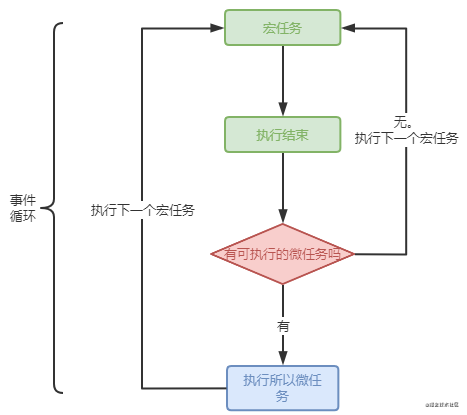
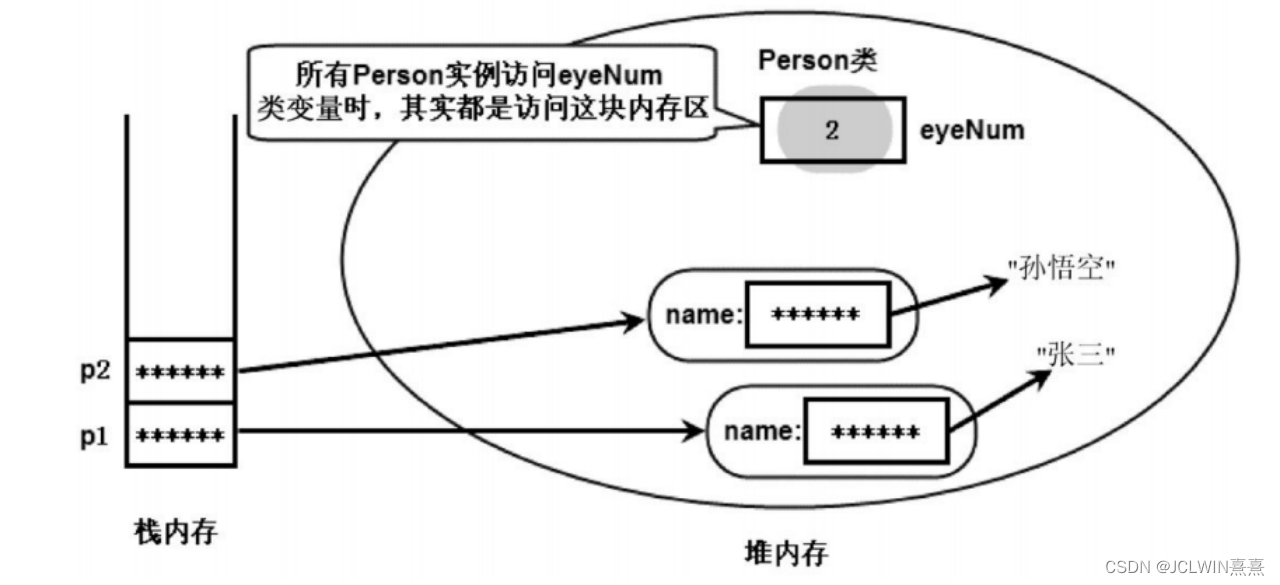
传统计数
模糊计数
Cache + DB。写Cache,批量刷新DB。
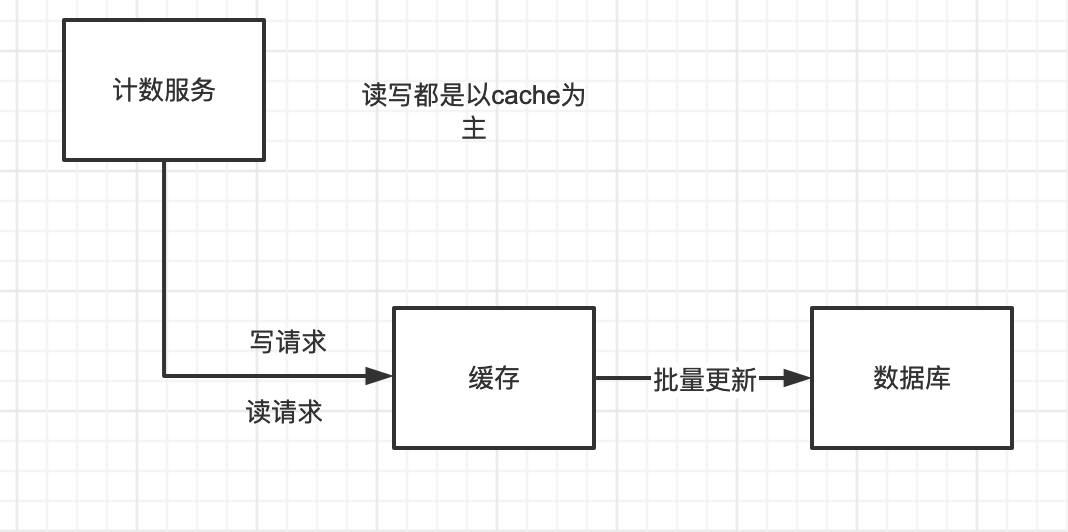
有一个写请求,我们就写cache,写一个在cache中+1,buffer记一个,差不多(buffer满了,时间到了)写一次DB,丢数据也就丢一个buffer的数据或者一段时间的数据。
精准计数
我收藏,我发布,我买到的,这些都是精准计数。
