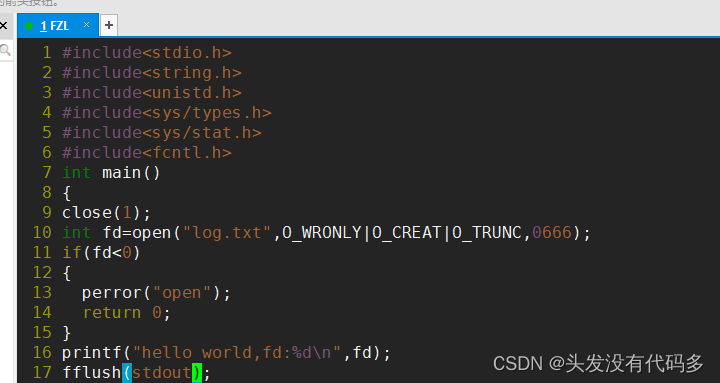
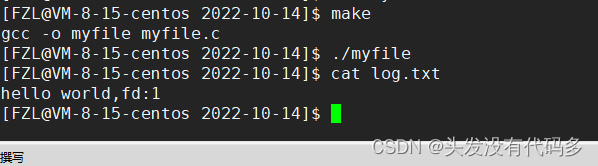
标准错误流的理解
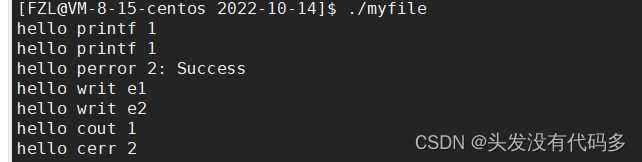
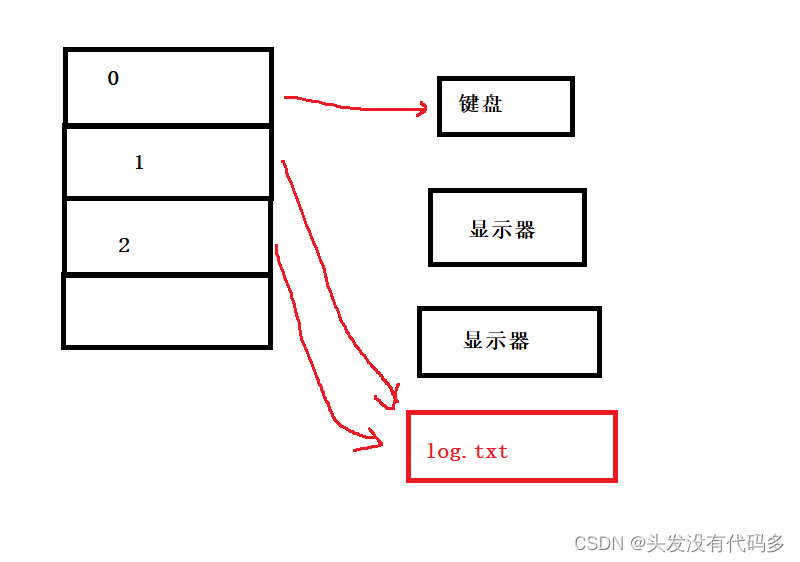
重定向到log.txt,>重定向改变的是1号文件描述符
说明了1和2号文件描述符对应的都是显示器文件,但是他们俩个是不同的,重定向一般是重定向1号文件描述符
上面我们可以看到,二号文件描述符里的内容都打印到屏幕上。
如果程序运行可能有问题的话,建议使用stderr或者cerr打印,常规文本stdout或cout打印即可
如果想经过重定向符号打印到一个文件里
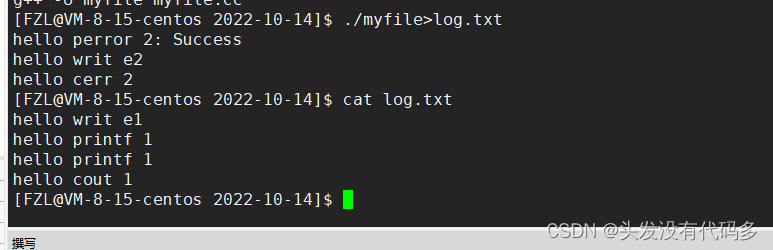
./myfile > log.txt 2>&1
含义:1重定向到log.txt,把1号文件描述符里的内容拷给2,也就是说1和2里面是同一个文件
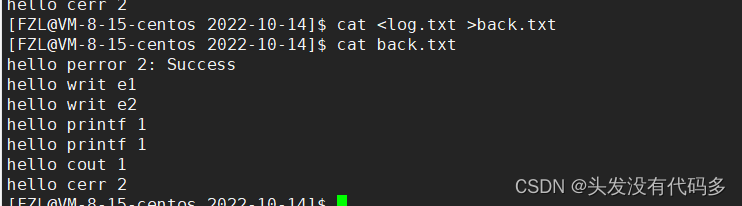
先执行输入重定向,把log.txt内容给cat,然后cat输出重定向给 back.txt
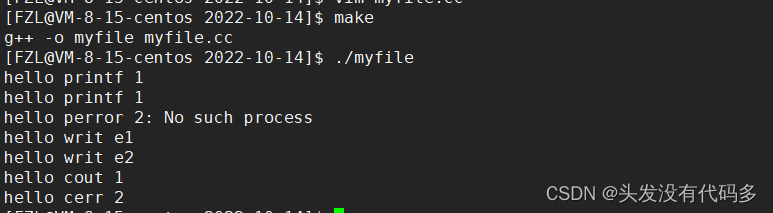
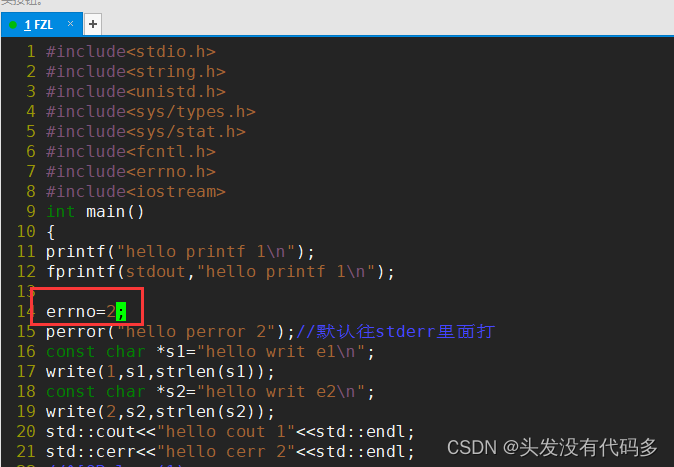
