Rocky Ding
公众号:WeThinkIn
写在前面
【人人都是算法专家】栏目专注于分享Rocky在AI行业中业务/竞赛/研究/产品维度的思考与感悟。欢迎大家一起交流学习💪
大家好,我是Rocky。
之前Rocky总结过很多关于AI算法竞赛的方法论、经验思考以及细节注意事项等方面的内容。虽然写了不同维度的文章,但是感觉比较零散,故Rocky在本文中将之前分享的核心观点和对AI算法竞赛最新的思考进行整合梳理,力求通过本文能让大家不再惧怕AI算法竞赛,并且在紧张的厮杀中能从容,能有收获。
So,enjoy:
正文开始
----【目录先行】----
-
为什么要参加AI算法竞赛
-
AI算法竞赛的赛题挖掘
-
AI算法竞赛厮杀方法论
-
分类/分割/检测算法竞赛中的实用Tricks
-
打完AI算法竞赛的日子
为什么要参加AI算法竞赛
参加AI算法竞赛的底层逻辑,Rocky这里主要总结以下几点:
学生时期
-
通过参加AI算法竞赛来入场AI领域,以赛代学,赛中学,学中赛。
-
丰富简历,为实习/升学/校招做准备。
-
增加实验室课题组的AI影响力。
-
赚取奖金。
-
热爱竞赛氛围,渴望提升技术能力。
工作时期
-
AI竞赛工具化,作为业务扩展的demo。
-
提升公司的AI影响力&AI软实力。
-
参与学术分享,提升行业内的知名度。
-
AI Lab的常规业务。
-
工作之余,赚取奖金。

AI算法竞赛的赛题挖掘
Rocky认为,AI算法竞赛的赛题本质通常是成熟领域+创新领域的混合模式。
成熟领域包括图像分类,图像分割,目标检测,目标追踪,对抗攻防等。
创新领域则一般是在成熟领域中再往前走一到两步,主要表现形式如下:
-
结合实际场景,如智慧城市,智慧安防,智慧工业,智慧电商,智慧硬件等。
-
成熟领域中的难点方向,如规则限制,条件约束,细分场景(细粒度,小样本,多任务结合等),引入前沿概念(“以数据为中心”,“元宇宙”,“大模型”等)。
-
结合新兴研究方向(扩散模型,AIGC,可信AI,Transformer等)
当然,除此之外,还包括一些热身赛,入门赛等赛题形式,这些赛题往往比较直观简单,在此就不做赘述。
AI算法竞赛厮杀方法论
“优质AI算法竞赛就是算法领域的天下第一武道大会。” —— Rocky Ding(中国)
Rocky相信一个有足够资源背书,竞赛赛题切实新颖,参赛队伍卧虎藏龙,并有顶级学术会议分享机制的AI竞赛,可以称得算上优质。如果我们能在这样的AI竞赛中全力以赴,深度参与,那么最后一定会有比较丰富的收获与感悟。