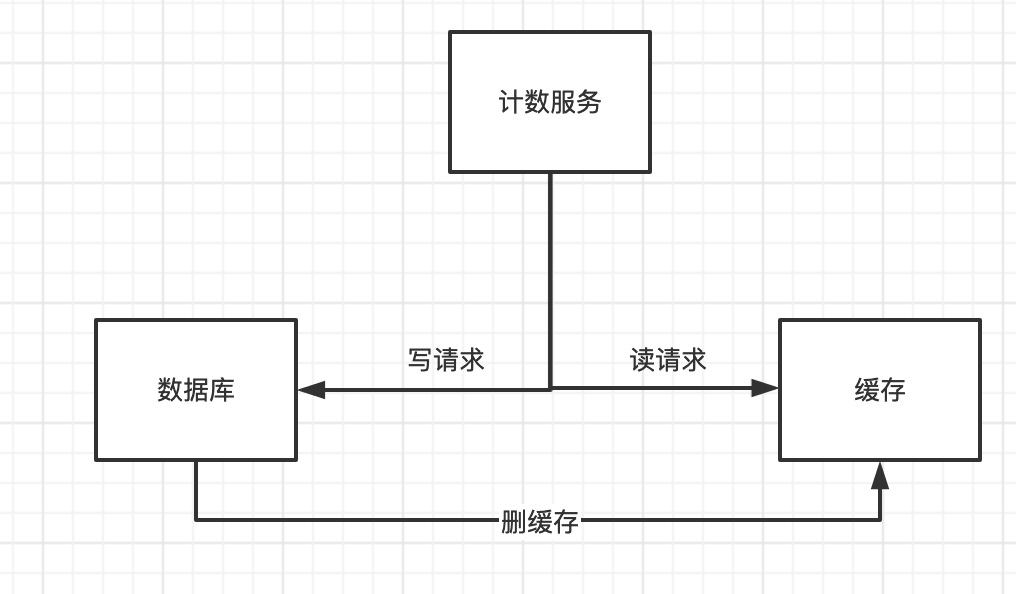
DB+cache
写DB同时调用count。
高可用设计
模糊查询:一般读写请求都高并发
精准查询:一般读多写少
DB层:防止流量暴增,读写分离
Cache层:搭建集群,高可用设计
高性能设计
在计数服务中,其实我们的数据都是KV存储,不太需要关系型存储。
数据一致性设计思考
模糊查询:
- Redis宕机,数据没同步DB
- Redis写过程异常,掉电,服务异常,主从切换
精准查询:
- 业务系统定期同步校正
- 业务数据和计数逻辑的事务性
精准查询为了保证业务数据和计数逻辑的准确性,我们可以使用分布式事务来去优化。

