资源整理
参考教程:StableDiffusion/NAI DreamBooth自训练全教程 - 知乎 (zhihu.com)
云服务器平台:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
镜像链接:CrazyBoyM/dreambooth-for-diffusion/dreambooth-for-diffusion、
代码仓库:CrazyBoyM/dreambooth-for-diffusion: AIGC模型训练工具箱 (完整封装、一体化训练stable diffusion, 可训练定制自己的独特大模型风格、人物,开箱即用,内含详细教程)
话不多说,结合我看的教程,对我自己的训练过程进行一个具体的记录。
环境搭建
根据我之前的文章《云服务器平台AutoDL--基本介绍与使用感受-CSDN博客》,无需自己搭建环境,直接在AutoDL平台选择一个3090机器拉取镜像,镜像链接(其中包含如何使用的视频教程)如下:CrazyBoyM/dreambooth-for-diffusion/dreambooth-for-diffusion: 首个完整封装、一体化训练stable diffusion dreambooth的镜像环境,可训练定制自己的独特大模型风格、人物,开箱即用,内含详细教程。 - CG (codewithgpu.com)
创建的实例如下:
(因为我训练了几次,每次的参数、训练内容都不太一样,为了保留过程,我分开在多个机器上进行了训练,所以有好几个实例)
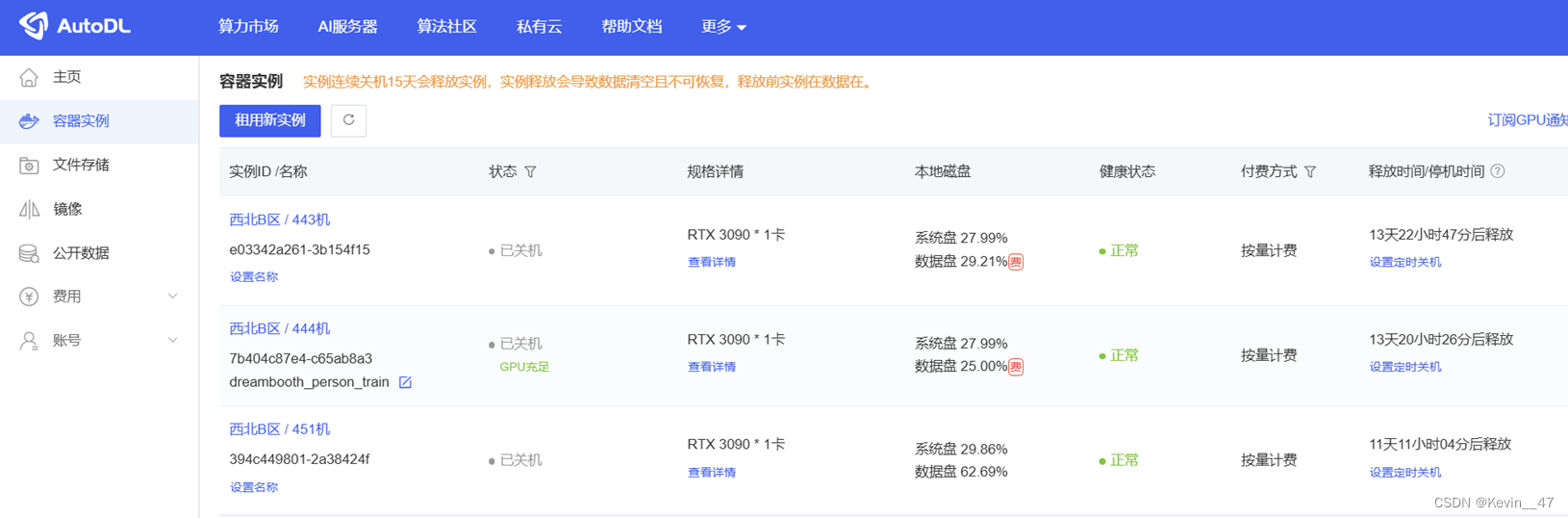
其中每个服务器实例的具体配置如下:

在上述镜像中,已经直接将所有需要使用的命令写在了文件夹下的“运行.ipynb”文件中。

一些基本的操作(文件夹位置的移动、工作路径的切换...)在这个.ipynb文件中已经描述的很清楚了,本文不再赘述。
根据教程所述,在拉取的镜像中已经包含了两个官方提供的模型,如下图所示。

其中,nd_lastest.ckpt用于二次元图像训练,v1-5-pruned.ckpt用于三次元图像(偏写实风格)训练。
虽然但是,在我拉取的镜像中并没有用于三次元训练的模型文件,然后我又去hugging face上进行了下载和上传。
下载地址:runwayml/stable-diffusion-v1-5 at main (huggingface.co)
这个写实风格的模型文件因为参数比较丰富,因此较大,一共有7.7G,上传起来比较缓慢。
hugging face似乎是有着大用处的,以后有时间一定好好研究一下!
