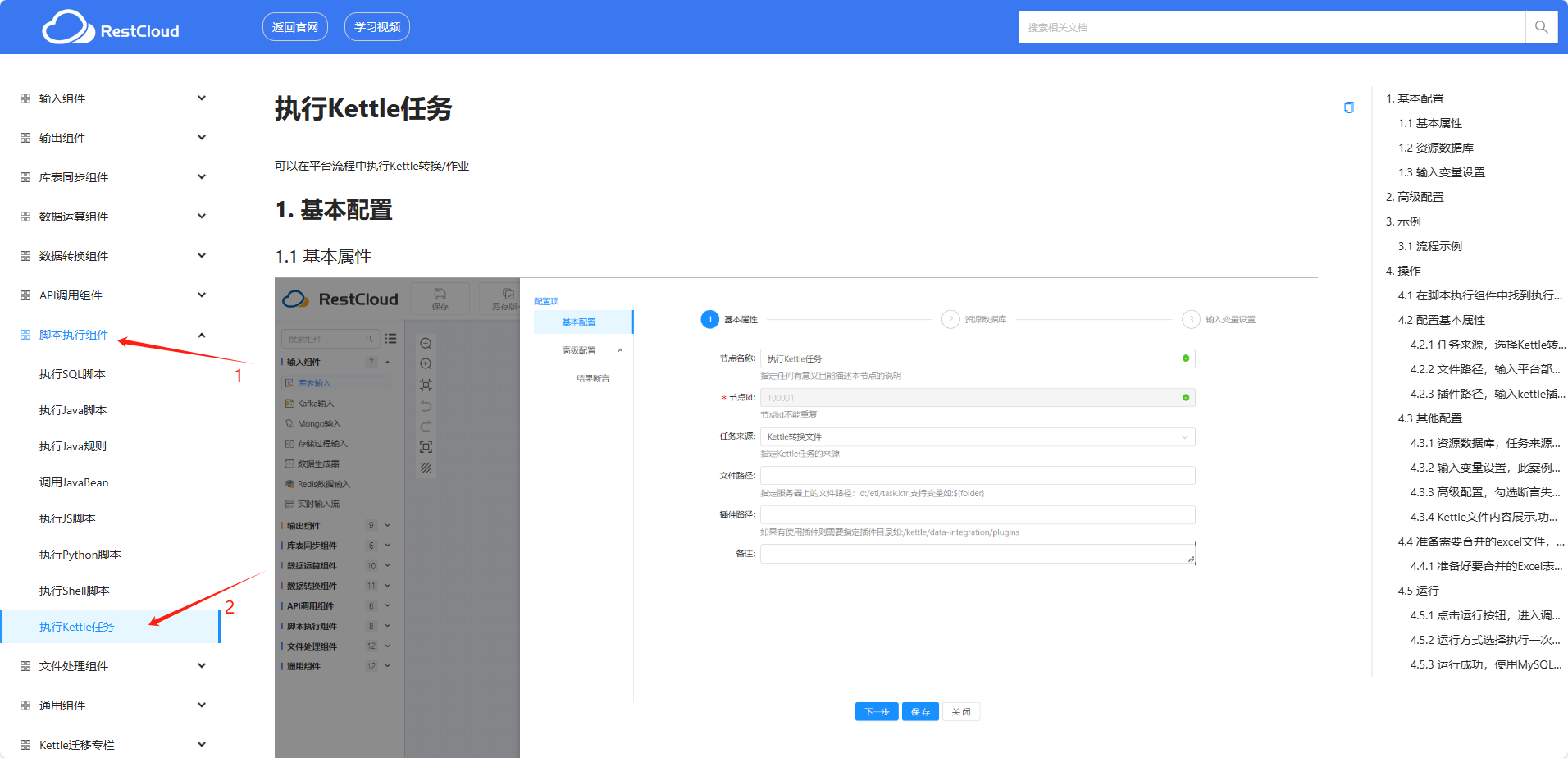
前置知识:图的基本概念
图的存储必须完整、准确地反映顶点集和边集的信息。根据不同图的结构和算法,采用不同的存储方式将对程序的效率产生相当大的影响,因此选取的存储结构应适合于待求解的问题。
图的存储
邻接矩阵法
所谓邻接矩阵存储,是指用一个一维数组存储图中顶点的信息,用一个二维数组存储图中边的信息(即各个顶点之间的邻接关系),存储顶点之间邻接关系的二维数组被称为邻接矩阵。
顶点数为
n
n
n的图
G
=
(
V
,
E
)
G=\left( V,E \right)
G=(V,E)的邻接矩阵
A
A
A 是
n
×
n
n×n
n×n的,将
G
G
G的顶点编号为
v
1
,
v
2
,
⋯
,
v
n
{{v}_{1}},{{v}_{2}},\cdots ,{{v}_{n}}
v1,v2,⋯,vn,则

#define MaxVertexNum 100//顶点数目的最大值
#define INF 0xfffffff//无穷大(不连通的点之间距离为无穷,点到自身距离可为无穷或0)
typedef char VertexType;//顶点对应的数据类型,此处为char,可以用更复杂的结构体类型
typedef int EdgeType;//边对应的数据类型
typedef struct {
VertexType Vex[MaxVertexNum];//顶点表
EdgeType Edge[MaxVertexNum][MaxVertexNum];//邻接矩阵(边表),如果只存放01可以用bool
int vexnum, arcnum;//图当前的顶点数和边数
}MGraph;
简而言之,邻接矩阵就是开一个二维数组存放点与点之间的关系,每一个点的编号作为数组下标。
假设顶点
A
A
A的编号为
0
0
0,顶点
B
B
B的编号为
1
1
1。
在无向图中,若
A
[
i
]
[
j
]
=
=
1
A[i][j]==1
A[i][j]==1,则
A
[
j
]
[
i
]
A[j][i]
A[j][i]也必为
1
1
1,表示顶点A到顶点
B
B
B之间存在一条边,或者说顶点
A
A
A与顶点
B
B
B是连通的。
在有向图中,若
A
[
i
]
[
j
]
=
=
1
A[i][j]==1
A[i][j]==1,则表示顶点A到顶点
B
B
B之间存在一条弧;若
A
[
j
]
[
i
]
=
=
1
A[j][i]==1
A[j][i]==1,则表示顶点B到顶点
A
A
A之间存在一条弧。若
