作者:@小萌新
专栏:@数据结构进阶
作者简介:大二学生 希望能和大家一起进步!
本篇博客简介:介绍高阶数据结构 unorder_set unorder_map的使用
unorder_set unorder_map
- unordered系列关联式容器
- unordered_set介绍
- unordered_set的使用
- unordered_set的定义方式
- 方式一 构造一个某类型空容器
- 方式二 拷贝构造某同类型容器的复制品
- 方式三 使用迭代器拷贝构造一段内容
- unordered_set的接口函数
- 展示去重和范围for遍历
- 展示直接去重
- 展示迭代器遍历
- 展示查找计数交换等
- 展示交换容器
- unordered_multiset
- unordered_map的介绍
- unordered_map的使用
- unordered_map的定义方式
- 方式一 构造一个某类型的空容器
- 方式二 拷贝构造某类型容器的复制品
- 方式三 使用迭代器拷贝构造某一段内容
- unordered的接口函数
- 展示去重和范围for遍历
- 展示直接去重
- 展示迭代器遍历
- 展示查找
- 展示【】运算符
- 展示计数清除等
- unordered_multimap
unordered系列关联式容器
在C++98中 STL提供了底层为红黑树的一系列关联式容器 在查询时效率可以达到Log(N)
即在最差的情况下 查询红黑树的高度次 这个时候的效率也不太理想
最好的查询是 通过很少的比较次数就能够将被查询元素找到
因此 在C++11中 STL又提供了四个unordered系列的关联式容器
这四个容器与map和set的用法相似 但底层结构不同
unordered_set介绍
- unordered_set是不按照特定顺序存储键值的关联式容器 其允许通过键值快速索引到对应元素
- 在unordered_set中 元素的值也是唯一标识它的key
- 在内部 unordered_set中的元素没有按照任何特定顺序排列 为了能在常数时间内找到key unordered_set将相同哈希值的键值放在桶中
- unordered_set查找单个元素的效率比set快 但是它遍历元素子集的范围迭代效率差
- 它的迭代器至少是前向迭代器
unordered_set的使用
