垃圾判断算法
引用计数法
每个对象增加引用计数器,引用加一,失效减一,为零判定为垃圾数据。
缺点:循环引用难以解决
根搜索算法
从树状引用链向下查找,如果对象无法找到,则标记为垃圾数据。
JVM算法
采用根搜索算法,使用虚拟机栈帧中的本地变量表的引用对象、方法区类静态属性引用对象、方法去常量引用对象、Native方法引用对象作为GC Root,向下搜索,两次未找到则标记为垃圾数据后进行回收处理。
第一次标记:标记并覆盖finalize方法,且从未调该方法的对象,放置到F-queue队列。
第二次标记:另一个线程检查F-queue,如果依然判定为垃圾数据则移除队列进行第二次标记。
JVM中的引用
- 强引用(Strong Reference):类似Object obj=new Object这样的直接引用。永远不会回收。
- 软引用(Soft Reference):有用但非必须的对象。抛出内存溢出异常前,将其列入回收范围,进行第二次回收。
- 弱引用(Weak Reference):有用非必须对象。垃圾回收直接回收
- 虚引用(PhantomReference):没有引用,仅用于在回收后得到通知。垃圾回收直接回收。
垃圾回收算法
标记清除法
先标记,再清除
缺点:
1.无法得到连续内存,供其他数据使用
2.标记与清除的地址不连续,效率低
复制算法
将内存分为两部分,第一部分内存用完时,将存活对象复制到第二部分,再全部清除第一部分。
缺点:
1.可利用空间减半
2.数据存活率较高时,需要复制的数据太多
标记整理法
标记过期对象,清除过期对象,将存活对象对齐,保证占用空间连续
分代收集算法
老年代:存活率高,使用标记清理或标记整理算法
新生代:存活率低,使用复制算法
垃圾收集器
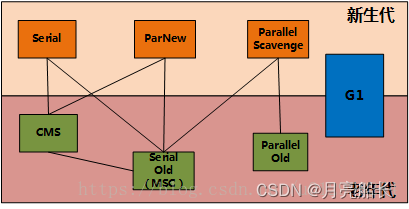
Serial收集器
单线程顺序收集
- 用途:新生代、桌面程序等Client模式,采用复制算法
- 优点:简单高效
- 缺点:收集时造成Stop The Wold暂停所有用户线程
ParNew收集器
多线程顺序收集
- 用途:老年代、Server模式,采用复制算法
- 优点:多CPU环境中GC时系统资源利用效果明显
- 缺点:暂停所有用户线程
Parallel Scavenge收集器
吞吐量优先收集器,并行多线程,使用复制算法
- 用途:新生代、需要大量运算少量交互操作的场景,采用复制算法
- 优点:提高吞吐量(减少GC时资源占用,提高用户代码的资源利用率)
- 缺点:
Serial Old收集器
Serial 老年代单线程收集器,使用标记-整理算法
- 用途:老年代桌面程序等Client模式
- 优点:
- 缺点:
Parallel Old收集器
Parallel Scavenge 老年代收集器,使用多线程,标记-整理算法
- 用途:注重吞吐量的场景
- 优点:提高用户CPU资源利用率
- 缺点:
CMS收集器
并发低停顿收集器,使用多线程,标记-清除算法
- 用途:互联网站、B/S 架构Server端等停顿时间短的场景
- 优点:回收停顿时间短
- 缺点:
- CPU资源占用率高,降低吞吐量
- 无法清除浮动垃圾
- 产生空间碎片过多。
G1收集器
垃圾优先收集器,老年代、年轻代混合管理, 多线程并发分代收集
内存的回收是以region作为基本单位的。Region之间是复制算法,但整体上实际可看作是标记一压缩(Mark一Compact)算法,两种算法都可以避免内存碎片。
详细说明:
https://blog.csdn.net/fengyuyeguirenenen/article/details/123483286
- 用途:服务端应用,物理环境具有大内存
- 优点:减少GC停顿时间的同时提高吞吐量
- 缺点:内存占用率、 CPU利用率较CMS偏高


![[Android]Bitmap Drawable](https://img-blog.csdnimg.cn/accc337971af4ee3839114832f7bffe6.jpeg)