A
[
i
]
[
j
]
=
=
1
&
&
A
[
j
]
[
i
]
=
=
1
A[i][j]==1 \&\& A[j][i]==1
A[i][j]==1&&A[j][i]==1,则顶点
A
A
A与顶点
B
B
B是强连通的。
注意:
①在简单应用中,可直接用二维数组作为图的邻接矩阵(顶点信息等均可省略)。
②当邻接矩阵的元素仅表示相应边是否存在时, E d g e T y p e EdgeType EdgeType(边的数据类型)可以使用 b o o l bool bool布尔类型或值为 0 0 0和 1 1 1的 e n u m enum enum枚举类型。
③无向图的邻接矩阵是对称矩阵,对规模特大的邻接矩阵可采用压缩存储。(特殊矩阵的压缩存储请参考王道系列《2025年数据结构考研复习指导》P105,本人当时偷懒没写这一块的博客)
④邻接矩阵表示法的空间复杂度为 O ( n 2 ) O( {n}^{2} ) O(n2),其中 n n n为图的顶点数 ∣ V ∣ \left | V \right | ∣V∣。
邻接矩阵存储的特点
图的邻接矩阵存储表示法具有以下特点:
- 无向图的邻接矩阵一定是一个对称矩阵(并且唯一)。因此,在实际存储邻接矩阵时只需存储上(或下)三角矩阵的元素。(矩阵的压缩存储)
- 对于无向图,邻接矩阵的第 i i i行(或第 i i i列)非零元素(或非 ∞ \infin ∞元素)的个数正好是顶点 i i i的度 T D ( V i ) TD(V_i) TD(Vi)。
- 对于有向图,邻接矩阵的第 i i i行非零元素(或非 ∞ \infin ∞元素)的个数正好是顶点 i i i的出度 O D ( v i ) OD(v_i) OD(vi);第 i i i列非零元素(或非 ∞ \infin ∞元素)的个数正好是顶点 i i i的入度 I D ( v i ) ID(v_i) ID(vi)。
- 用邻接矩阵存储图,很容易确定图中任意两个顶点之间是否有边相连。但是,要确定图中有多少条边,则必须按行、按列对每个元素进行检测,所花费的时间代价很大。
- 稠密图(即边数较多的图)适合采用邻接矩阵的存储表示。
- 设图
G
G
G的邻接矩阵为
A
A
A,
A
n
A^n
An的元素
A
n
[
i
]
[
j
]
A^n[i][j]
An[i][j]等于由顶点
i
i
i到顶点
j
j
j的长度为
n
n
n的路径的数目。该结论了解即可,证明方法可参考离散数学教材图论部分。(理解需要掌握线性代数矩阵乘法相关知识
,所以赶紧去看考研数学吧!)
