ClickHouse
- 一.特性
- 1.列式数据库管理系统
- 2.数据压缩
- 3.数据的磁盘存储
- 4.支持SQL
- 5.索引
- 6.适合在线查询
- 7.支持数据复制和数据完整性
- 8.实时的数据更新
- 9.处理大量短查询的吞吐量
- 10.处理大量短查询的吞吐量
- 11.限制
- 二.数据类型
- 1.数字类型
- 2.浮点数(float)
- 3.定点数(Decimal(p,s))
- 4.字符串(String)
- 5.固定字符串(FixedString)
- 6.枚举(Enum8,Enum16)
- 7.布尔值(boolean)
- 8.阵列(T)
- 9.日期类型(Date)
- 10.可为空类型
- 三.SQL语法
- 1.insert into
- 2.create
- 3.alter
- 4.limit by
- 5.EXISTS
- 6.COLUMNS
- 7.GROUP BY
- 8.PreWhere
- 9.CONSTRAINT
- 四.部分函数
- 1.自定义函数
- 2.算术函数
- 3.比较函数
- 4.逻辑函数
- 5.类型转换函数
- 6.随机函数
- 7.UUID函数
- 8.字符串函数
- 9.url函数
- 四.表引擎
- 1.MergeTree
- 稀疏索引 :
- 二级索引:
- TTL:
- 2.ReplacingMergeTree
- 3.TinyLog
- 4.Log
- 5.Memory
- 五.优化
- 1.更新删除优化
- 2.查询优化
- 用where条件时:
- 去重时:
- EXPLAIN :
- 3.建表优化
- 定义分区时:
- 定义索引时:
- 存null值时:
- 总计:
- 六.其它
- 1.数据一致性
- 2.集群机制
- 3.数据副本
- 4.查询熔断
- 5.引擎集成
一.特性
1.列式数据库管理系统
除了数据本身外不应该存在其他额外的数据,它是一个数据库管理系统。因为它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置或重启服务。
2.数据压缩
增加性能,且部分列式数据库不存在数据压缩。
针对特定类型数据的专用编解码器。。
3.数据的磁盘存储
ClickHouse被设计用于工作在传统磁盘上的系统,它提供每GB更低的存储成本,但如果可以使用SSD和内存,它也会合理的利用这些资源。 多核心并行处理 ClickHouse会使用服务器上一切可用的资源,从而以最自然的方式并行处理大型查询。
4.支持SQL
ClickHouse支持一种基于SQL的声明式查询语言,它在许多情况下与ANSI SQL标准相同。
5.索引
按照主键对数据进行排序,这将帮助ClickHouse在几十毫秒以内完成对数据特定值或范围的查找。
6.适合在线查询
在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。
7.支持数据复制和数据完整性
一个副本有数据,则会被送到其它副本
8.实时的数据更新
ClickHouse支持在表中定义主键。为了使查询能够快速在主键中进行范围查找,数据总是以增量的方式有序的存储在MergeTree中。因此,数据可以持续不断地高效的写入到表中,并且写入的过程中不会存在任何加锁的行为。
9.处理大量短查询的吞吐量
如果一个查询使用主键并且没有太多行(几十万)进行处理,并且没有查询太多的列,那么在数据被page cache缓存的情况下,它的延迟应该小于50毫秒(在最佳的情况下应该小于10毫秒)。 否则,延迟取决于数据的查找次数。如果你当前使用的是HDD,在数据没有加载的情况下,查询所需要的延迟可以通过以下公式计算得知: 查找时间(10 ms) * 查询的列的数量 * 查询的数据块的数量。
10.处理大量短查询的吞吐量
在相同的情况下,ClickHouse可以在单个服务器上每秒处理数百个查询(在最佳的情况下最多可以处理数千个)。但是由于这不适用于分析型场景。因此我们建议每秒最多查询100次
11.限制
没有完整的事务支持。
缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR。
稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
二.数据类型
1.数字类型
int8 8字节 int16 16字节 …Uint8 …无符号整型数
--Int8 — TINYINT, BOOL, BOOLEAN, INT1.
--Int16 — SMALLINT, INT2.
--Int32 — INT, INT4, INTEGER.
