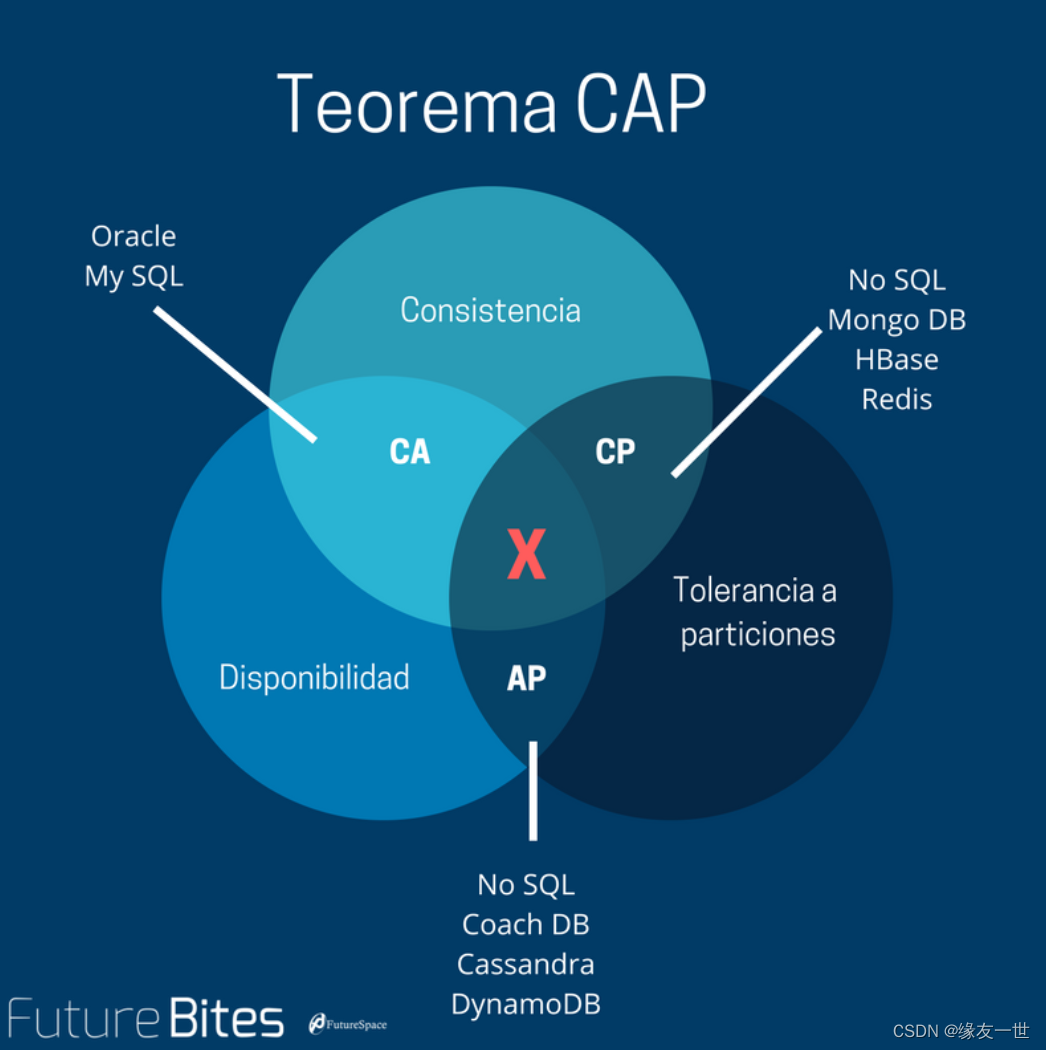
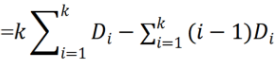摘要:零样本学习(ZSL)是一种成功的从未知类中对对象进行分类的范例。然而,它在广义零样本学习(GZSL)设置中遭受严重的性能降级,即以识别来自可见类和不可见类的测试图像。在本文中,为了GZSL和更开放的场景,我们提出了一个简单而有效的基于转移增量策略的机制。一方面,构建了一个基于双知识源的生成模型,解决了数据缺失问题;具体地,同时考虑从标签嵌入空间提取的局部关系知识和作为特征嵌入空间中的估计数据中心的全局关系知识来合成虚拟样本。另一方面,我们进一步探讨了GZSL环境下生成式模型的训练问题。设计了两种增量式训练模式,直接从合成样本中学习未见类,而不是将已见样本和合成未见样本一起训练分类器。在实际应用中,该方法不仅能有效地实现不可见类学习,而且所需的计算和存储资源较少。基于5个基准数据集进行了综合实验。与现有方法相比,提出的迁移增量策略兼顾了虚拟样本的生成和训练过程,对传统任务和GZSL任务都有显著改进。
一、问题背景
在ZSL和GZSL中,类标签的属性、文本描述和词向量经常被用作辅助信息,以弥合可见类和不可见类之间的差距。这种技术使得仅仅通过描述一个新的物体就可以识别它。起初ZSL已经在不现实的设置中进行了研究,在这种设置中,测试数据被默认为来自看不见的类。但由于可见对象在现实世界中总是更常见,可见类的分类精度可能与不可见类的分类精度一样重要,所以GZSL取消了对ZSL的不合理限制,在测试阶段允许可见类和不可见类,大大提高了实用性。
二、本文贡献
- 为了实现简单有效的知识转移,提出了一种基于双知识源的GRK和LRK生成模型;
- 首先设计增量式训练模式,直接从合成样本中学习未出现的类,从而获得更有效的GZSL任务训练过程。
三、基础知识
3.1.嵌入技术
