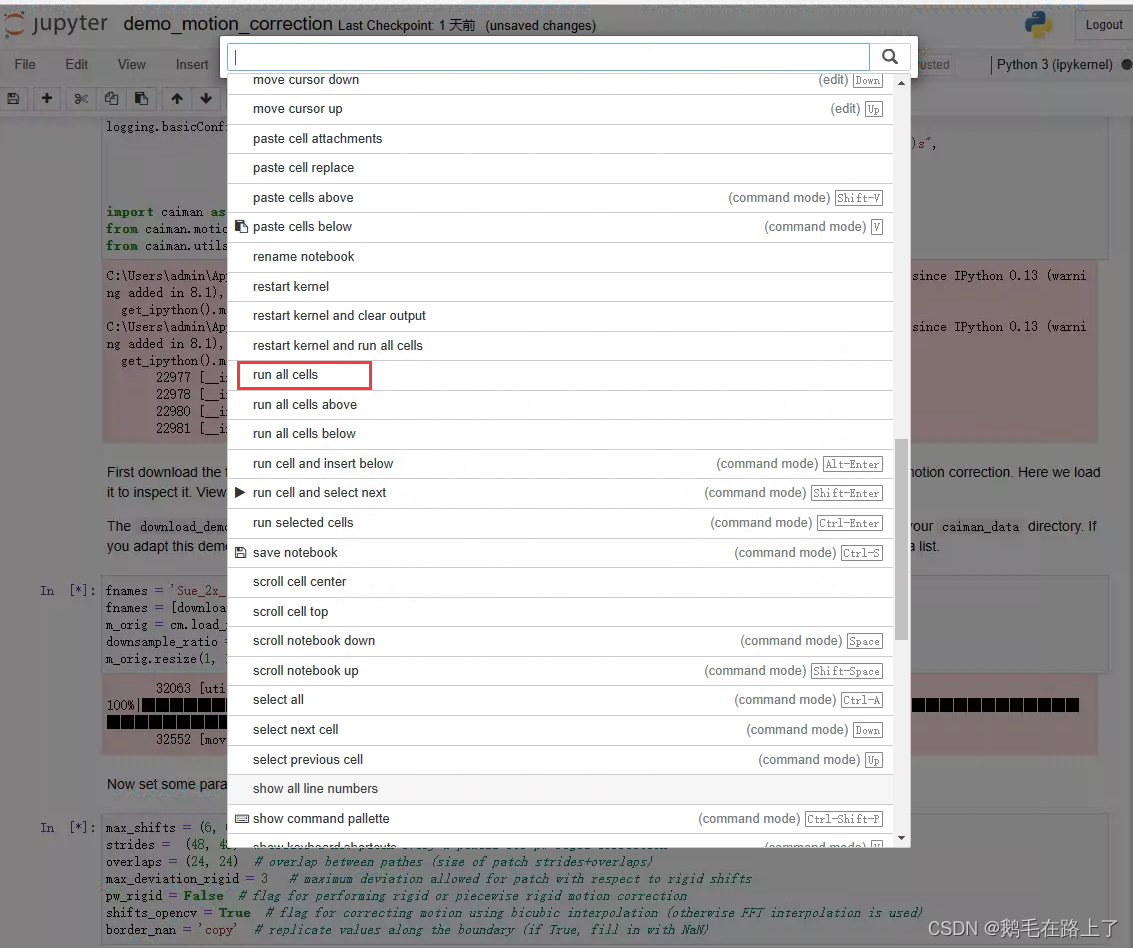
连载文章,长期更新,欢迎关注:
不管是用贝叶斯网络还是因子图,一旦SLAM问题用概率图模型得到表示后,接下来就是利用可观测量(和
)推理不可观测量(
和
),也就是说SLAM问题的求解过程是一个状态估计。在讲解7.4和7.5节具体状态估计方法之前,大家需要先对估计理论[3] p110~138有所了解。
7.3.1 估计量的性质
所谓估计,就是研究某问题时感兴趣的参数不能够通过精确测量得知,只能通过一组观测样本值
猜测参数
的可能取值
,猜测出来的这个
就是估计量。估计量
有时候比较直观,比如研究问题是室内温度,感兴趣的参数
就是室温,通过温度计可以在室内得到一组测量样本值
,对样本值求平均这样最简单的处理可以得到估计温度
。而有些估计量
就不太直观,比如研究问题是机械零件的精密度,感兴趣的参数
就是机械零件误差分布,误差分布需要根据经验设定为某个分布函数
,
是分布函数
的特征量,而观测样本值
是分布函数
上的样本点,也就是说观测样本值
需要通过
与待估计参数
建立联系;再比如研究问题是曲线拟合,感兴趣的参数
是曲线方程
的各个系数,还有很多例子就不一一列举了。
那么估计既然是一种猜测行为,可以毫无根据的瞎猜,也可以依据严密的逻辑策略进行科学的猜测。这就涉及到如何评价估计量的好坏程度,借助估计量的性质可以对估计好坏程度进行评价。估计量的性质主要是一致性和偏差性,下面进一步讨论。
1.一致性
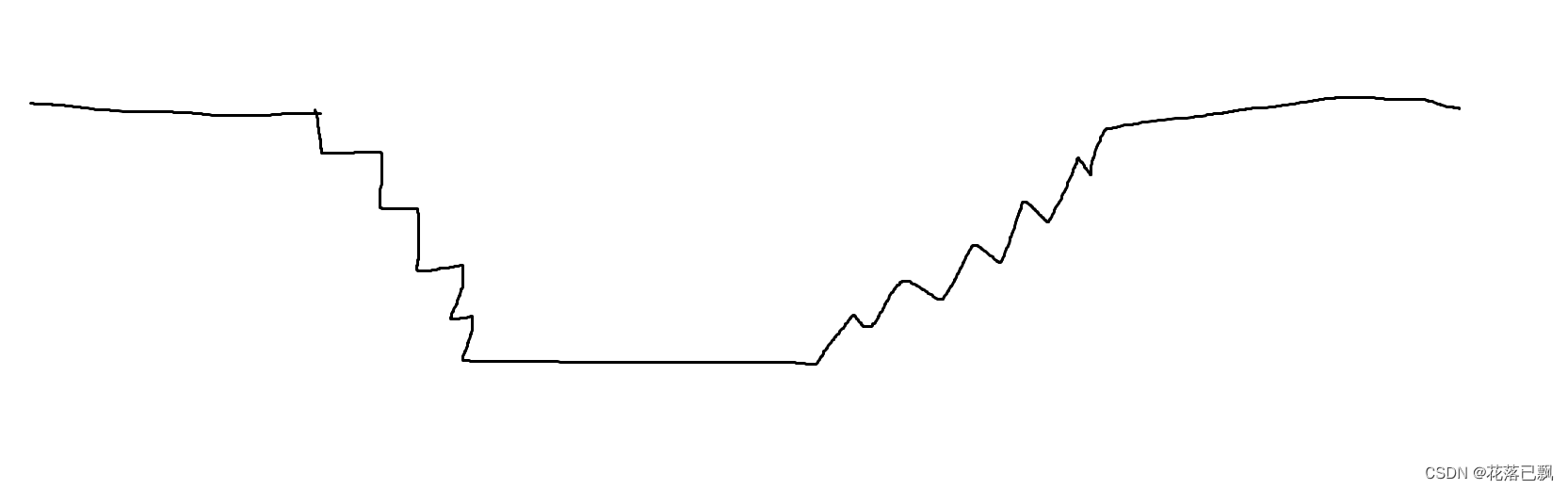
由于估计结果依靠观测样本,当样本数量少的时候可能对真实情况描述不够充分,随样本数量逐渐增多,估计量应该收敛到参数
的实际取值,也就是说估计值应该与实际值保持一致。一致性可以用式(7-51)和式(7-52)表述,第一种是弱一致收敛,当观测值规模k趋于无穷大时,
依概率收敛于
;第二种是强一致收敛,当观测值规模k趋于无穷大时,
严格收敛于
。这两种一致性的直观表达,如图7-1所示。一致性必须保证,不然估计没有意义。

2. 偏差性
实际情况,观测到的样本数量不可能无穷多,因此一致性只是理论上需要满足的条件。在样本数量有限时,讨论估计值与实际值之间的偏差将更有意义,也就是偏差性。可以用估计量的k阶矩来描述,k阶矩在数学中的定义分为k阶原点矩和k阶中心矩,分别如式(7-53)和式(7-54)所示。

一阶原点矩就是期望,二阶中心矩
就是方差,二阶以上的高阶矩过于复杂一般不讨论。如果估计量