邻接表法
邻接矩阵法存储图的缺点是空间复杂度很高,当存储稀疏图时,会浪费大量的存储空间。因此,可以使用顺序存储和链式存储的组合存储方式对稀疏图进行存储,从而减少不必要的空间浪费。这种结合了顺序存储和链式存储的方法就是邻接表法。
知识点回顾:单链表
知识点类比:树的孩子表示法
所谓邻接表,是指对图 G G G中的每个顶点 v i v_i vi建立一个单链表,第 i i i个单链表中的结点表示依附于顶点 v i v_i vi的边(对有向图则是以顶点 v i v_i vi为尾的弧),这个单链表就称为顶点 v i v_i vi的边表(对于有向图则称为出边表)。边表的头指针和顶点的数据信息采用顺序存储,称为顶点表,所以在邻接表中存在两种结点:顶点表结点和边表结点。
typedef struct ArcNode {//边表结点
int adjvex;//该边(弧)所指向的顶点位置(对应单链表的data)
struct ArcNode* nextarc;//指向下一条边(弧)的指针(对应单链表的*next)
//Infotype info;//如果存储的是带权图,则可加入边权值
}ArcNode;
typedef struct VNode {//顶点表结点
VertexType data;//顶点信息
ArcNode* firstarc;//指向第一条依附该顶点的边(弧)的指针
}VNode, AdjList[MaxVertexNum];//一维数组存储各个顶点
顶点表结点由两个域组成:顶点域(
d
a
t
a
data
data)存储顶点
v
i
v_i
vi的相关信息,边表头指针域(
f
i
r
s
t
a
r
c
firstarc
firstarc)指向第一条边的边表结点。边表结点至少由两个域组成:邻接点域(
a
d
j
v
e
x
adjvex
adjvex)存储与头结点顶点
v
i
v_i
vi邻接的顶点编号,指针域(
n
e
x
t
a
r
c
nextarc
nextarc)指向下一条边的边表结点。
(图片来自王道考研408数据结构2025)

图的邻接表存储结构定义如下:
typedef struct {
AdjList vertices;//邻接表
int vexnum, arcnum;//图的顶点数和弧数
}ALGraph;//ALGraph是以邻接表存储的图类型
邻接表存储的特点
图的邻接表存储方法具有以下特点:
- 若 G = ( V , E ) G=\left( V,E \right) G=(V,E)为无向图,则所需的存储空间为 O ( ∣ V ∣ + 2 ∣ E ∣ ) O \left ( \left | V \right | +2\left | E \right | \right ) O(∣V∣+2∣E∣);若 G G G为有向图,则所需的存储空间为 O ( ∣ V ∣ + ∣ E ∣ ) O \left ( \left | V \right | +\left | E \right | \right ) O(∣V∣+∣E∣)。前者的倍数是 2 2 2是因为在无向图中,每条边在邻接表中出现了两次。
- 对于稀疏图(即边数较少的图),采用邻接表表示将极大地节省存储空间。
- 在邻接表中,给定一个顶点,能很容易地找出它的所有邻边,只需读取它的邻接表即可。而在邻接矩阵中,相同的操作需要扫描一整行,时间复杂度为 O ( n ) O \left ( n \right ) O(n)。但是,如果要确定两个顶点之间是否存在边,在邻接矩阵中可以立即查到,而在邻接表中则需要在相应结点对应的边表中查找另一结点,效率较低。
- 在无向图的邻接表中,求某个顶点的度只需计算其邻接表中的边表结点个数。在有向图的邻接表中,求某个顶点的出度也只需计算其邻接表中的边表结点个数;但是求某个顶点
x
x
x的入度则需要遍历所有顶点的邻接表,统计邻接点(
a
d
j
v
e
x
adjvex
adjvex)域为
x
x
x的边表结点的个数
,非常麻烦。 - 图的邻接表并不唯一,因为在每个顶点对应的边表中,各边结点的链接次序可以是任意的,它取决于建立邻接表的算法及边的输入次序。
十字链表
十字链表是有向图的一种链式存储结构。在十字链表中,有向图的每条弧用一个结点(弧结点)来表示,每个顶点也用一个结点(顶点结点)来表示。
弧结点中有
5
5
5个域:
t
a
i
l
v
e
x
tailvex
tailvex和
h
e
a
d
v
e
x
headvex
headvex两个域分别表示指示弧尾和弧头的两个顶点的编号;头链域
h
l
i
n
k
hlink
hlink指向弧头相同的下一个弧结点;尾链域
t
l
i
n
k
tlink
tlink指向弧尾相同的下一个弧结点;
i
n
f
o
info
info域存放该弧的相关信息。这样,弧头相同的弧在同一个链表上,弧尾相同的弧也在同一个链表上。
