文章目录
- 延迟加载
- 概述
- 步骤
- 缓存
- 一级缓存
- 介绍
- 原理
- 二级缓存
- 介绍
- 设置缓存对象策略
- 原理
- 开启步骤
- 属性解释
- 是否使用一级缓存
- 分页插件
- 使用步骤
- 逆向工程
- 介绍
- 搭建
- 使用
- 增
- 删
- 修改
- 查
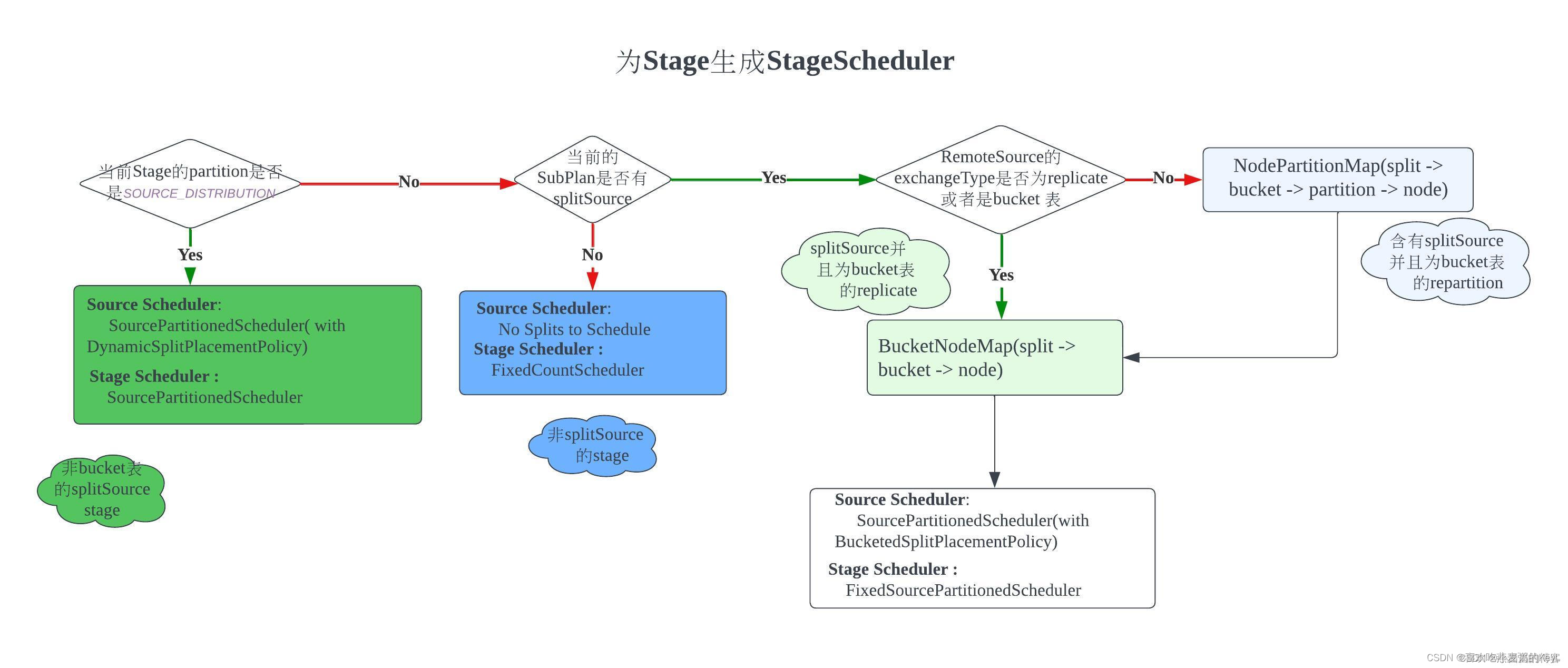
延迟加载
概述
延迟加载本身是依赖于多表查询的
- 延迟加载中返回值要选择resultMap
- 返回的结果一定是Dto
延迟加载也可以成为按需加载;默认是没有开启的
步骤
- 在config.xml中配置下面代码
<!-- lazyLoadingEnabled:延迟加载全局开关,开启后所有关联对象
都会延迟加载;默认是false
aggressiveLazyLoading:按需加载;
开启时,任一方法的调用都会加载该对象的所有延迟加载属性,因此设置为false;
设置为false表示的意思就是按需加载;mybatis版本3.4以上默认是false
-->
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
使用的时候需要将lazyLoadingEnabled设置为true,将aggressiveLazyLoading设置为false
- 在mapper.xml中书写下面代码
<!-- 一对多 -->
<select id="selectOrderAndDetails" resultMap="map1" >
select * from b_order
</select>
<resultMap type="BOrderDto" id="map1" extends="BaseMap">
<!-- 延迟加载和多表查询(高级映射)的区别:
在标签(collection或者association)中,添加column属性和select属性;
select属性中:里面的内容写的是:namespace.sqlID;
表示的是:用来封装当前collection或者association的返回结果
也就是select属性值中的sqlid查询出来的应该是和ofType同等类型;
column属性指的是:第一步查询结果中的列名——》用作参数传入到select调用的sqlId中;
-->
<collection property="details" ofType="BOrderDetailDto" column="id" select="selectDetails">
</collection>
</resultMap>
<!-- 按需加载,如果还需要查看订单详情信息,则调用该方法: -->
<select id="selectDetails" resultMap="map2">
select id detail_id, goods_id, main_id, price, num
from b_order_detail where main_id = #{id}
</select>
<resultMap type="BOrderDetailDto" id="map2">
<id column="detail_id" property="id"></id>
<result column="goods_id" property="goodsId"/>
<result column="main_id" property="mainId"/>
<result column="price" property="price"/>
<result column="num" property="num"/>
</resultMap>
缓存
mybatis为减轻数据库压力,提高数据库性能。提供了两级缓存机制:
mybatis框架中包含了一级缓存和二级缓存
一级缓存
介绍
框架中默认开启了一级缓存,一级缓存是sqlSession级别的缓存,缓存的数据只在SqlSession内有效
原理
- 第一次查询用户id为1的用户信息,先去缓存中查询是否有id为1的用户信息,如果没有,从数据库中查询用户信息。得到用户信息后,再将用户信息存储到一级缓存中
- 如果sqlSession去执行commit操作(插入,更新,删除),就会清空sqlSession中的一级缓存,保证缓存中始终保存的是最新的信息,避免脏读
- 第二次查询用户id为1的信息,先去缓存中查询是否有id为1的用户信息,如果缓存中有,则直接从缓存中获取
- 注:两次查询须在同一个sqlSession中完成,否则将不会走mybatis的一级缓存。在mybatis与spring进行整合开发时,事务控制在service中进行,重复调用俩次service将不会走一级缓存,因为在第一次调用时session方法结束,SqlSession就关闭了