特征和标签嵌入是未知物体识别任务中的基础技术,它将图像和标签从其原始空间转换到设计的特征和标签嵌入空间。嵌入技术的图示如图2所示。
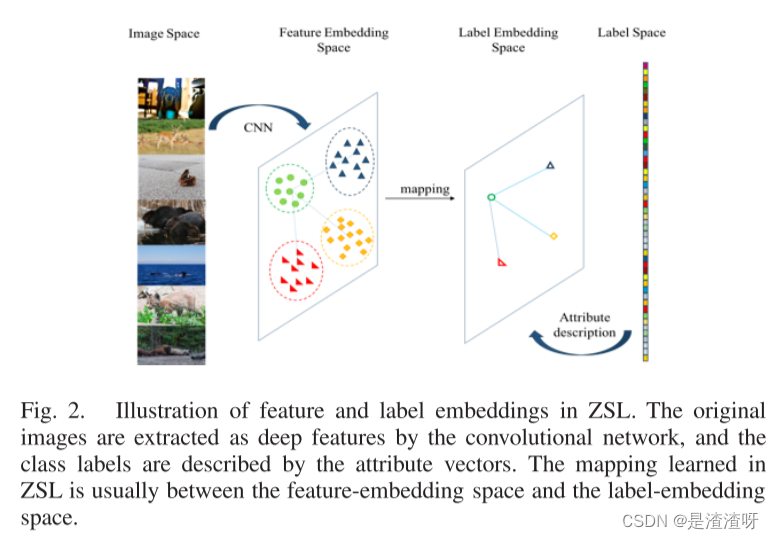
- 在特征嵌入空间中,通常通过网络提取特征进行深度表示。
- 在标签嵌入空间中,数据集的每一类都由其属性或词向量来描述,等等。
这里,为了更好地理解属性描述,以具有属性的动物(AWA)数据集为例。数据集中的"蓝鲸"类可以用许多属性来描述,包括"四肢(假)"、“蓝色(真)”、"海洋(真)“和"巨大(真)”。同样,“黑猩猩"也可以用同样的属性来描述,包括"四肢(对)”、“蓝色(错)”、"大海(错)“和"巨大(错)”。属性描述可以通过one-hot编码技术处理为属性向量,并作为不同类的细粒度类级表示在标签嵌入空间中使用。
嵌入层在ZSL中的应用可以分为两个主要范例:
- 基于相容性的方法学习具有区别性损失的线性或非线性交叉模态映射,并返回相容性得分以确定未见样本的类别;
- 基于概率的方法可以由经典的DAP和间接属性预测(IAP)方法表示,其学习多个概率学习器(分类器或回归器)并组合得分以进行预测。
3.2.相关知识转移
LRK表示特征和标签嵌入中可见类和不可见类之间的线性映射。当LRK在两个嵌入空间中相等时,可见类的学习器可以直接用于不可见类,并将其扩展为生成虚拟不可见样本
3.3.生成模型
生成式模型解决了ZSL的根本问题,即没有不可见类的样本可用于模型训练,因此近年来可以流行。除了提到的相关知识转移方法,
- Verma等人设计了一种反馈机制,并在测试阶段使用现成的分类器,以提高性能。
- Yang等人使用扩散正则化方法合成不可见的可视数据。
- 众所周知的生成对抗网络(GAN)也应用于ZSL领域。
- Jurie等人比较了四种不同的基于网络的ZSL生成模型的性能,包括条件GAN、生成矩匹配网络和去噪自动编码器。
- Xian等人提出了一种新的GAN,该GAN根据类级语义信息合成特征。该模型提供了一条直接从类的语义描述符到类条件特征分布的捷径。
