写在前面
手撕Pytorch源码系列目的:
通过手撕源码复习+了解高级python语法
熟悉对pytorch框架的掌握
在每一类完成源码分析后,会与常规深度学习训练脚本进行对照
本系列预计先手撕python层源码,再进一步手撕c源码
版本信息
python:3.6.13
pytorch:1.10.2
本博文涉及python语法点
json库的使用
pickle库的使用
__reduce__方法与__reduce_ex__方法
*args与**kwargs
@classmethod
目录
[TOC]
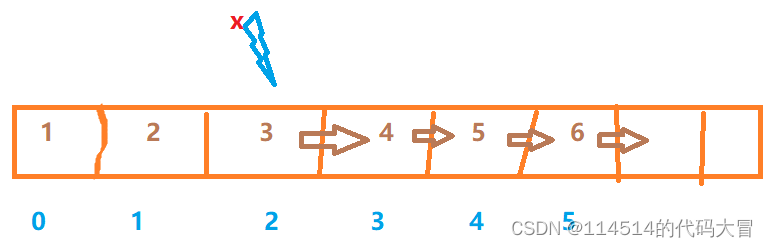
零、流程图
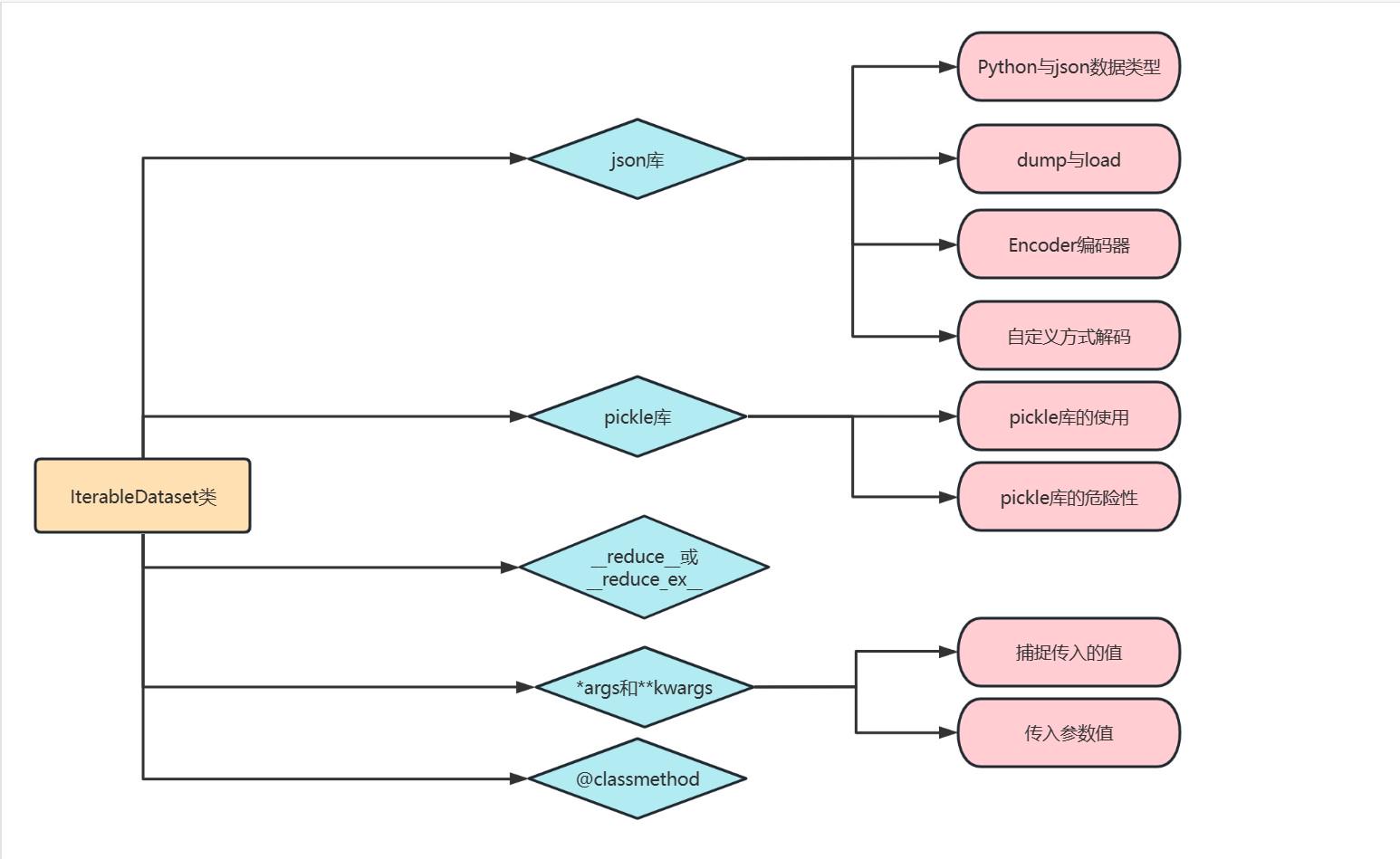
一、填坑python高级语法点
1.1 Json库的使用
1.1.1 Json的数据类型与Python数据类型
Python | Json |
dict | object |
list,tuple | array |
str | string |
int,float,... | number |
True | true |
False | false |
None | null |
Json对象都是小写的,而Python的True,False,None都是大写开头的,注意区分
Python字典对象中所有键值都是单引号格式的,而Json对象中所有键值都是双引号格式的
pydict = {
"Pytorch":"1.10.2",
"Python":"3.6.13",
"Other_lib":["numpy","pandas","matplotlib",'sklearn']
}
pyjson = json.dumps(pydict,indent=4,sort_keys=True)
print("pydict: {}".format(pydict))
print("pyjson: {}".format(pyjson))
# 输出结果为:
# pydict: {'Pytorch': '1.10.2', 'Python': '3.6.13', 'Other_lib': ['numpy', 'pandas', 'matplotlib', 'sklearn']}
# pyjson: {
# "Other_lib": [
# "numpy",
# "pandas",
# "matplotlib",
# "sklearn"
# ],
# "Python": "3.6.13",
# "Pytorch": "1.10.2"
# }1.1.2 dump和load操作
json.dumps是将python对象转化成json字符串对象
pydict = {
"Pytorch":"1.10.2",
"Python":"3.6.13",
"Other_lib":["numpy","pandas","matplotlib",'sklearn']
}
# indent = 4是为了让显示出的格式更好看
# sort_keys = True为了给Key排序
pyjson = json.dumps(pydict,indent=4,sort_keys=True)
print("pydict: {}".format(pydict))
print("pyjson: {}".format(pyjson))
print("type of pydict is {}".format(type(pydict)))
print("tyoe of pyjson is {}".format(type(pyjson)))
# 输出结果为:
# pydict: {'Pytorch': '1.10.2', 'Python': '3.6.13', 'Other_lib': ['numpy', 'pandas', 'matplotlib', 'sklearn']}
# pyjson: {
# "Other_lib": [
# "numpy",
# "pandas",
# "matplotlib",
# "sklearn"
# ],
# "Python": "3.6.13",
# "Pytorch": "1.10.2"
# }
# type of pydict is <class 'dict'>
# tyoe of pyjson is <class 'str'>json.dump将python对象转化成json文件
with open(".\\Deep-Learning-Image-Classification-Models-Based-CNN-or-Attention\\手撕Pytroch第四期\\data.json","w") as f:
json.dump(pydict,indent=4,fp=f)
f.close(){
"Pytorch": "1.10.2",
"Python": "3.6.13",