注意事项:
- 一个SqlSession结束后那么它里面的一级缓存也就不存在了
- mybatis的缓存是基于[namespace:sql:参数]来进行缓存的,意思就是,SqlSession的HashMap存储缓存数据时,是使用[namespace:sql:参数]作为key,查询返回的语句作为value保存的
二级缓存
介绍
- mapper级别的缓存,同一个namespace公用这一个缓存,所以对SqlSession是共享的,多个sqlSession去操作同一个Mapper的sql语句,多个sqlSession可以共用二级缓存,二级缓存是跨SqlSession的
- 二级缓存需要我们手动开启
- 作用域为namespace是指对该namespace对应的配置文件中所有的select操作结果都缓存,这样不同线程之间就可以共用二级缓存
设置缓存对象策略
- readOnly=“true”(只读):Mybatis认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。Mybatis为了加快获取数据,直接就会将数据在缓存中的引用交给用户。不安全,速度快
- readOnly=“false”(读写,默认):Myabtis觉得获取的数据可能会被修改,Mybatis会利用序列化或反序列化的技术克隆一份新的数据。安全,速度相对慢
原理
- 当一个sqlSession执行了一次select后,并关闭此session的时候,就会将查询结果存储到二级缓存中
- 当另一个sqlSession执行相同select时,首先会查询二级缓存,二级缓存中无对应数据,再去查询一级缓存,一级缓存中也没有,最后去数据库查找,从而减少了数据库压力提高了性能
注意事项:
- 原理和一级缓存原理一样
- 开启了二级缓存后,还需要将要缓存的pojo实现Serializable接口,为了将缓存数据取出执行反序列化操作
开启步骤
- 在mybatis-config.xml中添加下列代码
<setting name="cacheEnabled" value="true"/>
- 在xxxMapper.xml文件中添加
<cache eviction="FIFO" flushInterval="60000" readOnly="false" size="1024"/>
- 对返回的结果对应的实体类进行序列化:implements Serializable
- 执行的时候对SqlSession进行关闭
属性解释
- eviction:缓存的回收策略,默认是LRU
- LRU:最近最少使用,移除最长时间不被使用的对象
- FIFO:先进先出,按对象进入缓存的顺序来移除它们
- SOFT:软引用,移除基于垃圾回收器状态和软引用规则的对象
- WEAK:弱引用,更积极地移除基于垃圾收集器和弱引用规则的对象
- flushInterval:缓存刷新间隔。缓存多长时间清空一次,默认不清空,设置一个毫秒值
- readOnly:是否只读
- true:只读
- false:读写,默认
- size:缓存存放多少个元素
- type:指定自定义缓存的全类名(实现Cache接口即可)
是否使用一级缓存
如果一条语句每次都需要最新的数据,就意味着每次都需要从数据库中查询数据,可以把这个属性设置为false,如
<select id="selectUserById" resultMap="map" useCache="false">
二级缓存默认会在insert,update,delete操作后刷新缓存,但可以手动配置不更新缓存
<update id="updateUserById" parameterType="User" flushCache="false">
分页插件
pageHelper
官网:https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/zh/HowToUse.md
使用步骤
- 在pom.xml中添加如下依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>最新版本</version>
</dependency>
- 配置拦截器插件(在config.xml中)
<!--
plugins在配置文件中的位置必须符合要求,否则会报错,顺序如下:
properties?, settings?,
typeAliases?, typeHandlers?,
objectFactory?,objectWrapperFactory?,
plugins?,
environments?, databaseIdProvider?, mappers?