unordered_set的定义方式
方式一 构造一个某类型空容器
unordered_set<int> us1; // 构造一个int类型的空容器
方式二 拷贝构造某同类型容器的复制品
unordered_set<int> us2(us1); // 构造某类型容器的复制品
方式三 使用迭代器拷贝构造一段内容
string s1("hello world");
unordered_set<char> us3(s1.begin(), s1.end()); // 使用string的迭代器拷贝构造
unordered_set的接口函数
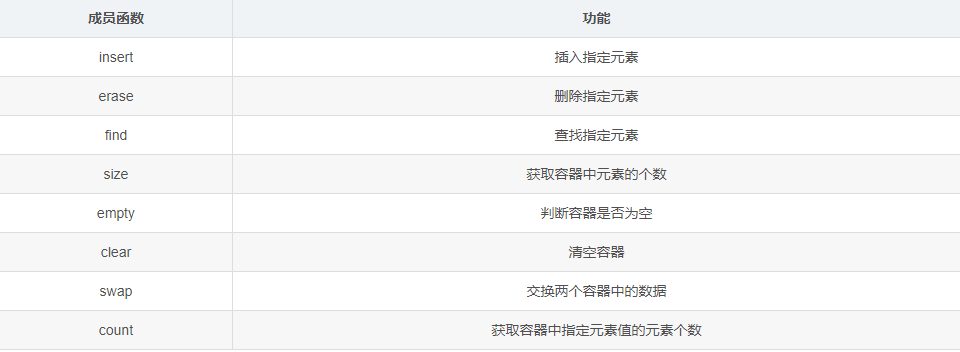
迭代器相关函数如下

使用示例如下
展示去重和范围for遍历
unordered_set<int> us1; // 构造一个int类型的空容器
us1.insert(3);
us1.insert(3);
us1.insert(5);
us1.insert(1);
us1.insert(7);
us1.insert(8);
for (auto x: us1)
{
cout << x << endl;
}
我们使用unordered_set容器 并且插入多组重复数据 之后使用范围for遍历 达到一个去重的效果
注意 这里和set的区别是不会排序
展示直接去重
unordered_set<int> us1; // 构造一个int类型的空容器
us1.insert(3);
us1.insert(3);
us1.insert(5);
us1.insert(1);
us1.insert(7);
us1.insert(8);
for (auto x : us1)
{
cout << x << " ";
}
cout << endl;
us1.erase(3);
for (auto x : us1)
{
cout << x << " ";
}
cout << endl;
我们调用erase删除我们想要删除的值 并且再遍历一遍容器
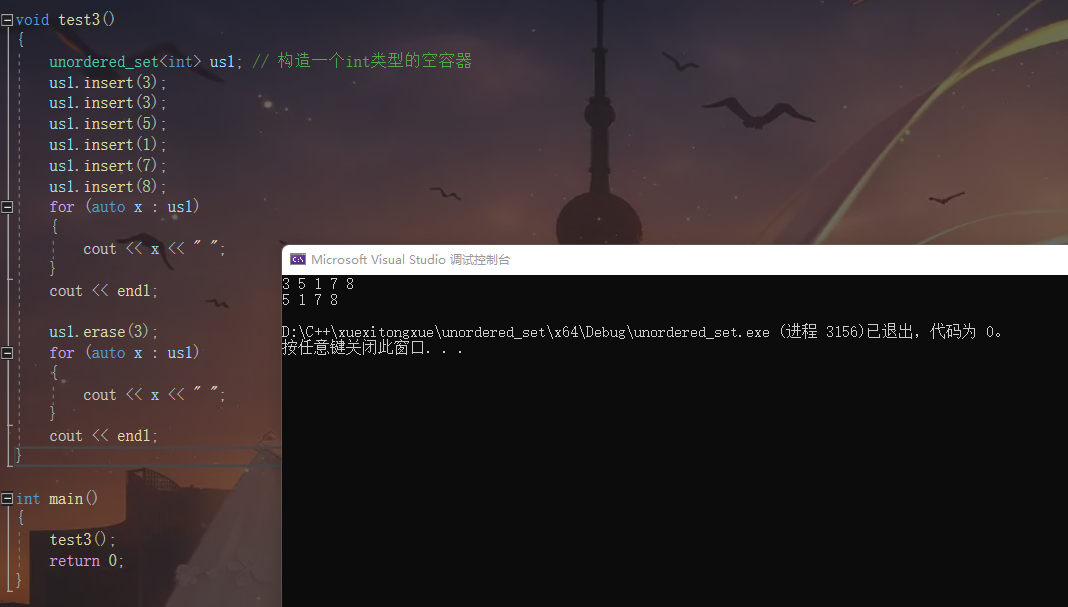
我们可以发现 3被删除了
那么假如我们连续两次删除3会发生什么呢?
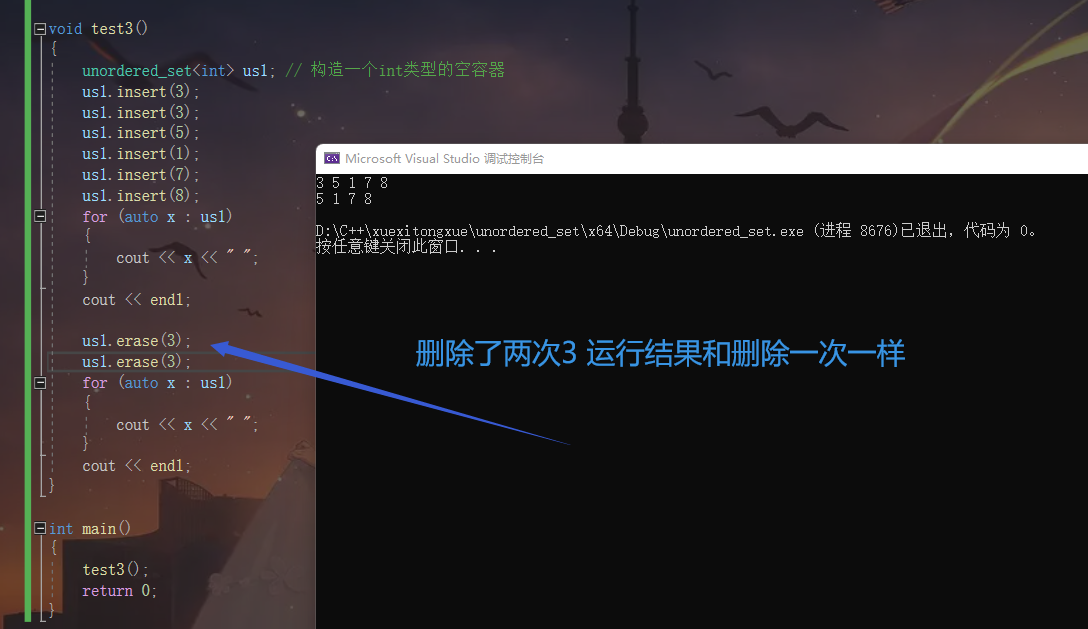