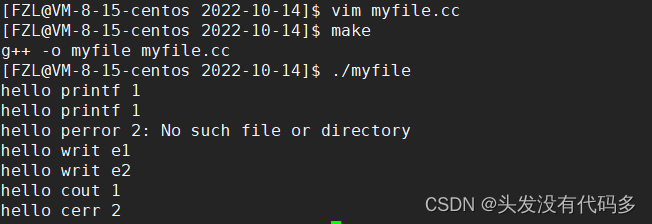
perror向2号文件描述符写入,perror会根据错误码输出错误原因。
未加errno之前perror 2:Success
把errno改为3
改为2
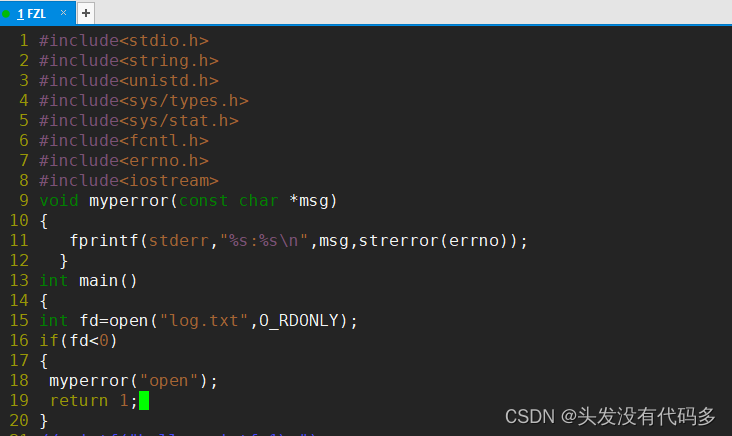
自己实现perror
删掉log.txt,再运行程序

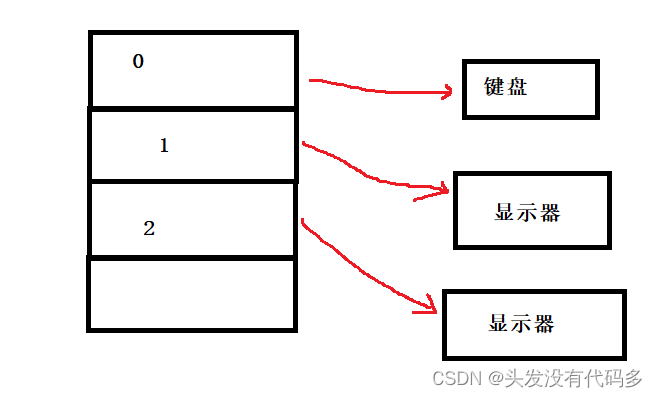
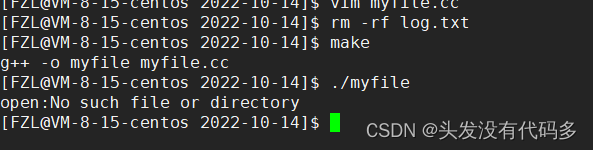
文件系统
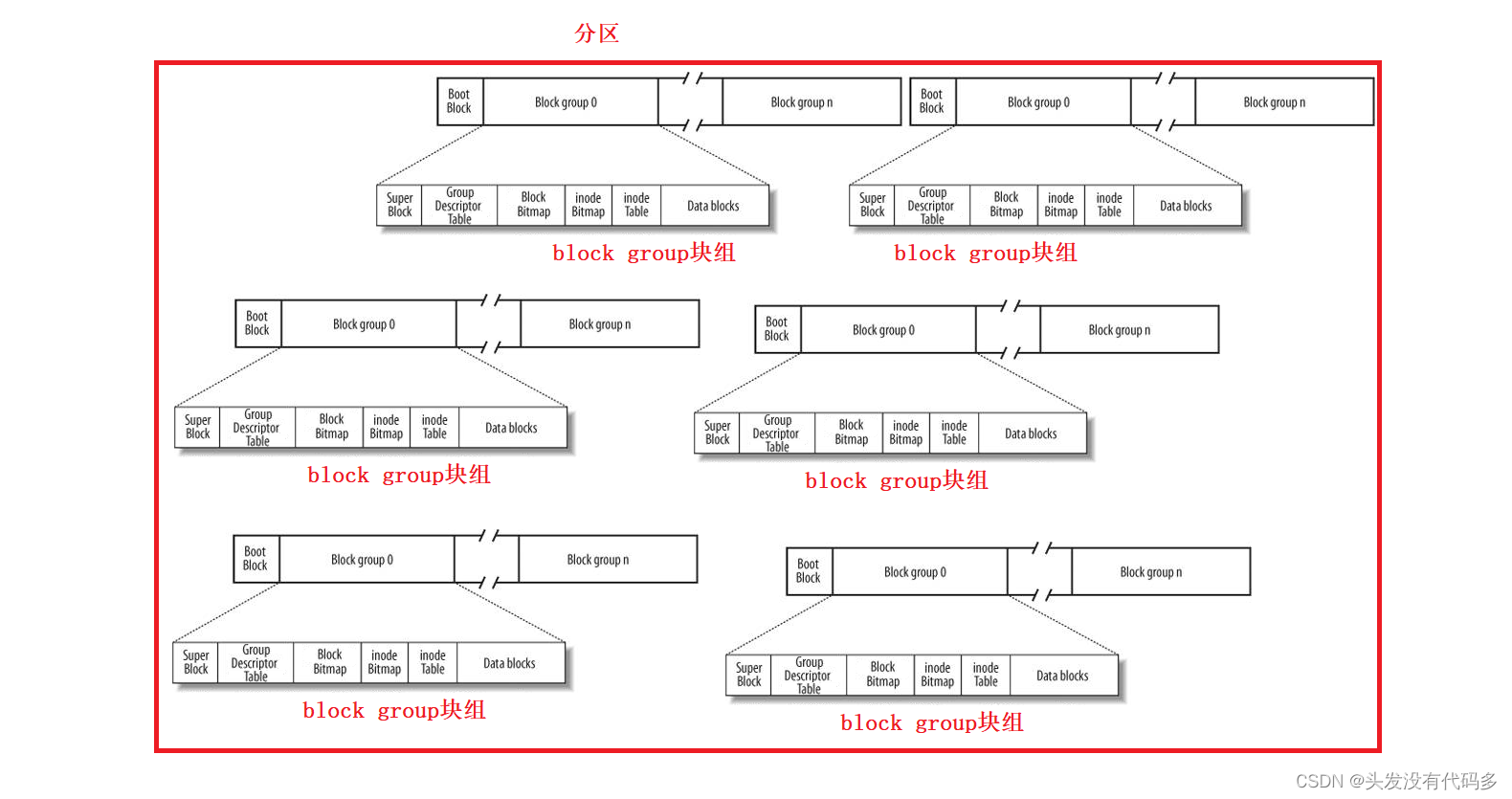
磁盘的抽象结构
SuperBlock:文件系统的属性信息(整个分区属性的属性集)。
虽然磁盘的基本单位是扇区(512字节),但是操作系统(文件系统)和磁盘进行IO的基本单位是4KB(8*512字节)
不以512字节为IO基本单位:1.512字节太小了,就需要多次IO(多次访问磁盘),导致效率降低。
2.如果操作系统使用和磁盘一样的大小,万一磁盘基本大小变了,OS的源代码肯定要改,用4KB可以将操作系统的硬件和软件进行解耦合。4kb一般为块大小,磁盘称为块设备。
Date Block:多个4KB(扇区*8)的集合,保存的都是特定文件的内容
文件=内容+属性