-->
<plugins>
<!-- com.github.pagehelper为PageHelper类所在包名 -->
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<!-- 使用下面的方式配置参数,后面会有所有的参数介绍 -->
<property name="param1" value="value1"/>
</plugin>
</plugins>
- 书写代码
方式1:
//获取第1页,10条内容,默认查询总数count
PageHelper.startPage(1, 10);
List<User> list = userMapper.selectAll();
//用PageInfo对结果进行包装
PageInfo page = new PageInfo(list);
//测试PageInfo全部属性
//PageInfo包含了非常全面的分页属性
assertEquals(1, page.getPageNum()); // 当前页
assertEquals(10, page.getPageSize()); //每页显示条数
assertEquals(1, page.getStartRow());
assertEquals(10, page.getEndRow());
assertEquals(183, page.getTotal()); //总条数
assertEquals(19, page.getPages()); //总页数
assertEquals(1, page.getFirstPage());
assertEquals(8, page.getLastPage());
assertEquals(true, page.isFirstPage());
assertEquals(false, page.isLastPage());
assertEquals(false, page.isHasPreviousPage()); //是否有前一页
assertEquals(true, page.isHasNextPage());
方式2:
//对应的lambda用法
pageInfo = PageHelper.startPage(1, 10).doSelectPageInfo(() -> userMapper.selectGroupBy());
逆向工程
介绍
正向工程操作:项目->需求分析->创建uml类图->创建实体类->表
逆向工程:表->创建实体类
搭建
- 逆向工程通常创建java项目,导入逆向工程所需要的maven插件
<build>
<!--可配置多个插件-->
<plugins>
<!--其中的⼀个插件:mybatis逆向⼯程插件-->
<plugin>
<!--插件的GAV坐标-->
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.4.2</version>
<!--允许覆盖-->
<configuration>
<overwrite>true</overwrite>
</configuration>
<!--插件的依赖-->
<dependencies>
<!--mysql驱动依赖-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
- 在resources下创建文件名为generatorConfig.xml(文件名必须是这个)
- xml
<!DOCTYPE generatorConfiguration PUBLIC
"-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!--
targetRuntime有两个值:
MyBatis3Simple:⽣成的是基础版,只有基本的增删改查。
MyBatis3:⽣成的是增强版,除了基本的增删改查之外还有复杂的增删改查。
context:一个配置文件中可以有多个context标签;
id:表示唯一标识;
defaultModelType:
conditional:正常生成一个实体类,如果实体类中只有一个主键字段,不会生成实体类;
flat:会为每张表生成一个实体类,实体类中包含表中所有字段;
hierarchical:
如果表中存在主键则生成主键类;
表中非主键列并且非Blob类型的列,会生成一个类,该类继承主键类
如果存在Blob类型的列,则为该类型的列生成专门的类,该类继承非主键类;
targetRuntime:目标运行环境:
-->
<context id="DB2Tables" targetRuntime="MyBatis3">
<!--防⽌⽣成重复代码-->
<plugin type="org.mybatis.generator.plugins.UnmergeableXmlMappersPlugin"/>
<commentGenerator>
<!--是否去掉⽣成⽇期-->
<property name="suppressDate" value="true"/>
<!--是否去除注释-->
