一、Hadoop
1、Hadoop大数据框架,处理分布式环境下数据存储和计算
2、Hadoop的HDFS处理存储
3、Hadoop的MapReduce处理计算
map让任务数据拆分到每一台去执行
reduce处理后的任务合并
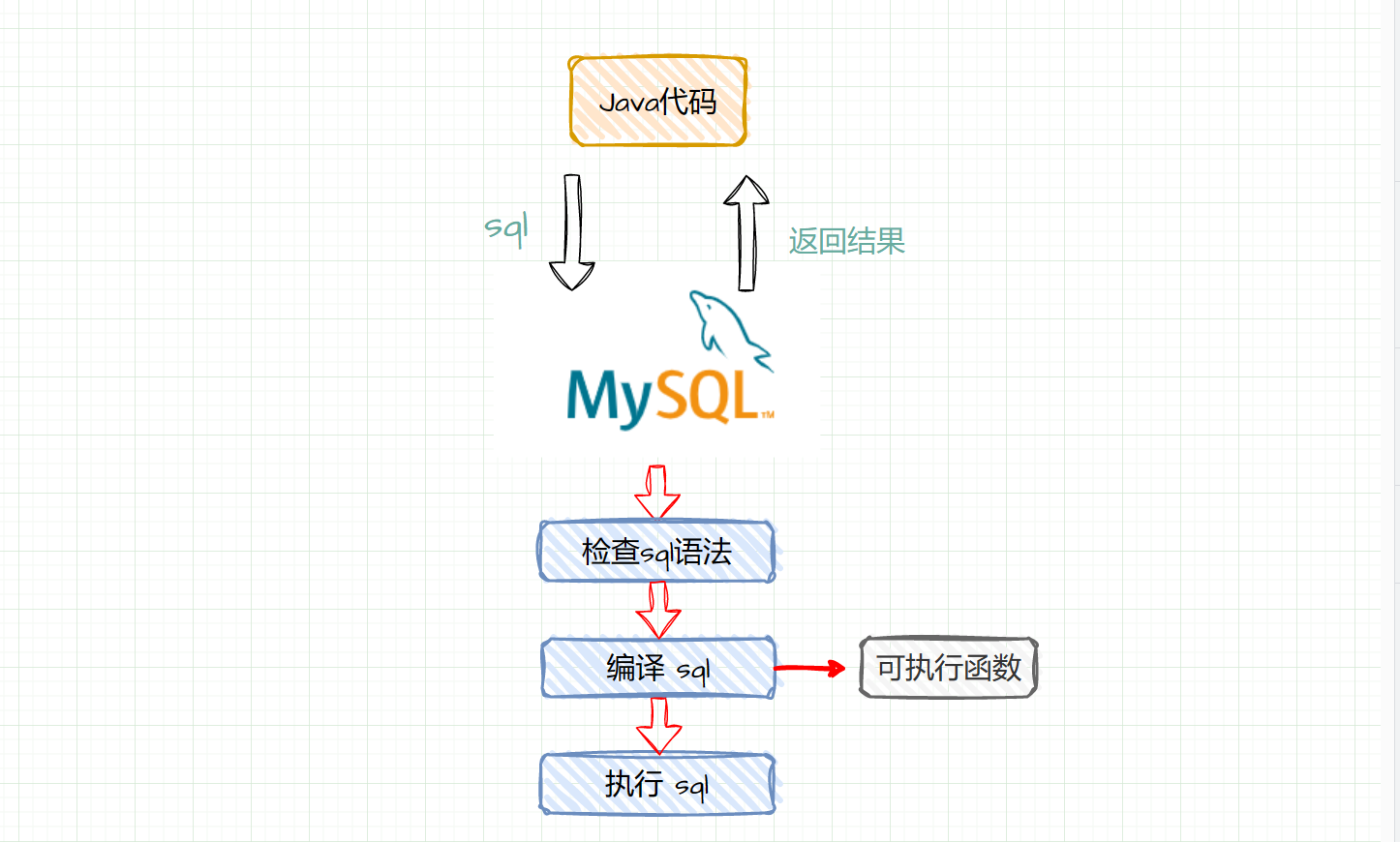
4、Hive作用是在Hadoop上能够让用户来写SQL处理数据
Hive的执行引擎,会把SQL语句翻译成一个MapReduce的任务去执行
二、Spark
1、Spark本身也是一个计算框架,它和Hadoop的MapReduce对比(相当于MapReduce升级版)。