inodeTable:inode是一个大小为128字节的空间,里面保存的是对应文件的属性,该块组内,所有文件的inode空间的集合,需要标识唯一性,每一个inode块,都要有一个inode编号。一般而言一个文件,一个inode,一个inode编号。
BlockBItmap:假设有10000+个blocks,BlockBitmap里面就有10000+个比特位,比特位和特定的block是一 一对应的,比特位位1,代表该block被占用,否则表示可用。
Inode Bitmap:假设有10000+个节点,Inode Bitmap就有10000+个比特位,比特位和特定的inode是一 一 对应的,其中bitmap中比特位为1,代表该inode被占用,否则表示可用。
GDT:块组描述符,这个块组多大,已经使用多少了,有多少Inode,已经占用多少个,还剩多少,已经使用多少block,还剩多少……
这些信息可让一个文件的信息可追溯,可管理。
我们将块组分割称为上面的内容。并且写入相关的数据,每一个块组都这么干,整个分区就被写入了文件系统信息。这个过程就叫格式化
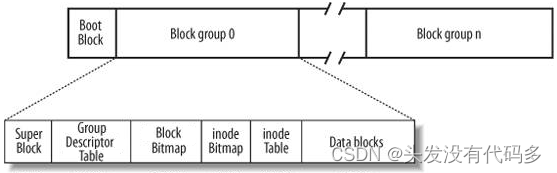
一个文件“只”对应一个inode属性节点,inode编号。
一个文件可以有多个data block
哪些block属于同一个文件?找到文件,只要找到该文件对应的inode编号,就能找到该文件的inode属性,可是文件的内容呢?