--Int64 — BIGINT
2.浮点数(float)
不建议使用,可能会导致精度丢失.
3.定点数(Decimal(p,s))
精度。有效范围:[1:38],决定可以有多少个十进制数字(包括分数)。S - 规模。有效范围:[0:P],决定数字的小数部分中包含的小数位数
4.字符串(String)
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。因此,字符串类型可以代替其他 DBMS 中的 VARCHAR、BLOB、CLOB 等类型。
5.固定字符串(FixedString)
固定长度 N 的字符串(N 必须是严格的正自然数).如果字符串包含的字节数少于`N’,将对字符串末尾进行空字节填充。如果字符串包含的字节数大于N,将抛出Too large value for FixedString(N)异常。
6.枚举(Enum8,Enum16)
CREATE TABLE t_enum
(
x Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog;
insert into t_enum values ('hello'),('hello');
SELECT * from t_enum;
如果需要看到对应行的数值,则必须将 Enum 值转换为整数类型。
SELECT CAST(x, 'Int8') FROM t_enum;
7.布尔值(boolean)
从19.0.49 之后,有单独的类型来存储布尔值。
在此之前的版本,没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
8.阵列(T)
由 T 类型元素组成的数组。
T 可以是任意类型,包含数组类型。 但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。
--创建array数组两种方式
--array(T)
--[]
ClickHouse会自动检测数组元素,并根据元素计算出存储这些元素最小的数据类型
如果在元素中存在 NULL 或存在 可为空 类型元素,那么数组的元素类型将会变成 可为空
不兼容的数据类型数组,ClickHouse 将引发异常。
SELECT array(1, 2) AS x, toTypeName(x);
SELECT toTypeName(160000);
SELECT
[1, 2] AS x,--[1,2]
toTypeName(x);--Array(UInt8)
9.日期类型(Date)
支持字符串 ‘2021-01-01’。
但最终完全支持的年份为2105。
最小值输出为1970-01-01。
时间日期类型(DateTime64)
‘2021-01-01 11:06:28.234’
10.可为空类型
Nullable(Int8) 类型的列可以存储 Int8 类型值,而没有值的行将存储 NULL。
对于 TypeName,不能使用复合数据类型 阵列 和 元组。
复合数据类型可以包含 Nullable 类型值,例如Array(Nullable(Int8))。
CREATE TABLE t_null(x Int8, y Nullable(Int8)) ENGINE TinyLog;
INSERT INTO t_null VALUES (1, NULL), (2, 3);
INSERT INTO t_null VALUES (1, 'true'); -- 存储的为 1 null
注:尽量不使用
要在表的列中存储 Nullable 类型值, NULL 有掩码的单独文件。 由于附加了新文件,Nullable 列与类似的普通文件相比消耗额外的存储空间。
三.SQL语法
1.insert into
--语法
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
ClickHouse有2类解析器:完整SQL解析器(递归式解析器),以及数据格式解析器(快速流式解析器)
INSERT查询会同时使用2种解析器,其它情况下仅使用完整SQL解析器。
INSERT INTO t VALUES 的部分由完整SQL解析器处理,
包含数据的部分(2, ‘abc’)…交给快速流式解析器解析。
通过设置参数 input_format_values_interpret_expressions 可以自定义。
实例
CREATE TABLE insert_select_testtable
(
`a` Int8,
`b` String,
`c` Int8
)
ENGINE = MergeTree()
ORDER BY a;
-- 插入值 除了b
INSERT INTO insert_select_testtable (* EXCEPT(b)) Values (2, 2);--
SELECT * from insert_select_testtable ist ;
--数据可以以ClickHouse支持的任何 输入输出格式 传递给INSERT。格式的名称必须显示的指定在查询中
INSERT INTO [db.]table [(c1, c2, c3)] FORMAT Values (v11, v12, v13), (v21, v22, v23), ...
