文章目录
- 一、简介
- 二、脚本
- 1 格式
- 2 执行方式
- 3 变量
- 自定义变量
- 特殊变量
- 4 运算符
- 5 条件判断
- 6 流程控制
- 1 if判断
- 2 case语句
- 3 for循环
- 4 while 循环
- 七、read读取控制台输入
- 八、函数
- 1 basename
- 2 dirname
- 3 自定义函数
- 九、正则表达式
- 十、文本处理工具
- 1 cut
- 2 grep
- 3 sed
- 4 awk
一、简介
常见的shell

echo $SHELL # 查看当前使用的shell
二、脚本
1 格式
- 开头指定解析器;
#!/bin/bash
2 执行方式
# 1
sh ./脚本名 # 使用sh,让解析器来执行脚本
# 2
chmod +x 脚本 # 修改脚本权限,让脚本有权限自己执行
./脚本 # 直接执行
3 变量
set:显示系统所有变量;
unset 变量名:撤销变量;
readonly 变量名:静态变量,只读不能修改,不能unset;
export 变量名:全局环境变量,可被其他shell使用;
自定义变量
变量名=变量值 # 格式,注意=不能有空格
变量定义规则
- 可由字母、数字、下划线组成,不能数字开头;
- 等号两侧不能有空格;
- 默认为字符串类型,不能数值计算;
- 若有空格,则需要使用
'或";

特殊变量
$n:n代表第几个参数,十个以上需要在数字加上{};

$#:获取输入参数的个数;
$*:获取行中所有的参数,为一个整体;
$@:获取行中所有的参数,每个都区分;

$?:返回最后一次执行命令的状态;若为0,则正确;
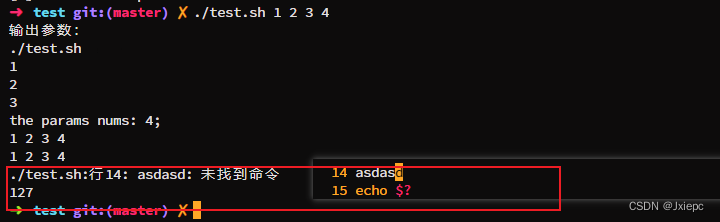
4 运算符
# 方式1
$((运算式))
# 方式2
$[运算式]