顶点结点中有
3
3
3个域:
d
a
t
a
data
data域存放该顶点的数据信息,如顶点名称;
f
i
r
s
t
i
n
firstin
firstin域指向以该顶点为弧头的第一个弧结点;
f
i
r
s
t
o
u
t
firstout
firstout域指向以该顶点为弧尾的第一个弧结点。
注意:顶点和顶点之间是顺序存储的。
在十字链表中,既容易找到 V i V_i Vi为尾的弧,也容易找到 V i V_i Vi为头的弧,因而容易求得顶点的出度和入度。
(下图来自王道考研408数据结构课程视频的截图 - 十字链表、邻接多重表)

对上图,这个有向图中,四个顶点按顺序存放在左边的顶点表里,顶点
A
B
C
D
ABCD
ABCD编号依次为
0123
0123
0123,分别存储在顶点结点数据域(蓝色色块)里。下面我将通过分析 顶点
A
A
A 对该图进行解读。
对顶点
A
A
A,以它作为弧尾顶点的弧共有两条,分别是
A
B
AB
AB和
A
C
AC
AC,因此,其
f
i
r
s
t
o
u
t
firstout
firstout指针(绿色色块)指向的弧结点为弧
A
B
AB
AB。下面对表示弧
A
B
AB
AB的弧结点进行分析:
- 弧尾域 t a i l v e x tailvex tailvex(绿色方块)存放的是 0 0 0,表示弧尾顶点为 A A A。
- 弧头域 h e a d v e x headvex headvex(橙色方块)存放的是 1 1 1,表示弧头顶点为 B B B。
- 权值域 i n f o info info(灰色块)置空,因为该有向图是无权图,所以在此可忽略。
- 尾链域
t
l
i
n
k
tlink
tlink(绿色长条块)指向的是下一个和自己弧尾域
t
a
i
l
v
e
x
tailvex
tailvex相同的弧结点,即存放弧
A
C
AC
AC的弧结点。因为之后没有了以顶点
A
A
A作为弧尾的弧,所以弧结点
A
C
AC
AC的尾链域
t
l
i
n
k
tlink
tlink指向
N
U
L
L
NULL
NULL(图中用
^表示)。 - 头链域
h
l
i
n
k
hlink
hlink(橙色长条块)指向的是下一个和自己弧头域
h
e
a
d
v
e
x
headvex
headvex相同的弧结点,即存放弧
D
B
DB
DB的弧结点。因为之后没有了以顶点
B
B
B作为弧头的弧,所以弧结点
D
B
DB
DB的头链域
h
l
i
n
k
hlink
hlink指向
N
U
L
L
NULL
NULL(图中用
^表示)。
对顶点 A A A,以它作为弧头顶点的弧共有两条,分别是 C A CA CA和 D A DA DA,因此,其 f i r s t i n firstin firstin指针(橙色色块)指向的弧结点为弧 C A CA CA。下面对表示弧 C A CA CA的弧结点进行分析:
- 弧尾域 t a i l v e x tailvex tailvex(绿色方块)存放的是 2 2 2,表示弧尾顶点为 C C C。
- 弧头域 h e a d v e x headvex headvex(橙色方块)存放的是 0 0 0,表示弧头顶点为 A A A。
- 权值域 i n f o info info(灰色块)置空,因为该有向图是无权图,所以在此可忽略。
- 尾链域
t
l
i
n
k
tlink
tlink(绿色长条块)指向的是下一个和自己弧尾域
t
a
i
l
v
e
x
tailvex
tailvex相同的弧结点,即存放弧
C
D
CD
CD的弧结点。因为之后没有了以顶点
C
C
C作为弧尾的弧,所以弧结点
C
D
CD
CD的尾链域
t
l
i
n
k
tlink
tlink指向
N
U
L
L
NULL
NULL(图中用
^表示)。 - 头链域
h
l
i
n
k
hlink
hlink(橙色长条块)指向的是下一个和自己弧头域
h
e
a
d
v
e
x
headvex
headvex相同的弧结点,即存放弧
D
A
DA
DA的弧结点。因为之后没有了以顶点
A
A
A作为弧头的弧,所以弧结点
D
A
DA
DA的头链域
h
l
i
n
k
hlink
hlink指向
N
U
L
L
NULL
NULL(图中用
^表示)。
对于其他的顶点结点和弧结点均可采用如上方式分析,顺着思路来看,这幅截图就变得非常简洁易懂。
十字链表法的空间复杂度为
O
(
∣
V
∣
+
∣
E
∣
)
O \left ( \left | V \right | +\left | E \right | \right )
O(∣V∣+∣E∣)。
对一个给定顶点,要想找到其所有出边,只需顺着绿色线路一路找下去即可;要想找到其所有入边,只需顺着橙色线路一路找下去即可。