<property name="suppressAllComments" value="true"/>
</commentGenerator>
<!--连接数据库信息-->
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/db11?nullCatalogMeansCurrent=true"
userId="root"
password="123456">
</jdbcConnection>
<!-- ⽣成pojo包名和位置 -->
<javaModelGenerator targetPackage="cn.ry.pojo" targetProject="src/main/java">
<!--是否开启⼦包-->
<property name="enableSubPackages" value="true"/>
<!--是否去除字段名的前后空⽩-->
<property name="trimStrings" value="true"/>
</javaModelGenerator>
<!-- ⽣成SQL映射⽂件的包名和位置 -->
<sqlMapGenerator targetPackage="cn.ry.mapper" targetProject="src/main/resources">
<!--是否开启⼦包-->
<property name="enableSubPackages" value="true"/>
</sqlMapGenerator>
<!-- ⽣成Mapper接⼝的包名和位置 -->
<javaClientGenerator
type="xmlMapper"
targetPackage="cn.ry.mapper"
targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
</javaClientGenerator>
<!-- 表名和对应的实体类名-->
<table tableName="tb_item" domainObjectName="Item"/>
</context>
</generatorConfiguration>
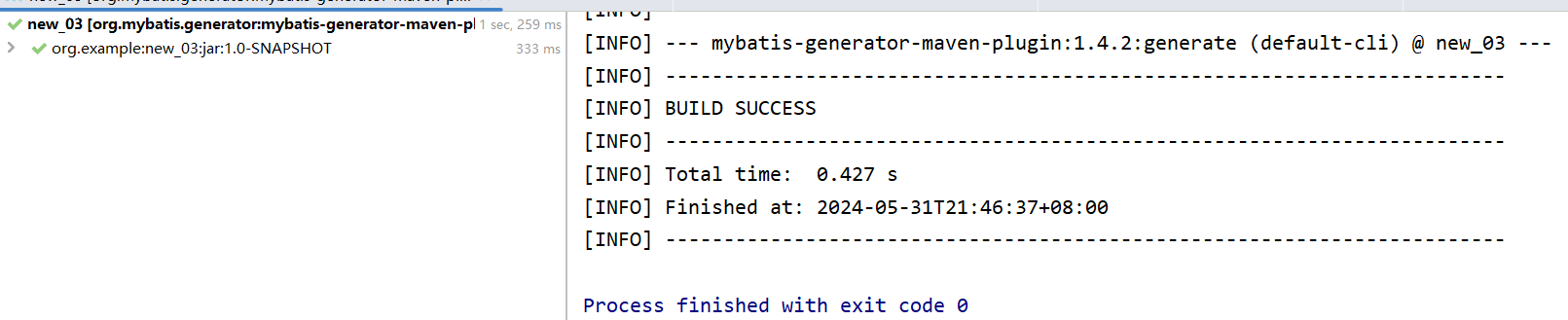
- 执行

- 出现BUID SUCCESS就是创建成功
使用
增
| 方法名 | 含义 |
|---|---|
| insert(obj) | 新增 |
| insertSelective(obj) | 新增 |
区别:如果表中某列设置了默认值,新增语句中,刚好没给这一列赋值,此时前者赋值为null,后者赋值为默认值
删
| 方法名 | 含义 |
|---|---|
| deleteByPrimaryKey(key) | 根据主键id进行删除 |
| deleteByExample(example) | 自定义条件删除 |
修改
| 方法名 | 含义 |
|---|---|
| updateByPrimaryKeySelective(obj) | 根据id进行修改,只更新不为空的数据;如果某列不想修改,直接不写,不会修改原来的值 |
| updateByPrimaryKey(obj) | 根据id进行修改 |
| updateByExampleSelective(obj,example) | 根据自定义条件进行修改 |
| updateByExample(obj,example) | 根据自定义条件进行修改,如果没有设置id会报错 |
查
| 方法名 | 含义 |
|---|---|
| selectByPrimaryKey(key) | 根据主键去查询 |
| countByExample(example) | 根据自定义条件查询数量 |
| selectByExample(example) | 根据自定义条件查询 |
example的代码使用如下:
SqlSession s = SqlSessionUtil.getSqlSession();
BOrderMapper mapper = s.getMapper(BOrderMapper.class);
BOrderExample example =new BOrderExample();
//创建条件对象;
Criteria c = example.createCriteria();
//使用条件对象中的方法:
c.andOrderNoLike("%02%");
c.andTotalGreaterThan(1);
创建条件对象2;
Criteria c1 = example.createCriteria();
c1.andIdIsNotNull();
example.or(c1);
List<BOrder> list = mapper.selectByExample(example);
System.out.println(list.size());
![[ROS 系列学习教程] 建模与仿真 - Xacro 语法](https://img-blog.csdnimg.cn/direct/f791657725cd4af4b933f5a8436dd3fb.png#pic_center)