3.1 用户画像计算更新
目标
- 目标
- 知道用户画像建立的流程
- 应用
- 无
3.1.1 为什么要进行用户画像
要做精准推送同样可以使用多种推荐算法,例如:基于用户协同推荐、基于内容协同的推荐等其他的推荐方式,但是以上方式多是基于相似进行推荐。而构建用户画像,不仅可以满足根据分析用户进行推荐,更可以运用在全APP所有功能上。
建立用户画像确实是一个一劳多得的事情,不仅可以运用于精准推送、精准推荐、精准营销,更可以作为网站的用户属性分析,用户行为分析,商业化转化分析等。同时网站共用一套用户画像,可以对用户有统一的认知。
3.1.2 用户画像计算设计
3.1.2.1 用户画像流程
用户画像的第一层主要是原始数据库,此数据库主要囊括后续分析所需要的所有原始数据。也是通过大量数据的分析和处理,后面能提炼成用户的画像得以运用。
- 头条画像原始数据
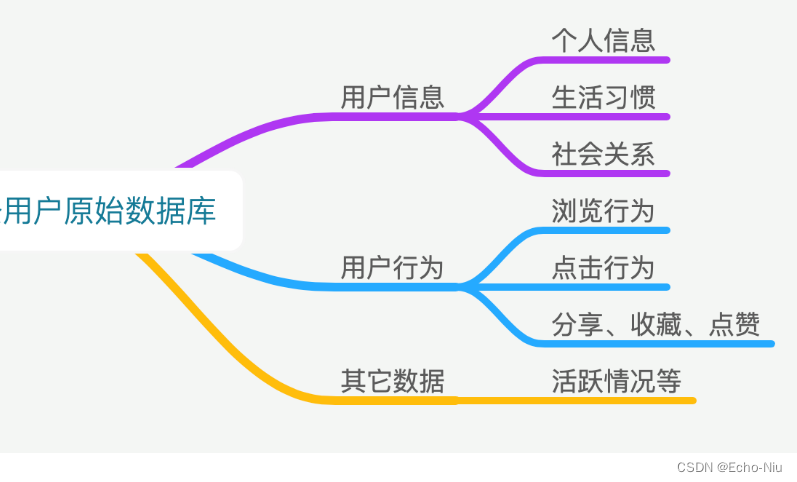
如数据库查询结果
hive> select * from user_action limit 1;
OK
2019-03-05 10:19:40 0 {"action":"exposure","userId":"2","articleId":"[16000, 44371, 16421, 16181, 17454]","algorithmCombine":"C2"} 2019-03-05
对于这样的数据,我们希望处理成一个完成统计基本表格,如下
- 用户画像标签建立
用户行为原始数据,我们得到了一张庞大的行为记录表。但是想要把这个表格的内容运用起来,我们需要把用户行为更为具象化,也就是需要把用户画像构建起来。
其实用户标签并不等同于用户画像,只是用户标签是用户画像直观的呈现,并且是比较好且常用的运用方式。
构建用户标签库其实比较简单,因为我们在上述采集用户行为过程中,已经把用户喜好的内容采集下来了,所以基础标签并可以直接运用内容的标签。也就是通过用户喜欢的内容给用户贴标签。
文章标签化
文章标签化,即之前我们建立好的文章标签,利用这些标签给用户贴上相应标签
| 频道1 | 频道2 | 频道3 | 频道4 | ... | 性别 | 年龄 | |
|---|---|---|---|---|---|---|---|
| 用户1 | 标签weights,标签,标签…. | 标签weights,标签,标签…. | 标签weights,标签,标签…. | 标签weights,标签,标签…. | ... | 1 | 10 |
| 用户2 | 标签weights,标签,标签…. | 标签weights,标签,标签…. | 标签weights,标签,标签…. | 标签weights,标签,标签…. | ... | 1 | 20 |
| 用户3 | 标签weights,标签,标签…. | 标签weights,标签,标签…. | 标签weights,标签,标签…. | 标签weights,标签,标签…. | ... | 0 | 30 |
3.2 用户画像增量更新
学习目标
- 目标
- 知道用户行为日志的处理过程
- 知道用户画像标签权重的计算公式
- 知道用户画像的HBase存储与Hive关联
- 应用
- 应用Spark完成用户画像的增量定时更新
3.2.1 增量用户行为日志处理
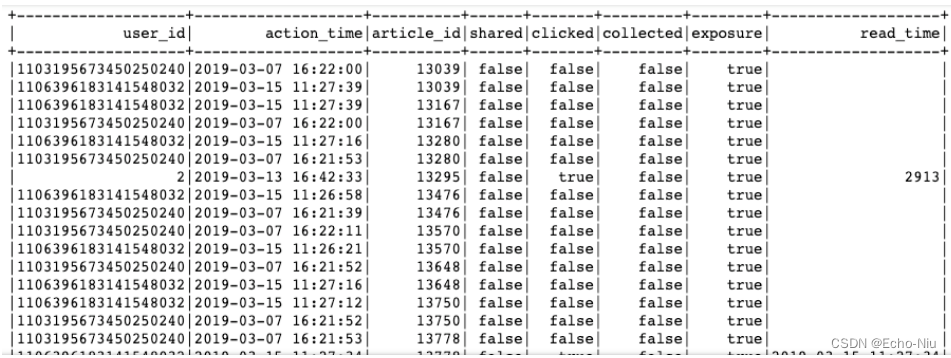
这里我们对用户画像更新的频率,
- 目的:首先对用户基础行为日志进行处理过滤,解析参数,从user_action—>user_article_basic表。
日志数据分析结果:
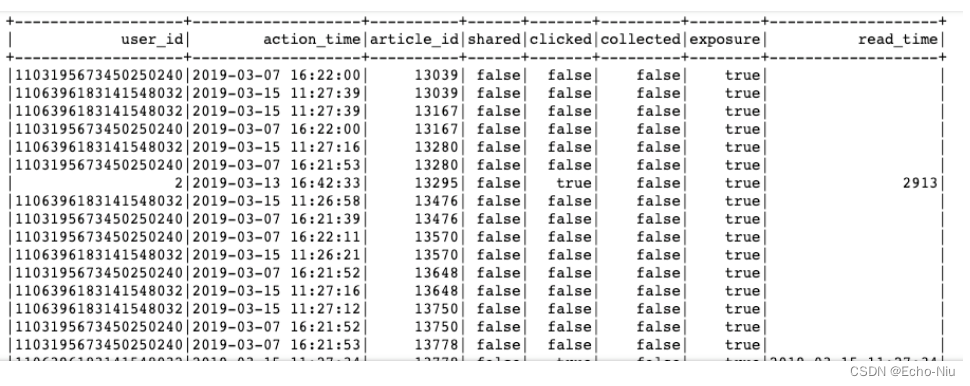
- 步骤:
- 1、创建HIVE基本数据表
- 2、读取固定时间内的用户行为日志
- 3、进行用户日志数据处理
- 4、存储到user_article_basic表中
创建HIVE基本数据表
create table user_article_basic(
user_id BIGINT comment "userID",
action_time STRING comment "user actions time",
article_id BIGINT comment "articleid",
channel_id INT comment "channel_id",
shared BOOLEAN comment "is shared",
clicked BOOLEAN comment "is clicked",
collected BOOLEAN comment "is collected",
exposure BOOLEAN comment "is exposured",
read_time STRING comment "reading time")
COMMENT "user_article_basic"
