文章目录
- 简述
- 架构选择
- 统一版本管理
- 基础框架包管理
- 业务框架包管理
- 模型分层
- 全局上下文管理
- 数据结构定义
- 上下文的传播
- 前后端数据格式协定
- 统一数据格式
- 字段规范协定
- 异常处理
- orm配置
- 公共字段处理
- 分页处理
- 字段加解密
- 缓存
- key的序列化
- 哪些数据进行缓存
- 消息队列
- key的规范
- 队列的管理
- 注册中心
- 配置中心
- 日志配置的热更新
- 普通配置的热更新
- 公共配置的抽取
- 网关
- 统一鉴权
- 负载均衡
- 限流降级
- 日志的收集
- 普通日志处理
- 审计\操作日志处理
- 文档管理
- 定时任务
简述
其实很多人不理解框架和架构的界限,架构的范围比框架来的要宽泛很多,框架是架构实施的具体体现。所以我们这里谈的是作为一个框架,应该需要做出什么处理。而架构可能不止涉及开发这部分。架构是个很泛的概念,如以下架构的选择,只是一种服务调用的方式。
架构选择
见过各种各样的微服务实现方式,各家长短我们这边不讨论,各自对号入座,常见的为以下三种方式。当然也有比较另类的方式。
第一种对业务进行分层禁止反向调用。
在服务都在同一层的情况下,又需要进行互调怎么办,在所有服务上加一层服务做为边界层,进行服务聚合。
这种方式就是允许服务间进行互调,可能会产生服务调用循环问题。但是控制的好的话正常也不会有什么问题。
另类的方式,比如把所有服务的sql整合到一个服务中,由单一的一个服务提供数据服务,这种是真的很另类,但是确实有人这么实现。
记得之前提过一个问题,就是feign-client 层到底是由服务开发者来写,还是由服务调用者来写?
从架构第一性原则出发,我也不说哪个更合适,因为出于权衡的角度来思考这个问题,有的人考虑了开发的便利性,决定由服务开发者来写;而有的人从微服务的松耦合原则上考虑,当然由服务调用者来写比较合适,因为如果由服务开发者来提供调用包的方式,会产生服务依赖,导致在cicd阶段,需要进行依赖编译,就需要用进行服务编排。而如果由调用者自己写接口调用,那么无需依赖,服务间没有直接依赖。当然还有第三种选择,就是抽取一个公共包,所有的服务接口全部写道公共包中的方式,这样所有服务只需要共同依赖一个接口包,这种方式可以说对前两种方式进行了折中。
统一版本管理
试想一下如果框架层面没有对版本做出统一的管理,随着时间的推移,每个开发各自引入各自的包会产生什么样的问题?当然就是各种包版本混乱各种包冲突之类的问题就随之而来。所以我们一般需要用一个pom将所有的版本统一管理起来,当遇到版本冲突时,可以根据此pom进行版本裁决,便于架构师对版本进行管理
基础框架包管理
如果公司有自己写的框架,以及中间件,这些框架作为基础框架需要进行单独管理。比如一些所有项目都需要共用的内容也可以纳入基础框架包中。
业务框架包管理
在基础框架包之上需要引入各种基础框架包。然后根据需要进行分包配置。比如有的项目需要用到mq 有的项目需要用到redis,而有的项目不需要,所以此时需要将这些组件的包进行单独拆包配置。
模型分层
我们一般对数据模型进行一个分层管理
- po 持久层模型,对应数据库表结构
- dto 传输层模型,作为接口入参,服务层与控制器层之间的数据传输
- vo 视图层模型,对应接口返回
但是分层之后会出现一个问题就是模型的拷贝来拷贝去是比较浪费性能的,尤其是为了便利使用的各种BeanCopyUtil产生的各种血案。所有有的人会直接使用po穿透到前端,实际上这种方式对于一些小系统,或者小公司而言也没什么问题。但是正常情况下我们还是会对模型进行一个分层处理,这样能让业务模型更加精准,提高数据的安全性,但是最好规定下copy规范,使用getter、setter进行数据设置,这个可以通过安装开发插件的方式处理,也可以规定只能使用cglib的beancopy,禁止使用反射,反射性能低下,配置不恰当还可能照成metaspace溢出之类的问题。当然通过配置也能解决此类问题,无非就是浪费点性能和资源。
全局上下文管理
一般我们系统需要一些全局上下文的缓存,在一次请求中记录请求的状态信息仅供一次请求全局使用。一般使用threadlocal来处理,线程结束后需要进行清理,避免缓存泄漏或者出现线程复用产生脏数据。
数据结构定义
正常情况下数据结构分为特定数据,非特定数据
- 特定数据,比如记录登入相关的信息
- 非特定数据,比如一些业务处理的状态需要流转到下一个服务
上下文的传播
上下文的传播我们一般可以将一个请求中产生的全局状态通过请求传播到下一个服务中。一般可以将对应的状态数据通过请求头进行传播。除了服务间的传播之外,我们还应当考虑异步线程间的传播。
前后端数据格式协定
一个统一的数据格式有助于前端架构的统一化
统一数据格式
- 错误码
- 错误消息
- 泛型数据
可以参考如下:所有的方式必须使用该类进行包装
@Data
public class JsonResult<T> implements Serializable {
private static final long serialVersionUID = 1559840165163L;
private Integer code;
private String message;
private T data;
public JsonResult() {
}
public JsonResult(Integer code, String message, T data) {
this.code = code;
this.message = message;
this.data = data;
}
public JsonResult(Integer code, String message) {
this.code = code;
this.message = message;
}
public static <T> JsonResult<T> success(String message, T data) {
JsonResult jsonResult = new JsonResult();
jsonResult.setCode(Const.CODE_SUCCESS);
jsonResult.setMessage(message);