--注 无DEFAULT表达式,才则填充零或空字符串
-- 可以使用SELECT的结果写入
INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...;
-- 插入表函数
INSERT INTO [TABLE] FUNCTION table_func ...;
CREATE TABLE simple_table (id UInt32, text String) ENGINE=MergeTree() ORDER BY id;
INSERT INTO TABLE FUNCTION remote('localhost', default.simple_table)
VALUES (100, 'inserted via remote()');
SELECT * FROM simple_table;
INSERT INTO [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
--使用上面的语句可以从客户端的文件上读取数据并插入表中,file_name 和 type 都是 String 类型,输入文件的格式 一定要在 FORMAT 语句中设置。
性能问题
在进行INSERT时将会对写入的数据进行一些处理,按照主键排序,按照月份对数据进行分区等
通过设置async_insert可以进行异步插入。
2.create
–创建数据库
CREATE DATABASE [IF NOT EXISTS] db_name;
–创建表
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine;
MATERIALIZED物化表达式
被该表达式指定的列不会被INSERT且SELECT *也不会显示,因为它总是被计算出来的。
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine];
建的只是表结构 如果没有表引擎声明,则创建的表将与db2.name2使用相同的表引擎。
临时表
–临时表仅能够使用Memory表引擎。
–当回话结束时,临时表将随会话一起消失
–无法为临时表指定数据库。它是在数据库之外创建的
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
);
CREATE VIEW
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
);
3.alter
*注:ALTER 仅支持 MergeTree ,Merge以及Distributed等引擎表。
列操作
ALTER TABLE [db].name [ON CLUSTER cluster] ADD 添加|DROP 删除|CLEAR 清空|COMMENT 注释|MODIFY COLUMN 改变值类型 …
删除列
ALTER TABLE [db].name DROP COLUMN [IF EXISTS] name;
改变列的类型
ALTER TABLE visits MODIFY COLUMN browser Array(String);
改变的过程
–为修改的数据准备新的临时文件
–重命名原来的文件
–将新的临时文件改名为原来的数据文件名
–删除原来的文件
ALTER 操作限制
–不支持对primary key或者sampling key中的列(在 ENGINE 表达式中用到的列)进行删除操作
–ALTER 操作会阻塞对表的所有读写操作。
–即当一个大的 SELECT 语句和 ALTER同时执行时,ALTER会等待,直到 SELECT 执行结束
–对于不存储数据的表(例如 Merge 及 Distributed 表), ALTER 仅仅改变了自身的表结构,不会改变从属的表结构。
更改约束
ALTER TABLE [db].name ADD CONSTRAINT constraint_name CHECK expression;
ALTER TABLE [db].name DROP CONSTRAINT constraint_name;
修改用户
ALTER USER [IF EXISTS] name [ON CLUSTER cluster_name]
[RENAME TO new_name]
[IDENTIFIED [WITH {PLAINTEXT_PASSWORD|SHA256_PASSWORD|DOUBLE_SHA1_PASSWORD}] BY {'password'|'hash'}]
[[ADD|DROP] HOST {LOCAL | NAME 'name' | REGEXP 'name_regexp' | IP 'address' | LIKE 'pattern'} [,...] | ANY | NONE]
[DEFAULT ROLE role [,...] | ALL | ALL EXCEPT role [,...] ]
[SETTINGS variable [= value] [MIN [=] min_value] [MAX [=] max_value] [CONST|READONLY|WRITABLE|CHANGEABLE_IN_READONLY] | PROFILE 'profile_name'] [,...]
修改settings配置
ALTER SETTINGS PROFILE [IF EXISTS] name [ON CLUSTER cluster_name]
[RENAME TO new_name]
[SETTINGS variable [= value] [MIN [=] min_value] [MAX [=] max_value] [CONST|READONLY|WRITABLE|CHANGEABLE_IN_READONLY] | INHERIT 'profile_name'] [,...]