CLUSTERED by (user_id) into 2 buckets
STORED as textfile
LOCATION '/user/hive/warehouse/profile.db/user_article_basic';
读取固定时间内的用户行为日志
import os
import sys
# 如果当前代码文件运行测试需要加入修改路径,避免出现后导包问题
BASE_DIR = os.path.dirname(os.path.dirname(os.getcwd()))
sys.path.insert(0, os.path.join(BASE_DIR))
PYSPARK_PYTHON = "/miniconda2/envs/reco_sys/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
from offline import SparkSessionBase
import pyhdfs
import time
class UpdateUserProfile(SparkSessionBase):
"""离线相关处理程序
"""
SPARK_APP_NAME = "updateUser"
ENABLE_HIVE_SUPPORT = True
SPARK_EXECUTOR_MEMORY = "7g"
def __init__(self):
self.spark = self._create_spark_session()
在进行日志信息的处理之前,先将我们之前建立的user_action表之间进行所有日期关联,spark hive不会自动关联
# 手动关联所有日期文件
import pandas as pd
from datetime import datetime
def datelist(beginDate, endDate):
date_list=[datetime.strftime(x,'%Y-%m-%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_list
dl = datelist("2019-03-05", time.strftime("%Y-%m-%d", time.localtime()))
fs = pyhdfs.HdfsClient(hosts='hadoop-master:50070')
for d in dl:
try:
_localions = '/user/hive/warehouse/profile.db/user_action/' + d
if fs.exists(_localions):
uup.spark.sql("alter table user_action add partition (dt='%s') location '%s'" % (d, _localions))
except Exception as e:
# 已经关联过的异常忽略,partition与hdfs文件不直接关联
pass
读取固定时间内的用户行为日志
注意每天有数据都要关联一次日期文件与HIVE表
# 如果hadoop没有今天该日期文件,则没有日志数据,结束
time_str = time.strftime("%Y-%m-%d", time.localtime())
_localions = '/user/hive/warehouse/profile.db/user_action/' + time_str
if fs.exists(_localions):
# 如果有该文件直接关联,捕获关联重复异常
try:
uup.spark.sql("alter table user_action add partition (dt='%s') location '%s'" % (time_str, _localions))
except Exception as e:
pass
sqlDF = uup.spark.sql(
"select actionTime, readTime, channelId, param.articleId, param.algorithmCombine, param.action, param.userId from user_action where dt={}".format(time_str))
else:
pass
为了进行测试防止没有数据,我们选定某个时间后的行为数据
sqlDF = uup.spark.sql(
"select actionTime, readTime, channelId, param.articleId, param.algorithmCombine, param.action, param.userId from user_action where dt>='2018-01-01'")