基于此,我分别进行了二次元图像和三次元图像的训练,接下来分别进行讲解。
二次元图像训练
数据集准备
互联网图像搜集,这里就使用了比较可爱的海绵宝宝形象。

使用镜像中提供的程序将图像剪裁成512*512的大小。

模型文件转换
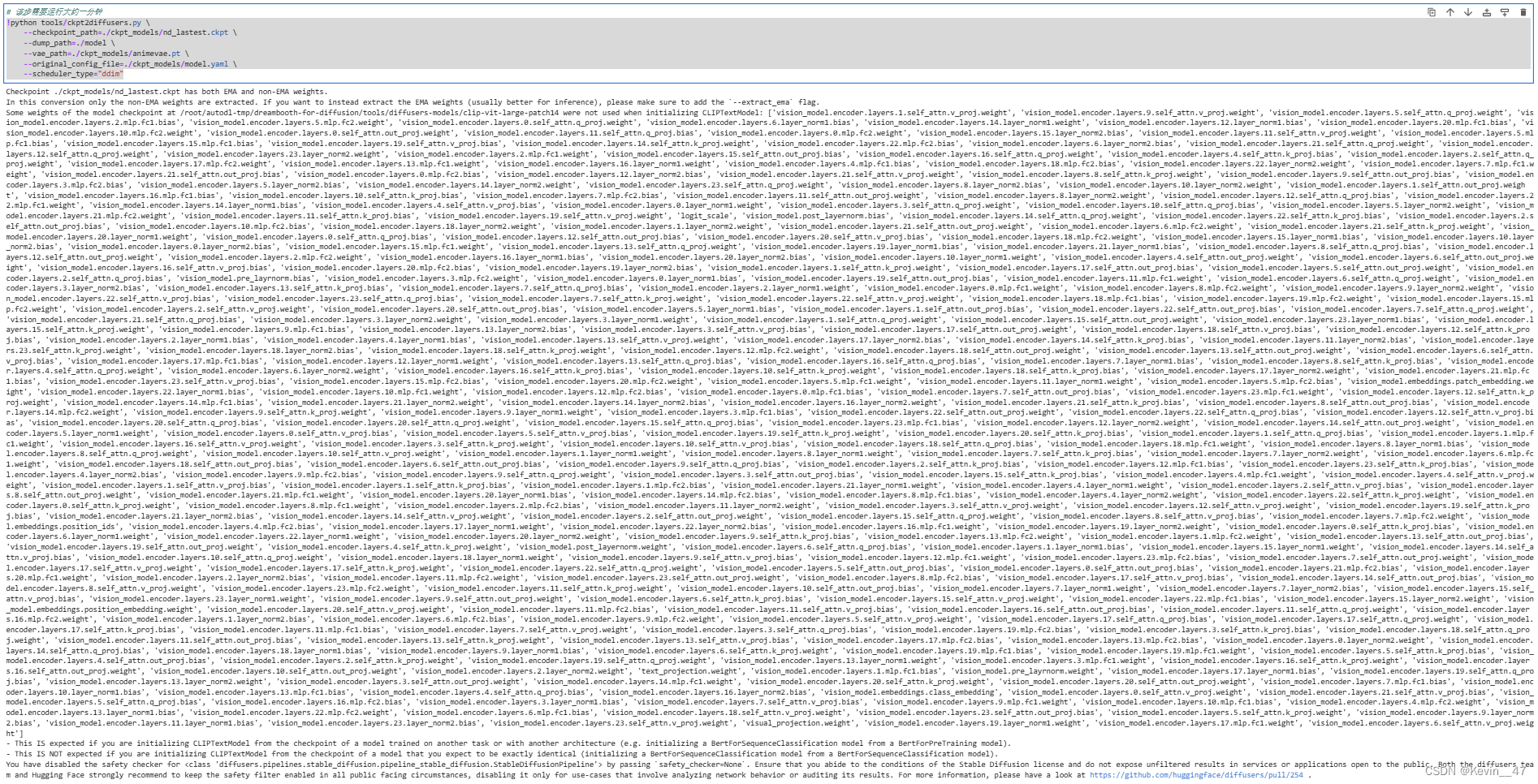
转换ckpt检查点文件为diffusers官方权重,转换二次元风格模型:
!python tools/ckpt2diffusers.py \
--checkpoint_path=./ckpt_models/nd_lastest.ckpt \
--dump_path=./model \