有向图的十字链表是不唯一的,但是一个十字链表唯一确定一张有向图。
注意:十字链表只用于存储
有向图。
我自己试着写了一个有向图的十字链表存储结构定义实现,不知道对不对,如有问题还请指出:
typedef struct Arc_Node {//弧结点
int tailvex, headvex;//弧尾,弧头编号域
struct Arc_Node* tlink, * hlink;//尾链域,头链域
//InfoType info;//权值域
}Arc_Node;
typedef struct V_Node {//顶点结点
Arc_Node* firstin, * firstout;
//分别指向以该顶点为弧头/弧尾的第一个弧结点
VertexType data;//顶点数据域
}V_Node, Adj_List[MaxVertexNum];
typedef struct {
Adj_List vertices;//邻接表
int vexnum, arcnum;//图的顶点数和弧数
}CRGraph;//CRGraph是以十字(Cross)链表存储的有向图类型
邻接多重表
邻接多重表是无向图的一种链式存储结构。在邻接表中,容易求得顶点和边的各种信息,但在邻接表中求两个顶点之间是否存在边而对边执行删除等操作时,由于每条边对应两份冗余信息,需要分别在两个顶点的边表中遍历,效率较低。为解决这个问题,可以采用邻接多重表的方式存储无向图。
与十字链表类似,在邻接多重表中,每条边用一个结点表示,每个顶点也用一个顶点表示。
边结点中有
5
5
5个域:
i
v
e
x
ivex
ivex和
j
v
e
x
jvex
jvex这两个域指示该边依附的两个顶点的编号;
i
l
i
n
k
ilink
ilink域指向下一条依附于顶点
i
v
e
x
ivex
ivex的边;
j
l
i
n
k
jlink
jlink域指向下一条依附于顶点
j
v
e
x
jvex
jvex的边;
i
n
f
o
info
info域存放该边的相关信息。
顶点结点中有
2
2
2个域:
d
a
t
a
data
data域存放该顶点的相关信息;
f
i
r
s
t
e
d
g
e
firstedge
firstedge域指向第一条依附于该顶点的边。
(下图来自王道考研408数据结构课程视频的截图 - 十字链表、邻接多重表)

看懂了十字链表后,邻接多重表也可以按照类似思路进行分析理解,这里就不再赘述,留给读者自己思考。(我已经看懂了,你呢)
下面再讲讲邻接多重表删除操作。
边的删除:例如边
A
B
AB
AB,要删除它的话,首先找到边结点
A
B
AB
AB。由顶点表可知,顶点
A
A
A和顶点
B
B
B的
f
i
r
s
t
e
d
g
e
firstedge
firstedge域都指向它。再对表示边
A
B
AB
AB的边结点进行分析,有——
- i v e x ivex ivex域(橙色方块)值为 0 0 0,指向顶点 A A A。
- j v e x jvex jvex域(绿色方块)值为 1 1 1,指向顶点 B B B。
- i n f o info info域(灰色方块)置空,因为是无权图。
- i l i n k ilink ilink域(橙色长条块)指向下一条依附于顶点 i v e x ivex ivex(即顶点 A A A)的边,由图可知其指向边结点 A D AD AD,由于之后没有再依附于顶点 A A A的边,故边结点 A D AD AD的 i l i n k ilink ilink域指向 N U L L NULL NULL。
- j l i n k jlink jlink域(橙色长条块)指向下一条依附于顶点 j v e x jvex jvex(即顶点 B B B)的边,由图可知其指向边结点 B C BC BC,而边结点 B C BC BC的 j l i n k jlink jlink域又指向边结点 E B EB EB,由于之后没有再依附于顶点 B B B的边,故边结点 E B EB EB的 j l i n k jlink jlink域指向 N U L L NULL NULL。
由分析,我们可以得到,对边结点 A B AB AB,顶点 A A A和顶点 B B B的 f i r s t e d g e firstedge firstedge域都指向它,而它的 i l i n k ilink ilink域指向边结点 A D AD AD, j l i n k jlink jlink域指向边结点 B C BC BC。因此,只需将顶点 A A A的 f i r s t e d g e firstedge firstedge域改为指向它的 i l i n k ilink ilink域(即指向边结点 A D AD AD),将顶点 B B B的 f i r s t e d g e firstedge firstedge域改为指向它的 j l i n k jlink jlink域(即指向边结点 B C BC BC),再 f r e e free free掉边结点 A B AB AB,即可完成对边 A B AB AB的删除。
