从BIO到NIO的转变
- 五种IO模型
- BIO的缺陷
- 非阻塞
- 非阻塞IO(NIO)
- 非阻塞读
- 非阻塞写
- 非阻塞IO模型
- php NIO 实现
- 适用场景
- 什么是C10k问题?
- C10K问题的由来
五种IO模型
在《UNIX 网络编程》一书中介绍了五种IO模型: 分别是 BIO,NIO,IO多路复用器,信号驱动式IO,AIO(异步IO 模型)。
BIO的缺陷
从BIO 到 NIO 在到 多路复用器等 后续的IO模型为什么出现? 是直接就出现了还是说他们之间有因果关系。
技术都有一个发展的过程,促使一个新IO模型的出现一定是老的IO模型存在弊端,新IO模型是为了解决弊端才会出现。
所以这个因果关系就是,BIO(Blocking I/O) 有没有弊端?才促使NIO的出现!
BIO 这种模式要服务多客户端,必须每个客户端连接都需要服务端创建一个线程去处理连接,每个线程又需要调用 accept() ,recv(),clone() 等一系列 系统调用函数,系统调用会造成中断,导致用户态到内核态的切换,加上线程间的切换导致 cpu 一部分时间是没有跑程序而是再跑内核调度的过程,最终得出一个比较浪费cpu资源的结论,为什么会这样?其实是因为进程或者是线程 太多了。
大家有没有想过BIO为什么要创建这么多进程或者线程,想明白这点,你才能找到BIO产生上面说的那些弊端最底层原因。
没错 Blocking(阻塞) 这才是BIO模型最底的弊端,内核给的系统调用 accept() ,recv() 一定是会有一个阻塞发生,就是因为阻塞才导致我们的程序必须不停的创建线程或者进程去处理客户端连接,如果都放在一个进程或者线程中执行就无法服务多个客户端连接

怎么解决 Blocking(阻塞) 这个弊端?
程序员写程序能解决这个问题吗?,你可以试一试不创建多个线程或者进程能不能处理多客户端连接,accept() ,recv()系统调用函数是内核提供的,调用就是有阻塞,所有我们程序员是无能为力了,只能是内核做出改变。
基于内核的改变,才有NIO(nonblock非阻塞IO模型) 的产生,每一种IO模型的出现都是对前一种的升级优化。
非阻塞
阻塞和非阻塞主要的区分是在第一阶段:数据准备阶段。
在第一阶段,当Socket的接收缓冲区中没有数据的时候,阻塞模式下应用线程会一直等待。非阻塞模式下应用线程不会等待,系统调用直接返回错误标志EWOULDBLOCK。
当Socket的接收缓冲区中有数据的时候,阻塞和非阻塞的表现是一样的,都会进入第二阶段等待数据从内核空间拷贝到用户空间,然后系统调用返回。
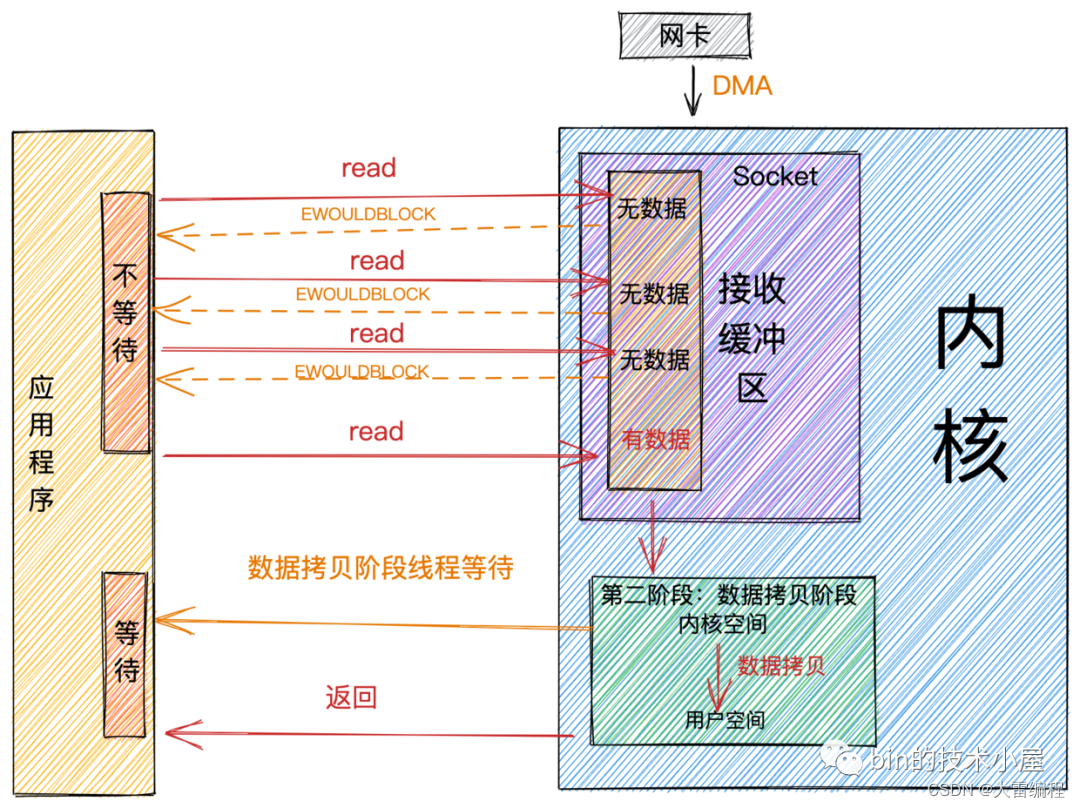
