文章目录
- 一. 本地模式安装部署
- 1)安装前准备
- 2)配置修改
- 3)操作Zookeeper
- 1.2 配置参数解读
- 二. 分布式安装部署
- 1)集群规划
- 2)解压安装
- 3)配置服务器编号
- 4)配置zoo.cfg文件
- 5)集群操作
- 客户端命令行操作
- 1)启动客户端
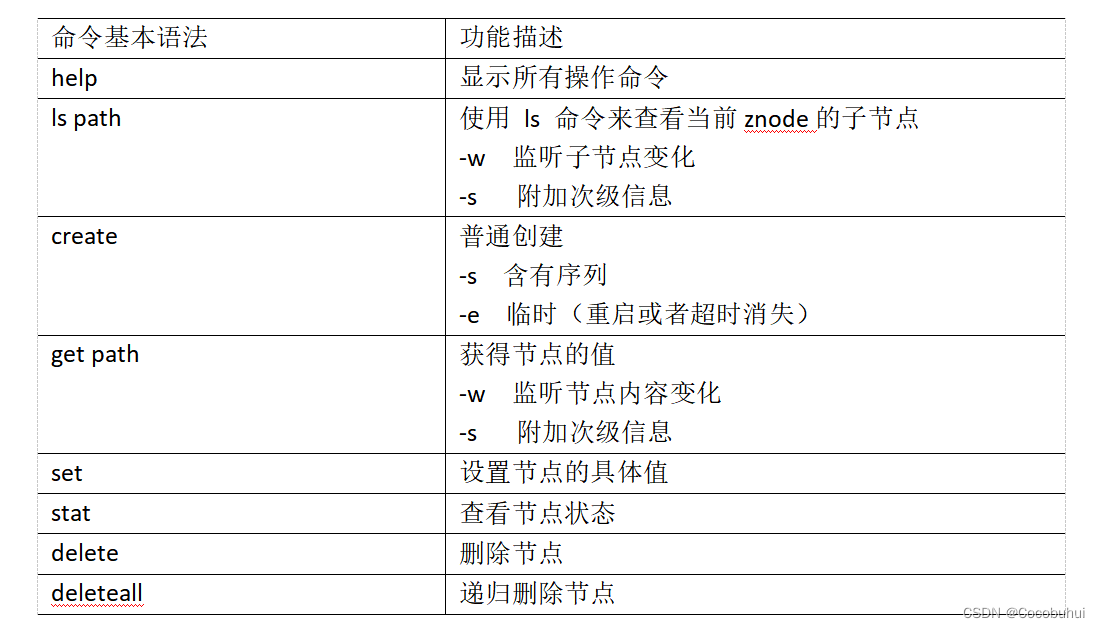
- 2)显示所有操作命令
- 3)查看当前znode中所包含的内容
- 4)查看当前节点详细数据
- 8)创建带序号的节点
一. 本地模式安装部署
1)安装前准备
(1)安装Jdk
(2)拷贝Zookeeper安装包到Linux系统下
(3)解压到指定目录
[atbigdata@hadoop102 software]$ tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/
2)配置修改
(1)将/opt/module/zookeeper-3.5.7/conf这个路径下的zoo_sample.cfg修改为zoo.cfg;
[atbigdata@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
(2)打开zoo.cfg文件,修改dataDir路径:
[atbigdata@hadoop102 zookeeper-3.5.7]$ vim zoo.cfg
修改如下内容:
dataDir=/opt/module/zookeeper-3.5.7/zkData
(3)在/opt/module/zookeeper-3.5.7/这个目录上创建zkData文件夹
[atbigdata@hadoop102 zookeeper-3.5.7]$ mkdir zkData
3)操作Zookeeper
(1)启动Zookeeper
[atbigdata@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
(2)查看进程是否启动
[atbigdata@hadoop102 zookeeper-3.5.7]$ jps
4020 Jps
4001 QuorumPeerMain
(3)查看状态:
[atbigdata@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Mode: standalone
(4)启动客户端:
[atbigdata@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh
(5)退出客户端:
[zk: localhost:2181(CONNECTED) 0] quit
(6)停止Zookeeper
[atbigdata@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh stop
1.2 配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
1)tickTime =2000:通信心跳数,Zookeeper服务器与客户端心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
2)initLimit =10:LF初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
3)syncLimit =5:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
4)dataDir:数据文件目录+数据持久化路径
主要用于保存Zookeeper中的数据。
5)clientPort =2181:客户端连接端口
监听客户端连接的端口。
二. 分布式安装部署
1)集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper。
2)解压安装
(1)解压Zookeeper安装包到/opt/module/目录下
[atbigdata@hadoop102 software]$ tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/
(2)同步/opt/module/zookeeper-3.5.7目录内容到hadoop103、hadoop104
[atbigdata@hadoop102 module]$ xsync zookeeper-3.5.7/
3)配置服务器编号
(1)在/opt/module/zookeeper-3.5.7/这个目录下创建zkData
[atbigdata@hadoop102 zookeeper-3.5.7]$ mkdir -p zkData
(2)在/opt/module/zookeeper-3.5.7/zkData目录下创建一个myid的文件
[atbigdata@hadoop102 zkData]$ touch myid
添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
(3)编辑myid文件
[atbigdata@hadoop102 zkData]$ vi myid
在文件中添加与server对应的编号:2
(4)拷贝配置好的zookeeper到其他机器上
[atbigdata@hadoop102 zkData]$ xsync myid
并分别在hadoop103、hadoop104上修改myid文件中内容为3、4
4)配置zoo.cfg文件
(1)重命名/opt/module/zookeeper-3.5.7/conf这个目录下的zoo_sample.cfg为zoo.cfg
[atbigdata@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
(2)打开zoo.cfg文件
[atbigdata@hadoop102 conf]$ vim zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(3)同步zoo.cfg配置文件
[atbigdata@hadoop102 conf]$ xsync zoo.cfg
(4)配置参数解读
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
5)集群操作
(1)分别启动Zookeeper
[atbigdata@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[atbigdata@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[atbigdata@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
(2)查看状态
[atbigdata@hadoop102 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Mode: follower
[atbigdata@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Mode: leader
[atbigdata@hadoop104 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Mode: follower