不同点是Spark是一个基于内存的计算,MapReduce是基于磁盘的计算,Spark速度会比Hadoop快2-3倍
2、Spark也有Spark SQL的这个模块,让用户在Spark的API上面去写SQL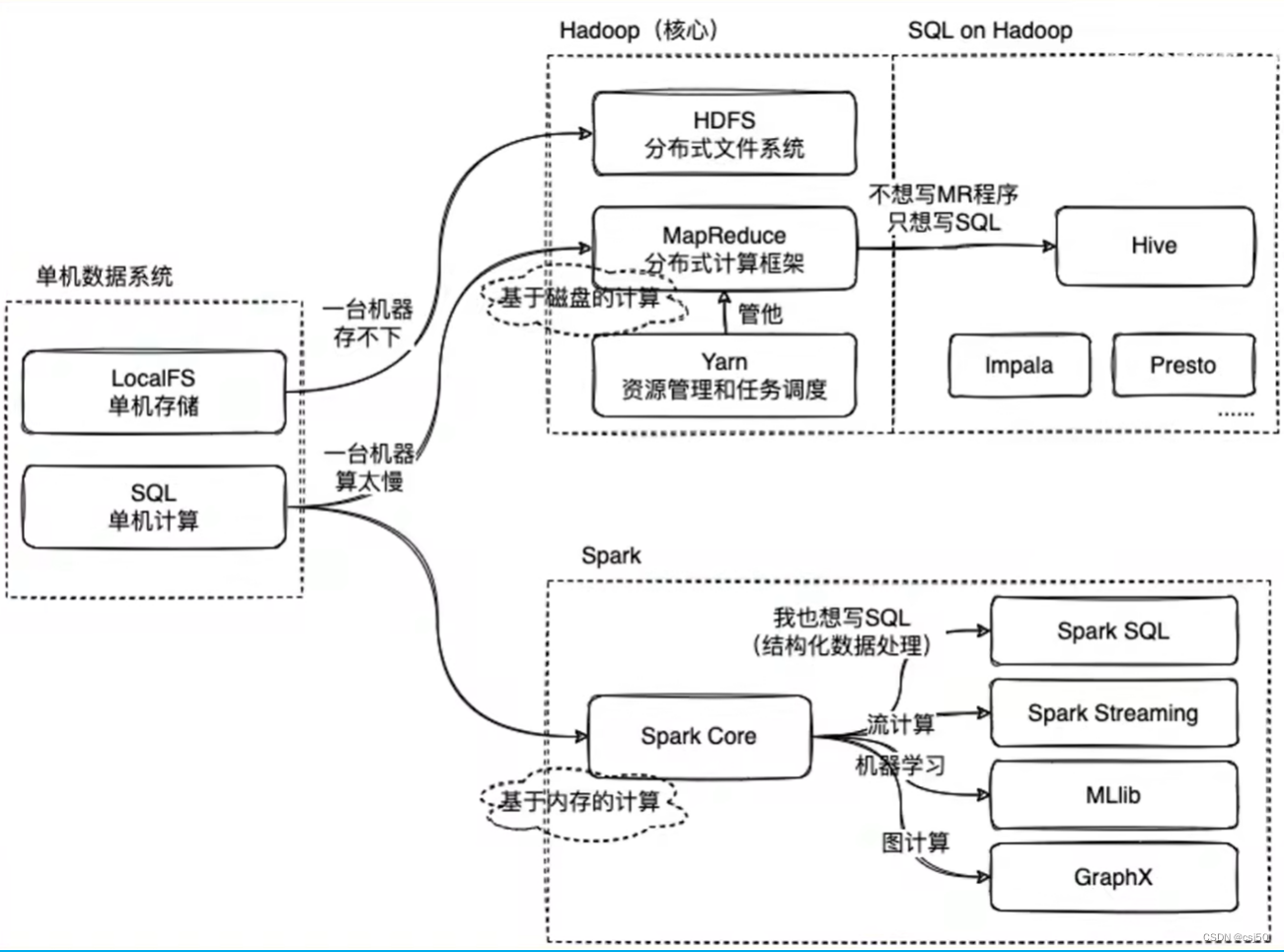
三、Hadoop的HDFS
1、Hadoop的分布式文件存储系统
2、数据分布在许多计算机中以块的形式存储,但是用户看起来就是一块磁盘
四、Hadoop的MapReduce
MapReduce将数据分成多个部分,并在不同的数据节点上分别处理每个部分,然后将各个结果汇总并输出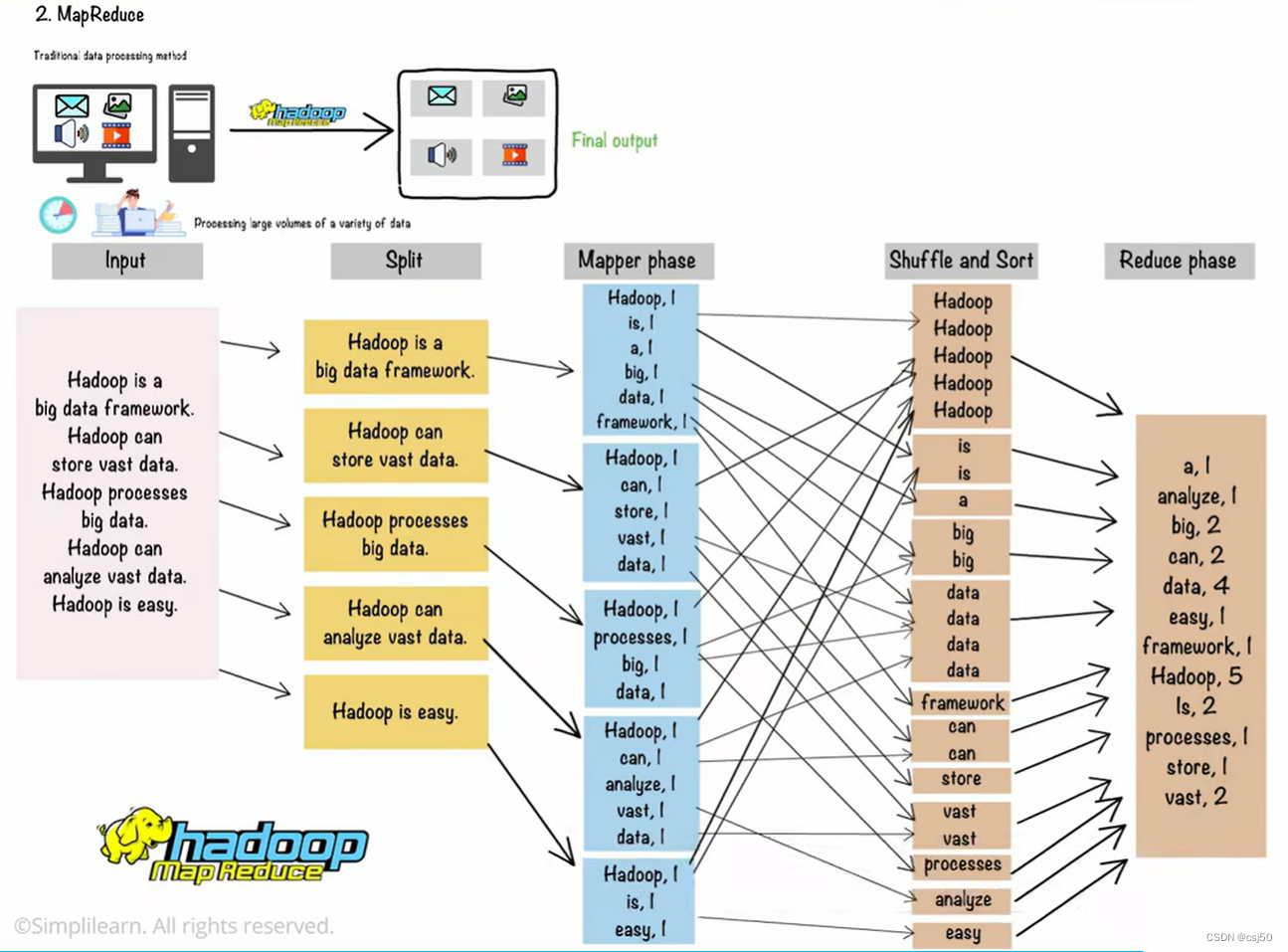
五、Hadoop的Yarn
1、资源管理器:分配资源
2、节点管理器:处理节点并监控节点中的资源使用情况
3、应用管理器:管理应用
4、容器:包含物理资源的集合

5、处理创建的MapReduce任务
(1)应用管理器从节点管理器请求容器
(2)节点管理器获得资源后,将它们发送给资源管理器
(3)这样Yarn在Hadoop中就可以处理任务请求并管理集群资源
六、Hadoop其他管理、处理、分析工具
Hive、Pig、Spark、Flume、Scoop等等
七、Flink
用于实时计算,可以与yarn集成
八、Hbase
用于海量存储