计数架构设计
我们把计数服务不管是模糊查询还是精准查询都做在一起,放到一个计数服务当中,通过请求来判断是精准计数还是模糊计数。
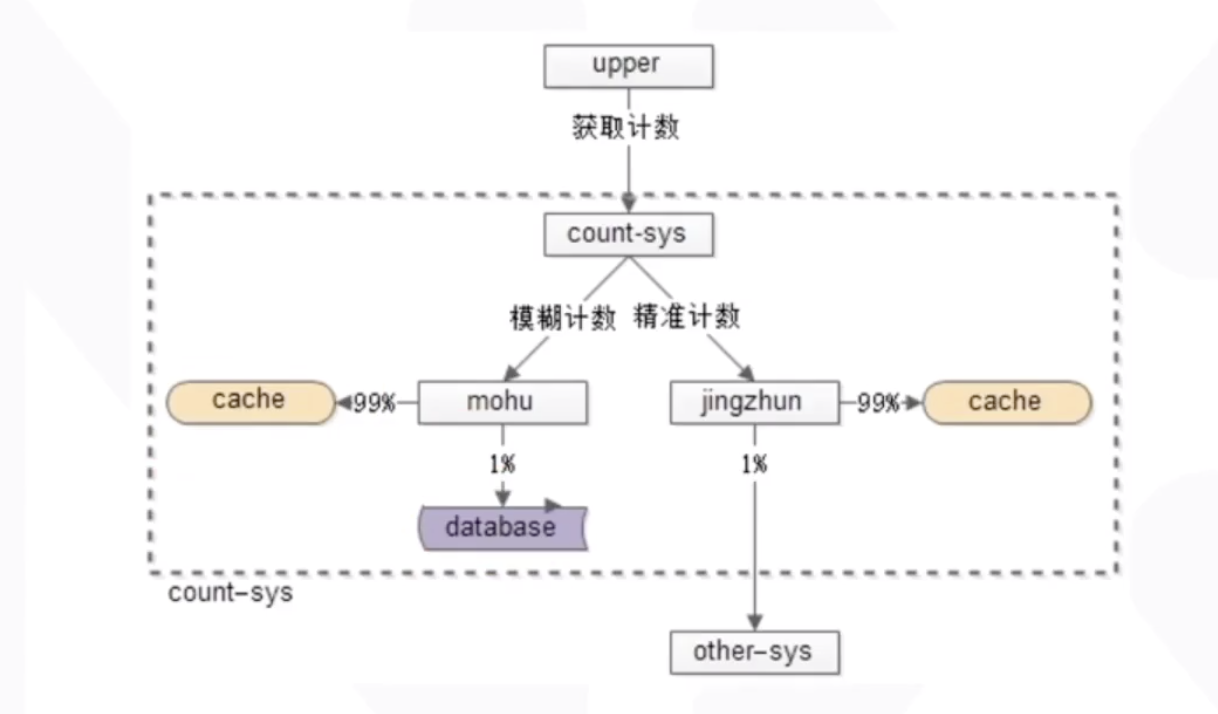
模糊计数写入:
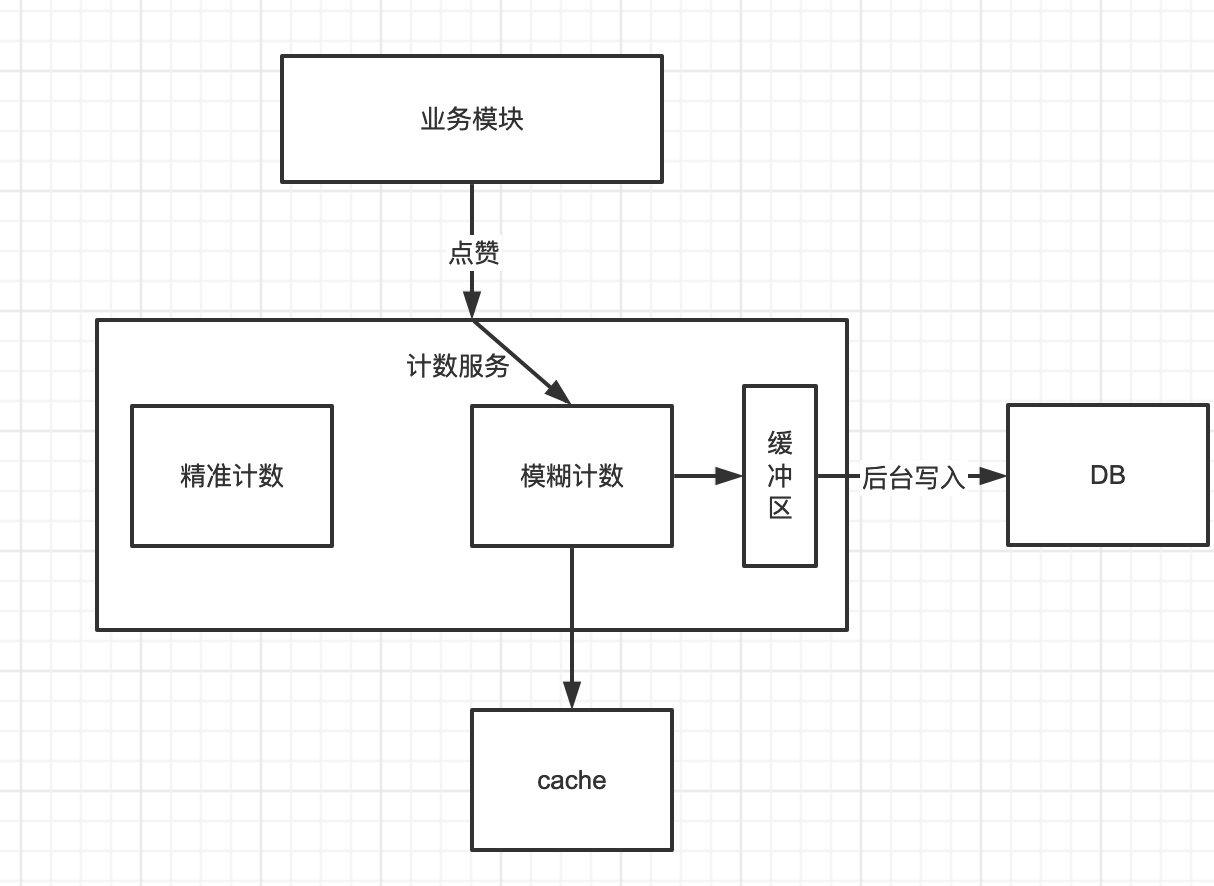
存在问题:未考虑服务重启,kill等数据不一致情况比较严重。所以这里为了保证一致性,我们也可以去定期调用服务进行对齐
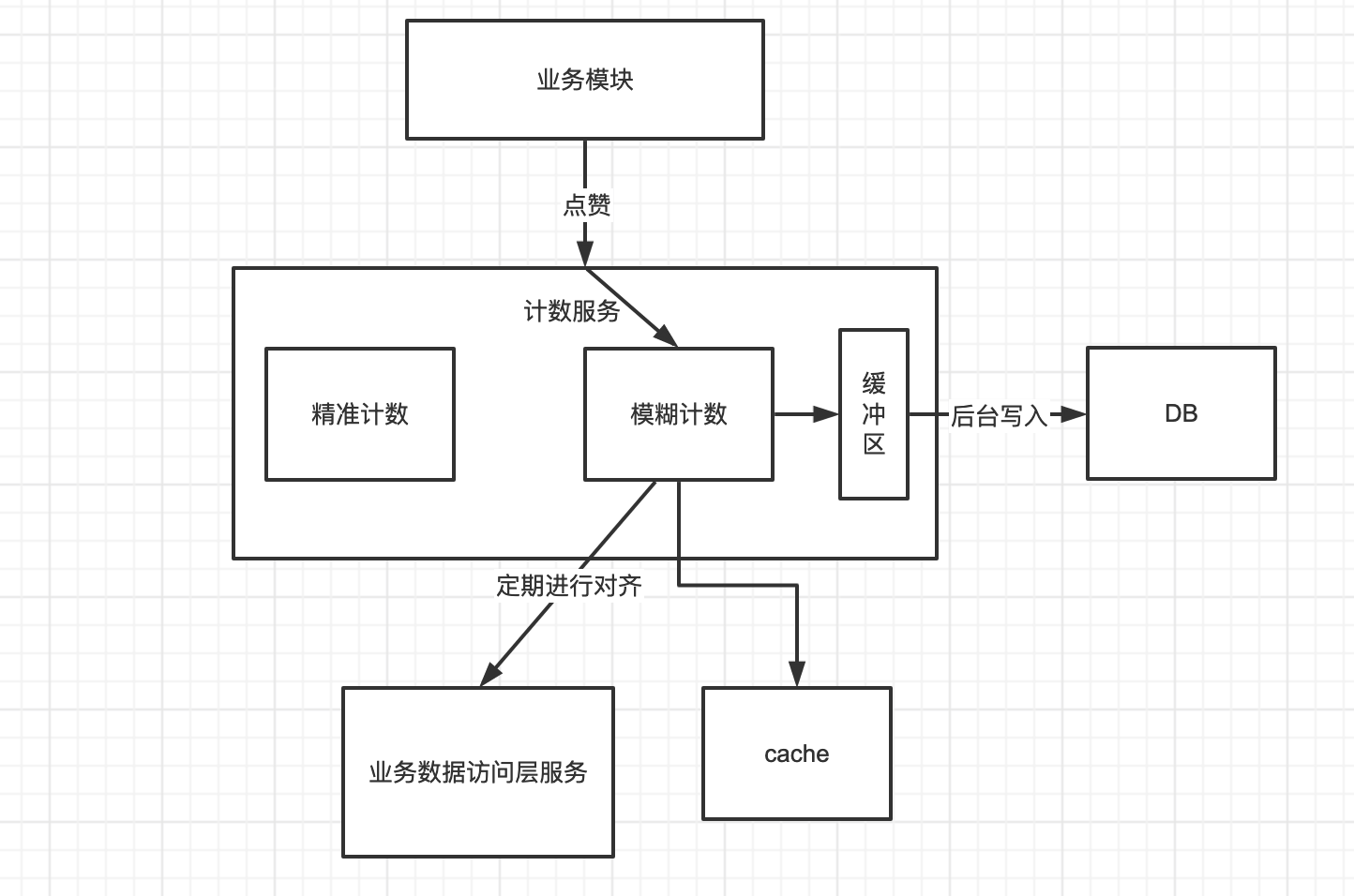
精准计数读取:
读Redis,如果没有调用业务接口获取,对于精准计数为了保证一致性,需要频繁调用业务接口对齐数据,需要业务DB做count计算(成本比较大)
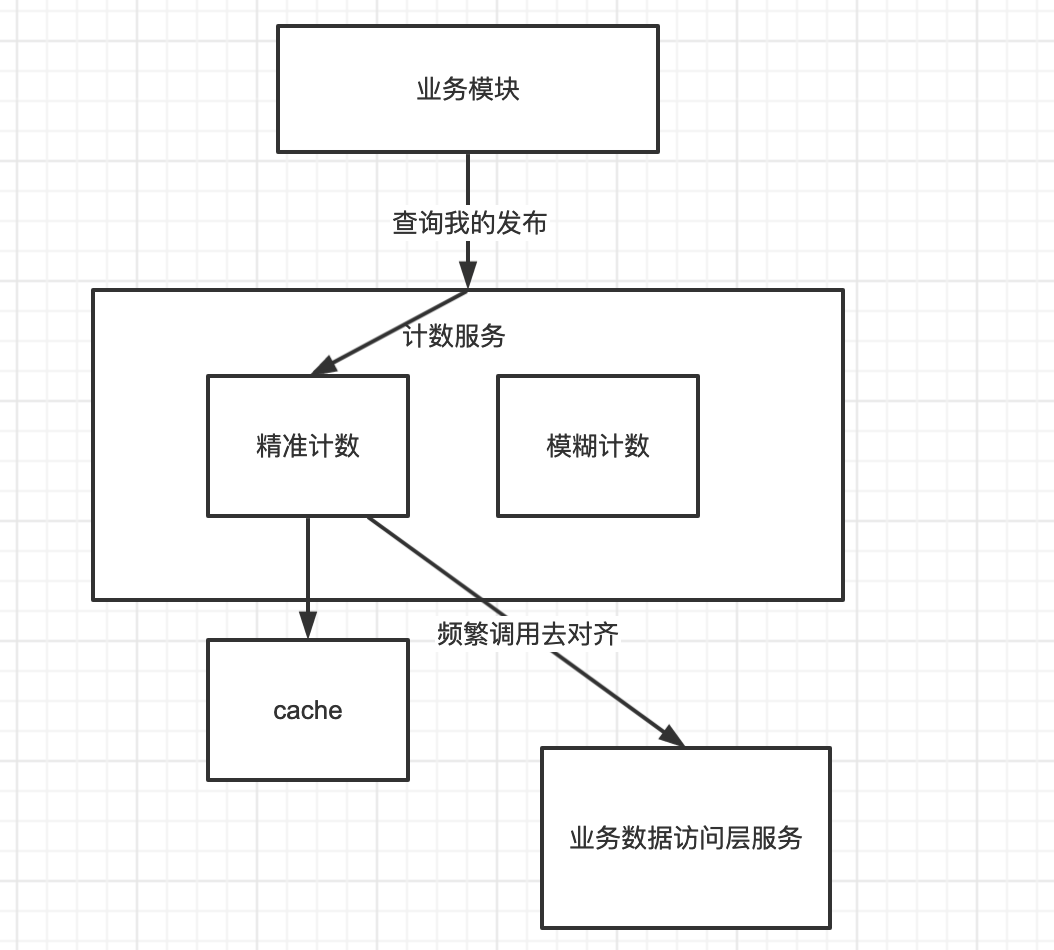
精准计数写入:
按照正常做法,我们写入一个数据就删除Redis,然后查询的时候,调用业务数据访问层服务进行写入Redis,同时我们还需要去调用服务对齐,这样大大的增加了服务的性能压力。所以我们这里可以去更新Redis,而不是写入Redis。但是更新Redis就会有数据一致性问题。这时候怎么解决?并且MySQL存在主从同步延迟问题,这怎么解决?