Inode属性里面有一个数组,数组里面的内容就是我们用到了哪些Data block。我们可以通过数组找到,数组和磁盘块建立了映射关系
因此,只要找到Inode编号,就能找到Inode,找到Inode就能找到对应的数据块,此时属性+内容全部找到,就能对文件进行读取
data block中,不是所有的data block,只能存文件数据,也可以存其它块的块号,当文件内容较大时,会有一个或多个块信息,这些信息指向其它的数据块,而我们通过找到其它的数据块就能找到文件内容,这就是对于较大文件的存储方式
Inode VS 文件名
要找到文件就要先找Inode编号, 在特定的分区当中Inode在分区内有效,
Inode编号->分区特定的bg(block group)->inode->属性->内容
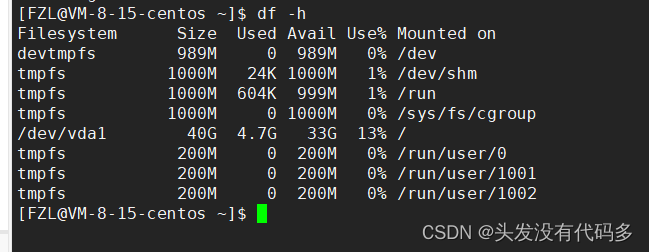
df -h查看自己在哪个分区
用户如何知道Inode编号?
依托于目录结构,目录当中保存了对应的某个文件
Linux中,Inode属性中,没有文件名的说法(Inode属性不保存文件名)。
预备知识:1.一个目录下,可以保存很多文件,但这些文件名不重复,
2.LInux下一切皆文件,目录也是文件,目录也有自己的Inode,有自己的data block,目录的data block中存的是文件名和对应的Inode编号的映射关系。
Inode和文件名互为Key值。
创建文件的时候把文件的Inode编号和文件名写入到目录的Data block中,建立映射关系。因此对目录具有写权限,才可以创建文件。
当用ls显示文件名的时候,为什么要在目录里面有r权限?
因为要去目录的内容里拿文件名,如果要拿到文件属性,先取去目录里拿到文件名,再通过映射关系找到Inode,之后去分区中找到文件的各种属性。
创建/删除/查看文件系统做了什么
创建文件:用户提供文件名,文件系统创建好文件并且返回Inode,给这俩者建立映射关系写到目录内容当中,其实就是找到目录的编号Inode(这个Inode是目录的Inode),之后找到它的数据块,把内容写入即可。
删除文件:用户提供文件名,文件系统会根据文件名找到Inode,根据Inode找到对应的块组,把InodeBitmap由1置为0,BlockBitmap也由1置0,再从目录中去掉这种映射关系,此时就代表删掉了。删除后的文件能恢复前提:能找到该文件的Inode(该Inode编号,没有被使用,Inode和datablock未被占用)