从上图中,我们可以看出:非阻塞的特点是第一阶段不会等待,但是在第二阶段还是会等待。
非阻塞IO(NIO)
阻塞IO模型最大的问题就是一个线程只能处理一个连接,如果这个连接上没有数据的话,那么这个线程就只能阻塞在系统IO调用上,不能干其他的事情。这对系统资源来说,是一种极大的浪费。同时大量的线程上下文切换,也是一个巨大的系统开销。
所以为了解决这个问题,我们就需要用尽可能少的线程去处理更多的连接。,网络IO模型的演变也是根据这个需求来一步一步演进的。
基于这个需求,第一种解决方案非阻塞IO就出现了。我们在上一小节中介绍了非阻塞的概念,现在我们来看下网络读写操作在非阻塞IO下的特点:
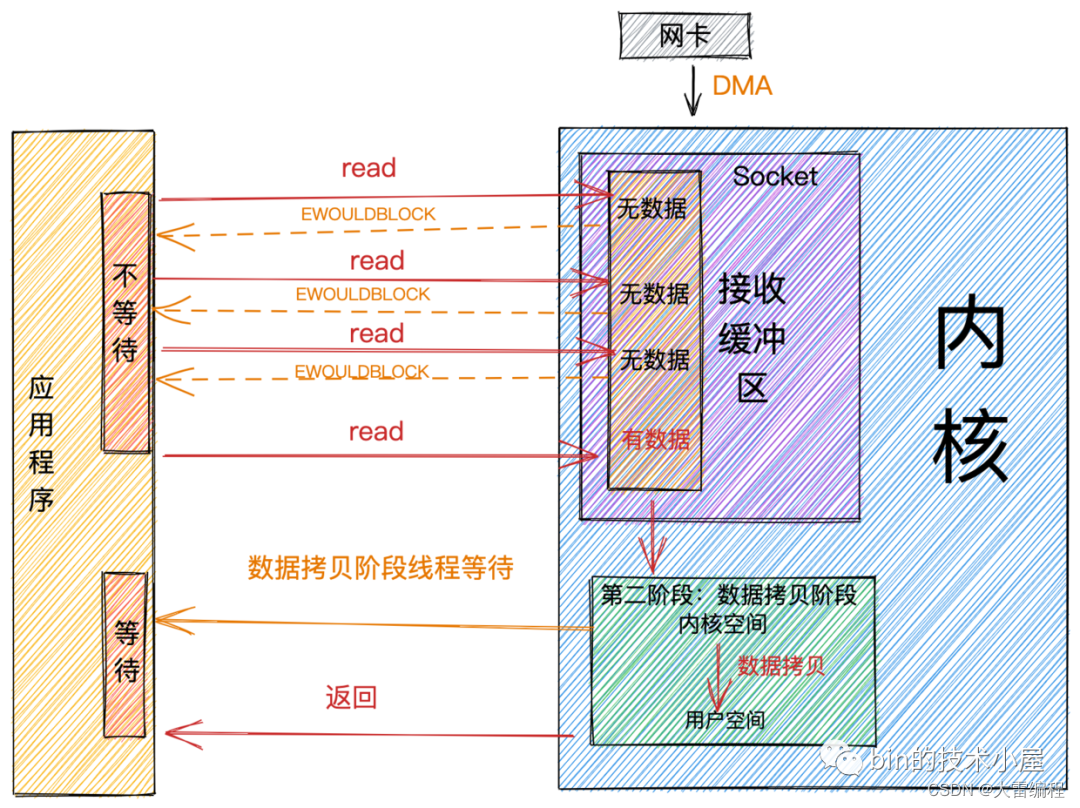
非阻塞读
当用户线程发起非阻塞read系统调用时,用户线程从用户态转为内核态,在内核中去查看Socket接收缓冲区是否有数据到来。
- Socket接收缓冲区中无数据,系统调用立马返回,并带有一个
EWOULDBLOCK或
EAGAIN错误,这个阶段用户线程不会阻塞,也不会让出CPU,而是会继续轮训直到Socket接收缓冲区中有数据为止。 - Socket接收缓冲区中有数据,用户线程在内核态会将内核空间中的数据拷贝到用户空间,注意这个数据拷贝阶段,应用程序是阻塞的,当数据拷贝完成,系统调用返回。
非阻塞写
前边我们在介绍阻塞写的时候提到阻塞写的风格特别的硬朗,头比较铁非要把全部发送数据一次性都写到Socket的发送缓冲区中才返回,如果发送缓冲区中没有足够的空间容纳,那么就一直阻塞死等,特别的刚。
相比较而言非阻塞写的特点就比较佛系,当发送缓冲区中没有足够的空间容纳全部发送数据时,非阻塞写的特点是能写多少写多少,写不下了,就立即返回。并将写入到发送缓冲区的字节数返回给应用程序,方便用户线程不断的轮训尝试将剩下的数据写入发送缓冲区中。
非阻塞IO模型
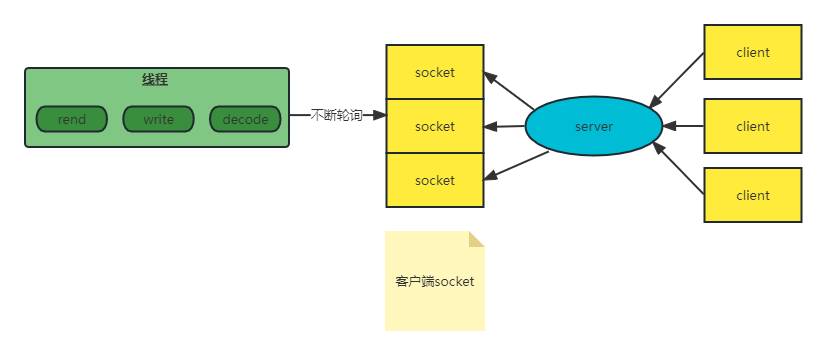
基于以上非阻塞IO的特点,我们就不必像阻塞IO那样为每个请求分配一个线程去处理连接上的读写了。
我们可以利用一个线程或者很少的线程,去不断地轮询每个Socket的接收缓冲区是否有数据到达,如果没有数据,不必阻塞线程,而是接着去轮询下一个Socket接收缓冲区,直到轮询到数据后,处理连接上的读写,或者交给业务线程池去处理,轮询线程则继续轮询其他的Socket接收缓冲区。
这样一个非阻塞IO模型就实现了我们需要用尽可能少的线程去处理更多的连接
php NIO 实现
// 创建 ipv4 tcp socket