展示迭代器遍历
代码如下
unordered_set<int> us1; // 构造一个int类型的空容器
us1.insert(3);
us1.insert(3);
us1.insert(5);
us1.insert(1);
us1.insert(7);
us1.insert(8);
unordered_set<int>::iterator it = us1.begin();
while (it != us1.end())
{
cout << *it << " ";
it++;
}
cout << endl;
展示效果如下
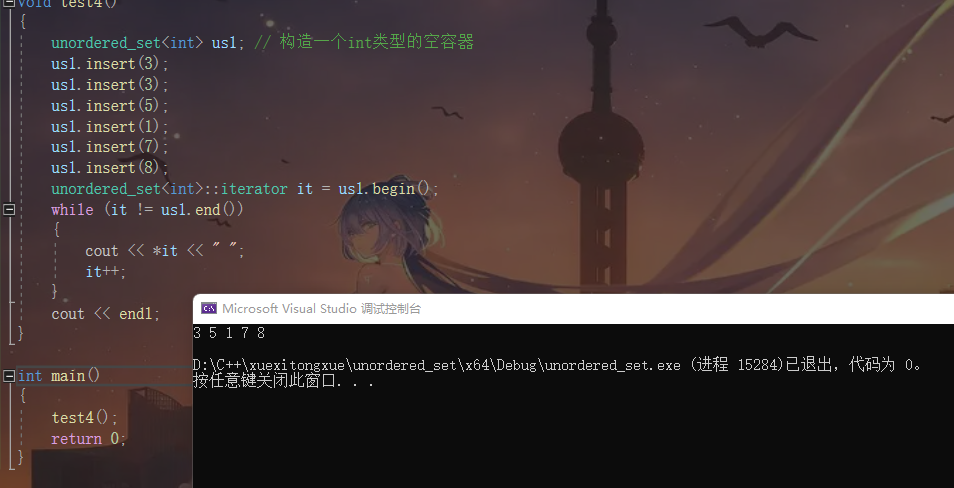
展示查找计数交换等
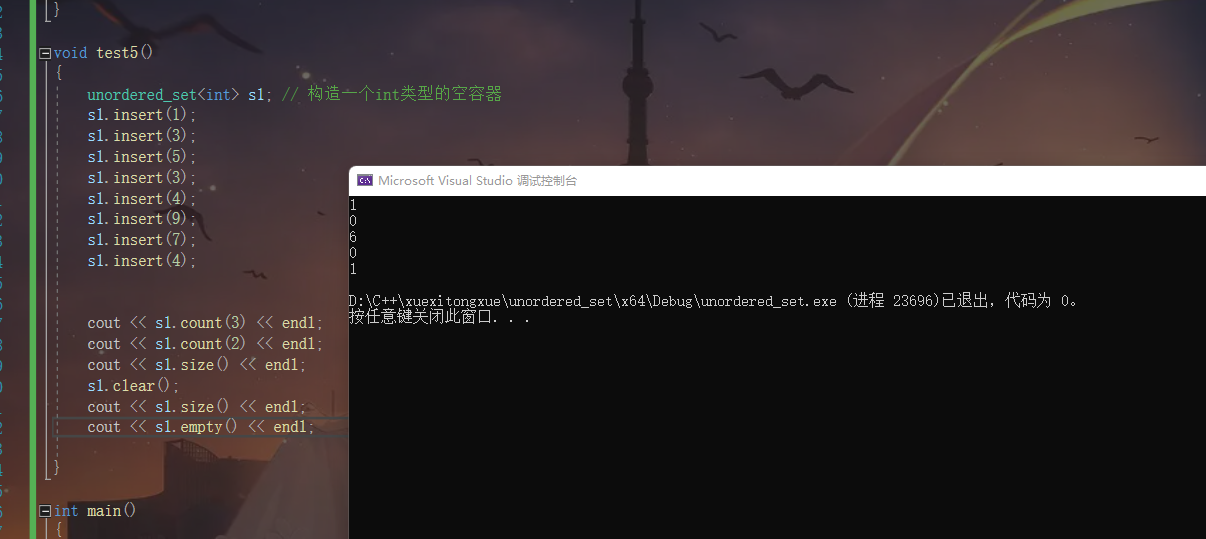
unordered_set<int> s1; // 构造一个int类型的空容器
s1.insert(1);
s1.insert(3);
s1.insert(5);
s1.insert(3);
s1.insert(4);
s1.insert(9);
s1.insert(7);
s1.insert(4);
cout << s1.count(3) << endl;
cout << s1.count(2) << endl;
cout << s1.size() << endl;
s1.clear();
cout << s1.size() << endl;
cout << s1.empty() << endl;
我们可以发现查找 3 2 出现的次数
s1的大小 清空后的大小 以及s1是否为空
展示交换容器
unordered_set<int> s1; // 构造一个int类型的空容器
s1.insert(1);
s1.insert(3);
s1.insert(5);
s1.insert(3);
s1.insert(4);
s1.insert(9);
s1.insert(7);
s1.insert(4);
unordered_set<int> s2;
cout << s2.size() << endl;
cout << s1.size() << endl;
s2.swap(s1);
cout << s2.size() << endl;
cout << s1.size() << endl;