查看文件:找到文件名通过映射找到Inode,把内容显示出来即可。
格式化就是在磁盘写入文件系统。
Inode是固定的,datablock是固定的。
有时候创建文件失败的原因是因为Inode还有,但没有databolck或没有databolck但是又有Inode
软硬链接
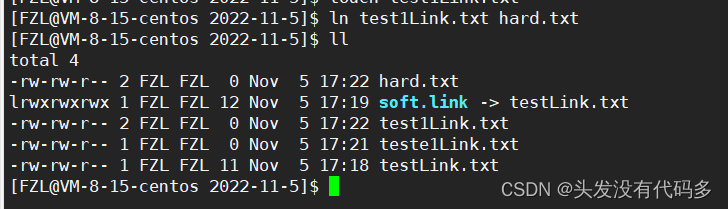
ls -i会显示Inode
创建一个软链接 ln -s
这里soft.link 是指向testLink.txt的软链接
这是在创建一个硬链接
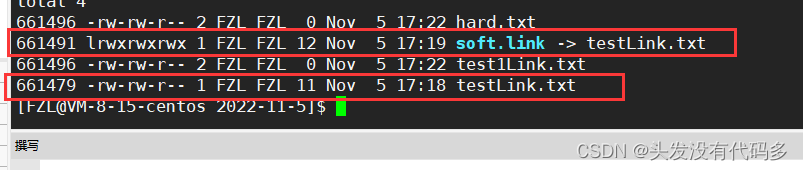
软链接有自己独立的Inode
建立完硬链接后,这里变为2,之前是1,而且这里硬链接的Inode是661496和test1Link.txt的Inode一样
结论:软链接有独立的Inode->软链接是一个独立的文件,硬链接没有独立的Inode->硬链接不是一个独立的文件
软链接就如同windows下的快捷方式,不需要输入具体路径,可直接运行
软链接特性:软链接的文件内容,是指向的文件对应的路径。
硬链接:创建硬链接,就是在指定的目录下建立了文件名和指定Inode的映射关系。就是起别名。
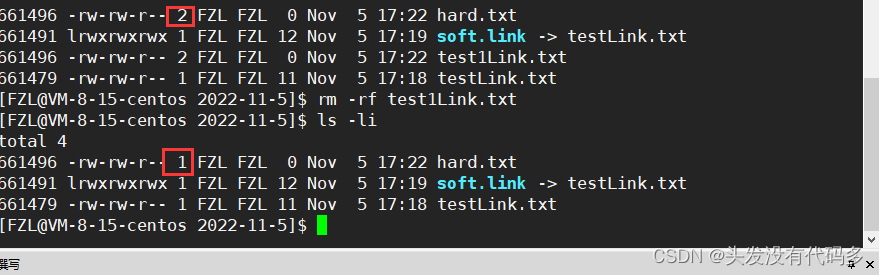
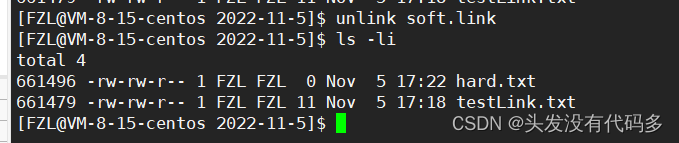
删除test1Link.txt之后并不影响hard.txt的存在,这里由2变为1,而且我们发现Inode此时还在。
这是因为刚才在删的时候,把test1Link.txt的Inode和文件名的映射关系在目录里去掉了,但Inode还在,而这里由2变1的数字被称作硬链接数
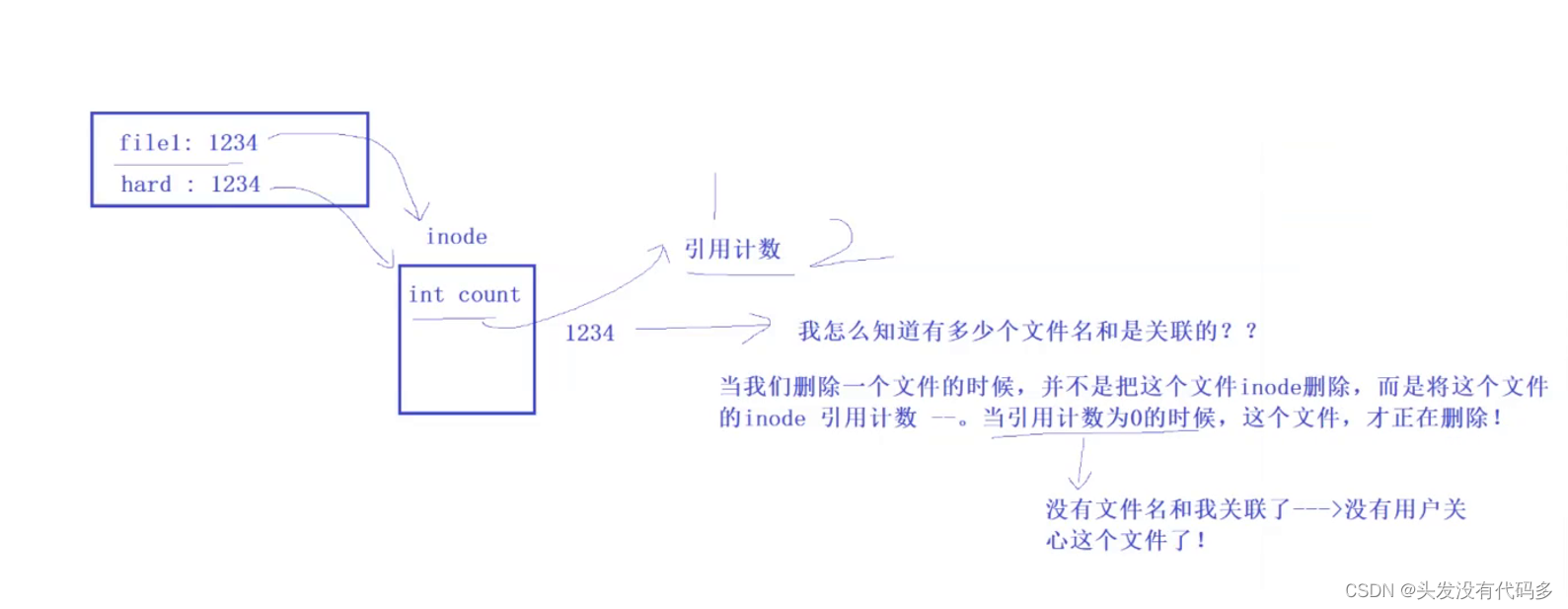
引用计数是用来记录多少个文件和Inode进行关联的
删除软硬链接用unlink
把文件全删光,再创建一个新的文件,创建的新文件默认的引用计数是1,自己的文件名和Inode形成了映射
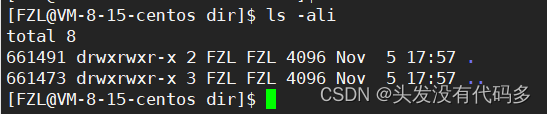
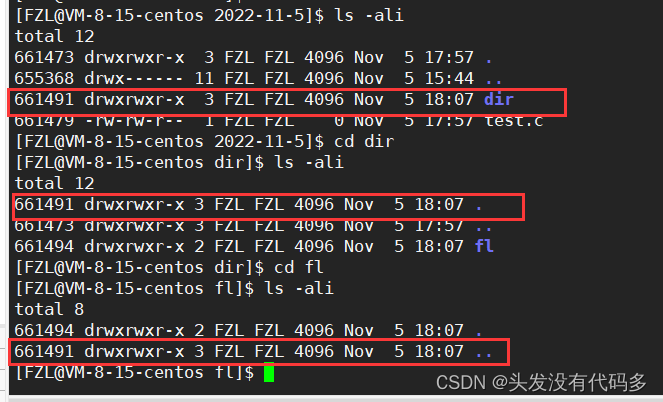
空目录的默认引用计数是2,目录首先和Inode建立映射关系,进入目录后可以看到.和..