顶点的删除:删除顶点比删除边略微复杂一点,除了要删除这个顶点,还需要删除和这个顶点相关的所有边。以顶点
E
E
E为例,依附于它的边有两条,分别是
E
B
EB
EB,
C
E
CE
CE。逐个对其进行分析。
首先看边结点
E
B
EB
EB,由于边结点
C
B
CB
CB的
j
l
i
n
k
jlink
jlink域指向它,并且没有边结点的
i
l
i
n
k
ilink
ilink域指向它,所以删除时,将边结点
E
B
EB
EB的
j
l
i
n
k
jlink
jlink域传递给边结点
C
B
CB
CB的
j
l
i
n
k
jlink
jlink域后,再
f
r
e
e
free
free掉边结点
E
B
EB
EB,即可完成删除操作。因为边结点
E
B
EB
EB的
j
l
i
n
k
jlink
jlink域指向
N
U
L
L
NULL
NULL,所以删除边
E
B
EB
EB后,边结点
C
B
CB
CB的
j
l
i
n
k
jlink
jlink域也就指向
N
U
L
L
NULL
NULL。
再看边结点
C
E
CE
CE,边结点
E
B
EB
EB的
i
l
i
n
k
ilink
ilink域指向它,但是边
E
B
EB
EB已经被删除,所以无需考虑;而边结点
C
D
CD
CD的
i
l
i
n
k
ilink
ilink域也指向它,并且没有边结点的
j
l
i
n
k
jlink
jlink域指向它,所以删除时,将边结点
C
E
CE
CE的
i
l
i
n
k
ilink
ilink域传递给边结点
C
D
CD
CD的
i
l
i
n
k
ilink
ilink域后,再
f
r
e
e
free
free掉边结点
C
E
CE
CE,即可完成删除操作。因为边结点
C
E
CE
CE的
i
l
i
n
k
ilink
ilink域指向
N
U
L
L
NULL
NULL,所以删除边
C
E
CE
CE后,边结点
C
D
CD
CD的
i
l
i
n
k
ilink
ilink域也就指向
N
U
L
L
NULL
NULL。
最后再到顶点表中删除顶点
E
E
E即可。
使用邻接多重表存储无向图的空间复杂度是
O
(
∣
V
∣
+
∣
E
∣
)
O \left ( \left | V \right | +\left | E \right | \right )
O(∣V∣+∣E∣),比邻接表还要好,因为其中没有冗余的边的信息。此外,邻接多重表删除边、删除结点等操作也很方便。
当然,无向图的邻接多重表是不唯一的,但是一个邻接多重表唯一确定一张无向图。
注意:邻接多重表只用于存储
无向图。
同样的,我也试着写了一个无向图的邻接多重表存储结构定义实现,不知道对不对,如有问题还请指出:
typedef struct Arc__Node {//边结点
int ivex, jvex;//边依附的两个顶点
struct Arc__Node* ilink, * jlink;//依附同一i/j顶点的链域
//InfoType info;//权值域
}Arc__Node;
typedef struct V__Node {//顶点结点
Arc__Node* firstedge;//与该顶点相连的第一条边
VertexType data;//顶点数据域
}V__Node, Adj__List[MaxVertexNum];
typedef struct {
Adj__List vertices;//邻接多重表
int vexnum, arcnum;//图的顶点数和弧数
}MutiGraph;//MutiGraph是以邻接多重表存储的无向图类型
完整代码可以看我的Github:传送门
图的基本操作
图的基本操作是独立于图的存储结构的,对于不同的存储方式,操作算法的具体实现会有着不同的性能。由于408考研初试中,最常考的还是邻接矩阵和邻接表,因此之后的探讨都是基于这两种存储结构对图进行基本操作的实现。
-
A d j a c e n t ( G , x , y ) Adjacent(G,x,y) Adjacent(G,x,y):判断图 G G G是否存在弧 < x , y > <x,y> <x,y>或边 ( x , y ) (x,y) (x,y)。
对邻接矩阵,实现该操作只需判断
E
d
g
e
[
x
]
[
y
]
Edge[x][y]
Edge[x][y]值是否为
1
1
1,时间复杂度为
O
(
1
)
O(1)
O(1)。
对邻接表,实现该操作需要判断
x
x
x的邻接边表中是否有
