本文介绍一个统一音频标记(Audio Tagger)和语音识别(ASR)的模型:Whisper-AT,通过冻结Whisper的主干,并在其之上训练一个轻量级的音频标记模型。Whisper-AT在额外计算成本不到1%的情况下,可以在单次前向传递中识别音频事件以及口语文本。这个模型的提出是建立一个有趣的发现基础上:Whisper对真实世界背景声音非常鲁棒,其音频表示实际上并不是噪声不变的,而是与非语音声音高度相关,这表明Whisper是在噪声类型的基础上识别语音的。
1.概述:
Whisper-AT 是建立在 Whisper 自动语音识别(ASR)模型基础上的一个模型。Whisper 模型使用了一个包含 68 万小时标注语音的大规模语料库进行训练,这些语料是在各种不同条件下录制的。Whisper 模型以其在现实背景噪音(如音乐)下的鲁棒性著称。尽管如此,其音频表示并非噪音不变,而是与非语音声音高度相关。这意味着 Whisper 在识别语音时会依据背景噪音类型进行调整。
主要发现:
-
噪音变化的表示:
- Whisper 的音频表示编码了丰富的非语音背景声音信息,这与通常追求噪音不变表示的 ASR 模型目标不同。
- 这一特性使得 Whisper 能够在各种噪音条件下通过识别和适应噪音来保持其鲁棒性。
-
ASR 和音频标签的统一模型:
- 通过冻结 Whisper 模型的骨干网络,并在其上训练一个轻量级的音频标签模型,Whisper-AT 可以在一次前向传递中同时识别音频事件和语音文本,额外的计算成本不足 1%。
- Whisper-AT 在音频事件检测方面表现出色,同时保持了 Whisper 的 ASR 功能。
技术细节:
-
Whisper ASR 模型:
- Whisper 使用基于 Transformer 的编码器-解码器架构。
- 其训练集包括从互联网上收集的 68 万小时音频-文本对,涵盖了广泛的环境、录音设置、说话人和语言。
-
抗噪机制:
- Whisper 的鲁棒性并非通过噪音不变性实现,而是通过在其表示中编码噪音类型。
- 这一机制使得 Whisper 能够根据背景噪音类型来转录文本,从而在嘈杂条件下表现优越。
-
构建 Whisper-AT:
- Whisper-AT 是通过在 Whisper 模型上添加新的音频标签层而构建的,未修改其原始权重。
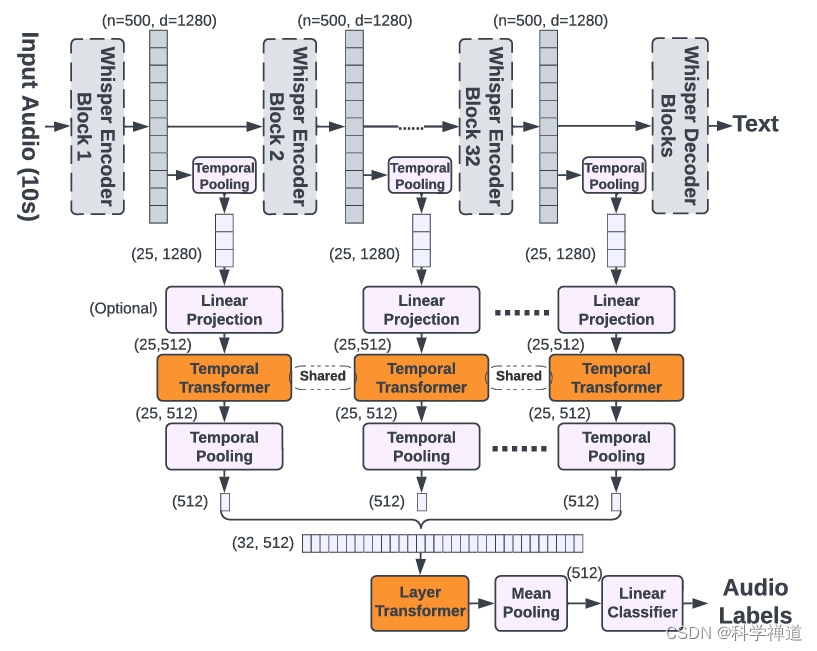
- 探索了不同的音频标签层集成方法,包括:
- Last-MLP:对 Whisper 的最后一层表示进行时间均值池化,然后应用线性层。
- WA-MLP:对所有层的表示进行加权平均,然后应用线性层。
- WA-Tr:用时间 Transformer 层替换线性层。
- TL-Tr:使用时间和层次 Transformer 处理所有层的表示。
- Whisper-AT 是通过在 Whisper 模型上添加新的音频标签层而构建的,未修改其原始权重。
-
效率考量:
- 为保持计算效率,采用了各种策略,例如减少表示的序列长度,并在应用音频标签 Transformer 之前可选地降低维度。
性能:
- Whisper-AT 在 AudioSet 上达到了 41.5 的 mAP,略低于独立的音频标签模型,但处理速度显著更快,超过 40 倍。
意义:
- 能够同时执行 ASR 和音频标签任务,使得 Whisper-AT 非常适合于视频转录、语音助手和助听器系统等应用场景,在这些场景中需要同时进行语音文本和声学场景分析。
2.代码:
欲了解详细的实现和实验结果,请访问 GitHub: github.com/yuangongnd/whisper-at.下面是对 Whisper-AT 代码的详细解释。我们将逐步解析其主要组件和功能,帮助理解其工作原理。
安装和准备
首先,确保你已经安装了 Whisper 和相关的依赖项:
pip install git+https://github.com/openai/whisper.git
pip install torch torchaudio
pip install transformers datasets
代码结构
简要 Whisper-AT 的代码结构如下所示:
Whisper-AT/
│
├── whisper_at.py
├── train.py
├── dataset.py
├── utils.py
└── README.md