我们可以发现 交换后两个容器的大小发生了变化
unordered_multiset
unordered_multiset和unordered_set的底层实现都是相同的 接口函数也十分类似
它们之间最大的区别就是 unordered_multiset中允许键值对冗余
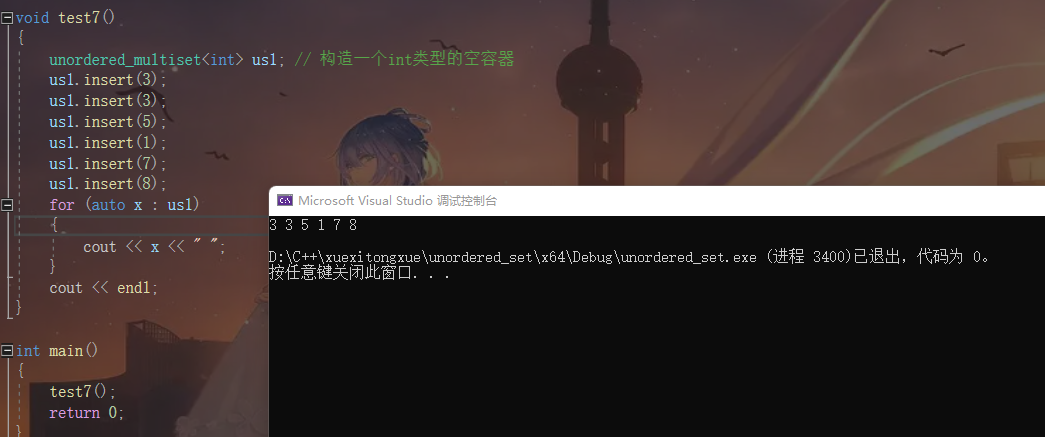
unordered_multiset<int> us1; // 构造一个int类型的空容器
us1.insert(3);
us1.insert(3);
us1.insert(5);
us1.insert(1);
us1.insert(7);
us1.insert(8);
for (auto x : us1)
{
cout << x << " ";
}
cout << endl;
我们可以看到运行结果有冗余的键值
由于multiset容器允许键值冗余,因此两个容器中成员函数find和count的意义也有所不同
| 成员函数find | 功能 |
|---|---|
| unordered_set容器 | 返回键值为val的元素的迭代器 |
| unordered_multiset容器 | 返回底层哈希表中第一个找到的键值为val的元素的迭代器 |
| 成员函数count | 功能 |
|---|---|
| unordered_set容器 | 键值为val的元素存在则返回1,不存在则返回0(find成员函数可替代) |
| unordered_multiset容器 | 返回键值为val的元素个数(find成员函数不可替代) |
unordered_map的介绍
- unordered_map是储存<key,vlaue>键值对的关联式容器 其允许通过key值快速的索引到对应value值
- 在unordered_map中 键值通常用于唯一的标识元素 而映射值是一个对象 映射内容与此键关联 它们的类型可能不同
- 在内部 unordered_map没有对<key , value>按照任何顺序排序 为了能在常数范围内找到key值对应的value unordered_map将相同的哈希值的键值放在相同的桶中
- unordered_map通过key值访问单个元素比map快 但是在遍历元素子集的迭代方面效率差