.和..也是文件名,.和dir对应的Inode一样
此时在dir里面创建一个目录,引用计数又成为了3
我们发现fl里面的..对应的Inode和dir对应的Inode一样,这是因为fl的..指向上一级路径,也就是dir


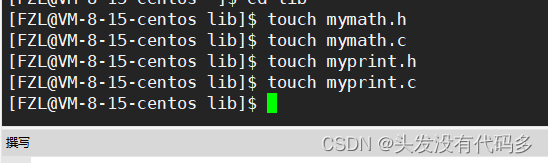
动静态库
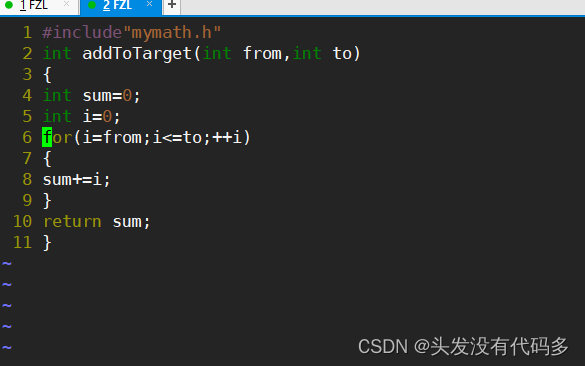
先创建四个文件,在.h中声明,在.c中实现,写一些简单的程序
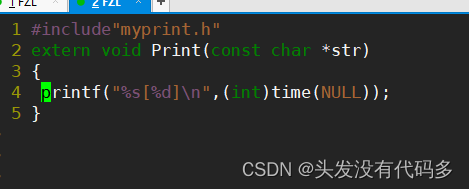
myprint.c
mymath.c
注意:要写库,库里面不能有main函数
我们使用time函数,获得时间戳
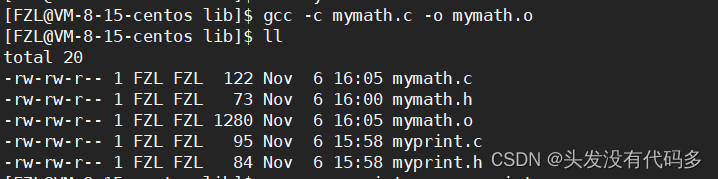
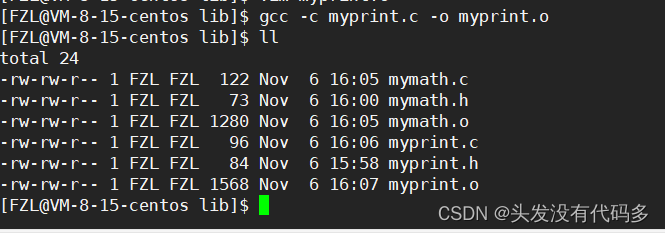
生成.o文件
如果把.o和.h给别人,别人是能使用的
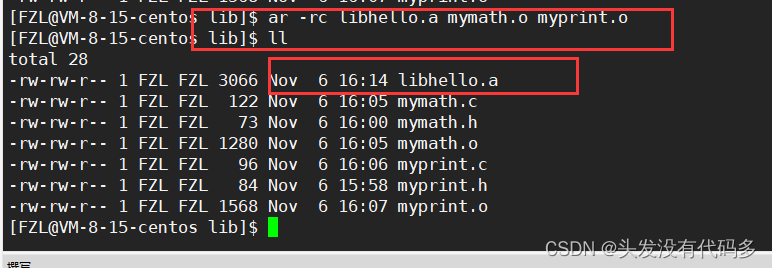
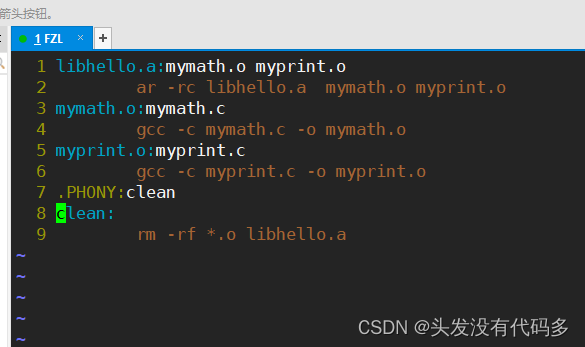
这里有俩个.o文件,我们可以把这俩个.o文件打包,打包的过程就叫形成静态库
打包命令ar -rc lib+库名.a
ar归档的意思
r替换,c创建,这里要创建库名字,库名字前缀必须是lib,后缀必须是.a
打包后生成.a文件
静态库制作:源文件变成.o,打包后变为.a文件
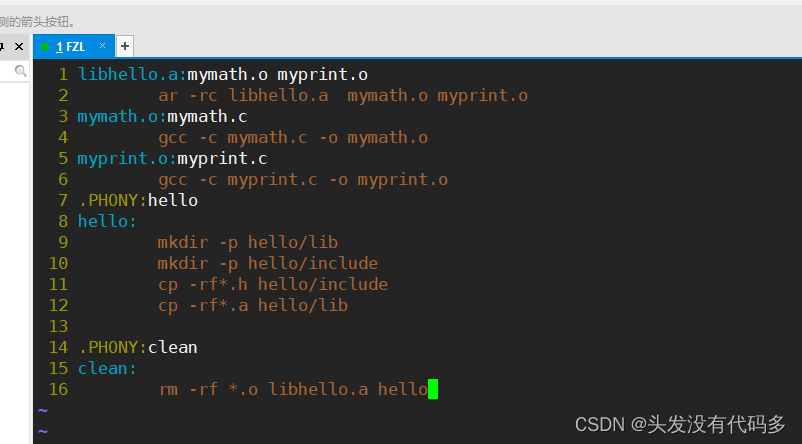
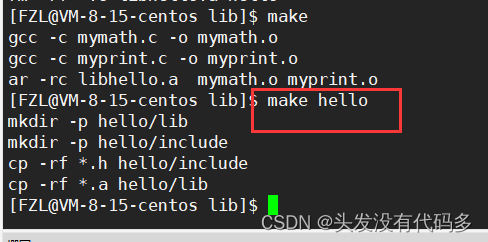
创建一个makefile文件
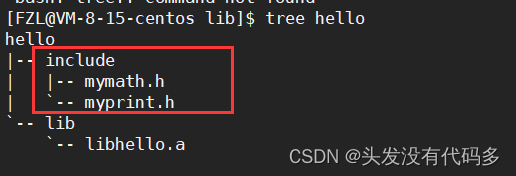
库通常是有头文件和对应的库文件,因此我们创建一个目录(目录名就叫hello),该目录下有俩个文件,一个存放库的头文件,另一个存放对应的库文件
红框部分叫发布
include里面存的是对应的库头文件,lib是库文件
此时库已经被打包好了,我们要给别人使用
我们把它拷贝到上级目录的一个文件夹下
进入该目录后,可看到我们打包的库
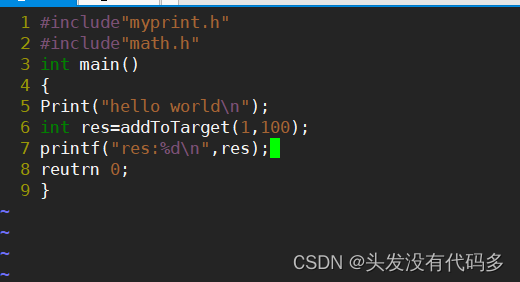
创建一个main.c的文件,这是main.c的文件内容
把库拷贝到系统路径下,头文件gcc的默认搜索路径是:/usr/include
库文件的默认搜索路径是:/lib64或usr/lib64