客户端命令行操作
1)启动客户端
[atbigdata@hadoop103 zookeeper-3.5.7]$ bin/zkCli.sh
2)显示所有操作命令
[zk: localhost:2181(CONNECTED) 1] help
3)查看当前znode中所包含的内容
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
4)查看当前节点详细数据
[zk: localhost:2181(CONNECTED) 1] ls -s /
[zookeeper]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
5)分别创建2个普通节点
[zk: localhost:2181(CONNECTED) 3] create /sanguo "diaochan"
Created /sanguo
[zk: localhost:2181(CONNECTED) 4] create /sanguo/shuguo "liubei"
Created /sanguo/shuguo
6)获得节点的值
[zk: localhost:2181(CONNECTED) 5] get /sanguo
diaochan
[zk: localhost:2181(CONNECTED) 6] get -s /sanguo
diaochan
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000003
mtime = Wed Aug 29 00:03:23 CST 2018
pZxid = 0x100000004
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 1
[zk: localhost:2181(CONNECTED) 7]
[zk: localhost:2181(CONNECTED) 7] get -s /sanguo/shuguo
liubei
cZxid = 0x100000004
ctime = Wed Aug 29 00:04:35 CST 2018
mZxid = 0x100000004
mtime = Wed Aug 29 00:04:35 CST 2018
pZxid = 0x100000004
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
7)创建临时节点
[zk: localhost:2181(CONNECTED) 7] create -e /sanguo/wuguo "zhouyu"
Created /sanguo/wuguo
(1)在当前客户端是能查看到的
[zk: localhost:2181(CONNECTED) 3] ls /sanguo
[wuguo, shuguo]
(2)退出当前客户端然后再重启客户端
[zk: localhost:2181(CONNECTED) 12] quit
[atbigdata@hadoop104 zookeeper-3.5.7]$ bin/zkCli.sh
(3)再次查看根目录下短暂节点已经删除
[zk: localhost:2181(CONNECTED) 0] ls /sanguo
[shuguo]
8)创建带序号的节点
(1)先创建一个普通的根节点/sanguo/weiguo
[zk: localhost:2181(CONNECTED) 1] create /sanguo/weiguo "caocao"
Created /sanguo/weiguo
(2)创建带序号的节点
[zk: localhost:2181(CONNECTED) 2] create /sanguo/weiguo "caocao"
Node already exists: /sanguo/weiguo
[zk: localhost:2181(CONNECTED) 3] create -s /sanguo/weiguo "caocao"
Created /sanguo/weiguo0000000000
[zk: localhost:2181(CONNECTED) 4] create -s /sanguo/weiguo "caocao"
Created /sanguo/weiguo0000000001
[zk: localhost:2181(CONNECTED) 5] create -s /sanguo/weiguo "caocao"
Created /sanguo/weiguo0000000002
[zk: localhost:2181(CONNECTED) 6] ls /sanguo
[shuguo, weiguo, weiguo0000000000, weiguo0000000001, weiguo0000000002, wuguo]
[zk: localhost:2181(CONNECTED) 6]
如果节点下原来没有子节点,序号从0开始依次递增。如果原节点下已有2个节点,则再排序时从2开始,以此类推。
9)修改节点数据值
[zk: localhost:2181(CONNECTED) 6] set /sanguo/weiguo "caopi"
10)节点的值变化监听
(1)在hadoop104主机上注册监听/sanguo节点数据变化
[zk: localhost:2181(CONNECTED) 26] [zk: localhost:2181(CONNECTED) 8] get -w /sanguo
(2)在hadoop103主机上修改/sanguo节点的数据
[zk: localhost:2181(CONNECTED) 1] set /sanguo "xishi"
(3)观察hadoop104主机收到数据变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/sanguo
11)节点的子节点变化监听(路径变化)
(1)在hadoop104主机上注册监听/sanguo节点的子节点变化
[zk: localhost:2181(CONNECTED) 1] ls -w /sanguo
[aa0000000001, server101]
(2)在hadoop103主机/sanguo节点上创建子节点
[zk: localhost:2181(CONNECTED) 2] create /sanguo/jin "simayi"
Created /sanguo/jin
(3)观察hadoop104主机收到子节点变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/sanguo
12)删除节点
[zk: localhost:2181(CONNECTED) 4] delete /sanguo/jin
13)递归删除节点
[zk: localhost:2181(CONNECTED) 15] deleteall /sanguo/shuguo
14)查看节点状态
[zk: localhost:2181(CONNECTED) 17] stat /sanguo
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000011
mtime = Wed Aug 29 00:21:23 CST 2018
pZxid = 0x100000014
cversion = 9
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 1