将除了 role1 和 role2之外的其它角色 设为默认
ALTER USER user DEFAULT ROLE ALL EXCEPT role1, role2
使用alter更改
使用alter进行删除和修改
create table te_DeUp1(
id UInt8,
name String,
comm FixedString(4) default '1234'
)Engine = Memory();
alter table te_DeUp1 delete where id =1; --删除id为1的
alter table te_DeUp1 update id=2 where id =1; --修改
注:这种修改和删效率极低。
4.limit by
LIMIT BY与LIMIT没有关系。它们可以在同一个查询中使用
CREATE TABLE limit_by(id Int, val Int) ENGINE = Memory;
INSERT INTO limit_by VALUES (1, 10), (1, 11), (1, 12), (2, 20), (2, 21);
SELECT * FROM limit_by ORDER BY id, val LIMIT 2 BY id<=1;
insert into limit_by values(2,20);
5.EXISTS
如果表或数据库不存在,则包含一个值 0,如果表在指定的数据库中存在,则包含一个值 1。
EXISTS [TEMPORARY] [TABLE|DICTIONARY] [db.]name [INTO OUTFILE filename] [FORMAT format]
6.COLUMNS
CREATE TABLE default.col_names (aa Int8, ab Int8, bc Int8) ENGINE = TinyLog;
SELECT COLUMNS('a'), COLUMNS('c'), toTypeName(COLUMNS('c')) FROM col_names;
SELECT COLUMNS('a') from col_names ;--aa -ab
想当于like ‘a’;
7.GROUP BY
group by 中 null 作为一个值也会进行分组
,
b String
)engine = Memory();
INSERT into te_group2 values(1,'2'),(1,'3'),(2,'3'),(2,'4'),(NULL,'2'),(NULL,'3');
SELECT a from te_group2 group by a;
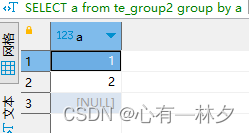
GROUP BY ALL 相当于对所有被查询的并且不被聚合函数使用的字段进行GROUP BY。
8.PreWhere
使用 prewhere选一列数据 代替where 选一行数据
功能和where一样
prewhere先查某列过滤之后的数据再通得到的数据求其它列,并不是单行扫描
只支持*MergeTree()引擎系列
ptimize_move_to_prewhere 设置为0 则关闭wehre到prewhere自动转换
9.CONSTRAINT
语法
constraint_name_1 CHECK boolean_expr_1, boolean_expr_1
测试
create table t_materialized4(
id Int8 ,
name String,
age Int8
)ENGINE = MergeTree()
order by age;
ALTER TABLE t_materialized4 ADD CONSTRAINT constraint_age CHECK age>18;
insert into t_materialized4 values(1,'name',20);
insert into t_materialized4 values(1,'name',14);
SELECT * FROM t_materialized4 ;

如果为表定义了约束,则将为表中的每一行检查它们中的每一行
四.部分函数
1.自定义函数
语法
CREATE FUNCTION name AS (parameter0, ...) -> expression
一个函数可以有任意数量的参数。
实例
CREATE FUNCTION linear_equation AS (x, k, b) -> k*x + b;
SELECT number, linear_equation(number, 2, 1) FROM numbers(3);

限制
命名不重复
不能是递归函数
定义时的参数和使用时的参数一致
2.算术函数
select plus(toDateTime('2012-01-01 20:35:26'),2);
-- datetime格式加的是秒 在Date的情况下,和整数相加整数意味着添加相应的天数。
--相减 同上
select minus(a, b);
--计算数值的商。结果类型始终是浮点类型
divide(a, b)
SELECT negate(-1);
--通过改变数值的符号位对数值取反,结果总是有符号的

SELECT gcd(15,5);
--返回数值的最大公约数。 除以零或将最小负数除以-1时抛出异常。

--返回数值的最大公约数。 除以零或将最小负数除以-1时抛出异常。
SELECT lcm(15,5);
--返回数值的最小公倍数。 除以零或将最小负数除以-1时抛出异常。
SELECT max2(-1, 2.5); --2.5
--比较两个值并返回最大值。min2
3.比较函数
--比较函数始终返回0或1(UInt8)