"Other_lib": [
"numpy",
"pandas",
"matplotlib",
"sklearn"
]
}json.loads将json字符串对象转化成python对象
pyobj = json.loads(pyjson)
print("pyobj:{}".format(pyobj))
print("type of pyonj is {}".format(type(pyobj)))
# 输出结果为:
# pyobj:{'Other_lib': ['numpy', 'pandas', 'matplotlib', 'sklearn'], 'Python': '3.6.13', 'Pytorch': '1.10.2'}
# type of pyonj is <class 'dict'>
jsonstr = '["1","2",{"Version":"1.10.2","download":true}]'
pyobj_ = json.loads(jsonstr)
print("pyobj_:{}".format(pyobj_))
print("type of pyonj_ is {}".format(type(pyobj_)))
# 输出结果为:
# pyobj_:['1', '2', {'Version': '1.10.2', 'download': True}]
# type of pyonj_ is <class 'list'>json.load将json文件解码为python对象
with open(".\\Deep-Learning-Image-Classification-Models-Based-CNN-or-Attention\\手撕Pytroch第四期\\data.json","r") as f:
pyobj_file = json.load(fp=f)
f.close()
print("pyobj_file:{}".format(pyobj_file))
print("type of pyonj_file is {}".format(type(pyobj_file)))
# 输出结果为:
# pyobj_file:{'Pytorch': '1.10.2', 'Python': '3.6.13', 'Other_lib': ['numpy', 'pandas', 'matplotlib', 'sklearn']}
# type of pyonj_file is <class 'dict'>1.1.3 Encoder编码器
json库的默认编码器encoder不能编码自定义的类型,代码如下:
class Lib():
def __init__(self,data:str) -> None:
self.data = data
def __repr__(self) -> str:
return str(self.data)
pydict = {"name":Lib("Pytorch"),"version":"1.10.2"}
json.dumps(pydict,indent=4)
# 代码报错如下:
# TypeError: Object of type Lib is not JSON serializable需要自己定义解码方式,需要继承json.JSONEncoder类,并且重载default方法,代码如下:
class Lib():
def __init__(self,data:str) -> None:
self.data = data
def __repr__(self) -> str:
return str(self.data)
pydict = {"name":Lib("Pytorch"),"version":"1.10.2"}
class Jsonencode(json.JSONEncoder):
def default(self, o: typing.Any) -> typing.Any:
if isinstance(o,Lib):
# 相当于调用了__repr__方法
return str(o)
return super(self).default(o)
pyjson_encode = json.dumps(pydict,cls = Jsonencode,indent=4)
print("pyjson_encode:{}".format(pyjson_encode))
# 输出结果为:
# pyjson_encode:{
# "name": "Pytorch",
# "version": "1.10.2"
# }1.1.4 object_hook自定义方式解码(Specializing JSON object decoding)
在使用json.load函数时,可以自定义解码方式,示例代码如下:
# 用object_hook解码(Specializing JSON object decoding)
def as_complex(dct:typing.Dict)->typing.Union[typing.Dict,complex]:
if "__complex__" in dct:
return complex(dct["real"],dct["imag"])
return dct
pyobj_decode = json.loads('{"__complex__":true,"real":2,"imag":1}',object_hook=as_complex)
print("pyobj_decode:{}".format(pyobj_decode))
# 输出结果为:
# pyobj_decode:(2+1j)1.2 pickle库
1.2.1 pickle库的使用
pickle库和json库的作用类似,都是对数据进行序列化和反序列化的操作,但是由于json与编程语言无关,因此对python数据的支持较弱,而pickle库则对python各种数据类型有较强的支持性
json文件是可读性较强的字符串格式,而pickle则是可读性较弱的二进制格式,因此在使用open()函数时,写入和读取的模型应该分别为:wb和rb
pickle数据类型与json数据类型的相互编码解码同样由四个函数完成pickle.dumps(),pickle.dump(),pickle.loads(),pickle.load()
上述四个函数的使用如下:
import pickle
# pickle.dumps()
class Lib():
def __init__(self,name) -> None:
self.name = name
pydict = {'name':Lib("Pytorch"),"version":"1.10.2"}
pypickle = pickle.dumps(pydict)
print(f"pypickle : {pypickle}")
print(f"type of pypickle : {type(pypickle)}")
# 输出结果为:
# pypickle : b'\x80\x04\x95E\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x08__main__\x94\x8c\x03Lib\x94\x93\x94)\x81\x94}\x94h\x01\x8c\x07Pytorch\x94sb\x8c\x07version\x94\x8c\x061.10.2\x94u.'
# type of pypickle : <class 'bytes'>
# pickle.dump()
with open(".\\Deep-Learning-Image-Classification-Models-Based-CNN-or-Attention\\手撕Pytroch第四期\\data.pickle","wb") as f:
pickle.dump(pydict,f)
f.close()
# pickle.loads()
pydict_ = pickle.loads(pypickle)
print(f"pydict_ : {pydict_}")
print(f"type of pydict_ : {type(pydict_)}")
# 输出结果为:
# pydict_ : {'name': <__main__.Lib object at 0x0000022C97E65F70>, 'version': '1.10.2'}
# type of pydict_ : <class 'dict'>
# pickle.load()
with open(".\\Deep-Learning-Image-Classification-Models-Based-CNN-or-Attention\\手撕Pytroch第四期\\data.pickle","rb") as f:
pydict_ = pickle.load(f)
f.close()
print(f"pydict_ : {pydict_}")
print(f"type of pydict_ : {type(pydict_)}")
# 输出结果为:
# pydict_ : {'name': <__main__.Lib object at 0x0000022C97E65F10>, 'version': '1.10.2'}
# type of pydict_ : <class 'dict'>由上述代码可以发现,pickle库可以直接支持python自定义的数据类型,而不需要配置encoder【配置encoder定义一个类,继承json.JSONEncoder类,重载default方法】
1.2.2 pickle库的危险性
不要轻易反序列化不可信任的pickle文件!