- unordered_map实现了直接访问操作符【】 它允许使用key作为参数直接访问value
- 它的迭代器至少是前向迭代器
unordered_map的使用
unordered_map的定义方式
方式一 构造一个某类型的空容器
unordered_map<int, int> um1; // 构造一个某类型的空容器
方式二 拷贝构造某类型容器的复制品
unordered_map<int, int> um2(um1); // 拷贝构造某类型容器的复制品
方式三 使用迭代器拷贝构造某一段内容
unordered_map<int, int> um3(um1.begin(), um1.end());// 使用迭代器拷贝构造某一段内容
unordered的接口函数

除了上述接口函数外 unordered_map还提供了一个功能十分强大的接口函数【】
- 若当前容器中已有键值为key的键值对 则返回该键值对于value的引用
- 若当前容器中无键值为key的键值对 则先插入键值对<key,value()> 之后返回该键值对于value的引用
迭代器相关函数如下

使用示例如下
展示去重和范围for遍历
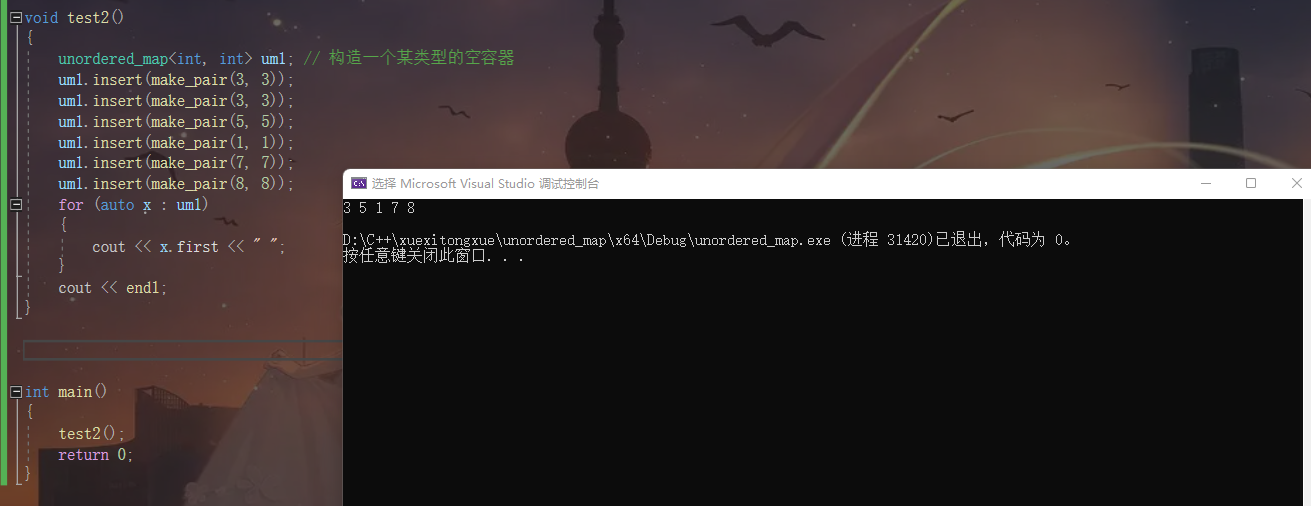
unordered_map<int, int> um1; // 构造一个某类型的空容器
um1.insert(make_pair(3, 3));
um1.insert(make_pair(3, 3));
um1.insert(make_pair(5, 5));
um1.insert(make_pair(1, 1));
um1.insert(make_pair(7, 7));
um1.insert(make_pair(8, 8));
for (auto x : um1)
{
cout << x.first << " ";
}
cout << endl;
我们使用unordered_map容器 并且插入多组重复数据之后使用范围for遍历 达到一个去重的效果
注意 这里和map的区别是不会排序
展示直接去重
unordered_map<int, int> um1; // 构造一个某类型的空容器
um1.insert(make_pair(3, 3));
um1.insert(make_pair(3, 3));