jsonResult.setData(data);
return jsonResult;
}
public static <T> JsonResult<T> success(T data) {
JsonResult jsonResult = new JsonResult();
jsonResult.setCode(Const.CODE_SUCCESS);
jsonResult.setMessage("操作成功");
jsonResult.setData(data);
return jsonResult;
}
public static <T> JsonResult<T> success() {
JsonResult jsonResult = new JsonResult();
jsonResult.setCode(Const.CODE_SUCCESS);
jsonResult.setMessage("操作成功");
jsonResult.setData(null);
return jsonResult;
}
public static <T> JsonResult<T> error(String message) {
JsonResult jsonResult = new JsonResult();
jsonResult.setCode(Const.CODE_FAILED);
jsonResult.setMessage(message);
jsonResult.setData(null);
return jsonResult;
}
public static <T> JsonResult<T> error(String message, T data) {
JsonResult jsonResult = new JsonResult();
jsonResult.setCode(Const.CODE_FAILED);
jsonResult.setMessage(message);
jsonResult.setData(data);
return jsonResult;
}
public static <T> JsonResult<T> fail() {
JsonResult jsonResult = new JsonResult();
jsonResult.setCode(Const.CODE_FAILED);
jsonResult.setMessage("操作失败");
return jsonResult;
}
public static <T> JsonResult<T> fail(String message) {
JsonResult jsonResult = new JsonResult();
jsonResult.setCode(Const.CODE_FAILED);
jsonResult.setMessage(message);
return jsonResult;
}
@JsonIgnore
public boolean isSuccess() {
return Const.CODE_SUCCESS.equals(this.code);
}
@JsonIgnore
public boolean isFail() {
return !isSuccess();
}
}
字段规范协定
除了统一返回之外,我们还需要对某些比较特殊的结构进行一些定制,比如日期格式的统一,还有对空列表的序列化,比如规定空列表是返回null,还是返回空列表,正常我们可以返回空列表,这样前端拿到空列表不需要在进行处理可以直接填充,还有一般的null是返回空,还是索性不返回这个字段等等。
- 日期
- 空列表
异常处理
在异常处理中,我们一般可以封装一个业务异常,方便开发在深层调用出现异常时直接抛出,而不用进行层层return,虽然牺牲了点性能,还是从第一性原则上讲,这种方式的对于开发便利性的收益是非常可观的。
同时我们需要进行异常的全局拦截,并将异常收敛在当前服务,再将异常包装成统一返回。但是将异常收敛之后,链路追踪类的组件也就无法进行捕获,所以需要当前项目进行链路上报,此时需要在对全局异常处理类再进行一层拦截,收集异常信息再进行上报。
对ExcelptionHandler进行切面处理上报异常给skywalking
@Aspect
public class ExceptionHandlerAspect {
@Around(value = "@annotation(org.springframework.web.bind.annotation.ExceptionHandler)")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
Object[] args = joinPoint.getArgs();
for (Object arg : args) {
if (arg instanceof Throwable) {
ActiveSpan.error((Throwable)arg);
}
}
return joinPoint.proceed();
}
}
orm配置
在开发过程中,开发效率以及开发便利性是架构权衡很重要的一个质量属性,所以我们一般以实体为中心,在做架构设计的时候,为了这个质量属性,我们正常有代码生成器生成并且多次生成时幂等的。比如我一个实体有10个字段,现在我新增了一个字段,我再次生成之后是不会影响原本所有的现有代码。例如我们使用mybatis时我们会将xml文件分成2个,一个生成的、一个由开发编写的,生成的部分我们不允许修改。当我们重新生成代码时我么仅覆盖默认的xml以及实体。
公共字段处理
我们在做数据库设计时我们正常会规定一些公共字段,比如createt_time、update_time、create_user、update_user、deleted这些公共字段。那么此时我们需要对这些公共字段进行合理的配置,并将这些字段抽取成BasePO,让所有PO继承至这个BasePO。并在框架层面自动填充。
比如mybatis-plus中我们可以利用MetaObjectHandler处理此类问题
public class BasePOMetaObjectHandler implements MetaObjectHandler {