先把hello/include路径下的所有文件,拷贝到/usr/include路径下
此时hello/include路径下的文件就被拷贝到了系统里
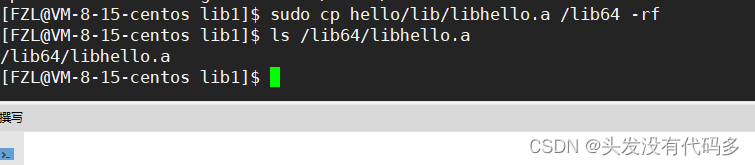
库文件也拷贝过去
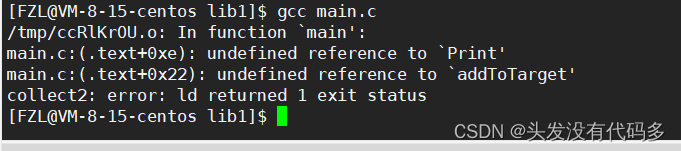
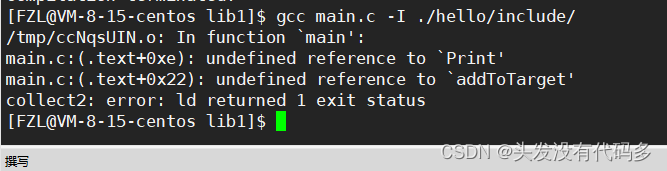
但此时输入gcc main.c系统仍然报错
这是因为我们自己所写的库,属于第三方库(不是语言库也不是系统库),C语言的静态库默认为lib64/libc.a,这里报错是因为没有告诉gcc我们要链接哪个库
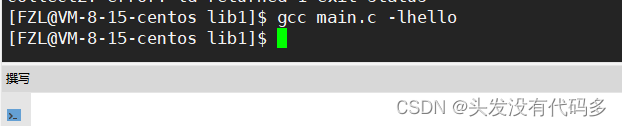
输入gcc main.c -lhello ,注意这里要加l去掉库前缀和后缀,即l后直接加库名字
输入./a.out即可运行程序,这就是静态库的使用
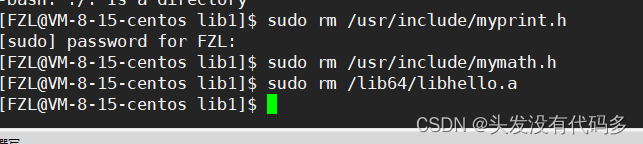
把所需要的库拷贝到默认路径下,就叫做库的安装,我们一般不要把自己的库安装到系统路径下。
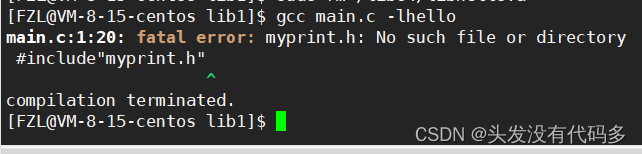
把库删掉之后,使用时就会报错,这里报错信息为这个头文件找不到
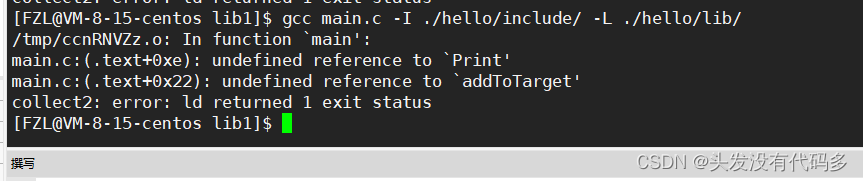
编译器默认在系统路径和当前路径下找头文件,-I 在指定路径下找头文件,加上-I之后还是会报错,但是跟刚才的报错有点差别,这是因为此时找到了头文件,但是找不到对应的库,我们的库没有在系统默认路径下安装,我们得告诉编译器去哪里找库
-L去指定路径下搜索库文件
我们已经声明去哪里找头文件和库了,但此时还会报错,这是因为我们无法保证lib路径下只有一个库,我们没有告诉编译器是lib路劲下得哪一个库,用-l(小写L)
加-lhello 去掉库的前缀和后缀
总结:-I 头文件搜索路径
-L 库文件搜索路径
-l在特定路径下,使用某个具体的库






习题
下面关于Linux文件系统的inode描述错误的是:A
A.inode和文件名是一一对应的
B.inode描述了文件大小和指向数据块的指针
C.通过inode可获得文件占用的块数
D.通过inode可实现文件的逻辑结构和物理结构的转换
A选项错误,这里说的文件名指的是文件的目录项,一个文件inode是有可能有多个目录项的,比如给一个文件创建多个硬链接,因此并非一一对应