um1.insert(make_pair(5, 5));
um1.insert(make_pair(1, 1));
um1.insert(make_pair(7, 7));
um1.insert(make_pair(8, 8));
for (auto x : um1)
{
cout << x.first << " ";
}
cout << endl;
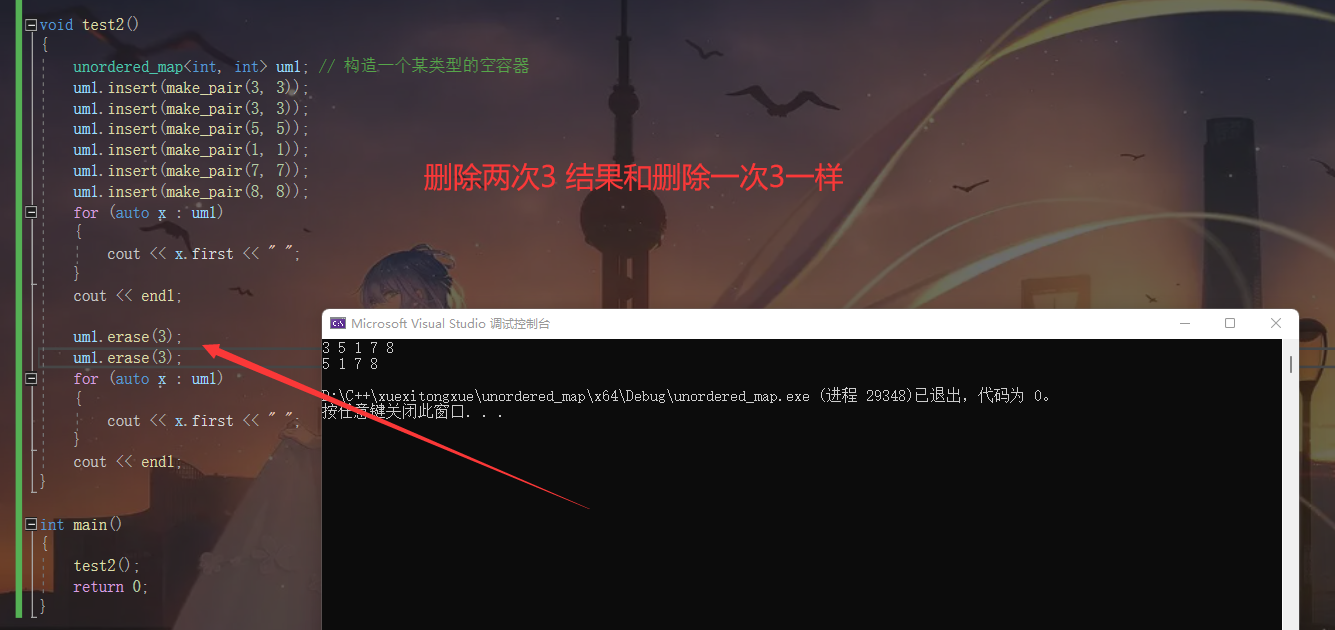
um1.erase(3);
for (auto x : um1)
{
cout << x.first << " ";
}
cout << endl;
我们调用erase删除我们想要删除的key值 并且再遍历一遍容器
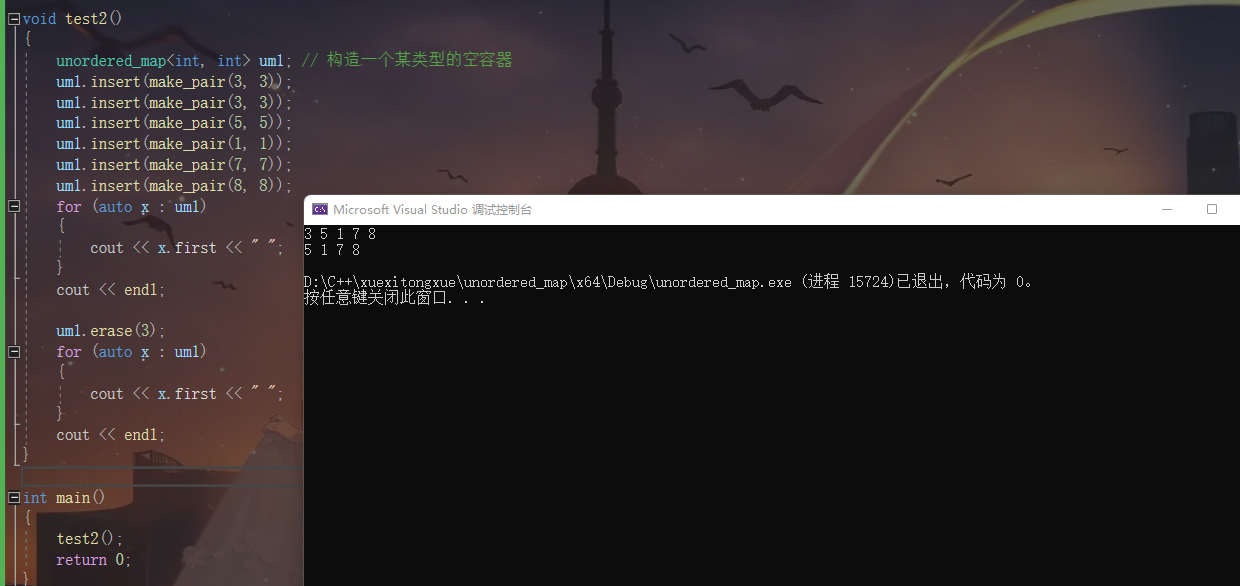
我们可以发现3被删除了
那么假如我们连续两次删除3会发生什么呢?
展示迭代器遍历
代码如下
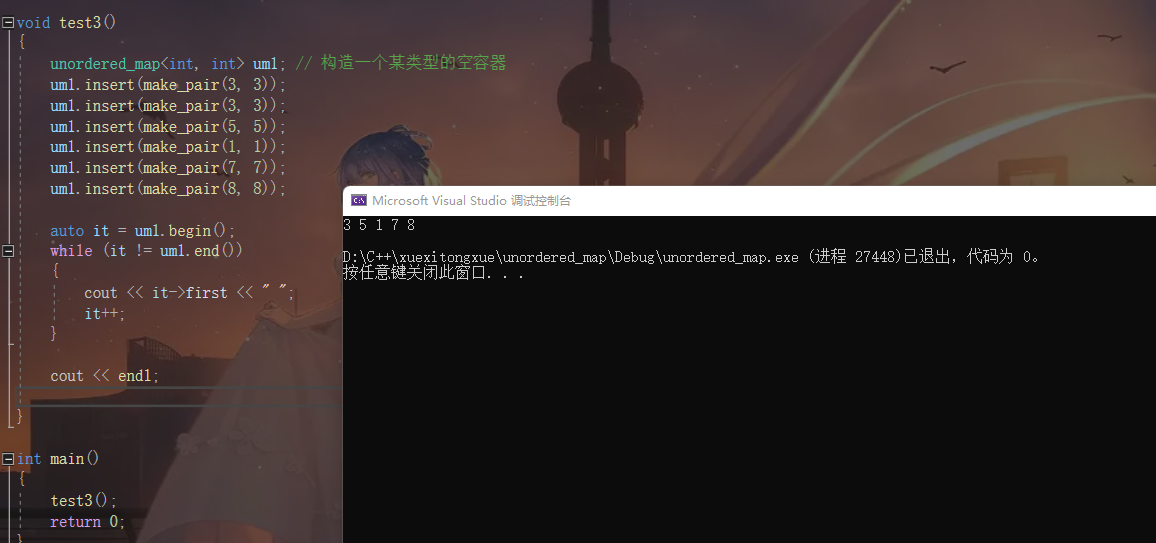
unordered_map<int, int> um1; // 构造一个某类型的空容器
um1.insert(make_pair(3, 3));
um1.insert(make_pair(3, 3));
um1.insert(make_pair(5, 5));
um1.insert(make_pair(1, 1));
um1.insert(make_pair(7, 7));
um1.insert(make_pair(8, 8));
auto it = um1.begin();
while (it != um1.end())
{
cout << it->first << " ";
it++;
}
cout << endl;
展示效果如下
展示查找
unordered_map的查找是根据key值在unordered_map中查找 有两种结果
- 如果找到了则返回对应的迭代器
- 如果找不到则返回end迭代器
代码和演示效果如下
unordered_map<int, int> um1; // 构造一个某类型的空容器
um1.insert(make_pair(3, 3));
um1.insert(make_pair(3, 3));
um1.insert(make_pair(5, 5));