为了帮助大家更好的参与“天下第一武道大会”,Rocky从工业界的角度出发,结合自身的多年竞赛厮杀经验,总结了一套全方位的AI算法竞赛厮杀方法论:
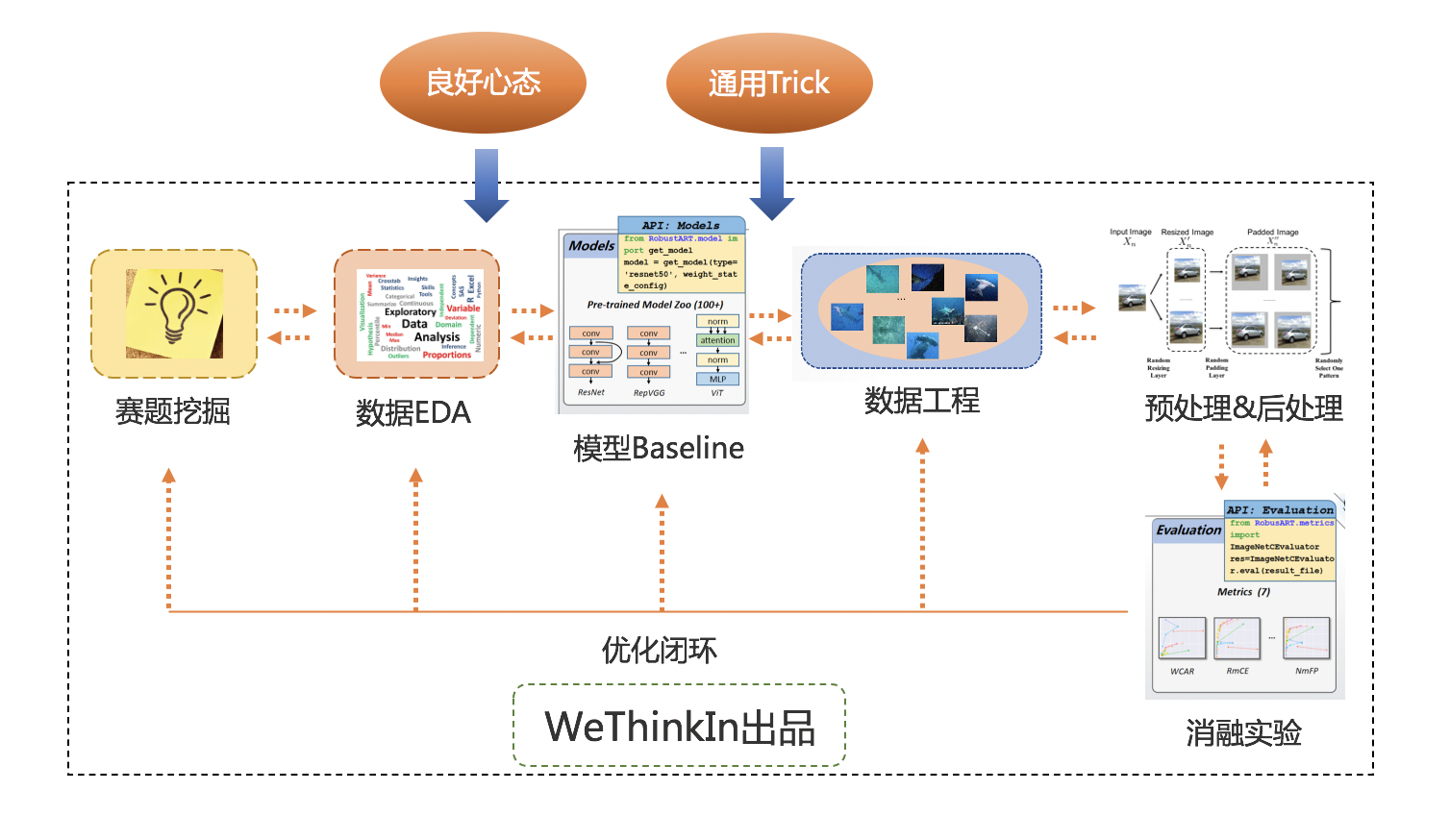
赛题挖掘
在上一节中已经详细阐述,此处就不再赘述。
数据EDA(Exploratory Data Analysis)
磨刀不误砍柴工,对数据进行分析挖掘,从而对数据整体特征有更好的把握。我们可以从下面几个维度入手:
- 数据量级和基本信息
- 是否存在噪声数据/脏数据
- 是否存在小目标
- 是否存在类别不均衡问题
- 理解不同类别的数据特征
- 是否存在难样本
模型Baseline
一般选择SOTA模型或者竞赛打榜热门模型做baseline入场,再针对竞赛赛题的特点对模型结构进行针对性的优化。
比如在成熟领域,图像分类任务先上类ResNet模型,图像分割任务先上类U-Net模型,目标检测任务先上类YOLO模型。
我们可以直接将上述模型的预训练权重进行微调,一般会有不错的效果。搭建模型的框架推荐使用PyTorch,它本身代码比较轻量级,代码逻辑清晰,撰写方便,更重要的是,很多竞赛支持开源库(Fast.ai,Albumentations等)与预训练模型都有PyTorch的API,这让我们的idea能高效实现与验证。
在有了入场模型之后,接着再进行模型的替换,模型结构优化,多模型级联等尝试。
数据工程
针对赛题特点对数据进行增强,包括线下增强和线上增强等,一些常用的数据工程手段有:
- 常规数据增强(crop、pad、flip、resize、rotation、translation、noise等)
- 使用传统CV算法处理数据(传统CV算法API工具化)
- 高级数据增强(interpolation、cutmix、mosaic等)
- 数据特征组合(concate、stack,Patch等)
这里说一句题外话,AI技术发展到现阶段,数据护城河远远超过了模型以及相关的附带技术。所以从工业界角度看,数据价值大于整个比赛,数据价值大于整个比赛,数据价值大于整个比赛。
前处理&后处理
通过一些前处理&后处理算法对模型进行更多的约束,从而提升模型的综合性能:
- 使用传统CV算法做前&后处理。
- 测试时增强(Test Time Augmentation,TTA)
- 设计规则减少bad case。
- 模型集成(竞赛核武)
消融实验
主要可以从以下几个方面进行:
- 损失函数
