'''均摘自C语言中文网'''
网页一般由三部分组成,分别是 HTML(超文本标记语言)、CSS(层叠样式表)和 JavaScript(简称“JS”动态脚本语言),它们三者在网页中分别承担着不同的任务。
- HTML 负责定义网页的内容
- CSS 负责描述网页的布局
- JavaScript 负责网页的行为
HTML
HTML 是网页的基本结构,它相当于人体的骨骼结构。网页中同时带有“<”、“>”符号的都属于 HTML 标签。常见的 HTML 标签如下所示:
<!DOCTYPE html> 声明为 HTML5 文档 <html>..</html> 是网页的根元素 <head>..</head> 元素包含了文档的元(meta)数据,如 <meta charset="utf-8"> 定义网页编码格式为 utf-8。 <title>..<title> 元素描述了文档的标题 <body>..</body> 表示用户可见的内容 <div>..</div> 表示框架 <p>..</p> 表示段落 <ul>..</ul> 定义无序列表 <ol>..</ol>定义有序列表 <li>..</li>表示列表项 <img src="" alt="">表示图片 <h1>..</h1>表示标题 <a href="">..</a>表示超链接

CSS
CSS 表示层叠样式表,其编写方法有三种,分别是行内样式、内嵌样式和外联样式。CSS 代码演示如下:

如图所示内嵌样式通过 style 标签书写样式表:
<style type="text/css"></style>
而行内样式则通过 HTML 元素的 style 属性来书写 CSS 代码。注意,每一个 HTML 元素,都有 style,class,id,name,title 属性。
外联样式表指的是将 CSS 代码单独保存为以 .css 结尾的文件,并使用 <link> 引入到所需页面:
<head> <link rel="stylesheet" type="text/css" href="mystyle.css"> </head>
当样式需要被应用到多个页面的时候,使用外联样式表是最佳的选择。
JavaScript
JavaScript 负责描述网页的行为,比如,交互的内容和各种特效都可以使用 JavaScript 来实现。当然可以通过其他方式实现,比如 jQuery、还有一些前端框架( vue、React 等),不过它们都是在“JS”的基础上实现的。