um1.insert(make_pair(1, 1));
um1.insert(make_pair(7, 7));
um1.insert(make_pair(8, 8));
auto it = um1.find(3);
auto it2 = um1.find(4);
if (it != um1.end())
{
cout << it->first << endl;
}
if (it2 != um1.end())
{
cout << it2->first << endl;
}

我们可以发现 确实符合上面的规则
展示【】运算符
首先我们明确下它的规则
- 如果key不在unordered_map中 则使用【】会插入键值对 然后返回该键值对中value的引用
- 如果key在unordered_map中则会返回键值为K的元素的value的引用
测试代码和结果如下
unordered_map<int, int> um1; // 构造一个某类型的空容器
um1.insert(make_pair(3, 3));
um1.insert(make_pair(3, 3));
um1.insert(make_pair(5, 5));
um1.insert(make_pair(1, 1));
um1.insert(make_pair(7, 7));
um1.insert(make_pair(8, 8));
um1[3] = 20;
um1[9] = 9;
auto it = um1.find(3);
cout << it->second << endl;
for (auto x : um1)
{
cout << x.first << " ";
}
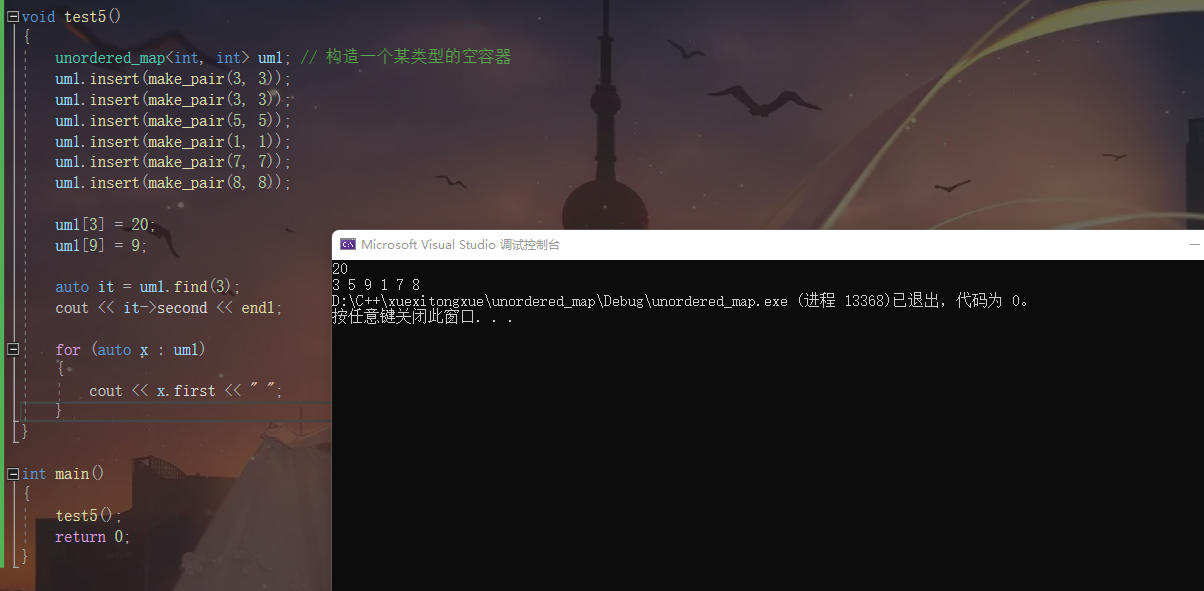
我们可以看到 进行了
um1[3] = 20;
um1[9] = 9;
这两步操作之后
key值为3的value变成了20
多了一个key值为9的元素
展示计数清除等
这里很简单 直接看代码和演示结果就可以
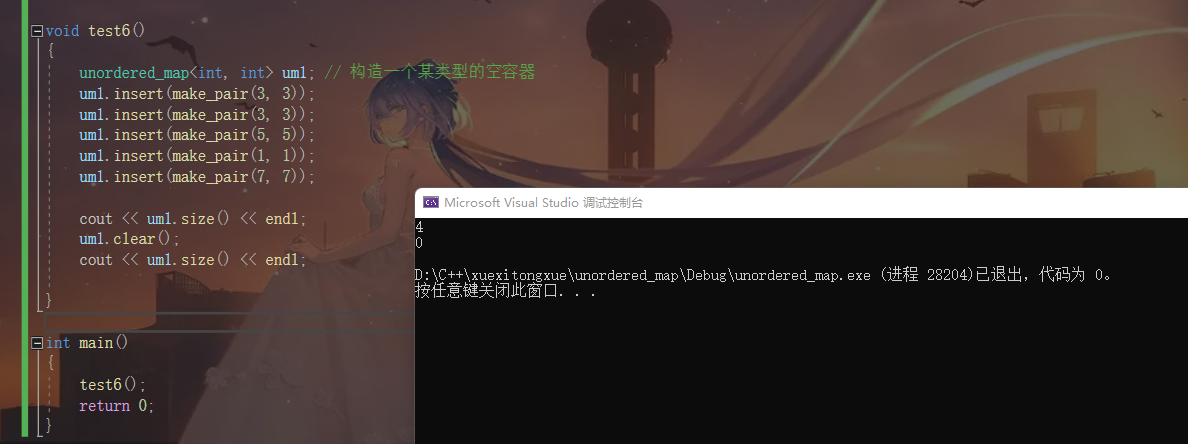
unordered_map<int, int> um1; // 构造一个某类型的空容器
um1.insert(make_pair(3, 3));