5 条件判断
格式
# 方式1
test condition
# 方式2
[ condition ] # 前后要有空格
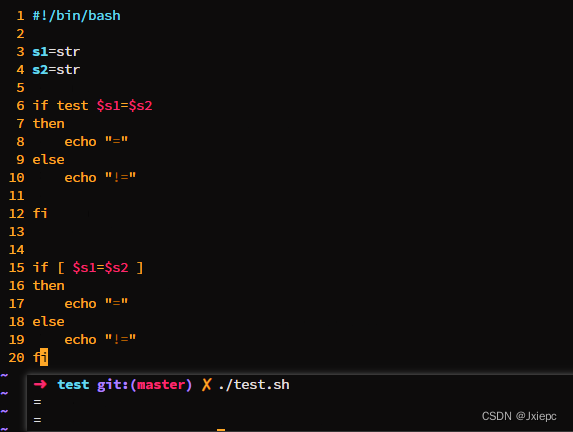
整数比较条件
-eq # equal 等于
-ne # not equal不等于
-lt # less than 小于
-le # less equal 小于等于
-gt # greater than 大于
-ge # greater equal 大于等于
字符串比较条件
= # 等于
!= # 不等于
按文件权限判断
-r # 读权限
-w # 写权限
-x # 执行权限
文件类型
-e # exist 文件存在
-f # file 文件存在且为常规文件
-d # dir 文件存在且为目录
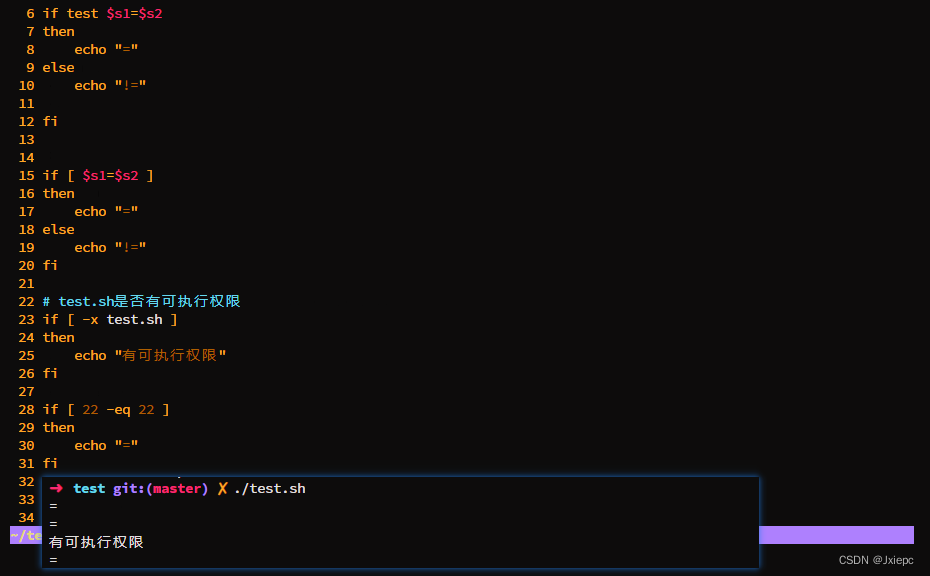
多条件判断
&& # 与
|| 或
6 流程控制
1 if判断
# 注意,if后需要有空格
# 单分支
if [ 判断 ]
then
# ...
fi
# 多分支
if [ 判断 ]
then
# ...
elif [ 判断 ]
then
# ...
else
# ...
fi
2 case语句
case $变量名 in
"值1")
# ...
;;
"值2")
# ...
;;
*) # 相当于default
# ....
;;
esac
3 for循环
#方式1
for(( 初始值;循环控制条件;变量变化 ))
do
# ...
done
# 方式2
for 变量 in 值1 值2 值3...
do
# ...
done
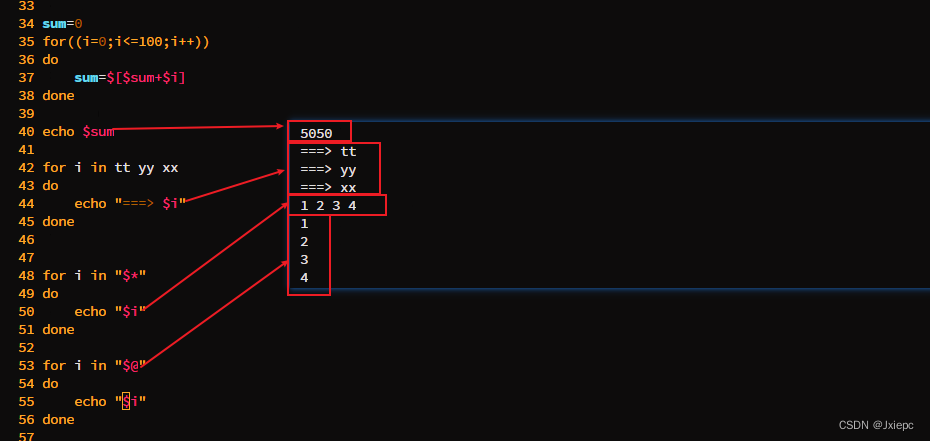
4 while 循环
while [ 判断 ]
do
# ...
done
七、read读取控制台输入
格式
read 选项 参数
# 选项
-p # 指定读取值时的提示符
-t # 指定读取值时等待的时间
# 参数
变量 # 指定读取值的变量名
read -t 7 -p "Enter your name in 7 seconds :" NN
echo $NN
八、函数
1 basename
格式
basename [string / pathname] [suffix] # 删掉所有的前缀包括最后一个/字符,再将字符串显示