$sockfd = socket_create(AF_INET, SOCK_STREAM, 0);
if (!is_resource($sockfd)) {
fprintf(STDOUT, "socket create fail:%s\n", socket_strerror(socket_last_error($this->_sockfd)));
}
// 绑定地址 端口
socket_bind($sockfd,'0.0.0.0',6379);
// 监听 socket
socket_listen($sockfd,10);
// 存放客户端 socket
$client = [];
while (1){
// 设置监听 socket 为非阻塞
socket_set_nonblock($sockfd);
// socket_accept() 设置为非阻塞没有客户端连接将直接返回 false。
$connfd = socket_accept($sockfd);
if(empty($connfd)){
if($client){
// 遍历所有客户端socket 连接,挨个读取看看客户端是否有发送数据到服务端
foreach ($client as $c_fd){
// 读取 socket 上发来的数据,如果未发来数据,立即返回 false ,不会阻塞
$buff = socket_read($c_fd,1024);
if(empty($buff)){
continue;
}
fprintf(STDOUT,"client data: %s\n",$buff);
$biff = "server ok!\n";
socket_write($c_fd,$biff,strlen($biff));
}
}
}else {
// 设置客户端 socket 为非阻塞,当调用socket_read()读取socket发送过来数据,如果为发送数据不产生阻塞,直接返回 false
socket_set_nonblock($connfd);
$client[] = $connfd;
socket_getpeername($connfd,$address,$port);
fprintf(STDOUT, "有客户端连接 ip:%s,port:%d\n",$address,$port);
}
if($client){
foreach ($client as $c_fd){
// 读取 socket 上发来的数据,如果未发来数据,立即返回 false ,不会阻塞
$buff = socket_read($c_fd,1024);
if(empty($buff)){
continue;
