文章目录
- 前言
- 一、上传并解压HBase安装包
- 二、修改HBase配置文件
- (一)hbase-env.sh
- (二)hbase-site.xml
- 三、配置环境变量
- 四、复制jar包到lib文件夹
- 五、修改regionservers文件
- 六、分发安装包和配置文件
- 七、启动Hbase
- 八、验证HBase是否启动成功
- 总结
前言
#博学谷IT学习技术支持#
本篇文章主要介绍HBase集群的搭建,搭建步骤与Kafka、Hadoop等类似,都是先将安装包上传到Linux系统中,然后进行解压并进行相关档案的配置;
HBase底层的数据存储在HDFS中,节点管理也是由Zookeeper负责,所以启动Hbase前需要确保已安装Hadoop和Zookeeper并正常运行,若还未安装Hadoop和Zookeeper,可以参考文章:
(1)Zookeeper集群搭建:点这里
(2)Hadoop集群搭建:点这里
一、上传并解压HBase安装包
tar -xvzf hbase-2.1.0.tar.gz -C ../server/
解释:
上传的安装包统一放置在/export/software中,HBase安装包解压到/export/server文件夹中
二、修改HBase配置文件
(一)hbase-env.sh
cd进入HBase的conf文件夹,修改文件hbase-env.sh,配置JavaHome和HBASE_MANAGES_ZK
cd /export/server/hbase-2.1.0/conf
vim hbase-env.sh
# 第28行
export JAVA_HOME=/export/server/jdk1.8.0_241/
export HBASE_MANAGES_ZK=false
(二)hbase-site.xml
该文件也在conf文件夹中,使用vim语句修改hbase-site.xml文件
vim hbase-site.xml
------------------------------
<configuration>
<!-- HBase数据在HDFS中的存放的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1.itcast.cn:8020/hbase</value>
</property>
<!--Hbase的运行模式。false是单机模式,true是分布式模式。
若为false,Hbase和Zookeeper会运行在同一个JVM里面 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1.itcast.cn,node2.itcast.cn,node3.itcast.cn</value>
</property>
<!-- ZooKeeper快照的存储位置 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/server/apache-zookeeper-3.6.0-bin/data</value>
</property>
<!-- V2.1版本,在分布式情况下, 设置为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
三、配置环境变量
cd进入etc文件夹中,修改profile,将HBASE的存放路径添加到系统变量中,配置完成后需要使用source /etc/profile语句进行刷新,Linux才能获取最新的环境变量配置
# 配置Hbase环境变量
vim /etc/profile
export HBASE_HOME=/export/server/hbase-2.1.0
export PATH=$PATH:${HBASE_HOME}/bin:${HBASE_HOME}/sbin
#加载环境变量
source /etc/profile
四、复制jar包到lib文件夹
cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/
五、修改regionservers文件
cd进行hbase的conf文件夹中,使用vim语句创建regionservers文件,并将node1/node2/node3写入该文件中
cd /export/server/hbase-2.1.0/conf
vim regionservers
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
六、分发安装包和配置文件
HBase是一个集群,在node1节点上配置好后,也需要将相关文件分发到node2节点和node3节点中
cd /export/server
scp -r hbase-2.1.0/ node2.itcast.cn:$PWD
scp -r hbase-2.1.0/ node3.itcast.cn:$PWD
在node2.itcast.cn和node3.itcast.cn配置加载环境变量
source /etc/profile
七、启动Hbase
HBase依赖于Zookeeper和Hadoop,所以在启动HBase之前需要先启动Zookeeper和Hadoop,并确保这两个系统的正常运行。
cd /export/server
# 启动ZK (只是告诉大家需要启动zookeeper, 原来怎么启动 还怎么启动)
./start-zk.sh
# 启动hadoop
start-all.sh
# 启动hbase
start-hbase.sh
八、验证HBase是否启动成功
HBase地址:http://node1.itcast.cn:16010/master-status,使用浏览器访问该地址后如果出现以下界面,说明HBase已经启动成功;
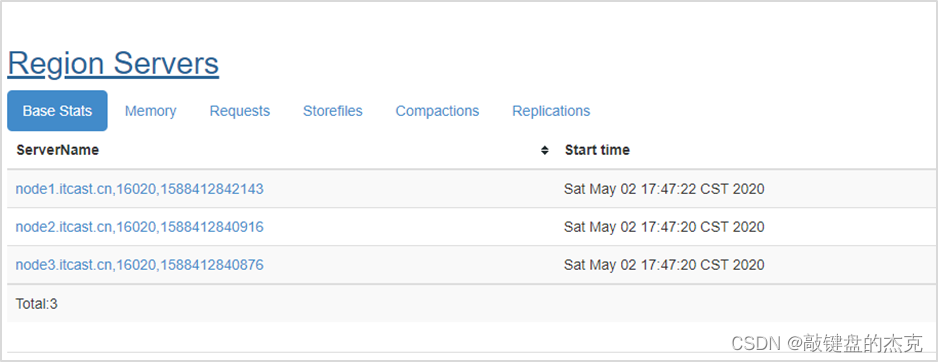
还有另一种验证方式,通过shell命令启动hbase shell客户端,并且输入status即可查询当前HBase集群的节点状态。
【补截图】
总结
HBase是一个非关系型数据库,其具有高可靠性、高性能、列存储、可伸缩的特性,主要用来存储结构化和半结构化的松散数据,HBase还有很多知识可以了解,下篇文章中还会继续探讨HBase的相关知识点。