B选项正确,inode中包含了文件的各种描述信息,权限,大小,时间属性,数据块指针....等等都包含在内
C选项正确,inode中包含了文件数据所占据的存储位置的信息,因此可以获得we你按占用的数据块数
D选项正确,inode就像是文件的一个整体的描述,有了这个描述,上层就可以重新组织虚拟逻辑结构,通过inode映射其物理结构(简单理解可以联想类似于虚拟地址空间与物理内存之间的页表)
查看文件file的inode号,正确的是:C
A.ls -l file
B.ls -a file
C.ls -i file
D.ls -d file
ls常见选项:
- -l 表示查看文件详细信息
- -a 表示查看所有包含以 . 开头的文件(隐藏文件)
- -i 打印每个文件的inode索引号
- -d 针对目录产生效果,表示查看目录文件自身信息,而并非目录内的文件信息
使用In命令将生成了一个指向文件old的符号链接new,如果你将文件old删除,是否还能够访问文件中的数据? A
A.不可能再访问
B.仍然可以访问
C.能否访问取决于文件的所有者
D.能否访问取决于文件的权限
ln生成符号链接文件,指的是通过 ln -s 命令生成软链接文件,
软链接文件是一个独立的文件,有自己的inode节点,这个文件数据中保存的是源文件路径,通过保存的路径访问源文件,因此源文件被删除则无法再访问,通过路径将找不到源文件,这时候软链接就会失效。
根据以上对于软链接的理解,A选项正确,其他选项都错误
Linux中包括两种链接:硬链接(Hard Link)和软连接(Soft Link),下列说法正确的是(A)
A.软连接可以跨文件系统进行连接,硬链接不可以
B.当删除原文件的时候软连接文件仍然存在,且指向的内容不变
C.硬链接被删除,磁盘上的数据文件会同时被删除
D.硬链接会重新建立一个inode,软链接不会
软链接文件是一个独立的文件有自己的inode节点,文件中保存了源文件路径,通过数据中保存的源文件路径访问源文件
硬链接是文件的一个目录项,与源文件共用同一个inode节点,直接通过自己的inode节点访问源文件(其实本质上来说与源文件没区别)
- A正确 不同分区有可能有不同文件系统,就算系统相同,也会导致节点号有歧义冲突,因此硬链接不能跨分区建立,正确
- B错误 删除源文件,软链接文件失效
- C错误 硬链接被删除,则inode中的链接数-1,并不会直接删除文件数据,而是等链接数为0的时候才会实际删除对应文件的inode,将所占用数据块置为空闲
- D错误 硬链接与源文件共用inode