笔记整理:张嘉芮,天津大学硕士
链接:https://aclanthology.org/2021.findings-acl.278.pd
动机
传统的数据驱动方法不适用于零样本和少样本的场景。对于人类来说,常识知识是理解和推理的关键因素。在没有标注数据和用户立场的隐晦表达的情况下,引入常识性的关系知识作为推理支持,可以进一步提高模型在零样本和少样本场景下的泛化和推理能力。
亮点
本文的亮点主要包括:
(1)从外部结构知识库ConceptNet引入常识知识
(2)引入了一个基于图卷积网络的常识知识增强模块,利用关系子图的结构层和语义层信息,可以进一步增强模型的泛化和推理能力。
模型
问题定义:
形式上,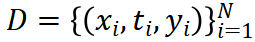 表示包含N个样本的零样本立场检测数据集,其中 为文档, 为对应主题, 为立场标签。该任务的目标是获得给定 的立场标签 。为了连接文档和主题,作者引入了一个从外部KG中提取的常识知识子图G = (V, E),其中V是概念的子集,E表示概念之间的关系。
表示包含N个样本的零样本立场检测数据集,其中 为文档, 为对应主题, 为立场标签。该任务的目标是获得给定 的立场标签 。为了连接文档和主题,作者引入了一个从外部KG中提取的常识知识子图G = (V, E),其中V是概念的子集,E表示概念之间的关系。
框架:
模型整体框架如下:
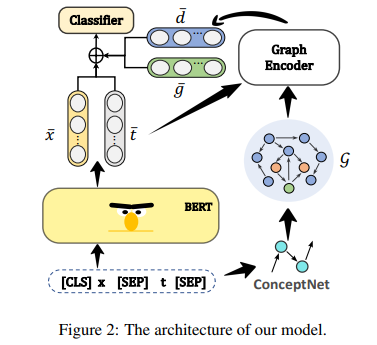
1.BERT编码
作者使用预训练的语言模型BERT对文档x和主题t进行编码。具体来说,作者将x和t以以下格式连接成一个输入序列:[CLS] x [SEP] t [SEP]。然后,输入序列送入BERT获取上下文表示X = {x1 , … , xm}文档和T = {t1 , … , tn}为主题,m和n的长度是分别文档和主题。最后,可以得到文档和主题的平均表示 和 )。
2.Knowledge Graph Encoding with CompGCN
在介绍作者的图编码器之前,让作者首先描述从外部知识图构造关系子图的过程。作者采用ConceptNet作为知识图库G. ConceptNet由数百万个关系三元组组成,共包含34个关系。每个三元组都表示为R = (u, r, v),其中u是头部概念,r是关系,v是尾部概念。作者将文档和主题中的短语与来自ConceptNet的提到的概念集(Cd和Ct)进行匹配。为了从G中提取关系子图G = (V, E),作者找到Cd中的概念到Ct中的概念的两跳有向路径。路径上的所有概念构成概念集合V和E,由V内概念之间的所有边组成。此外,作者在任意概念对之间添加反向关系边,以改善信息流。
现有的关于GCNs的研究主要集中在非关系图上。因此,为了整合常识关系知识,作者利用了CompGCN ,这是图卷积网络(GCNs)的一种变体,它联合嵌入了子图G的节点和关系。图编码器由L层叠加的CompGCN层组成。节点和关系的特征均通过TransE嵌入进行初始化。作者通过聚合节点的邻居及其关系边的信息来更新节点表示。形式上,节点的更新方程定义为:
这里φ是一个基于平移理论(Bordes et al., 2013)的实体-关系复合运算,其形式为减法:
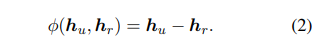
将关系嵌入变换如下:
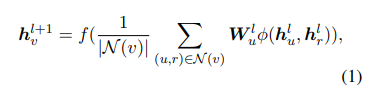
然后,作者得到Cd和Ct的节点表示Hd和Ht。为了聚合合理的关系信息,作者通过执行缩放的dot - product attention计算Cd的平均关系表示 ,以 为键,Hd为查询和值。同样,作者得到Ct的平均关系表示 。
3.立场分类
将纯文本的表示(即 和 )与关系表示(即 和 )连接起来,以充分利用文本信息和图结构信息。然后,通过softmax函数将连接的表征输入到双层多层感知(MLP)中,以预测立场标签:

最后,利用多类交叉熵损失对网络参数进行训练。
实验
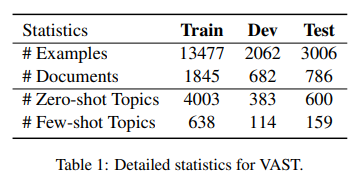
1.数据集:VAST
2.总体结果
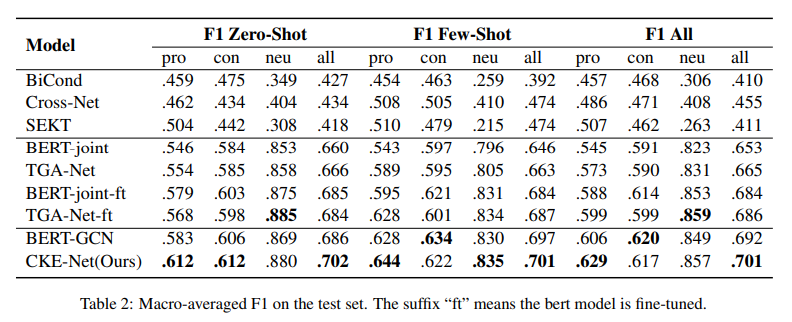
我们的模型和基线的总体结果如表2所示。我们的模型在很大程度上优于所有基线,这可以说明结合丰富的常识知识以关系图的形式是有效的。此外,我们观察到所有基于bert的基线的性能都更差。对于零样本的主题,赞成的例子多于反对的例子。一种可能的解释是反面例子中有更多的否定词,这在语义上更容易识别。我们的模型在零样本和少样本的情况下都带来了显著的平均改善,这表明来自外部知识库的关系信息可以增强归纳推理能力。相对于BERT-GCN只对节点聚合建模,我们的模型充分利用了关系信息,对整体模型做出了很大贡献。
总结
本文阐述了在零样本和少样本立场检测中引入常识知识的必要性,我们提出了一种常识知识增强的方法,它促进了关系知识的集成,进一步加强了模型的归纳推理能力。大量的实验表明,我们提出的模型取得了最先进的成果。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。