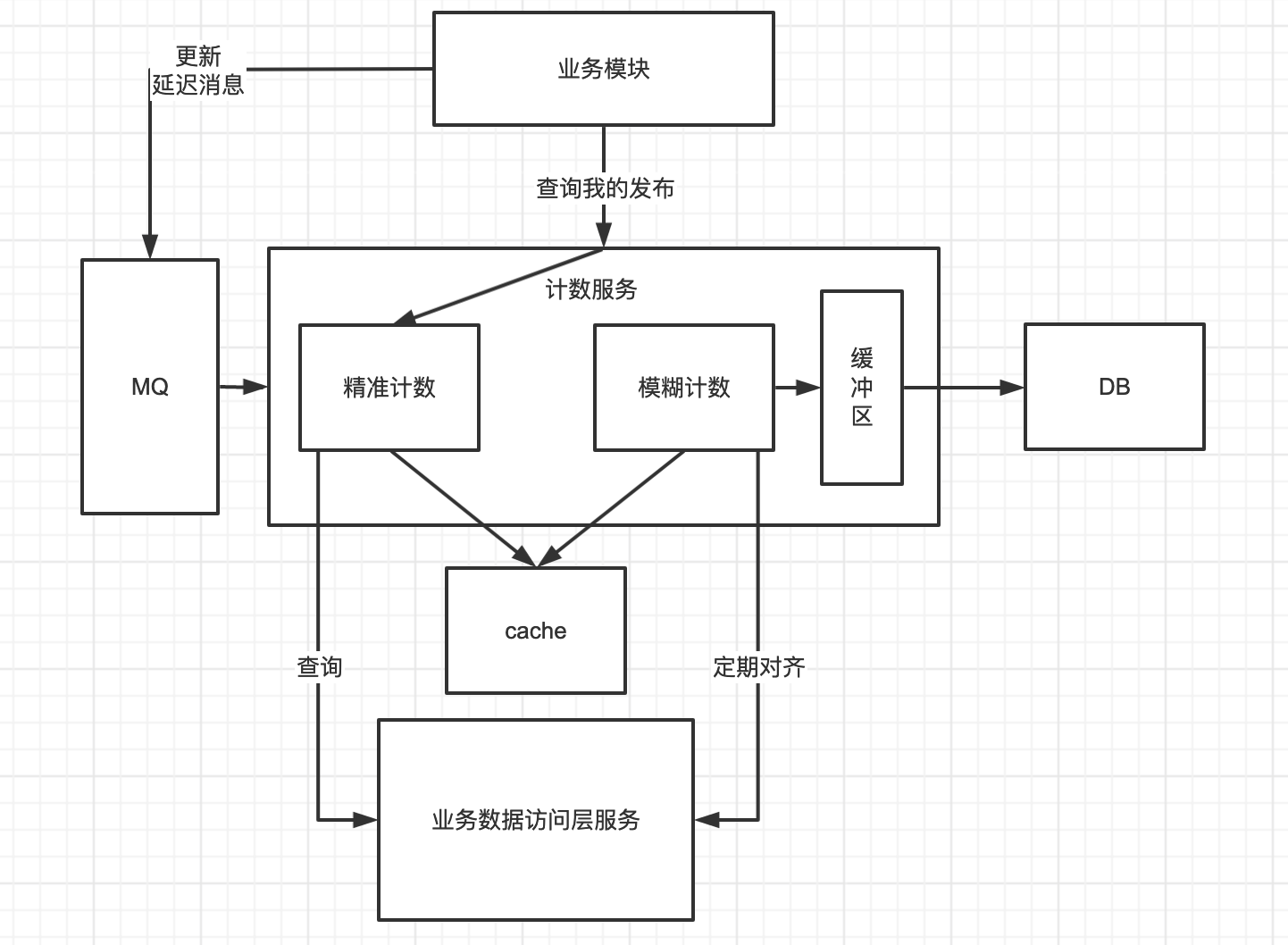
消息队列需要考入顺序问题,但是在计数服务中不需要考虑顺序问题。因为计数服务只有加减操作,先加还是先减都是ok的。
事务计数设计
我们精准计数需要保证数据一致性问题,那这里呢,我们可以用事务消息来保证
这里详细可以看一下我写的rabbitmq的那一篇文章。
那么接下来来看一些具体的东西:
点赞业务如何实现
根据点赞业务特点可以发现:
- 吞吐量高
- 能够接受数据不一致
如果只考虑点赞可以怎么做?
如果只考虑点赞的话可以怎么做?
可以用MySQL来固化存储,Redis做缓存,读写操作都落缓存,异步线程定期(定时器)刷新DB。架一层技数服务,将计数业务逻辑解耦。
则会时候MySQL的字段包括:
- tmsg_id
- praise_count
所以Redis的kv设计就是:
- key: msg_id
- value: praise_count
但是以微博为例,不仅有点赞,还有转发数,评论数,阅读量等。所以,微博的难点在于业务的拓展性问题,以及效率问题。如果需要查询这些的话,我们就需要多次查询Redis,多次查询DB。这是不合理的,效率太低了。
所以我们应该这么去设计:
MySQL字段:贴子的id,点赞的count,转发数,评论数,阅读数。。。。
Redis:
- key:贴子的id:点赞
- value:点赞数量
。。。。
加入微博首页,有10条贴子,因此我们需要得到10条转发数等等的相关信息。
select * from limit 10;
然后Redis也查10条。
这效果太差了!!!