简单的构造具有危险性的代码
import pickle
import typing
import os
class Dangerous:
def __init__(self) -> None:
pass
# 专门为pickle预留的魔法方法,允许用于定义较为复杂的复原object的方式
def __reduce__(self) -> str or tuple[typing.Any, ...]:
return (
os.system,
("dir",),
)
danger = Dangerous()
with open(".\\Deep-Learning-Image-Classification-Models-Based-CNN-or-Attention\\手撕Pytroch第四期\\dangerous","wb") as f:
pickle.dump(danger,f)
f.close()
with open(".\\Deep-Learning-Image-Classification-Models-Based-CNN-or-Attention\\手撕Pytroch第四期\\dangerous","rb") as f:
pickle.load(f)
f.close()
# 输出结果为:
# 2023-01-23 01:25 <DIR> .
# 2023-01-23 01:25 <DIR> ..
# 2023-01-23 12:26 <DIR> Deep-Learning-Image-Classification-Models-Based-CNN-or-Attention
# 2023-01-11 23:26 96 GitHub克隆地址.txt
# 1 个文件 96 字节
# 3 个目录 65,380,278,272 可用字节上述代码中的__reduce__函数相当于让pickle.load打开了一个windows终端,并输入dir命令
当程序可以直接操作终端,相当于防线被攻破,有极大的风险
1.3 __reduce__和__reduce_ex__函数
__reduce__和__reduce_ex__都是为了pickle库专门创建的魔法方法,用于定义较为复杂的复原object的方式
具体用法见上1.2.2中的代码
IterableDataset中的函数正是此目的:
def __reduce_ex__(self, *args, **kwargs):
if IterableDataset.reduce_ex_hook is not None:
try:
return IterableDataset.reduce_ex_hook(self)
except NotImplementedError:
pass
return super().__reduce_ex__(*args, **kwargs)1.4 *args与**kwargs
*args是位置参数,必须按照顺序传入,**kwargs是关键字参数,按照关键字名称传入,可以不按顺序。且关键字参数keyword argument必须在位置参数argument之后
*和**其实是解包符号,类似电脑中的解压软件
其中*解元组的包,因而对应位置参数
**解字典的包,因而对应关键字参数
1.4.1 利用*args或**kwargs捕捉传入的值
可以直接使用for loop遍历args以及kwargs,代码如下:
def try_args(arg1,*args)->None:
print("arg1 = {}".format(arg1))
for arg in args:
print("Optional Argument = {}".format(arg))
try_args(1,2,3,4)
# 输出结果1:
# arg1 = 1
# Optional Argument = 2
# Optional Argument = 3
# Optional Argument = 4
def try_kwargs(arg1,**kwargs)->None:
print("arg1 = {}".format(arg1))
for key,arg in kwargs.items():
print("Optional Argument key {} : {}".format(key,arg))
try_kwargs(1,arg2=2,arg3 =3,arg4 = 4)
# 输出结果2:
# arg1 = 1
# Optional Argument key arg2 : 2
# Optional Argument key arg3 : 3
# Optional Argument key arg4 : 41.4.2 直接以元组(字典)方式传入参数
由上文可知,*是元组的解包符号,**是字典的解包符号,因而可以对应传入元组或字典,并且利用对应的解包符号进行解包传值,代码如下:
def try_args_kwargs(arg1,arg2,arg3)->None:
print("arg1:{}".format(arg1))
print("arg2:{}".format(arg2))
print("arg3:{}".format(arg3))
args = (1,2,3)
kwargs = {'arg1':1,'arg2':2,'arg3':3}
try_args_kwargs(*args)
# 输出结果1:
# arg1:1
# arg2:2
# arg3:3
try_args_kwargs(**kwargs)
# 输出结果2:
# arg1:1
# arg2:2
# arg3:31.5 @classmethod
@classmethod修饰器声明了一个属于类的方法,在调用的时候可以直接通过类名进行调用,或者通过对象进行调用
@classmethod有什么意义呢?他可以让继承的子类不需要重载父类的初始化函数,而只需要定义一个属于类的方法即可,直接上代码:
class Time():
def __init__(self,hour:int,minute:int)->None:
self.hour = hour
self.minute = minute
class String_Time(Time):
@classmethod
def get_version(cls,time:str)->Time:
hour,minute = map(int,time.split(":"))
Time_1 = Time(hour,minute)
return Time_1
time = String_Time.get_version("12:34")
print(time.hour)
print(time.minute)
# 输出结果为:
# 12
# 34