-- 比较的类型 数字 String 和 FixedString 日期 日期时间
-- 不同组的类型间不能够进行比较
SELECT 2>=1; --1
SELECT 2>=2; --1
SELECT 2<>2; --0
4.逻辑函数
-- 逻辑函数可以接受任何数字类型的参数,并返回UInt8类型的0或1。
--当向函数传递零时,函数将判定为«false»,否则,任何其他非零的值都将被判定为«true»。
-- and 与 or或 not 非 XOR异或
5.类型转换函数
注意:这是一个不安全的操作,可能导致数据的丢失
-- toInt(8|16|32|64) 有效数字之前的0也会被忽略
SELECT toInt32(32), toInt16('16'), toInt8(8.8);--32 --16 --8
--toInt(8|16|32|64)OrZero 转换失败返回0 toInt(8|16|32|64)OrNull 转换失败返回null
select toInt64OrZero('123123'), toInt8OrZero('123qwe123'); --123123 0
--toDecimal(32|64|128) toDateTime toFloat(32|64) toFloat(32|64)OrZero等相同
--当将Date转换为数字或反之,Date对应Unix时间戳的天数。 将DataTime转换为数字或反之,DateTime对应Unix时间戳的秒数。
--toString
-- 注意1. 这些函数用于在数字、字符串(不包含FixedString)、Date以及DateTime之间互相转换。 所有的函数都接受一个参数。
--2.toDate/toDateTime函数的日期和日期时间格式定义如下:
--YYYY-MM-DD
--YYYY-MM-DD hh:mm:ss
--3.如果将UInt32、Int32、UInt64或Int64类型的数值转换为Date类型,并且其对应的值大于等于65536,则该数值将被解析成unix时间戳(而不是对应的天数)
SELECT toDate(65536); --1970-01-02
--4。Date与DateTime之间的转换以更为自然的方式进行:通过添加空的time或删除time。
SELECT toDate(toDateTime('2021-03-03')); --2021-03-03
--5. 可以包含时区 DateTime参数的toString函数可以在第二个参数中包含时区名称
SELECT
now() AS now_local,
toString(now(), 'Asia/Yekaterinburg') AS now_yekat;--2023-01-19 16:09:42 --2023-01-19 13:09:42
select timeZone();
--INTERVAL 时间间隔
SELECT now() AS current_date_time, current_date_time + INTERVAL 4 DAY + INTERVAL 3 HOUR;
--2023-01-19 16:11:26 --2023-01-23 19:11:26
-- 6.toFixedString(s,N)
--将String类型的参数转换为FixedString(N)类型的值(具有固定长度N的字符串)。
--N必须是一个常量。 如果字符串的字节数少于N,则向右填充空字节。如果字符串的字节数多于N,则抛出异常
CAST(x, T)
将’x’转换为’t’数据类型。还支持语法CAST(x AS t)
SELECT
'2016-06-15 23:00:00' AS timestamp, --2016-06-15 23:00:00
CAST(timestamp AS DateTime) AS datetime,--2016-06-15 23:00:00
CAST(timestamp AS Date) AS date,--2016-06-15
CAST(timestamp, 'String') AS string,--2016-06-15 23:00:00
CAST(timestamp, 'FixedString(22)') AS fixed_string;--2016-06-15 23:00:00
INTERVAL
表示时间和日期间隔
SELECT now() as current_date_time, current_date_time + INTERVAL 4 DAY;
--2023-01-19 16:14:05 --2023-01-23 16:14:05
--!!! warning "警告" Interval 数据类型值不能存储在表中。
6.随机函数
随机函数使用非加密方式生成伪随机数字。
可以传一个参数,但参数不影响随机数的结果,参数的唯一目的是防止公共子表达式消除。
SELECT rand();
--
--rand64 返回一个UInt64类型的随机数字
--rand, rand32 返回一个UInt32类型的随机数字
7.UUID函数
--生成一个UUID
SELECT generateUUIDv4();
--e3e3b17f-0460-4f24-a19e-dbdbc87d63f6
建表时指定UUID类型
CREATE TABLE t_uuid (x UUID) ENGINE=TinyLog;
INSERT INTO t_uuid SELECT generateUUIDv4();
SELECT * FROM t_uuid;
将String类型的值转换为UUID类型的值
toUUID(String);
8.字符串函数
SELECT LENGTH('tit.name');--8
--返回字符串的字节长度
lower()lcase()
--将字符串中的ASCII转换为小写。