--vae_path=./ckpt_models/animevae.pt \
--original_config_file=./ckpt_models/model.yaml \
--scheduler_type="ddim"运行效果如下图所示。
训练过程
二次元图像在开始训练前需要给图片加上描述,具体过程参考.ipynb文件。
修改train_object.sh文件中的相关设置,修改的部分如下图所示。
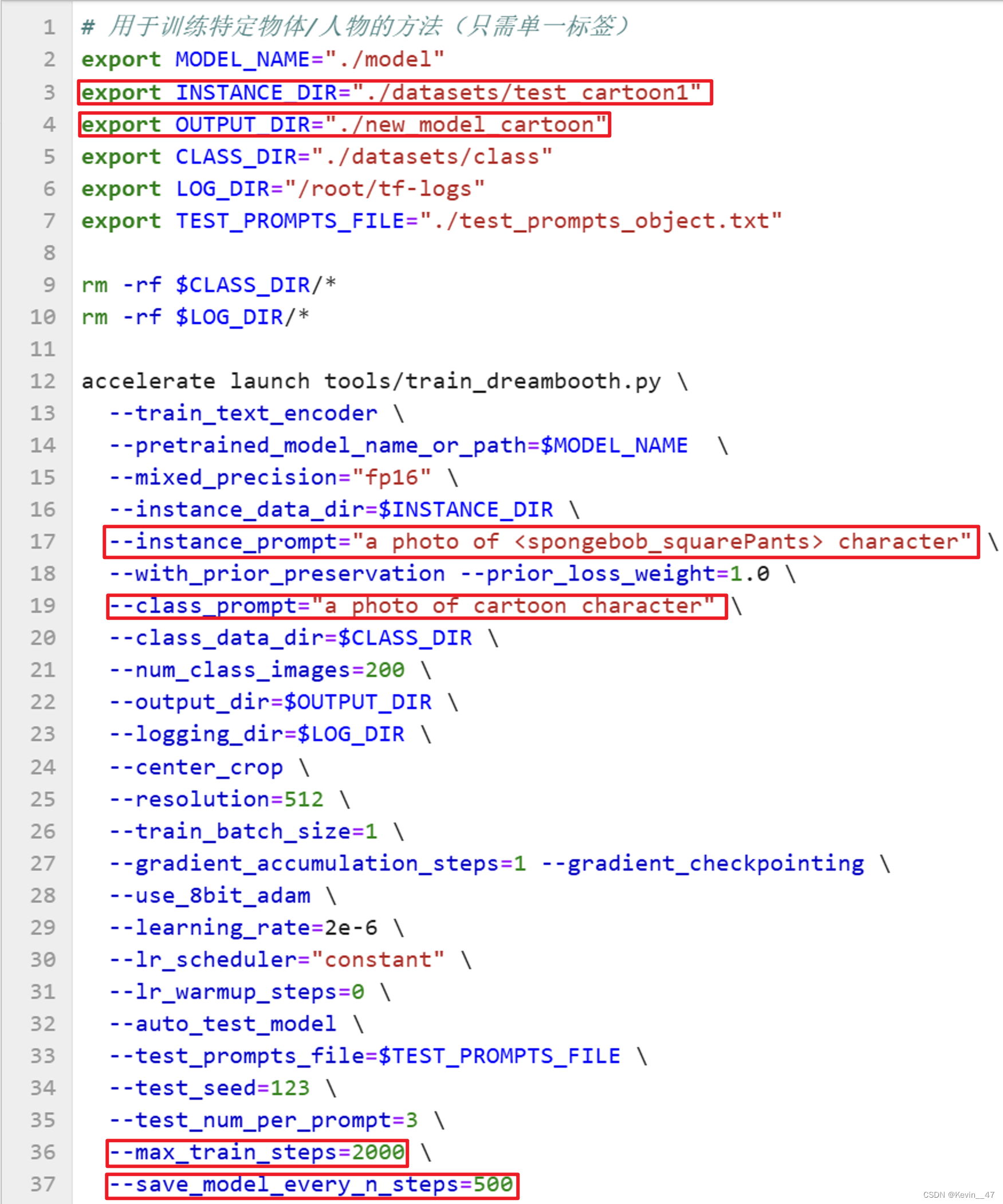
然后运行该文件。
!sh train_object.sh中间过程命令行输出如下图所示。
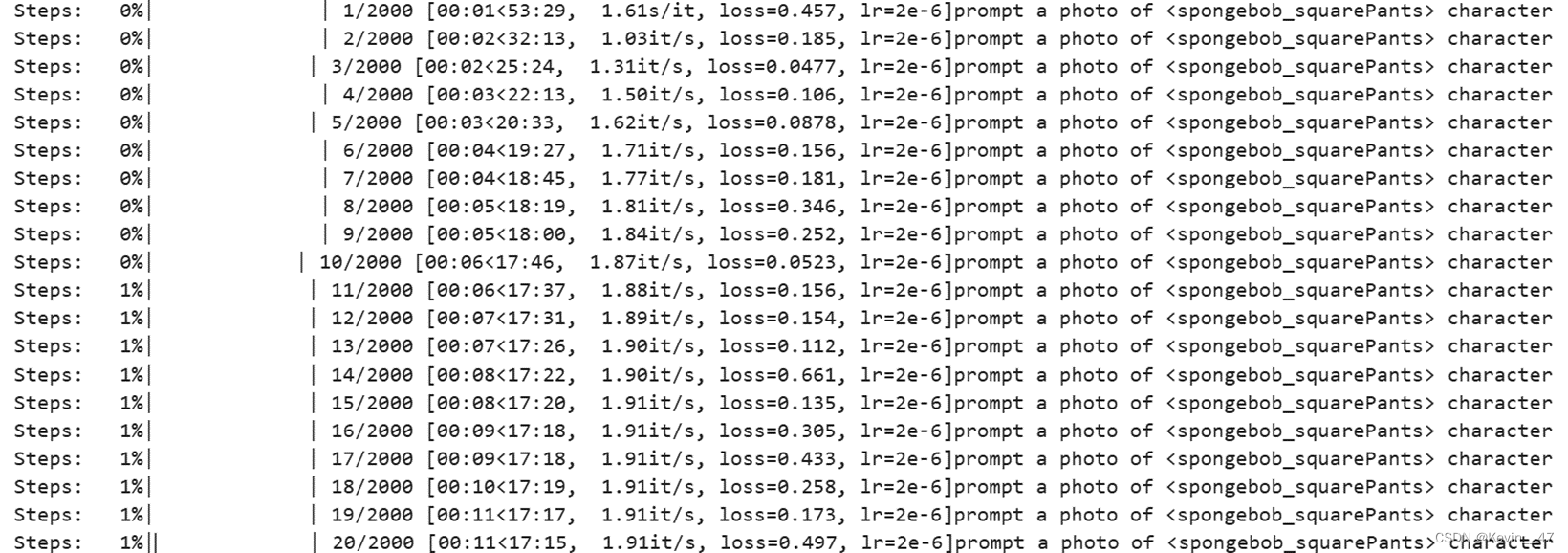