HTML为骨架;CSS为外观;JS为功能;
当我们在编写一个爬虫程序前,首先要明确待爬取的页面是静态的,还是动态的,只有确定了页面类型,才方便后续对网页进行分析和程序编写。对于不同的网页类型,编写爬虫程序时所使用的方法也不尽相同。
静态网页
静态网页是标准的 HTML 文件,通过 GET 请求方法可以直接获取,文件的扩展名是.html、.htm等,网面中可以包含文本、图像、声音、FLASH 动画、客户端脚本和其他插件程序等。静态网页是网站建设的基础,早期的网站一般都是由静态网页制作的。静态并非静止不动,它也包含一些动画效果,这一点不要误解。
我们知道,当网站信息量较大的时,网页的生成速度会降低,由于静态网页的内容相对固定,且不需要连接后台数据库,因此响应速度非常快。但静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据全部包含在 HTML 中,因此爬虫程序可以直接在 HTML 中提取数据。通过分析静态网页的 URL(地址之符),并找到 URL 查询参数的变化规律,就可以实现页面抓取。与动态网页相比,并且静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页指的是采用了动态网页技术的页面,比如 AJAX(是指一种创建交互式、快速动态网页应用的网页开发技术)、ASP(是一种创建动态交互式网页并建立强大的 web 应用程序)、JSP(是 Java 语言创建动态网页的技术标准) 等技术,它不需要重新加载整个页面内容,就可以实现网页的局部更新。
动态页面使用“动态页面技术”与服务器进行少量的数据交换,从而实现了网页的异步加载。下面看一个具体的实例:打开百度图片(百度图片-发现多彩世界)并搜索 Python,当滚动鼠标滑轮时,网页会从服务器数据库自动加载数据并渲染页面,这是动态网页和静态网页最基本的区别。如下所示 
动态网页中除了有 HTML 标记语言外,还包含了一些特定功能的代码。这些代码使得浏览器和服务器可以交互,服务器端会根据客户端的不同请求来生成网页,其中涉及到数据库的连接、访问、查询等一系列 IO 操作,所以其响应速度略差于静态网页。
审查网页元素
对于一个优秀的爬虫工程师而言,要善于发现网页元素的规律,并且能从中提炼出有效的信息。因此,在动手编写爬虫程序前,必须要对网页元素进行审查。本节将讲解如何使用“浏览器”审查网页元素。
检查网页结构
对于爬虫而言,检查网页结构是最为关键的一步,需要对网页进行分析,并找出信息元素的相似性。下面以猫眼电影网为例,检查每部影片的 HTML 元素结构。如下所示:
经过对比发现,除了每部影片的信息不同之外,它们的 HTML 结构是相同的,比如每部影片都使用<dd></dd>标签包裹起来。这里我们只检查了两部影片,在实际编写时,你可以多检查几部,从而确定它们的 HTML 结构是相同的。
知识准备
Web前端
了解 Web 前端的基本知识,比如 HTML、CSS、JavaScript,这能够帮助你分析网页结构,提炼出有效信息。推荐阅读《HTML入门教程》、《CSS教程》、《JS入门教程》。
HTTP协议
掌握 OSI 七层网络模型,了解 TCP/IP 协议、HTTP 协议,这些知识将帮助您了解网络请求(GET 请求、POST 请求)和网络传输的基本原理。同时,也有助您了解爬虫程序的编写逻辑
Python 爬虫介绍
一、什么是爬虫
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
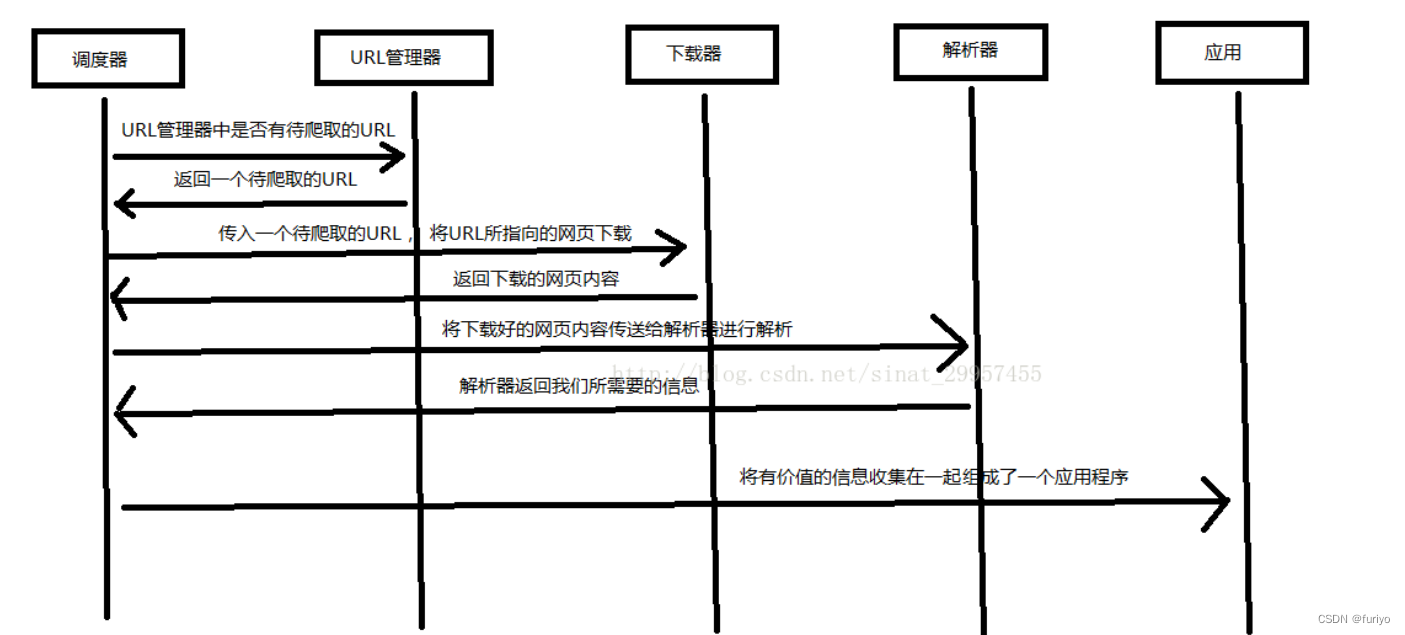
二、Python爬虫架构
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。