- Zhu等人使用了GAN,该GAN将关于不可见类的噪声文本描述作为输入,并为该类生成合成视觉特征。
这些生成方法在ZSL和GZSL任务中表现出良好的性能。然而,这些方法大多是基于复杂网络的生成方法。模型的实现在实际中是相当困难的,对抗式训练也可能是耗时和不稳定的。对于更有效的生成过程,可能需要更简单的方法。
3.4.增量学习
渐进式学习策略为学习任务提供了一种有效的范式。由于数据缺失的问题,只有少数文章提到了ZSL领域的策略。
- Nan等采用线性判别分析和QR分解实现了基于IAP方法的增量ZSL。当选择了更多真实的样本(类)时,可以递增地更新模型,以了解有关属性的信息,从而实现更好的预测。由于IAP在GZSL设置下对可见类有偏差,因此该方法实际上仅限于ZSL任务。
- 类似地,Kawewong 基于IAP模型,针对不同用户以在线增量方式逐步标注属性的场景,使用无监督增量神经网络学习ZSL任务的更多类型属性。
- Ferreira等人开发了一种口语理解的在线自适应策略,这实际上是ZSL的一种应用。实验和数据集都与标准ZSL不同。
应该注意的是,所提到的方法中没有一种将增量学习技术应用于生成模型以学习看不见的类并在标准GZSL设置下报告结果。不同的是,本文为所提出的生成式模型设计了两种增量式训练模式,并给出了基于5个基准数据集的综合结果。
四、本文方法
本文所提方法为转移增量策略,包括两个阶段。
- 在转换阶段,利用标签嵌入的LRK和可见特征的GRK构造生成模型,为不可见类合成虚拟样本。
- 在增量阶段,已经在可见样本上训练过的增量学习器继续从为不可见类生成的样本中学习。
- 可见类和不可见类都被经典DAP模型识别。
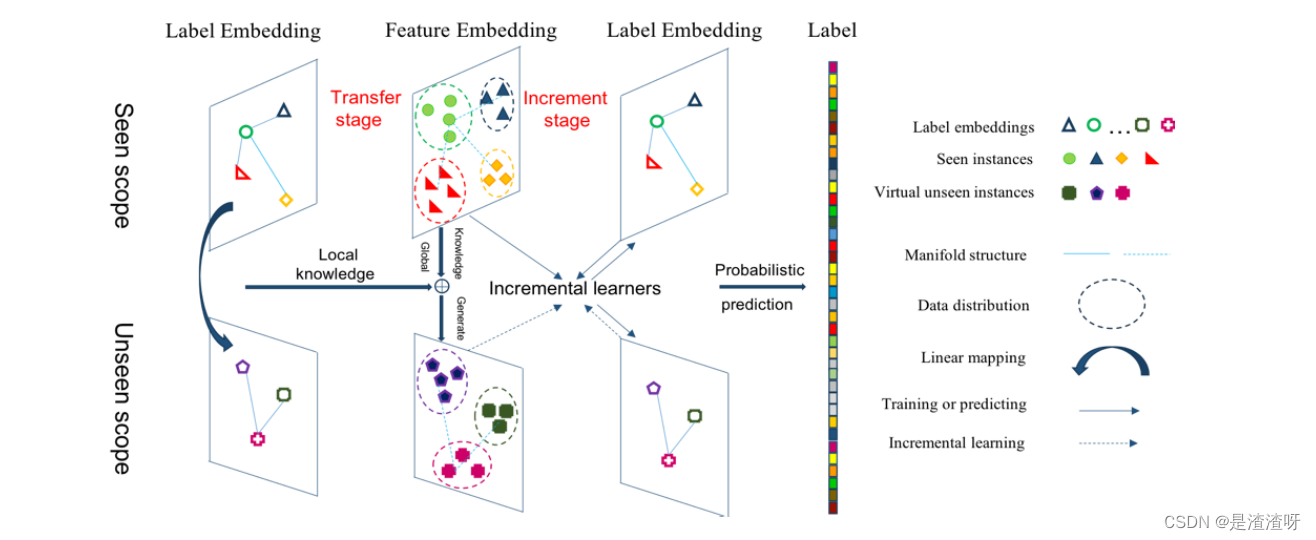
4.1.基于双知识源的转移阶段