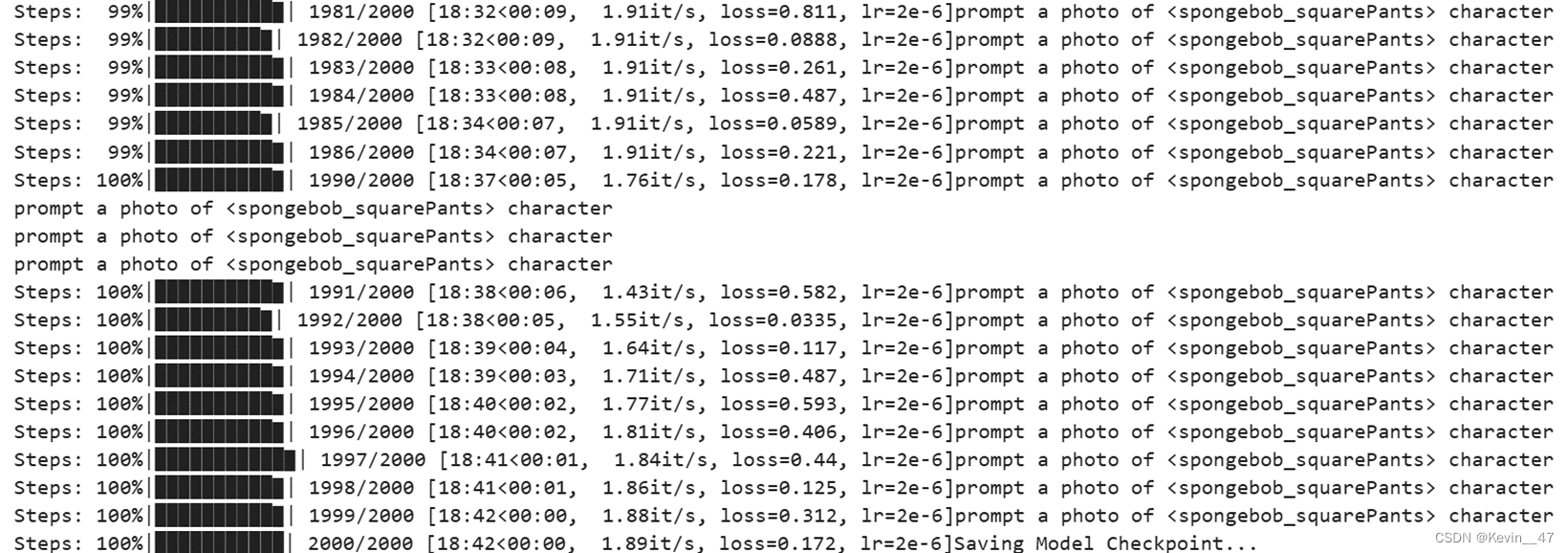
训练到最后的命令行输出如图所示。从图中可以看出训练2000步只需要20min不到的时间,并且最终的训练用时18:42和一开始预估的17:37来去不大。
图像生成
修改test_model.py文件,主要将调用路径改为训练好的模型,然后结合实际生成效果,调整提示词、生成步数、每次生成的张数。
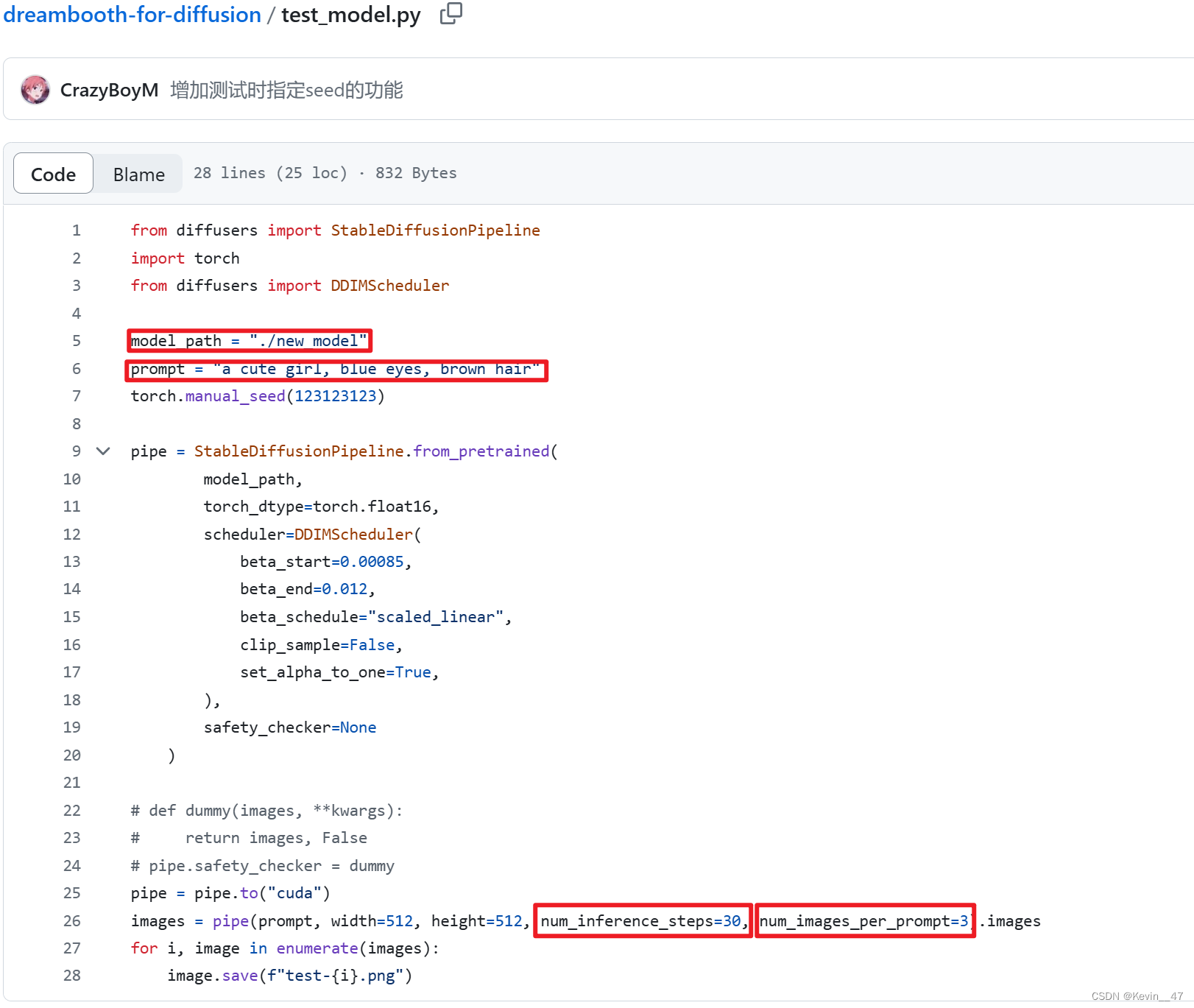
运行test_model.py。
!python test_model.py几个生成的结果如图所示。


三次元图像训练
数据集准备
我在网上又搜集了霉霉的图片,然后准备代入模型训练。