upper ucase()
--将字符串中的ASCII转换为大写
reverse();
--翻转字符串。
SELECT concat('"s1"','"s2"');--8
--将参数中的多个字符串拼接,不带分隔符。
substring(s,offset,length)
--’offset’从1开始(与标准SQL相同)。’offset’和’length’参数必须是常量。
endsWith(s,后缀) startsWith(s,前缀) 相反
--返回是否以指定的后缀结尾。如果字符串以指定的后缀结束,则返回1,否则返回0。
SELECT trimLeft(' s');--s
--返回一个字符串,用于删除左侧的空白字符。
SELECT LENGTH (trimRight('s ')); --1
--返回一个字符串,用于删除右侧的空白字符。
SELECT LENGTH (trimBoth(' s '));--1
--返回一个字符串,用于删除任一侧的空白字符
SELECT replaceOne('haystack', 'stack', '-replacement');--hay-replacement
replaceOne(haystack, pattern, replacement)
--用’replacement’子串替换’haystack’中第一次出现的’pattern’子串(如果存在)。
--’pattern’和’replacement’必须是常量。
replaceAll(haystack, pattern, replacement), replace(haystack, pattern, replacement)
--用’replacement’子串替换’haystack’中出现的所有的’pattern’子串。
9.url函数
SELECT topLevelDomain('https://www.runoob.com/jquery/jquery-intro.html');--com
--返回顶级域名
SELECT cutToFirstSignificantSubdomain('https://www.runoob.com/jquery/jquery-intro.html');--runoob.com
--返回包含顶级域名与第一个有效子域名之间的内容
SELECT pathFull('https://www.runoob.com/jquery/jquery-intro.html');--/jquery/jquery-intro.html
--去除域名 但包括请求参数和fragment例如:/top/news.html?page=2#comments
SELECT extractURLParameter('https://blog.csdn.net/qq_46058550/article/details/128716298?spm=1001.2014.3001.5502','spm');
--1001.2014.3001.5502
--返回URL请求参数中名称为’name’的参数。如果不存在则返回一个空字符串。如果存在多个匹配项则返回第一个相匹配的
注:在聚合过程中,所有 NULL 被跳过。
四.表引擎
1.MergeTree
Clickhouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。
数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。
语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr --分区内排序
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
注意:
主键必须是 OrderBy字段的前缀字段。
主机是稀疏索引。
稀疏索引 :
隔中间会有索引 不是每行都有, 查询时用二分。
二级索引:
建表时指定。
对1级索引分的区间再统一 GRANULARITY 3 对1级索引分的3区间统一为一个二级索引。
CREATE TABLE table_name
(
u64 UInt64,
i32 Int32,
s String,
...
INDEX a (u64 * i32, s) TYPE minmax GRANULARITY 3,
INDEX b (u64 * length(s)) TYPE set(1000) GRANULARITY 4
) ENGINE = MergeTree()
...
TTL:
TTL用于设置值的生命周期,它既可以为整张表设置,也可以为每个列字段单独设置。
其不能是主键所在的且计算结果必须是 日期 或 日期时间 类型的字段。
为列设置时
CREATE TABLE example_table
(
d DateTime,
a Int TTL d + INTERVAL 1 MONTH,
b Int TTL d + INTERVAL 1 MONTH,
c String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;
为表中已存在的列字段添加 TTL
ALTER TABLE example_table
MODIFY COLUMN
c String TTL d + INTERVAL 1 DAY;
修改列字段的 TTL
ALTER TABLE example_table
MODIFY COLUMN
c String TTL d + INTERVAL 1 MONTH;
表可以设置一个用于移除过期行的表达式:
DELETE - 删除过期的行(默认操作);
TO DISK ‘aaa’ - 将数据片段移动到磁盘 aaa;
TO VOLUME ‘bbb’ - 将数据片段移动到卷 bbb.