我们使用两种知识,即LRK和GRK,分别从标签嵌入空间和特征嵌入空间中提取生成模型。GZSL的数据逻辑如图 4(a)所示,其中 ES ∈ RD×p 是所见类数据的均值矩阵,ES中每列 ei ∈ RD×1 表示第 i 个所见类的均值向量。
此外,DAP、LRKT 和我们的生成模型的基本思想在图4(b)-(d)中进行了比较。
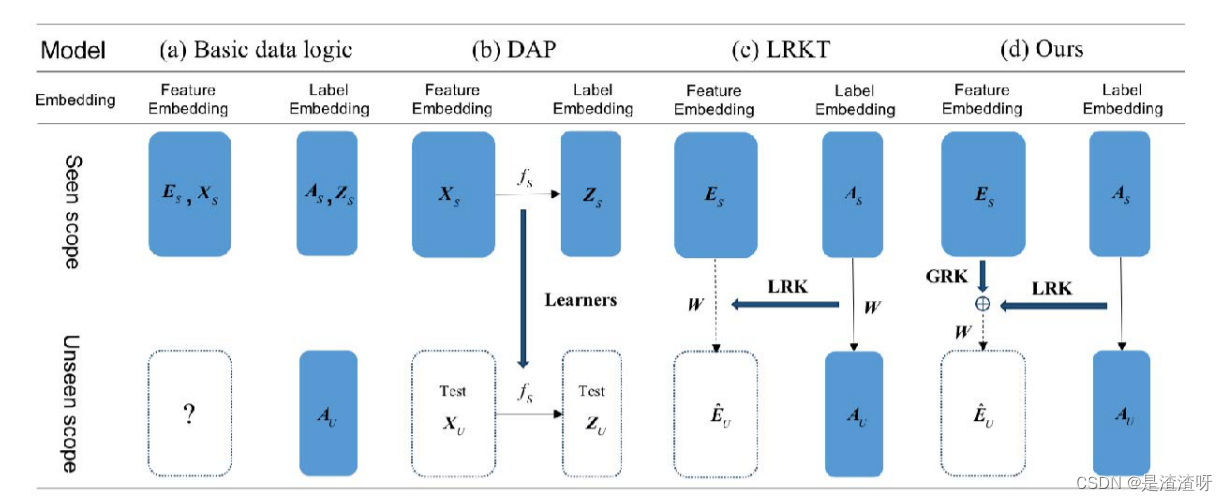
- LRKT将LRK转化应用于合成不可见类 E ^ \hat{E} E^U ∈ RD×q 的虚均值矩阵和解决DAP的移位问题。然而,该算法在提取LRK时没有考虑真实的样本。
- 不同的是,我们的方法估计未见类在特征嵌入空间中的中心作为GRK,使合成的未见类的总体分布更接近真实的类的分布。GRK是基于以下假设定义的:
- 假设:在ZSL和GZSL设置中,数据集的整体中心可以由可见类近似,并转移到不可见类的中心。其公式为
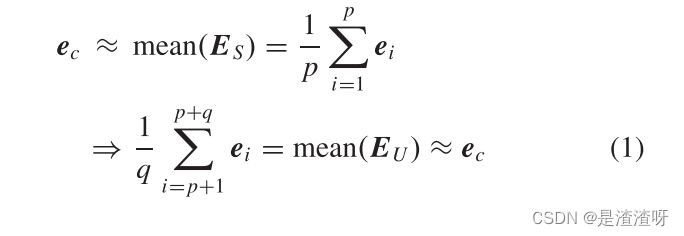
其中ec是数据集的总体中心,EU ∈ RD×q 是未见类的真实的均值矩阵。
- 假设:在ZSL和GZSL设置中,数据集的整体中心可以由可见类近似,并转移到不可见类的中心。其公式为
4.2.增量培训阶段
在传输阶段,可以为不可见类生成虚拟标签数据{XU,Y U,Z U},其中X U ∈ RD×M是合成不可见样本,Y U ∈ R1×M是合成不可见标签,Z U ∈ RAD×M是合成不可见属性标签,M 是合成样本的数量。为了有效地从虚拟样本中学习并减少转移-增量策略对可见类数据的依赖性,设计了IWM和IOM。
与传统的CLM相比,IWM和IOM的基本思想如图5所示。
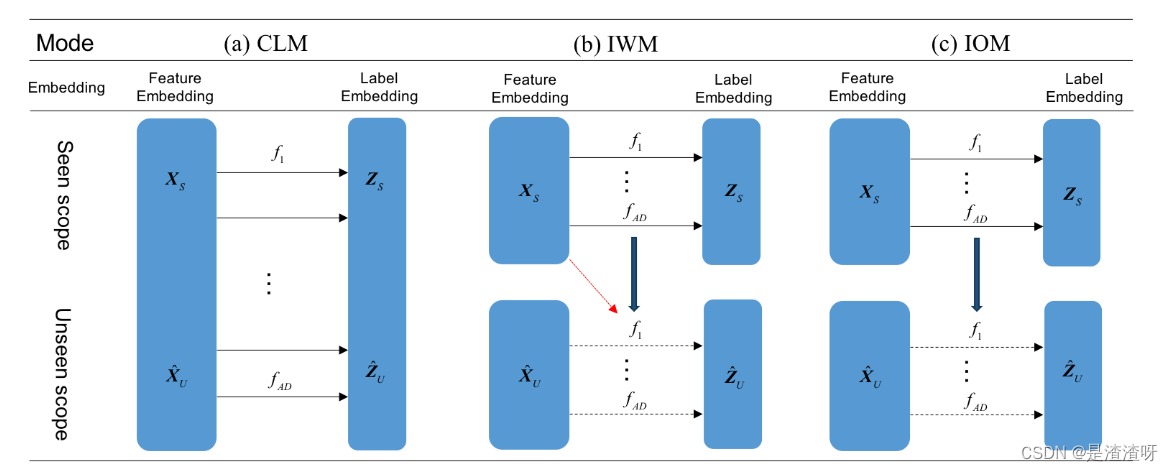 在GZSL设置下比较(a)CLM、(b)IWM 和(c)IOM。f 表示学习器(分类器或回归器),实线箭头表示一般训练过程,黑色虚线箭头表示增量学习过程,红色箭头表示在增量学习期间使用XS。
