引言
- 简介:使用pytorch框架,从模型训练、模型部署完整地实现了一个基础的图像识别项目
- 计算资源:使用的是Kaggle(每周免费30h的GPU)
1.创建名为“utils_1”的模块
模块中包含:训练和验证的加载器函数、训练函数、验证函数
import os
import sys
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from tqdm import tqdm
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def get_train_loader(image_path):
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform = train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=32,
shuffle=True, num_workers= 0)
return train_loader
def get_val_loader(image_path):
val_transform = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
val_dataset = datasets.ImageFolder(root=os.path.join(image_path, "validation"),
transform = val_transform)
val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=32,
shuffle = False, num_workers = 0)
return val_loader
def train(train_loader,net):
net.train()
train_correct = 0.0
train_loss = 0.0 # 初始化训练损失
train_bar = tqdm(train_loader, file=sys.stdout)
loss_function = nn.CrossEntropyLoss()
loss_function = loss_function.to(device)
optimizer = optim.Adam(net.parameters(), lr=0.001)
for step, data in enumerate(train_bar):
images, labels = data
images, labels = images.to(device),labels.to(device)
# 梯度清零
optimizer.zero_grad()
# 训练
outputs = net(images)
# 计算损失
loss = loss_function(outputs, labels)
# 反向传播
loss.backward()
# 更新权重
optimizer.step()
# 统计
_, preds = outputs.max(1)
correct = preds.eq(labels).sum()
train_correct += correct
train_loss += loss.item() # 累加损失值
train_bar.desc = 'Training Epoch:[{trained_samples}/{total_samples}]\t Loss: {:0.4f}\t Accuracy: {:0.4f}\t'.format(
loss.item(),
(100. * correct) / len(outputs),
trained_samples=step * train_loader.batch_size + len(images),
total_samples=len(train_loader.dataset))
train_correct = (100. * train_correct) / len(train_loader.dataset)
train_loss /= len(train_loader) # 计算平均损失值
return train_correct, train_loss # 返回训练正确率和平均损失值
def val(val_loader,net):
net.eval()
val_correct = 0.0
val_loss = 0.0 # 初始化验证损失
loss_function = nn.CrossEntropyLoss()
loss_function = loss_function.to(device)
val_bar = tqdm(val_loader, file=sys.stdout)
for step, data in enumerate(val_bar):
images, labels = data
images, labels = images.to(device), labels.to(device)
with torch.no_grad():
# 验证
outputs = net(images)
# 计算损失
loss = loss_function(outputs, labels)
# 统计
_, preds = outputs.max(1)
correct = preds.eq(labels).sum()
val_correct += correct
val_loss += loss.item() # 累加损失值
val_bar.desc = 'Valing Epoch:[{trained_samples}/{total_samples}]\t Loss: {:0.4f}\t Accuracy: {:0.4f}\t'.format(
loss.item(),
(100. * correct) / len(outputs),
trained_samples=step * val_loader.batch_size + len(images),
total_samples=len(val_loader.dataset))
val_correct = (100. * val_correct) / len(val_loader.dataset)
val_loss /= len(val_loader) # 计算平均损失值
return val_correct , val_loss # 返回验证正确率和平均损失值注意:若使用Kaggle,想要导入该模块,需要添加以下代码
import sys
sys.path.append(r'/kaggle/input/mycode2')其中,模块路径如下图
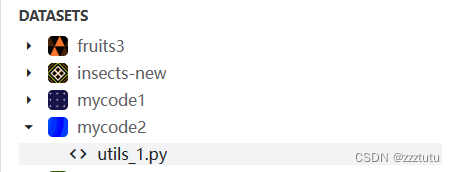
2.主函数
主函数包含:使用模型函数、训练主函数、画图代码
2.1使用模型函数
【若使用其他模型,可chatgpt创建其函数】
(1)resnet101
def get_resnet101(class_num):
net_name = "resnet101"
net = torchvision.models.resnet101(pretrained=True)
net.fc = Linear(in_features=2048, out_features=class_num, bias=True) # ResNet101's fully connected layer expects 2048 input features
net = net.to(device)
return net_name, net(2)resnet34
