这才是真正RAG,如果只是把检索得到结果放到prompt里面,可能够呛。
好久没有读paper了,最近因为有个小工作,来读一篇较早提出来RAG想法的文章吧。这篇文章是Facebook、伦敦大学学院以及纽约大学的研究者们搞出来的。文章首先指出,目前大语言模型在一些知识密集型任务上,性能并不高,而且你总不能一直要求大语言模型不断训练新知识吧,成本也是很高的,于是乎。他们提出了a general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) — models which combine pre-trained parametric and non-parametric memory for language generation. 基于RAG的微调方法,用这个方法模型会将预训练的参数和非参数记忆结合起来进行内容生成。这句话听起来有些麻烦,但是咱们仔细看看他们是怎么做的。但是在看细节之前,先讲一下为什么现在RAG这么火,到处都在尝试用。主要原因就是大语言模型的Hallucination,幻觉特性。也就是大语言模型会,讲出不符合实际的回答(与事实不一致,或者直接捏造),有点像瞎编的一样。一些研究人员把幻觉主要分成了几类:
- 和指令表现不符,LLM忽略了用户的指令。比如你跟他说我要用中文回答,LLM用英文回答了问题。
- 上下文不一致,LLM输出了与所提供的上下文不存在或矛盾的信息。
- 逻辑不一致,LLM的输出存在逻辑错误。
幻觉的原因,目前大家主要说的是这么几点:
- 无法反映出训练数据集中没有的知识点,所以瞎说
- 训练数据集庞大、复杂、多样,事实正确性,无偏见性、公平性根本无法保证。
- 模型的训练目标不一致。
- 推理阶段,上下文注意力不足、采样方法的随机性导致输出的随机性。
- 提示词缺乏明确的背景信息或措辞含糊。
为了解决幻觉这个问题,有这么几种方向,比如更好的Prompt提示信息,提高数据质量,使用评分系统等等,RAG可以看作是一种更好的Prompt提示信息。相比于让通用的大语言模型直接回答用户的问题,RAG将更相关的背景知识一起送给大语言模型,在进行序列字符的概率预测时,相当于减少了一些不确定性。我不用再从10个球里选那个红色的了,而是从3个球里选。有这种感觉。
接下来废话不多说,继续来看这篇文章,作者的RAG模型中,参数记忆是预先训练好的seq2seq模型,就是咱们的LLM。非参数记忆是一个维基百科的向量索引,可以通过检索器进行访问。作者比较了两种RAG,We compare two RAG formulations, one which conditions on the same retrieved passages across the whole generated sequence, and another which can use different passages per token。这个要怎么理解呢,
实验任务是三个开放领域的QA任务,模型表现当然是优于不做RAG的LLM以及一些特定任务的模型框架。我们来看一下文章的框架图:

看起来挺复杂,不过大致可以看到query来了以后encoder一下,然后根据maximum inner product search,最大点积向量搜索,找到维基百科中最相关的K个文档,然后送给文本生成器,让其进行文本序列的预测。文章是这么公式化咱们的生成器:

翻译一下就是,两步走:
- Retriever:给定原始输入x(用户query),检索得到TopK的文档片段z。文章用了Dense Passage Retrieval(详见:https://github.com/facebookresearch/DPR)。
- Generator:给定原始输入x和检索得到的相关文档片段z,生成字符序列,且是不断根据之前的字符预测下一个字符。文章用了BRAT模型(详见:https://huggingface.co/docs/transformers/en/model_doc/bart)。
另外,文章提出了两种RAG形式:
RAG-sequence:根据检索到的同一个文档来生成sequence。
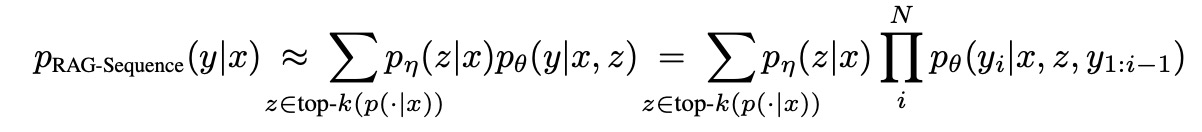
看公式,右边是一个连乘符号,把所有单个token得概率相乘,得到整个sequence的概率,然后左边是咱根据输入x检索得到z的概率。将两者相乘后,相当于对于给定的x和检索出的z,生成sequence得概率。因为z是有k个,所以整体都要加在一起。
RAG-Token:根据检索到的所有文档来生成一个一个的token。
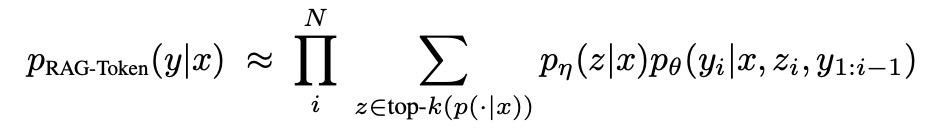
看公式,对于每个生成的token,即yi的概率,都和根据x检索得到z的概率进行了相乘。因为有TopK个z,所以要进行加和。然后对于所有的token,整个再相乘,以得到整个输出sequence的概率。
最后最后我们再总结一下这个过程:
- 检索器将输入变成embedding后,利用DPR算法来检索相关文本,用了MIPS计算的。
- 然后检索得到的文本z和咱们的用户query x,一起送给BART模型,模型基于z和x,依次生成第i个字符。并且计算所有N个字符输出出来的时候的概率,即当前sequence的概率。
- 针对所有Top K个检索回来的文档分别计算概率,通过将所有概率相加(Marginalisation/边缘化)以推断出根据用户query x,检索K个相关文档,返回给大语言模型后得到输出的概率。
在训练的时候,作者表明他们并没有给出任何监督的信息,即什么样的文本应该被检索出来。仅仅fine-tuning 查询query的encoder BERTq 以及BART生成器。最后在Decode阶段,要重点讲一下RAG-sequence,token那种一次就把每个字符确定了所以其实问题不大。但是对于sequence,每篇检索得到的文章出来的sequence可能并不相同,那就需要看怎么操作一下。
首先,作者利用beam search(搜索算法,用于在图或树结构中扩展最有希望的节点)得到了每篇基于检索得到的文章z,所生成出来比较好的一些结果y。但是并不是所有的z都是一样的答案。于是,为了估计到底得到什么y,对于每个文章z在进行beam search中有些没有出现的y,进行了前向传播以得到概率,然后将该概率带入计算最终的边缘概率里,该操作叫thorough decoding。当y序列长度较长时,生成后就不进行前向传播,以节省计算资源,该操作叫fast decoding。
最后的最后,总的来说,这篇文章把检索器的query encoder和一个seq2seq的文本生成模型,串在了一起做训练。