在GZSL设置下比较(a)CLM、(b)IWM 和(c)IOM。f 表示学习器(分类器或回归器),实线箭头表示一般训练过程,黑色虚线箭头表示增量学习过程,红色箭头表示在增量学习期间使用XS。
传统的CLM将X U和XS组合在一起以形成训练数据X =[XS|X U]并学习属性标号 Z =[ZS | Z U],其中ZS ∈ RAD×NS是可见样本的属性标签,NS是可见样本的数目。CLM是DAP的基本方法。
- 相比之下,IWM和IOM使用可见数据{XS,ZS}初始化属性学习器,并增量学习合成样本{XU,Z U}。2. 在IWM的增量学习过程期间使用所见类XS的样本。这在保持所见类的识别能力方面表现出了益处。
- 对于IOM来说,这种模式在学习未看到的类时不再需要已看到的类的数据。
- IWM和IOM都基于经典的DAP方法进行最终分类。显然,CLM、IWM 和 IOM对所见样本的依赖性依次降低。
4.2.1.Incremental Learning With the Data of Seen Classes Mode(IWM)
IWM用属性标签矩阵ZS = [zS1,…,zSAD]T ∈ RAD×NS,其中 NS 是可见样本的数目。对于属性标号zSi ∈ RNS×1(i = 1,…,AD),属性学习器的基本线性形式被呈现为具有如下的正则化项:
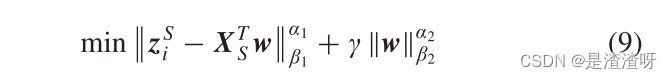
其中α1 > 0,α2 > 0,β1和β2是典型的范数正则化,w ∈ RD×1是学习的属性学习器。通过取α1 = α2 = β1 = β2 = 2,用 l2-范数正则化来设置对象,该正则化是凸的,具有更好的推广性能。值γ是正则化项的参数。利用岭回归理论可以很容易地解决这一问题:
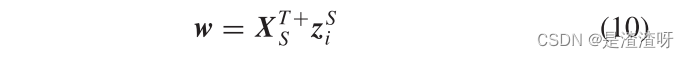
其中 XT+S 是 XTS 的伪逆,并通过以下公式获得:
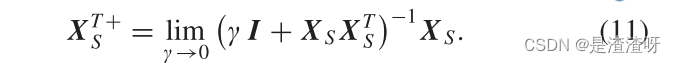