GROUP BY - 聚合过期的行
创建一张表,设置一个月后数据过期,这些过期的行中日期为星期一的删除:
CREATE TABLE table_with_where
(
d DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH DELETE WHERE toDayOfWeek(d) = 1;
创建一张表,设置过期的列会被聚合。列x包含每组行中的最大值,y为最小值,d为可能任意值
CREATE TABLE table_for_aggregation
(
d DateTime,
k1 Int,
k2 Int,
x Int,
y Int
)
ENGINE = MergeTree
ORDER BY (k1, k2)
TTL d + INTERVAL 1 MONTH GROUP BY k1, k2 SET x = max(x), y = min(y);
2.ReplacingMergeTree
该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行。有一些数据可能仍未被处理OPTIMIZE 语句会引发对数据的大量读写。
建表
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
行的唯一性由ORDERBY表部分决定,而不是由PRIMARY KEY决定。
ver — 版本列。类型为 UInt*, Date 或 DateTime。可选参数。
在数据合并的时候,ReplacingMergeTree 从所有具有相同排序键的行中选择一行留下:
如果 ver 列未指定,保留最后一条。
如果 ver 列已指定,保留 ver 值最大的版本。
CREATE TABLE mySecondReplacingMT
(
`key` Int64,
`someCol` String,
`eventTime` DateTime
)
ENGINE = ReplacingMergeTree(eventTime)
ORDER BY key;
3.TinyLog
不支持索引
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中。写入时,数据将附加到文件末尾。
不支持并发读写 先读后写抛异常,先写后读 数据错误
此引擎适用于相对较小的表
当您拥有大量小表时,可能会导致性能低下。
4.Log
不支持索引
Log 与 TinyLog 的不同之处在于,«标记» 的小文件(里面存储偏移量)与列文件存在一起。
这些偏移量指示从哪里开始读取文件以便跳过指定的行数
Log引擎适用于临时数据,write-once 表以及测试或演示目的。
5.Memory
存储在内存中,数据重启则数据消失
不支持索引 效率高,一般用于测试(上限大概1亿行)
主要用于测试(在简单查询上达到最大速率(超过10 GB /秒))
五.优化
1.更新删除优化
定义版本号字段_version,更新的时候就插入一条数据,然后版本号+1。
_sign UInt8 – 0,1表示是否删除
查询时
where _sign=0 and _version最大
问题:时间就了,数据膨胀。
解决:定时清空一下无用的数据。
2.查询优化
用where条件时:
使用 prewhere选一列数据 代替where 选一行数据(一般查询时会自动转换)
因为prewhere先查某列过滤之后的数据再通得到的数据求其它列,并不是单行扫描。
限制就是只支持*MergeTree()引擎系列。
注意:optimize_move_to_prewhere 设置为0 则关闭wehre到prewhere自动转换。
去重时:
distinct() 精确去重
uniqCombined() 近似去重
但第二个效率高。
EXPLAIN :
SYNTAX 查看真正执行的SQL即自动(优化后的SQL)
explain SYNTAX SELECT sum(id*2) FROM te_DeUp tdu ;

3.建表优化
定义分区时:
常规按天就行,
大致1一亿条数据分30个区。
定义索引时:
频率优先。其次是重复少,基数大的不建议。
存null值时:
因为null值ClickHouse会独立的搞一个文件。
所以null值我们可以用 对应类型无意义的值充当即
null 值 string 存 空串
null 值 数字 存 -1
总计:
1.选择合适的表引擎
2.建表时尽量不要使用null
3.注意分区和索引
分区 有date的话尽量使用date 没有分区数据尽量不超过一百万行
4.数据变更优化
clickhouse的增删改都会产生新的临时分区,操作数据也不能过快
每一秒 一次 每次操作在2-5w数据之间
5.使用 prewhere选一列数据 代替where 选一行数据
6.尽量使用 in 代替 join (会把另一张表放内存中) 通常join 小表在前 大表在后
4.其它优化
配置优化方面
users.xml里面 <max_memory_usage> 单任务使用的内存上限
六.其它
1.数据一致性
1.手动 optimize table tablename final;
2.通过sql语法通常是(GroupBy)
3.业务上保证 使用乐观锁 加一个字段
2.集群机制
基本做单机, 数据备份 数据分开存,查询消耗。
因为ClickHouse 特别吃资源,所以一般一台机只部署一个ClickHouse也就行了。
3.数据副本
通过zookeeper 基于表做副本
4.查询熔断
1.用户周期内频繁慢查询,则不进行查询
2. 设置单个查询时间,超出则不进行查询
5.引擎集成
无集成时
1.mysql数据
2.导入 ck
3.然后查询ck
集成后:
ck 直接映射到mysql表上面 无需导入
可集成的引擎