whisper_at.py - Whisper-AT 模型
import torch
import torch.nn as nn
import whisper
class WhisperAT(nn.Module):
def __init__(self, model_name="base"):
super(WhisperAT, self).__init__()
self.whisper = whisper.load_model(model_name)
self.audio_tagging_head = nn.Linear(self.whisper.dims, 527) # 527 是 AudioSet 的标签数
def forward(self, audio):
# 获取 Whisper 的中间表示
with torch.no_grad():
features = self.whisper.encode(audio)
# 通过音频标签头
audio_tagging_output = self.audio_tagging_head(features.mean(dim=1))
return audio_tagging_output
train.py - 训练脚本
import torch
from torch.utils.data import DataLoader
from dataset import AudioSetDataset
from whisper_at import WhisperAT
import torch.optim as optim
import torch.nn.functional as F
def train():
# 加载数据集
train_dataset = AudioSetDataset("path/to/training/data")
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 初始化模型
model = WhisperAT()
model.train()
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=1e-4)
for epoch in range(10): # 假设训练10个epoch
for audio, labels in train_loader:
optimizer.zero_grad()
# 前向传播
outputs = model(audio)
# 计算损失
loss = F.binary_cross_entropy_with_logits(outputs, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item()}")
if __name__ == "__main__":
train()
dataset.py - 数据集处理
import torch
from torch.utils.data import Dataset
import torchaudio
class AudioSetDataset(Dataset):
def __init__(self, data_path):
self.data_path = data_path
self.audio_files = [...] # 这里假设你有一个包含所有音频文件路径的列表
self.labels = [...] # 这里假设你有一个包含所有对应标签的列表
def __len__(self):
return len(self.audio_files)
def __getitem__(self, idx):
# 加载音频
audio, sample_rate = torchaudio.load(self.audio_files[idx])
# 获取对应标签
labels = torch.tensor(self.labels[idx])
return audio, labels
utils.py - 辅助功能
import torch
def save_model(model, path):
torch.save(model.state_dict(), path)
def load_model(model, path):
model.load_state_dict(torch.load(path))
model.eval()
详细解释
-
Whisper-AT 模型 (