y
y
y,最坏时间复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣)。
对邻接矩阵,实现该操作需统计表示
x
x
x的行(有向图中的入边)或列(有向图中的出边)中所有值为
1
1
1的元素,时间复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣)。
对邻接表,实现该操作只需遍历
x
x
x的邻接边表(有向图中的出边),最坏时间复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣)。但是,如果需要在有向图中寻找顶点
x
x
x的入边,则需要遍历整个顶点表所有的邻接边表,时间复杂度为
O
(
∣
E
∣
)
O(|E|)
O(∣E∣)。当然,如果存储的是稀疏图,这样的时间复杂度也可以接受。
对邻接矩阵,实现该操作,只需在保存现有顶点的数组最后空白的位置写入新结点的数据即可,由于邻接矩阵初始化时已经默认置零,因此唯一的时间开销就是在顶点表中插入新结点,时间复杂度为
O
(
1
)
O(1)
O(1)。
对邻接表,实现该操作,只需在顶点表的末尾插入新结点即可,由于初始时新结点未连任何边,所以其
f
i
r
s
t
a
r
c
firstarc
firstarc域指向
N
U
L
L
NULL
NULL,时间复杂度为
O
(
1
)
O(1)
O(1)。
对邻接矩阵,删除一个顶点时需要把与之相连的边一并删除。若采取在邻接矩阵内删除表示顶点
x
x
x的行和列,并将剩余的数据拼接在一起的这种方法,需要移动大量数据,显然是不合算的。因此,可以在顶点的结构体中新增一个
b
o
o
l
bool
bool型变量,用于表示当前顶点是否为空顶点。删除时,只需将顶点
x
x
x的
b
o
o
l
bool
bool值置零,同时把邻接矩阵中表示顶点
x
x
x的行和列也全部置零,时间复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣)。
对邻接表,删除一个顶点时同样需要把与之相连的边一并删除。除了在顶点表中删除
x
x
x,以及删除顶点
x
x
x所连的邻接边表,还需要在其他与之相连的顶点的边表中,找到指向顶点
x
x
x的边结点,并将其删除,最坏时间复杂度为
O
(
∣
E
∣
)
O(|E|)
O(∣E∣)。对有向图,删出边的时间复杂度是
O
(
1
)
O(1)
O(1)到
O
(
∣
V
∣
)
O(|V|)
O(∣V∣),删入边的时间复杂度则是
O
(
∣
E
∣
)
O(|E|)
O(∣E∣)。
-
A d d E d g e ( G , x , y ) AddEdge(G,x,y) AddEdge(G,x,y):若边 ( x , y ) (x,y) (x,y)或弧 < x , y > <x,y> <x,y>不存在,则向图 G G G中添加该边(弧)。
对邻接矩阵,只需判断只需判断
E
d
g
e
[
x
]
[
y
]
Edge[x][y]
Edge[x][y]值是否为
1
1
1,若为
0
0
0则改为
1
1
1即可完成边的添加(无向图还需同时将
E
d
g
e
[
y
]
[
x
]
Edge[y][x]
Edge[y][x]的值置
1
1
1),时间复杂度为
O
(
1
)
O(1)
O(1)。
对邻接表,需要遍历顶点
x
x
x的邻接边表,判断该边是否存在。如果不存在,则可采用尾插法或头插法,在顶点
x
x
x和顶点
y
y
y的邻接边表中分别插入
y
y
y和
x
x
x,头插法的时间复杂度为
O
(
1
)
O(1)
O(1)。对有向图也是类似的,最坏时间复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣)。
-
R e m o v e E d g e ( G , x , y ) RemoveEdge(G,x,y) RemoveEdge(G,x,y):若边 ( x , y ) (x,y) (x,y)或弧 < x , y > <x,y> <x,y>存在,则从图 G G G中删除该边(弧)。
删除操作与插入操作类似。(王道视频里漏讲了这一小段)
对邻接矩阵,只需判断只需判断
E
d
g
e
[
x
]
[
y
]
Edge[x][y]
Edge[x][y]值是否为
1
1
1,若为
1
1
1则改为
0
0
0即可完成边的删除(无向图还需同时将
E
d
g
e
[
y
]
[
x
]
Edge[y][x]
Edge[y][x]的值置零),时间复杂度为
O
(
1
)
O(1)
O(1)。
对邻接表,需要遍历顶点
x
x
x的邻接边表,判断该边是否存在。如果存在,则需要在顶点
x
x
x和顶点
y
y