- 优化器
- 激活函数
- 学习率
- Batch-size、epoch设置
- 正则化
- 阈值设置
- 模型结构
- 其他
同时高效的消融实验非常重要,因为深度学习模型训练时间一般较久,如果一个实验跑一周的话在竞赛中是完全不行的,这就考验参赛队伍的算力以及训练策略了。
持续优化闭环

良好的心态
竞赛短则1-2个月,长则半年,不同的竞赛时间段都需要保持一个合适的心态,在竞赛前期不要放松,在竞赛中期不要焦躁,在竞赛后期冲刺时保持心态平稳。
分类/分割/检测算法竞赛中的实用Tricks
本章节主要介绍AI算法竞赛中的“东邪、西毒、南帝、北丐以及中神通”。而AI算法竞赛的整体氛围,也犹如华山论剑一般,紧张刺激。

- 分类经典模型:ResNet,RVT, Swin,EfficientNet等。
- 分割经典模型:U-Net,deeplab,PSPNet,Mask R-CNN等。
- 检测经典模型:YOLOv5,Faster R-CNN,Cascade R-CNN等。
- Model Exponential Moving Average参数更新策略。
- mixup,cutmix等在线增强策略。
- 余弦退火学习率优化手段。
- 在线样本生成。(难样本,增强样本,小样本)
- Label Smooth。
- Early Stopping。
- 测试时增强(Test Time Augmentation,TTA)
- 模型集成。
- 使用dilation convolution。
- 融合不同维度的特征信息。
- 嵌入注意力机制。
- 增加上下文信息。
- 使用图像Patch的输入进行训练,以减少训练时间。
- 使用伪标签。
- 多尺度训练。
- 借鉴YOLO系列论文中提出的优化点。
- 使用Soft NMS。
- 使用在线难例挖掘(OHEM)
- 使用可形变卷积。
- 交叉验证。
- 使用xavier初始化。
- 传统CV算法辅助支持。
- 其他
打完AI算法竞赛的日子
在新经济周期中,AI算法竞赛一定要和现金流业务拉通,竞赛成果需要快速转化沉淀,形成业务闭环。
并且可以参与到个人和组织的AI品牌软实力&影响力建设中(学术分享,高校合作,科研机构合作,组织竞赛等)
精致的结尾
最后,希望大家能在被压力,竞争,适应,迭代,及时复盘,打榜等关键词汇填充的竞赛周期里,不断成长,不断前进,从容地打完收工。

Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)