private final static String update_time="updateTime";
private final static String create_time="createTime";
private final static String update_user_code="updateUserCode";
private final static String create_user_code="createUserCode";
private final static String update_username="updateUsername";
private final static String create_username="createUsername";
private final static String deleted="deleted";
private final static String available="available";
@Override
public void insertFill(MetaObject metaObject) {
LocalDateTime now = LocalDateTime.now();
this.setFieldValByName(create_time, now,metaObject);
this.setFieldValByName(update_time, now,metaObject);
this.setFieldValByName(create_user_code, StringUtils.defaultIfEmpty(SystemContext.getUserInfo().getUserCode(),"0"),metaObject);
this.setFieldValByName(create_username,StringUtils.defaultIfEmpty(SystemContext.getUserInfo().getUserName(),"system"),metaObject);
this.setFieldValByName(deleted,0,metaObject);
//this.setFieldValByName(available,1,metaObject);
}
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName(update_time, LocalDateTime.now(),metaObject);
this.setFieldValByName(update_user_code,StringUtils.defaultIfEmpty(SystemContext.getUserInfo().getUserCode(),"0"),metaObject);
this.setFieldValByName(update_username,StringUtils.defaultIfEmpty(SystemContext.getUserInfo().getUserName(),"system"),metaObject);
}
}
分页处理
系统中一般存在大量的分页查询,在做分页时,我们通常也是封装一个统一入参,像以下这样,跟统一返回的作用是一样的
@Data
public class PageParam<T> implements Serializable {
private static final long serialVersionUID = -7248374800878487522L;
/**
* <p>当前页</p>
*/
private int pageNum = 1;
/**
* <p>每页记录数</p>
*/
private int pageSize = 10;
/**
* <p>分页外的其它参数</p>
*/
private T param;
字段加解密
字段的加解密一般分为三层
- 接口层的数据加解密
- 数据库层的字段加解密,这类加解密一般是身份证、手机号、银行卡子类的特殊字段,这一层我们可以采用的shading-sphere encrypt插件的方式处理,代理数据源,拦截preparment处理,0入侵,也可以使用mybatis的typeHandler处理,相对业务层有入侵
- 日志打印的字段加解密
当然一般的系统这些内容可以不考虑,其实大部分系统对这个没什么要求,但是如果你需要申请一些资质的时候这个是必须的,或者从安全性角度出发,当你被托库了或者日志被泄漏了,此时加密将是你数据的最后一层保障。有很多大公司发生过此类事件,比如美团,当前的博客,更多的例子就不说了。
缓存
key的序列化
如果你使用redisTemplate设置缓存数据时,由于是对象,此时key也会被序列化层二进制,此时如果出现问题,你排查问题,需要对应的一个缓存管理界面,通过java接口反序列化,才能找到对应的key和数据,对于一些小公司而言非常不友好,因为一般公司没有时间给你去开发这样的一些功能,所以一般对序列化进行一些简单的配置是小公司的首选,将key序列化层字符串。
哪些数据进行缓存
- 一些静态不怎么变化的数据 比如一些字典类的
- 业务上的临时数据 比如短信验证码5分钟有效
- 一些热数据 为了性能考虑做的一些优化
消息队列
除了老生常谈的一些问题,比如消息丢失的处理,业务特定场景之类的我们还要考虑一些规范性的东西
key的规范
大部分的框架对key的定义并没有做什么特别的处理,但是正常情况下我们一般会对key做一些特殊定义,比如这个消息是由哪个服务发送到哪个服务的,可以把这些信息标注到key上,排查问题时,就不用导出找代码,当然你也可以做一张对照表,排查问题的时候可以取对照表进行对照,但是维护一段时间之后就会出现断层,除非你能让开发按照你的标准坚定不移的执行下去。
队列的管理
分为两类
- 框架层作为消费者的消息
- 业务层间交互的消息
队列的创建一般由框架层处理,提供一个单独的包给对应的业务,这个包包含消息的发送,消息的消费者由开发自己处理。
注册中心
这些老生常谈的东西,就不多说了。
配置中心