y的邻接边表中分别删除对应边结点,最坏时间复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣),有向图中也是类似的。
-
F i r s t N e i g h b o r ( G , x ) FirstNeighbor(G,x) FirstNeighbor(G,x):求图 G G G中顶点 x x x的第一个邻接点,若有则返回顶点号。若 x x x没有邻接点或图中不存在 x x x,则返回 − 1 -1 −1。
对邻接矩阵,只需扫描与顶点
x
x
x对应的这一行,按顺序找到第一次出现
1
1
1的位置并返回,如果扫描结束都没找到则返回
−
1
-1
−1,最坏时间复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣)。如果是在有向图中找入边的第一个邻接点,则按顺序扫描与顶点
x
x
x对应的列,同样最坏时间复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣)。
对邻接表则非常简单,只需找到顶点
x
x
x的邻接边表的第一个元素,如果没有则返回
−
1
-1
−1,时间复杂度为
O
(
1
)
O(1)
O(1)。有向图的出边同样简单,但是找有向图中入边的第一个邻接点则会非常麻烦,需要遍历整个邻接边表,最坏时间复杂度为
O
(
∣
E
∣
)
O(|E|)
O(∣E∣)。当然,一般情况下都是找出边。
-
N e x t N e i g h b o r ( G , x , y ) NextNeighbor(G,x,y) NextNeighbor(G,x,y):假设图 G G G中顶点 y y y是顶点 x x x的一个邻接点,返回除 y y y之外的顶点 x x x的下一个邻接点的顶点号,若 y y y是 x x x的最后一个邻接点,则返回 − 1 -1 −1。
对邻接矩阵,只需在表示顶点
x
x
x的行或列中从
y
y
y的位置开始继续往后扫描,直到找到第一个
1
1
1出现的位置,或者扫描完整行(列)都没有找到
1
1
1而返回
−
1
-1
−1,最坏时间复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣)。
对邻接表,只需在顶点
x
x
x的邻接边表中找到
y
y
y的位置,因为是已知的,所以直接读取
y
y
y的
n
e
x
t
a
r
c
nextarc
nextarc域信息即可,若有点则返回其编号值,若为
N
U
L
L
NULL
NULL则返回
−
1
-1
−1,时间复杂度为
O
(
1
)
O(1)
O(1)。
-
G e t _ e d g e _ v a l u e ( G , x , y ) Get \_ edge \_ value(G,x,y) Get_edge_value(G,x,y):获取图 G G G中边 ( x , y ) (x,y) (x,y)或弧 < x , y > <x,y> <x,y>对应的权值。
-
S e t _ e d g e _ v a l u e ( G , x , y , v ) Set \_ edge \_ value(G,x,y,v) Set_edge_value(G,x,y,v):设置图 G G G中边 ( x , y ) (x,y) (x,y)或弧 < x , y > <x,y> <x,y>对应的权值为 v v v。
这两个基本操作的时间开销也是在于找边(弧),与 A d j a c e n t ( G , x , y ) Adjacent(G,x,y) Adjacent(G,x,y)类似,且时间开销相同,因此不再赘述。
感兴趣的读者可以试着分析用十字链表和邻接多重表又要如何实现这些基本操作。
此外,图还有遍历算法(按照某种方式访问图中每个顶点,且仅访问一次),包括 深度优先搜索(
D
F
S
DFS
DFS) 和 广度优先搜索(
B
F
S
BFS
BFS) ,这些留在之后的篇章中再介绍。
408考研初试中,对
F
i
r
s
t
N
e
i
g
h
b
o
r
(
G
,
x
)
FirstNeighbor(G,x)
FirstNeighbor(G,x)和
N
e
x
t
N
e
i
g
h
b
o
r
(
G
,
x
,
y
)
NextNeighbor(G,x,y)
NextNeighbor(G,x,y)这两个基本操作,在图的遍历算法中会经常用到,因此需重点掌握,可以自己尝试写一写代码实现。当然,考试时可以直接调用这两个函数接口。
附:【模板题】洛谷B3643 图的存储 解题报告
最近期末考试比较多,需要分配大量时间应付,加上现在图的内容难度很大,所以我的博客更新频率可能会暂时放缓。
由于图的代码实现比较复杂,考研初试中涉及的应该不多,当然如果想要高分还是需要掌握的。
以上。