在此基础上,利用{XS,ZS}对所见类进行AD属性学习器的训练。接下来,相同的学习器从合成的虚拟数据{XU,ZU}中为看不见的类递增地学习。这可以通过将伪逆 XT+S 更新为 XT+ 来实现:
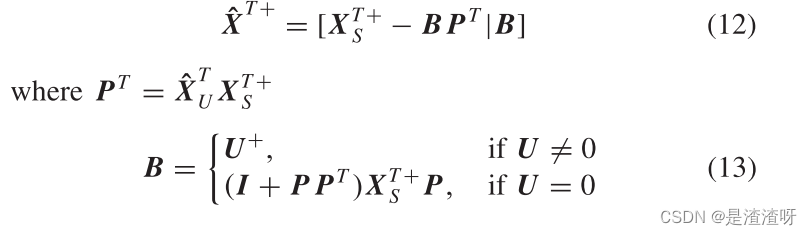
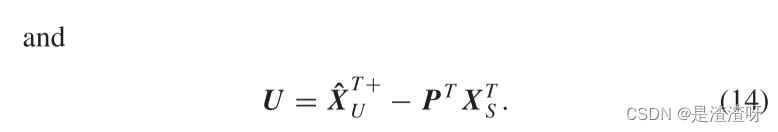
使用更新后的伪逆,w可以通过下式更新为
w
^
\hat{w}
w^:
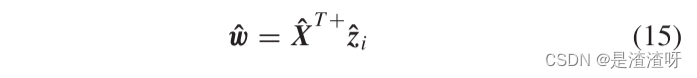
其中,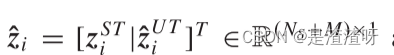 ,并且
,并且 是
是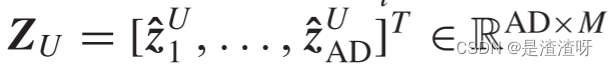 中的虚拟属性标签。
中的虚拟属性标签。
IWM使用(12)-(15)中的增量算法来更新属性学习器,以学习未见过类的附加属性知识。在更新期间,将所见类XS的样本设置为(14)中的中间信息而不是输入数据。增量式算法允许IWM学习看不见的类,并保留看到的类的知识,而不需要从一开始就进行整个重新训练。
4.2.2.Incremental Learning Without the Data of Seen Classes Mode(IOM)
IOM采用迭代的方式学习所有样本,迭代后每个样本的损失最小,这与自适应策略类似。

类似地,基于(16)-(18)中的模型,可以针对具有{XS,ZS}的所见类来训练AD属性学习器。
- 由于迭代学习策略对样本进行逐个学习,因此在初始训练之后不再需要所见类的数据。
- 经过训练的属性学习器可以直接基于合成的样本学习未见过的类。
- 迭代方式学习看不见的类要快得多,并且在训练少量虚拟样本的情况下呈现较高的调和平均精度。
可以证明,IOM的被动攻击算法对未见类的求解虽然没有已见类的样本,但已见类的知识损失是有限的,在测试阶段可以同时实现对已见类和未见类的识别
五、实验
略