的期望等于参数
的实际取值,称为无偏估计。无偏估计只是保证估计量在期望上是正确的,估计量本身还是有不确定性,方差描述了估计量的不确定性,方差越小估计不确定性越小,这就是最小方差估计。显然这里最小是一个模糊的概念,在数学上需要给出严谨的设定,这就是克拉美罗下界(CRLB)[3] p125,由于超出了本书的讨论范围,就不展开了。
7.3.2 估计量的构建
经过上面对估计量性质的讨论,好的估计量应该是最小方差无偏估计(Minimum Variance Unbiased Estimation,MVUE),然而这会非常困难,因此需要寻找近似方法,下面就介绍工程中常用的一些估计量构建方法。
1.最大似然估计
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
2.最小二乘估计
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
3.贝叶斯估计
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
7.3.3 各估计量对比
上面已经介绍了很多常用的估计,既有经典估计(比如最大似然估计、最小二乘估计、...),也有效果可能会更好的贝叶斯估计(比如最小均方误差估计、最大后验估计、……)。当然,这些估计之间既有关联也有区别,往往相互关系还错综复杂,让很多初学者往往摸不着头脑。所以,下面从几个不同的角度对这些估计进行对比,这样将易于读者去理解。
不过,估计理论涉及众多基础数学理论,很多数学理论和学派之间本来就存在各种争论。所以,下面将要讨论对比的角度难免会存在一些不严谨和受争论的点,读者清楚即可。
1.从策略角度对比
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
2.从模型角度对比
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
3.等价转换关系
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
参考文献
【1】 张虎,机器人SLAM导航核心技术与实战[M]. 机械工业出版社,2022.
![UE INI文件操作 INI File Operation [ Read / Write ] 插件说明](https://img-blog.csdnimg.cn/e665ccfb8b9f4d34bac062ec534502c1.png)