因此我们应该去设计一个业务中台:
MySQL:
- id
- 类型名称
- 数量count
这样我们只需要:
select * from xxx where 贴子id = 1;
Redis:
- key: 贴子的id
- value:10 : 100 : 1000放在一起
Redis来获取业务的话,可以存储为hash用来计数。
这种模糊查询会出现很多问题,因为所有都需要依赖Redis再去刷新DB。这时候会出现以下情况:
- Redis宕机,数据没有同步DB
- Redis写过程异常,掉电,服务异常,主从切换
同时精准查询也会出现一些问题比如:
- 业务系统定期同步纠正
- 业务数据和计数逻辑的事务性
在Feed系统中还有一些业务数据,无法直接当做简单数据类型或集合数据类型。比如判断性业务,判断一个用户是否赞了某条feed,是否阅读了某条feed等。如果直接缓存,会需要消耗大量的内存。还有计数类业务,存储一个key为8字节,value为4字节的计数。如果用Redis来存储,每日新增n条记录,每日的成本可能会高达数百G,这成本是很高的。所以微博的话,在Redis上进行了扩展,新增了ConunterService和Phantom两个组件。
ConunterService组件
CounterService 的主要应用场景就是计数器,比如微博的转发、评论、赞的计数。采用Redis进行KV存储的话,大概一条KV需要至少65个字节,上面说了,存储一条计数服务,KV加起来是12个字节,其余四十多个字节都被浪费掉了。一条微博,通常有好几个计数:比如转发数,评论数,点赞数。而一天微博会新增无数的帖子。
ConunterService存储结构采用上面是内存下面是 SSD,预先把内存分成 N 个 Table,每个 Table 根据微博 ID 的指针序列,划出一定范围。任何一个微博 ID 过来先找到它所在的 Table,如果有的话,直接对它进行增减;如果没有,就新增加一个 Key。有新的微博 ID 过来,发现内存不够的时候,就会把最小的 Table dump 到 SSD 里面去,留着新的位置放在最上面供新的微博 ID 来使用。如果某一条微博特别热,转发、评论或者赞计数超过了 4 个字节,计数变得很大超过限制该怎么处理呢?可以把这些放到Aux Dict 进行存放。对于落在 SSD 里面的 Table,可以有专门的 Index 进行访问,通过 RDB 方式进行复制。根据时间维度,近期的热数据放在内存,之前的冷数据放在磁盘,降低机器成本。如果之前的冷数据被频繁的访问则放到LRU缓存进行加载。加载的时候采用异步IO,不会影响服务的整体性能。
Phantom组件
微博还有一种场景是“存在性判断”,比如某一条微博某个用户是否赞过、某一条微博某个用户是否看过之类的。这种场景有个很大的特点,它检查是否存在,因此每条记录非常小,比如 Value 用 1 个位存储就够了,但总数据量又非常巨大。比如每天新发布的微博数量在 1 亿条左右,是否被用户读过的总数据量可能有上千亿,怎么存储是个非常大的挑战。而且还有一个特点是,大多数微博是否被用户读过的存在性都是 0,如果存储 0 的话,每天就得存上千亿的记录;如果不存的话,就会有大量的请求最终会穿透 Cache 层到 DB 层,任何 DB 都没有办法抗住那么大的流量。
Phantom 跟 CounterService 一样,采取了分 Table 的存储方案,不同的是 CounterService 中每个 Table 存储的是 KV,而 Phantom 的每个 Table 是一个完整的 BloomFilter,每个 BloomFilter 存储的某个 ID 范围段的 Key,所有 Table 形成一个列表并按照 Key 范围有序递增。当所有 Table 都存满的时候,就把最小的 Table 数据清除,存储最新的 Key,这样的话最小的 Table 就滚动成为最大的 Table 了。
当一个 Key 的读写请求过来时,先根据 Key 的范围确定这个 Key 属于哪个 Table,然后再根据 BloomFilter 的算法判断这个 Key 是否存在。
计数服务拓展
上面说了用db+cache的方式来完成计数服务。在一些软件中,也有用cache直接存储计数的。定期清理,只不过是缓存的周期稍微长一些。比如QQ空间的点赞。你会发现过很长的时间再回头一看,以前点赞的数据都没了。剩下只有新帖子还有点赞数据。
对于并发特别高数据量特别大的服务不够友好。所以上面说了可以用ConunterService,当然,这个是微博自己的,还没有开源。这里的话,我们可以简单自己对Redis做以下小小的优化
struct item {
int64_t id;
int star_num; //点赞
int repost_num; //转发
int comment_num; //评论
};
存储数字,而不是字符串,没有多余的指针存储
程序启动时开辟一大片内存。插入时,
h1 = hash1(item.id);
h2 = hash2(item.id);
查询时,比较id和item.id是否一致,一致就表示查到。不一致表示值为0;
删除时,查找到所在位置,设置特殊的标志;下次插入时,可以填充这个标志位,以复用内存。
这里其实一般转发数和评论数都不会很多,几百几千已经是很多了,超过十万,比如鹿晗官宣恋情这种基本上没几个。所以这里还可以做一个优化:
struct item{
int64_t id;
int star_num;
unsigned short repost_num; 转发数
unsigned short comment_num;评论数
};
对于转发数和评论数大于65535的帖子,我们在这里记录一个特殊的标志位,然后去另外的dict中去查找。
这样就大大的节省了内存的占用。
查看点赞详情如何设计
一般微博这种是不能查看点赞详细人数的,但是如果想像微博,QQ这种,需要查看点赞的详细人数,这种架构我们如何设计呢?