2 dirname
格式
dirname 文件绝对路径 # 从给定的包含绝对路径的文件名中取去除文件名,返回剩下的路径

3 自定义函数
格式
[function] funname[()]
{
Action;
[return int;]
}
#[注意]:需要在调用前声明;函数返回值只能通过$?来获取
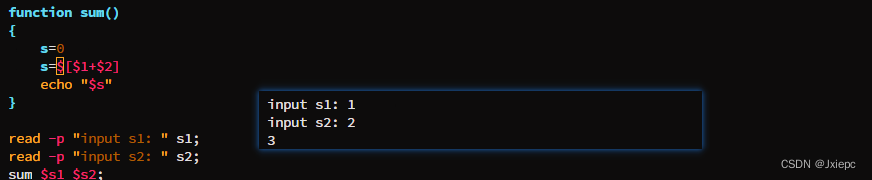
九、正则表达式
\w # 等价于 [A-Za-z0-9_]
. # 匹配除了\n\r之外
\s # 任意的空白字符
\S # 匹配任何非空白字符
^ # 在[]外表示开头,在[]内表示取反的意思
$ # 表示结尾
() # 子表达式的开始和结束
* # 匹配前表达式0或多次
+ # 匹配前表达式1或多次
? # 非贪婪限定符,匹配前子表达式0或多次
{m,n} # 匹配前表达式最少m次,最多n次
| # 选择左或右边的选项
# 贪婪和非贪婪
匹配最近的满足规则的 # 非贪婪
匹配范围最广的满足规则的 # 贪婪
案例
1 以S开头的字符串: ^S
2 以数字结尾的字符串: [0-9]$
[0123456789] # 匹配任意数字
[0-9] # 匹配任意数字
\d # 匹配任意数字
3 匹配空字符串(没有任何字符): ^$
4 字符串只包含三个数字: ^\d\d\d$ 或 ^\d{3}$
{n} 花括号括起来一个数字,表示前面的单元重复n次
5 字符串只有3到5个字母: ^[a-zA-Z]{3,5}$
{m,n} m表示前面单元最小重复次数,n表示最大重复次数
[a-zA-Z] 表示大小写字母 如果中括号中有多个区间,区间之间不要留空格或其他分隔符
6 匹配不是a-z的任意字符: ^[^a-z]$
[^a-z] 中括号中第一个字符如果是^,表示区间取反
7 字符串有0到1个数字或者字母或者下划线: ^[0-9a-zA-Z_]?$ 或 ^\w?$
{0,1} 表示重复0-1次
? 也可以表示0-1次重复
8 字符串有1个或多个空白符号(\t\n\r等): ^\s+$
\s 表示空白字符 包括 \t\n\r ....
{1,} 表示重复1-n 跟+号一样
9 字符串有0个或者若干个任意字符(除了\n)
. 代表任意字符,除了\n
^.{,}$ 花括号中两个参数置空表示重复次数任意 0-n
^.*$ *表示前面的单元重复0-n次
? 0-1
+ 1-n
* 0-n
10 匹配0或任意多组ABC,比如ABC,ABCABCABC: ^(ABC)*$
使用小括号来讲多个单元重新组合成为一个单元
11 字符串要么是ABC,要么是123: ^ABC$|^123$
| 表示选择,选择两边的正则匹配一个
^(ABC|123)$ 小括号也可以将选择范围控制在括号内
12 字符串只有一个点号: ^\.$
做转义 还是使用\
13 匹配十进制3位整数: ^([0-9]|[1-9][0-9]{1,2})$
100 - 999
^[1-9][0-9]{2}$
匹配十进制 0-999 的数字
分段
一位数
[0-9]
两位数
10-99
[1-9][0-9]
三位数
[1-9][0-9]{2}
14 匹配0-255的整数
匹配 ip
分段
一位数: [0-9]
两位数: 10-99 => [1-9][0-9]
三位数: 100-199 => 1[0-9]{2}
200-249 => 2[0-4][0-9]
250-255 => 25[0-5]
15 匹配端口号: 0-65535
16 email:[\w!#$%&'*+/=?^_`{|}~-]+(?:\.[\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\w](?:[\w-]*[\w])?\.)+[\w](?:[\w-]*[\w])?
十、文本处理工具
1 cut
cut [选项] filename
-f # 列号,提取第几列
-d # 分隔符,默认`\t`
-c # 按字符进行切割,后加n表示取第几列
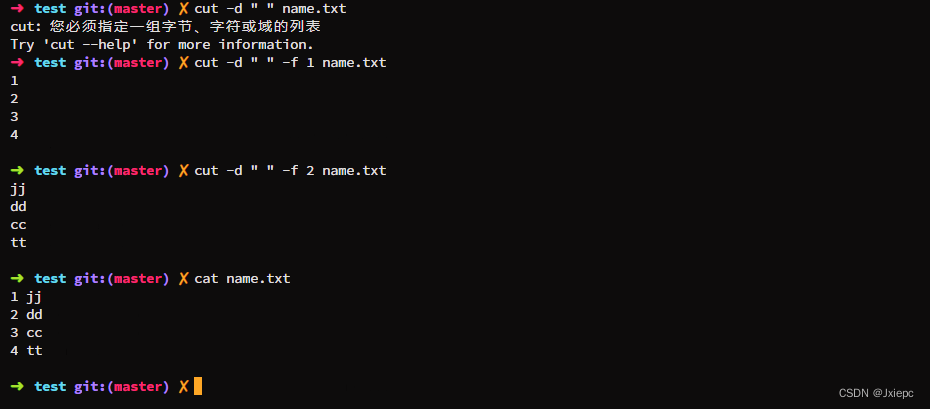
2 grep
-c # 只输出匹配行的计数
-i # 不区分大小写
-H # 文件名显示
-r # 递归遍历目录
-n # 显示行号
-s # 不显示不存在或无匹配文本的错误信息
-v # 显示不包含匹配文本的所有行,这个参数经常用于过滤不想显示的行
-E # 使用扩展的正则表达
-P # 使用perl的正则表达式
-F # 匹配固定的字符串,而非正则表达式
egrep = grep -E
fgrep = grep -F
rgrep = grep -r
3 sed
文本1 -> sed + 脚本 -> 文本2
ed 编辑器 -> sed -> vim
sed option 'script' file1 file2 ... # sed 参数 ‘脚本(/pattern/action)’ 待处理文件
sed option -f scriptfile file1 file2 ... # sed 参数 –f ‘脚本文件’ 待处理文件
p, print # 打印
a, append # 追加
i, insert # 插入
d, delete # 删除
s, substitution # 替换
4 awk
awk option 'script' file1 file2 ...
awk option -f scriptfile file1 file2 ...
最常见用法就是过滤哪一列
xxxx | awk '{print $2}'
参数
-F # 指定输入文件分隔符
-v # 赋值一个用户定义变量
脚本格式:
{actions} # 每一行文本都无条件的执行脚本
/pattern/{actions} # 匹配了模式之后再执行后面的动作
condition{actions}
BEGIN
# 在遍历文本的第一行之前会执行某个动作
END
# 在遍历完文本之后再去执行某个动作