MySQL GROUP BY
【 GROUP BY】 子句用于将结果集根据指定的字段或者表达式进行分组。
有时候,我们需要将结果集按照某个维度进行汇总。这在统计数据的时候经常用到,考虑以下的场景:
- 按班级求取平均成绩。
- 按学生汇总某个人的总分。
- 按年或者月份统计销售额。
- 按国家或者地区统计用户数量。
GROUP BY语法
【GROUP BY】 子句是 SELECT 语句的可选子句。 GROUP BY 子句语法如下:
SELECT column1[, column2, ...], aggregate_function(ci)
FROM table
[WHERE clause]
GROUP BY column1[, column2, ...];
[HAVING clause]
说明:
【column1[, column2, ...]】是分组依据的字段,至少一个字段,可以多个字段。【aggregate_function(ci)】是聚合函数。这是可选的,但是一般都用得到。【SELECT】后的字段必须是分组字段中的字段。【WHERE 】子句是可选的,用来过滤结果集中的数据。【HAVING】子句是可选的,用来过滤分组数据。
经常使用的聚合函数主要有:
SUM(): 求总和AVG(): 求平均值MAX(): 求最大值MIN(): 求最小值COUNT(): 计数
GROUP BY实例
简单的GROUP BY 实例
创建actor表
DROP TABLE IF EXISTS `actor`;
CREATE TABLE `actor` (
`actor_id` int(11) NOT NULL AUTO_INCREMENT,
`last_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`first_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`gender` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '男',
`age` int(11) NOT NULL,
PRIMARY KEY (`actor_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
插入数据
INSERT INTO `actor` VALUES (1, '李', '小龙', '男', 33);
INSERT INTO `actor` VALUES (2, '刘', '德华', '男', 60);
INSERT INTO `actor` VALUES (3, '梁', '朝伟', '男', 58);
INSERT INTO `actor` VALUES (4, '张', '家辉', '男', 55);
INSERT INTO `actor` VALUES (5, '刘', '嘉玲', '女', 58);
INSERT INTO `actor` VALUES (6, '周', '润发', '男', 60);
INSERT INTO `actor` VALUES (7, '古', '天乐', '男', 58);
INSERT INTO `actor` VALUES (8, '吴', '京', '男', 48);
INSERT INTO `actor` VALUES (9, '周', '也', '女', 24);
INSERT INTO `actor` VALUES (10, '周', '星驰', '男', 59);
SET FOREIGN_KEY_CHECKS = 1;
查看actor表中的姓氏列表
SELECT last_name
FROM actor
GROUP BY last_name;
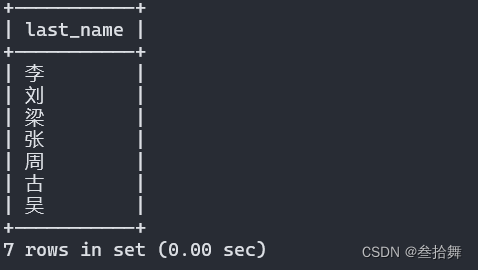
本例中,使用 【GROUP BY 】句按照 last_name 字段对数据进行分组。
本例的输出结果与以下使用 DISTINCT 的 SQL 输出结果完全一样:
SELECT DISTINCT last_name FROM actor;
GROUP BY 与聚合函数实例
我们使用 【GROUP BY 】子句和聚合函数 【COUNT() 】查看 actor 表中的姓氏列表以及每个姓氏的次数。
SELECT last_name, COUNT(*)
FROM actor
GROUP BY last_name
ORDER BY COUNT(*) DESC;
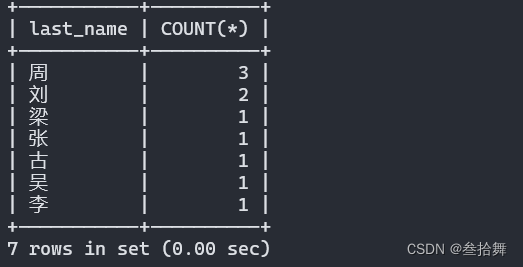
本例中,执行顺序如下:
- 首先使用 GROUP BY 子句按照 last_name 字段对数据进行分组。
- 然后使用聚合函数 COUNT(*) 汇总每个姓氏的行数。
- 最后使用 ORDER BY 子句按照 COUNT(*) 降序排列。
这样,数量最多的姓氏排在最前面。
GROUP BY 和 HAVING 实例
统计演员片酬大于【1500W】的演员有哪些
SELECT *
from actor
GROUP BY actor_id
HAVING salary > 1500
ORDER BY salary DESC;

结论
在本文中,我们介绍了在 MySQL 中使用 GROUP BY 子句将结果集根据指定的列或者表达式进行分组。以下是 GROUP BY 子句的要点:
GROUP BY子句用于将结果集根据指定的字段或者表达式进行分组。GROUP BY子句的分组字段或表达式至少一个,可以多个。HAVING子句是可选的,用来过滤分组数据。GROUP BY子句经常用于数据统计汇总,通常使用聚合函数。