def get_resnet34(class_num):
net_name = "resnet34"
net = torchvision.models.resnet34(pretrained=True)
net.fc = Linear(in_features=512, out_features=class_num, bias=True)
net = net.to(device)
return net_name,net(3)mobilenetv2
def get_mobilenet_v2(class_num):
net_name = "mobilenet_v2"
net = torchvision.models.mobilenet_v2(pretrained=True)
net.classifier[1] = Linear(in_features=1280, out_features=class_num, bias=True)
net = net.to(device)
return net_name,net2.2画图代码
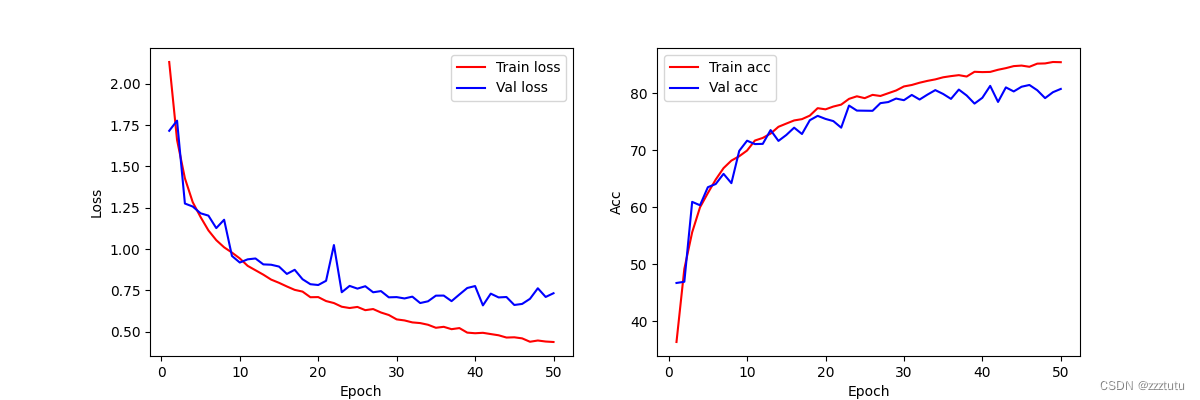
save_path="/kaggle/working/"
plt.figure(figsize=(12, 4))
# loss
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs + 1), train_losses, "r-",label='Train loss')
plt.plot(range(1, epochs + 1), val_losses, "b-",label='Val loss')
plt.legend()
plt.xlabel('Epoch')
plt.ylabel('Loss')
# acc
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs + 1), train_accs,"r-", label='Train acc')
plt.plot(range(1, epochs + 1), val_accs,"b-" ,label='Val acc')
plt.legend()
plt.xlabel('Epoch')
plt.ylabel('Acc')
plt.legend()
plt.savefig(os.path.join(save_path, 'result.png')) # 保存
plt.show()2.3完整代码
import torch
import torchvision.models
from matplotlib import pyplot as plt
from torch.nn import Linear
import os
# 导入自己创建的模块
from utils_1 import get_train_loader, train, val, get_val_loader
# 模型选择
def get_resnet101(class_num):
net_name = "resnet101"
net = torchvision.models.resnet101(pretrained=True)
net.fc = Linear(in_features=2048, out_features=class_num, bias=True) # ResNet101's fully connected layer expects 2048 input features
net = net.to(device)
return net_name, net
# def get_resnet34(class_num):
# net_name = "resnet34"
# net = torchvision.models.resnet34(pretrained=True)
# net.fc = Linear(in_features=512, out_features=class_num, bias=True)
# net = net.to(device)
# return net_name,net
# def get_mobilenet_v2(class_num):
# net_name = "mobilenet_v2"
# net = torchvision.models.mobilenet_v2(pretrained=True)
# net.classifier[1] = Linear(in_features=1280, out_features=class_num, bias=True)
# net = net.to(device)
# return net_name,net
# 训练主函数
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#1 加载数据
image_path = r"/kaggle/input/fruits3"
train_loader = get_train_loader(image_path)
val_loader = get_val_loader(image_path)
#2 加载模型
net_name,net = get_resnet34(class_num=5)
#3 训练
epochs = 5
best_acc = 0
train_losses = []
val_losses = []
train_accs = []
val_accs = []
for epoch in range(epochs):
train_acc,train_loss = train(train_loader, net)
val_acc,val_loss = val(val_loader, net)
train_losses.append(train_loss)
val_losses.append(val_loss)
train_accs.append(train_acc.item())
val_accs.append(val_acc.item())
if best_acc<val_acc:
best_acc = val_acc
torch.save(net, os.path.join("/kaggle/working/", net_name + ".pt"))
# 画图
save_path="/kaggle/working/" # 图片保存路径
plt.figure(figsize=(12, 4))
# loss
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs + 1), train_losses, "r-",label='Train loss')
plt.plot(range(1, epochs + 1), val_losses, "b-",label='Val loss')
plt.legend()
plt.xlabel('Epoch')
plt.ylabel('Loss')
# acc
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs + 1), train_accs,"r-", label='Train acc')
plt.plot(range(1, epochs + 1), val_accs,"b-" ,label='Val acc')
plt.legend()
plt.xlabel('Epoch')
plt.ylabel('Acc')
plt.legend()
plt.savefig(os.path.join(save_path, 'result.png')) # 保存
plt.show()2.4训练效果与模型文件