}
fprintf(STDOUT,"client data: %s\n",$buff);
$biff = "server ok!\n";
socket_write($c_fd,$biff,strlen($biff));
}
}
}
适用场景
虽然非阻塞IO模型与阻塞IO模型相比,减少了很大一部分的资源消耗和系统开销。
但是它仍然有很大的性能问题,因为在非阻塞IO模型下,需要用户线程或进程去不断地发起系统调用去轮训Socket接收缓冲区,这就需要用户线程不断地从用户态切换到内核态,内核态切换到用户态。随着并发量的增大,这个上下文切换的开销也是巨大的。
所以单纯的非阻塞IO模型还是无法适用于高并发的场景。只能适用于C10K以下的场景。
什么是C10k问题?
著名的C10K并发连接问题(即单机1万个并发连接问题),“C10K”概念最早由Dan Kegel发布于其个人站点,即出自其经典的《The C10K problem 》一文。
C10K问题的由来
大家都知道互联网的基础就是网络通信,早期的互联网可以说是一个小群体的集合。互联网还不够普及,用户也不多,一台服务器同时在线100个用户估计在当时已经算是大型应用了,所以并不存在什么 C10K 的难题。互联网的爆发期应该是在www网站,浏览器,雅虎出现后。最早的互联网称之为Web1.0,互联网大部分的使用场景是下载一个HTML页面,用户在浏览器中查看网页上的信息,这个时期也不存在C10K问题。
Web2.0时代到来后就不同了,一方面是普及率大大提高了,用户群体几何倍增长。另一方面是互联网不再是单纯的浏览万维网网页,逐渐开始进行交互,而且应用程序的逻辑也变的更复杂,从简单的表单提交,到即时通信和在线实时互动,C10K的问题才体现出来了。因为每一个用户都必须与服务器保持TCP连接才能进行实时的数据交互,诸如Facebook这样的网站同一时间的并发TCP连接很可能已经过亿。
这时候问题就来了,最初的服务器都是基于进程/线程模型的,新到来一个TCP连接,就需要分配1个进程(或者线程)。而进程又是操作系统最昂贵的资源,一台机器无法创建很多进程。如果是C10K就要创建1万个进程,那么单机而言操作系统是无法承受的(往往出现效率低下甚至完全瘫痪)。如果是采用分布式系统,维持1亿用户在线需要1万台服务器,成本巨大,也只有Facebook、Google、雅虎等巨头才有财力购买如此多的服务器。
基于上述考虑,如何突破单机性能局限,是高性能网络编程所必须要直面的问题。这些局限和问题最早被Dan Kegel 进行了归纳和总结,并首次成系统地分析和提出解决方案,后来这种普遍的网络现象和技术局限都被大家称为 C10K 问题。