实现方案
将该动态下所有的点赞用户查询出来放入到集合中,然后列化为Json字符串以Key/Value的方式存储到Redis中,当用户浏览内容时,取出缓存数据,反序列化Json,然后通过in_array和count方法判断是否已点赞及内容点赞数。在缓存的维护上,则是每一次有新用户点赞或取消赞则直接清除Redis。
缓存结构如下: cId => ‘[uid1,uid2,uid3…]’
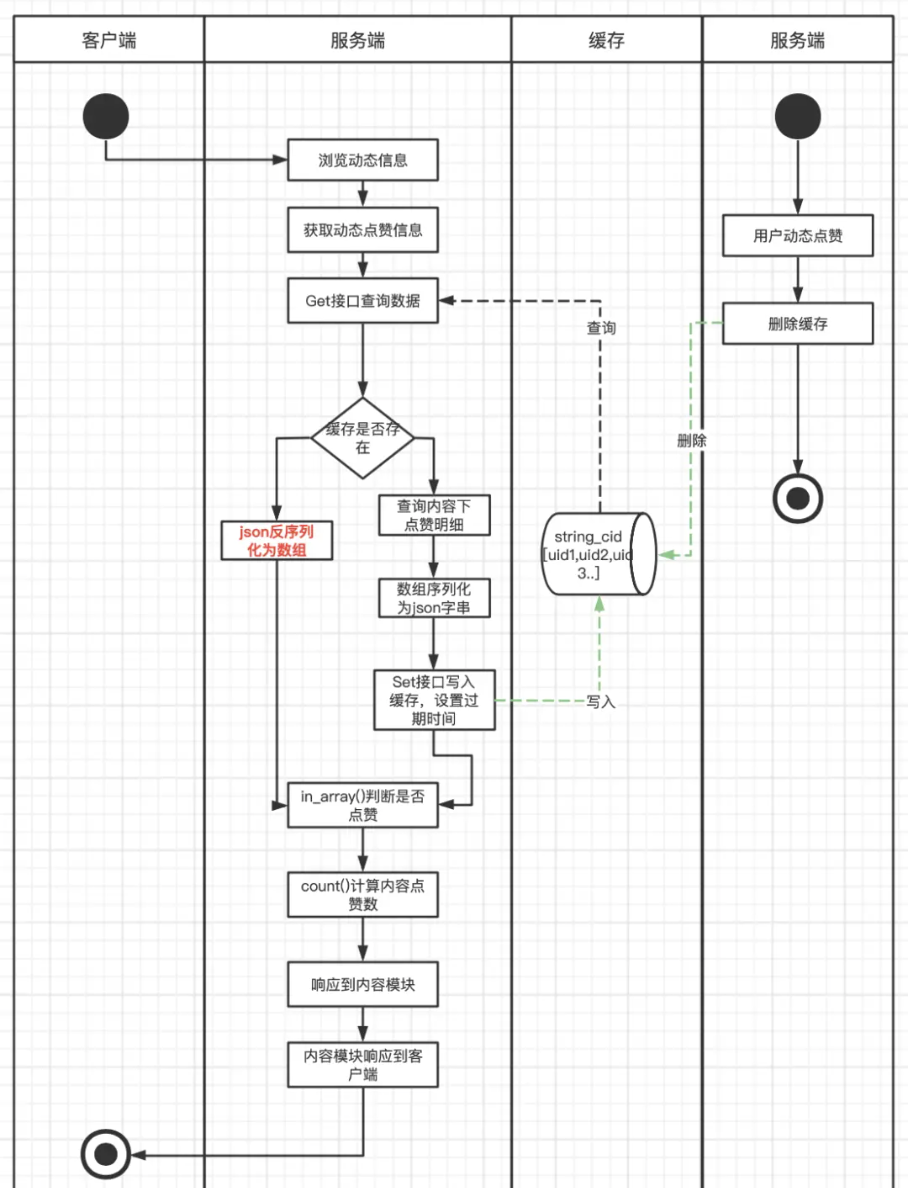
那使用这个架构方案的话就会有很多的问题存在。
首先缓存构造时要查询动态下所有点赞用户数据,数据量大,容易产生慢SQL,对DB和带宽都可能有比较大的压力。
其次缓存存储数据结构上为Key/Value结构,每次使用时需先从Redis查询,再反序列化成Go数组,in_array()和count() (这两个方法实际上是PHP的方法,这里借鉴的其他的文章,就不更改了)方法都有比较大的开销,尤其是查询热门动态时,对服务器的CPU和MEM资源都有一定浪费,对Redis也产生了比较大的网络带宽开销。
缓存维护上,每次新增点赞都直接清除缓存,热门动态大量点赞操作下会出现缓存击穿,会造成大量DB回查操作。
所以我们这里Redis中可以采用集合的结构来进行存储点赞的用户数据集合的特性保证集合中的用户ID不会出现重复,可以准确维护了动态下的点赞总数,通过查看用户是否在集合中,可以高效判断用户是否点赞内容。这样解决每次查询时需要从Redis中获取全部数据和每次需要代码解析Json的过程,Redis集合支持直接通过SISMEMBER和SCARD接口判断是否赞和计算点赞数,从而提升了整个模块的响应速度和服务负载。每次有新点赞时,主动向集合中添加用户ID,并更新缓存过期时间。每次查询时也同样会查询缓存的剩余过期时间,如果低于三分之一,就会重新更新过期时间,这样避免了热门动态有大量新增点赞动作时,出现缓存击穿的情况。
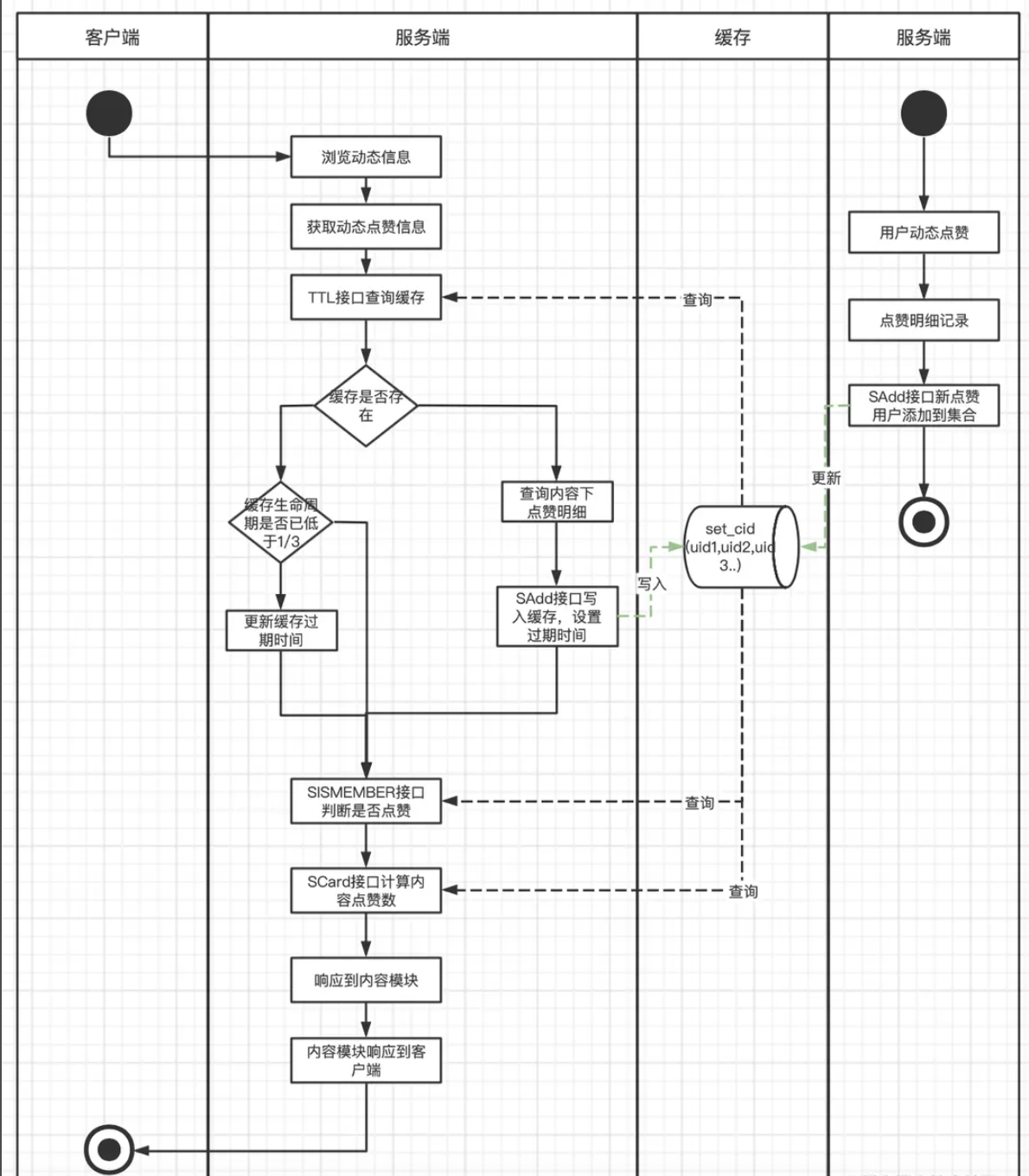
但是这个点赞还是和之前讲的粉丝列表和关注列表一样,也是一个存在大key的,当这个帖子是一个热门帖子的时候,那这时候点赞用户非常多,查询出来的点赞用户列表非常长,集合就变成一个大Key,而大Key的清理对Redis的稳定性有比较大的影响,随时可能会因为缓存过期,而引起Redis的抖动,进而引起服务的抖动。并且每次查询出全部的点赞用户,容易产生慢SQL,对网络带宽也比较有压力。