um1.insert(make_pair(3, 3));
um1.insert(make_pair(5, 5));
um1.insert(make_pair(1, 1));
um1.insert(make_pair(7, 7));
cout << um1.size() << endl;
um1.clear();
cout << um1.size() << endl;
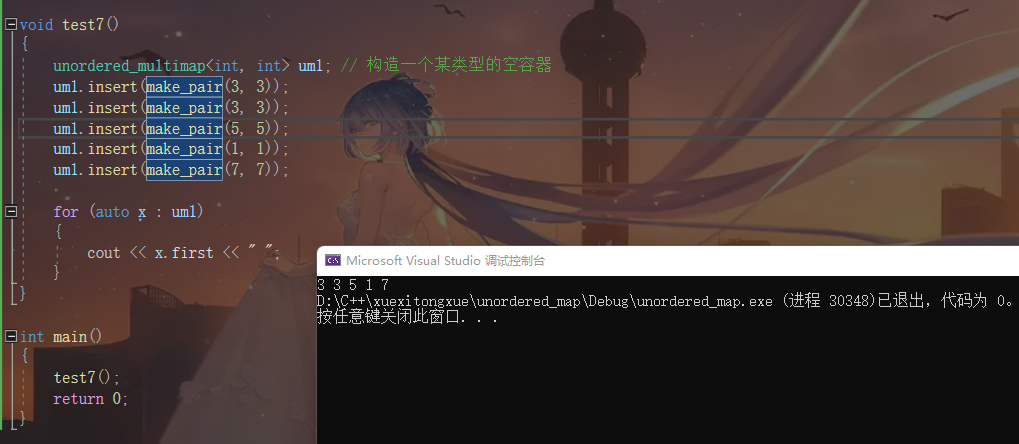
unordered_multimap
unordered_multimap和unordered_map的底层实现都是相同的 接口函数也十分类似
它们之间最大的区别就是 unordered_multimap中允许键值对冗余
代码和演示结果如下
unordered_multimap<int, int> um1; // 构造一个某类型的空容器
um1.insert(make_pair(3, 3));
um1.insert(make_pair(3, 3));
um1.insert(make_pair(5, 5));
um1.insert(make_pair(1, 1));
um1.insert(make_pair(7, 7));
for (auto x : um1)
{
cout << x.first << " ";
}
由于unordered_multimap容器允许键值对的键值冗余 因此该容器中成员函数find和count的意义与unordered_map容器中的也有所不同
| 成员函数find | 功能 |
|---|---|
| unordered_map容器 | 返回键值为key的键值对的迭代器 |
| unordered_multimap容器 | 返回底层哈希表中第一个找到的键值为key的键值对的迭代器 |
| 成员函数count | 功能 |
|---|---|
| unordered_map容器 | 键值为key的键值对存在则返回1,不存在则返回0(find成员函数可替代) |
| unordered_multimap容器 | 返回键值为key的键值对的个数(find成员函数不可替代) |
此外由于unordered_multimap容器允许键值对冗余 因此【】操作符可能会产生歧义 因此在unordered_multimap容器中并未实现之