还是通过tools/handle_images.py将搜集到的图像裁剪成512*512的大小。这里我没有再另外将图像下载到本地进行显示。
模型文件转换
这次转换的是v1-5-pruned.ckpt模型文件。
!python tools/ckpt2diffusers.py \
--checkpoint_path=./ckpt_models/v1-5-pruned.ckpt \
--dump_path=./model \
--original_config_file=./ckpt_models/model.yaml \
--scheduler_type="ddim"训练过程
修改模型的输入输出文件夹,修改相关的prompt,这次我将训练的总步数设置为10000步,每1000步进行一次模型保存,具体的训练过程如下:
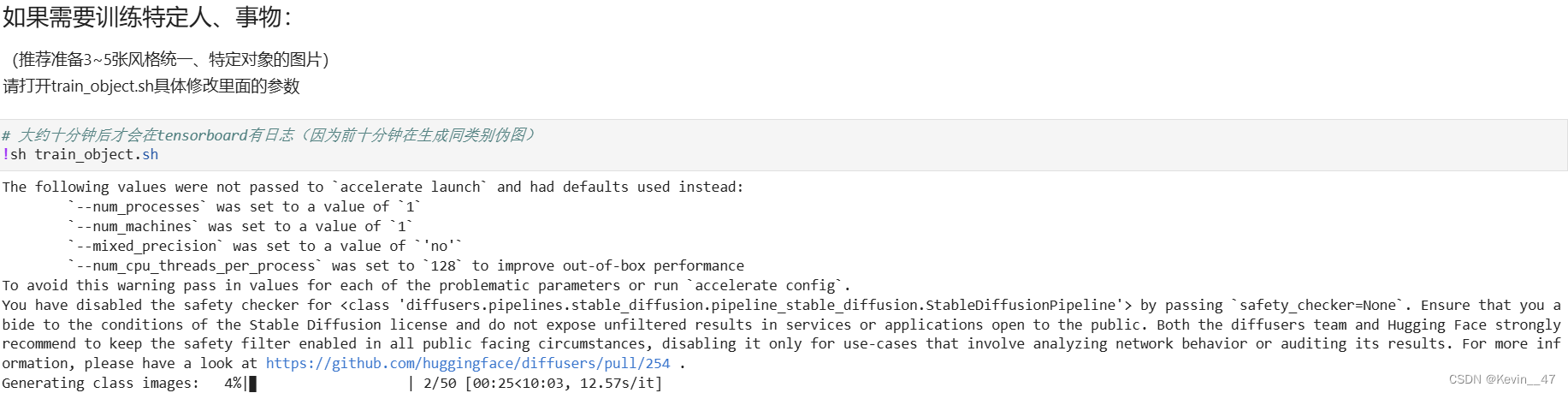
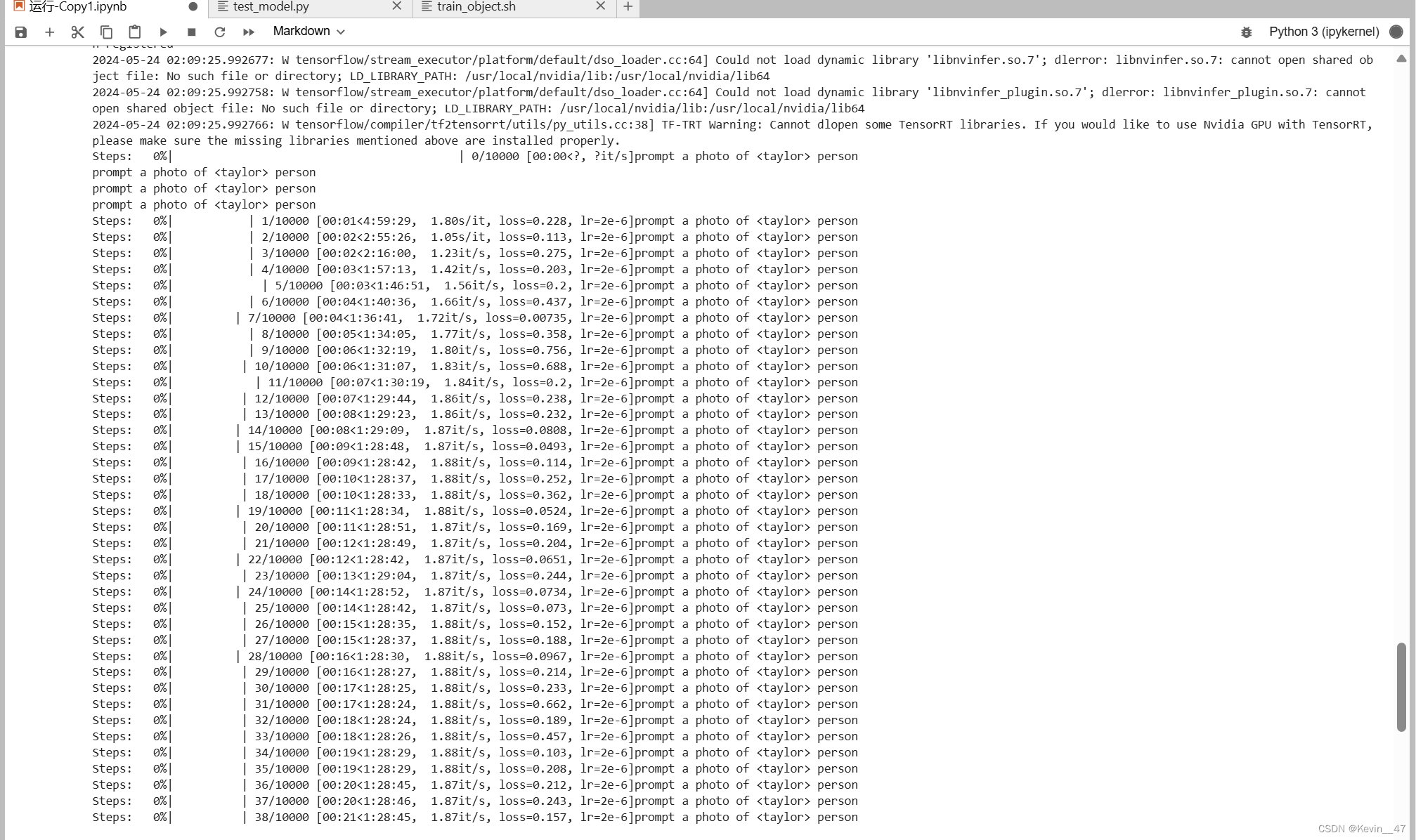
从图中可以看出10000步的训练时间大概在1.5h左右。
这里需要注意的是,如果中间过程保存的模型较多(比如500步保存一次)可能会使免费的50GB数据盘跑爆,请根据实际需求进行扩容或调整模型保存的间隔步数。
另一个需要注意的问题是,扩容之后我虽然没有跑爆数据盘,但是我确实没有拿到第10000步的训练模型,训练过程中我离开了,等我离开足够长的时间再回来,发现.ipynb中运行的cell卡住了,没有报错也没有再继续输出了,查看模型文件夹,也是空的,但是第9000步的训练模型确实是完成了,时间有限,我也没再跑了。
图像生成
这里的prompt在开头都是与训练时相同的a photo of <taylor> person,后面跟的提示词分别是in white/pink/blue dress,设置的生成步数为30,最终生成的图像如下:

说句题外话:从PPT复制时同时选中三张图片,粘贴过来就自动合成了一张,布局与PPT中一致,以后可以用于并列放图。
至此我的所有复现过程全部讲解完毕。
反思
最终训练后的模型生成图像的效果不是太好,经过分析后可能的原因如下:
1. 训练步数过长可能过拟合,过短可能学习不充分;
最终展示的结果并没有使用最终的训练模型,使用9000步存下来的模型效果也就那样,对比2000/3000步出来的结果并没有明显的优越性,训练时长上去了GPU还要花更多的钱。
2. 训练输入图像3-5张就够了;
训练效果的好坏似乎与输入图像的张数多少没有直接关系。
3. 训练时的相关参数未调试。
由于我并不研究图像方面,对于相关参数调整会带来的效果并不清楚,时间有限,也没有进行深入研究。
其他的资源
有机会可以再看下(其实我也不懂为什么他训练出来的效果就这么好呜呜呜)。
runwayml/stable-diffusion: Latent Text-to-Image Diffusion (github.com)