那么对于大key问题,我们已经写过文章了,可以去看一下。《高并发系统设计 – 热key问题解决》
这里看上去其实已经完成的差不多了,在一定时间内也能正常支撑点赞业务的高性能响应。但是,还是有许多可以优化的点,比如:
缓存分片中仍旧维护了被浏览动态下全部的点赞用户数据,消耗了非常大的Redis资源,也增加了缓存维护难度。缓存数据的有效使用率很低,推荐流场景下,用户浏览过的动态,几乎不会再次浏览到。
一些点赞量特别多的历史动态,有人访问时均会重建缓存,重建成本高,但使用率不高。 缓存集合分片的设计维护了较多无用数数据,也产生了大量的Key,Key在Redis中同样是占用内存空间的。
解决方案:
- 旧方案中访问内容点赞数据会重建缓存,有些老旧内容重建缓存性价比低,而且内容下的点赞用户并不是一直活跃和会重新访问内容,新方案要等区分冷热数据,冷数据直接访问DB,不再进行缓存的重建/更新维护。
- 旧方案在维护缓存过期时间和延长过期时间的设计中,每次操作缓存都会进行ttl接口操作,QPS直接x2。新方案要避免ttl操作,但同时又可以维护缓存过期时间。
- 缓存操作和维护要简单,期望一个Redis接口操作能达到目的。
- 所以新方案Redis数据结构的选择中,能判断是否点赞、是否是冷热数据、是否需要延长过期时间,之前的集合是不能满足了,我们选择Hash表结构。用户ID做Key,contentId做field,考虑到社区内容ID是趋势递增的,一定程度上contentID能代表数据的冷热,在缓存中只维护一定时间和一定数量的contentID,并且增加minCotentnID用于区分冷热数据,为了减少ttl接口的调用,还增加ttl字段用户判断缓存有效期和延长缓存过期时间
{
"userId":{
"ttl":1653532653, //缓存新建或更新时时间戳
"cid1":1, //用户近一段时间点赞过的动态id
"cid2":1, //用户近一段时间点赞过的动态id
"cidn":1, //用户近一段时间点赞过的动态id
"minCid":3540575, //缓存中最小的动态id,用以区分冷热,
}
}