日志配置的热更新
在spring-boot的体系下提供了一个LogSystem抽象,所有的日志框架都实现了该抽象类,所以可以基于这个抽象类我们在运行时进行刷新日志级别。
public class LoggingSystemConfiguration {
private static final Logger log = LoggerFactory.getLogger(LoggerConfiguration.class);
private static final String LOGGER_TAG = "logging.level.";
@Resource
private LoggingSystem loggingSystem;
@ApolloConfig
private Config config;
@ApolloConfigChangeListener(interestedKeyPrefixes = "logging")
private void configChangeListener(ConfigChangeEvent changeEvent) {
log.info("logger configure refresh");
refreshLoggingLevels();
}
private void refreshLoggingLevels() {
Set<String> keyNames = config.getPropertyNames();
for (String key : keyNames) {
if (StringUtils.containsIgnoreCase(key, LOGGER_TAG)) {
String strLevel = config.getProperty(key, "info");
LogLevel level = LogLevel.valueOf(strLevel.toUpperCase());
loggingSystem.setLogLevel(key.replace(LOGGER_TAG, ""), level);
log.info("{}:{}", key, strLevel);
}
}
}
}
普通配置的热更新
此处我们以apollo为例,普通配置的热更新我们需要@ApolloConfigChangeListener进行配置更新的监听然后刷新配置。
@Configuration
@ConditionalOnClass({ApolloAutoConfiguration.class,RefreshScope.class})
public class ApolloReFreshAutoConfig implements ApplicationContextAware {
private final static Logger log=LoggerFactory.getLogger(ApolloReFreshAutoConfig.class);
ApplicationContext applicationContext;
@Resource
RefreshScope refreshScope;
@Bean
public LoggingSystemConfiguration loggingSystemConfiguration() {
return new LoggingSystemConfiguration();
}
public ApolloReFreshAutoConfig(final RefreshScope refreshScope) {
this.refreshScope = refreshScope;
}
@ApolloConfigChangeListener({"application","bootstrap.yml","common.properties"})
private void refresh(ConfigChangeEvent changeEvent) {
log.info("Apollo config refresh start");
this.applicationContext.publishEvent(new EnvironmentChangeEvent(changeEvent.changedKeys()));
refreshScope.refreshAll();
log.info("Apollo config refresh end");
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext=applicationContext;
}
}
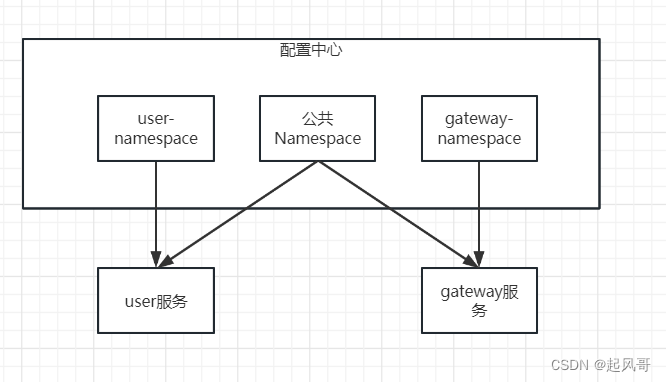
公共配置的抽取
正常情况下我们一个项目可能共用一些公共组件,比如redis,mq在这种情况下我们当然不希望这些配置每个项目都写一遍,所以我们需要抽取一个公共配置,将这些配置的公共配置都放在公共配置中。
网关
统一鉴权
网关统一鉴权的数据来源正常我们可以分为两种方式
- 通过服务接口获取
- 直接通过缓存,用户服务在登入成功后将数据放入缓存,网关直接取缓存。
至于jwt这个东西真的没什么必要,既然都用缓存了,jwt在其中根本没有丝毫作用。
负载均衡
一般小企业的系统轮询就够了。正常就能满足大部分小公司的需求,日单量10万以内的系统正常不需要什么特别的配置。所以一般负载均衡的策略上更多我们会有其它的一些架构上的作用,比如无损发布等等这些处理上。
限流降级
这些方案也是老生常谈,不多说。
限流

降级
这个一般设置个开关,分成两种处理方式,一种手动关闭一些分支业务,一种自动处理,当错误数量达到阀值时自动关闭某些服务即可。
日志的收集
日志收集我们正常两种方式
普通日志处理
- 落盘之后通过诸如filebeat之类的程序去抽取集中到某个地方,如es
- 直接通过kafkaappender将日志打到网络端口去
审计\操作日志处理
这类日志我们一般需要存成特定的数据结构,可以通过mq统一收集之后单独由一个消费者进行处理成结构化的数据,方便业务上使用。
文档管理
这个我们正常选择swagger,这个无需我多说了。
定时任务
- 中心化的xxl-job
- 去中心化的elastic-job
- quatz