whisper_at.py):WhisperAT类继承自nn.Module,初始化时加载 Whisper 模型,并在其上添加一个线性层用于音频标签任务。forward方法首先调用 Whisper 模型的encode方法获取音频特征,然后将这些特征传递给音频标签头(线性层)以生成标签输出。
-
训练脚本 (
train.py):train函数中,数据集被加载并传递给 DataLoader。- 模型实例化并设置为训练模式。
- 定义了 Adam 优化器和二进制交叉熵损失函数。
- 在训练循环中,音频输入通过模型生成输出,计算损失并执行反向传播和优化。
-
数据集处理 (
dataset.py):AudioSetDataset类继承自Dataset,实现了音频数据和标签的加载。__getitem__方法加载音频文件并返回音频张量和对应标签。
-
辅助功能 (
utils.py):- 包含保存和加载模型状态的函数,方便模型的持久化和恢复。
通过以上代码结构和解释,可以帮助理解 Whisper-AT 的实现和训练流程。可以根据需要扩展这些代码来适应具体的应用场景和数据集。
附录:
A. 通用音频事件标记(Audio Tagger)
通用音频事件标记 (Audio Tagger) 是一种用于识别和分类音频信号中不同事件的技术。它在音频处理领域具有广泛的应用,包括环境声音识别、音乐信息检索、语音识别、和多媒体内容分析等。
核心概念
-
音频事件(Audio Event): 音频事件指的是音频信号中的特定声音,如鸟鸣、犬吠、警笛声、音乐片段或人声。这些事件可以是短暂的瞬时声音或持续一段时间的信号。
-
标签(Tagging): 标签是对音频信号中的事件进行分类或标注的过程。每个标签对应一个音频事件类别,目的是识别音频信号中包含哪些类型的声音。
技术实现
1. 特征提取
特征提取是音频事件标记的第一步,它将原始音频信号转换为适合分类的特征向量。常用的特征提取方法包括:
- 梅尔频率倒谱系数(MFCC):捕捉音频信号的短时频谱特征。
- 谱质心(Spectral Centroid):描述音频信号的亮度。
- 零交叉率(Zero-Crossing Rate):音频信号通过零点的次数。
- 色度特征(Chromagram):表示音频信号的音调内容。
2. 特征表示和建模
一旦提取了音频特征,需要将其输入到机器学习模型中进行训练和预测。常用的模型包括:
- 传统机器学习模型:如高斯混合模型 (GMM)、支持向量机 (SVM) 和隐马尔可夫模型 (HMM)。
- 深度学习模型:卷积神经网络 (CNN) 和递归神经网络 (RNN) 在音频事件标记中表现出色,尤其是能够处理复杂的时间和频率模式。
3. 标签分配和分类
在训练模型之后,对新的音频信号进行标签分配。模型根据输入的特征向量预测音频信号所属的事件类别。
应用实例
- 环境声音识别:识别并分类自然环境中的声音,如鸟叫、雨声、车流声等。
- 音乐信息检索:分析和分类音乐片段,识别音乐类型、乐器声或特定的音乐模式。
- 语音识别:识别和分类语音中的特定事件,如关键词检测、语音活动检测等。
前沿研究
-
多任务学习: 多任务学习方法通过在多个相关任务上共享表示来提高模型性能。例如,PSLA(Pretraining, Sampling, Labeling, and Aggregation)方法在音频标签任务中取得了显著进展 。
-
自监督学习: 自监督学习方法通过利用大量未标记数据进行预训练,显著提高了模型在音频事件标记任务上的表现。
-
基于Transformer的模型: 例如,Audio Spectrogram Transformer (AST) 利用Transformer架构的优势,在多个音频分类任务上表现优异,超越了传统的卷积神经网络(CNN)方法 。
总结
通用音频事件标记在现代音频处理领域发挥着重要作用。通过结合特征提取、先进的机器学习模型和深度学习技术,音频事件标记能够实现高效、准确的音频信号分类和识别。在未来,随着多任务学习、自监督学习和更先进的深度学习模型的引入,音频事件标记技术将继续发展和完善。
B. Whisper模型
Whisper 是由 OpenAI 开发的一个先进的自动语音识别(ASR)模型。它采用了Transformer架构,特别擅长捕捉音频信号中的全局特征和时间动态。这使得 Whisper 能够在多语言和多任务的语音识别任务中表现优异。
Whisper 模型简介
1. 模型架构
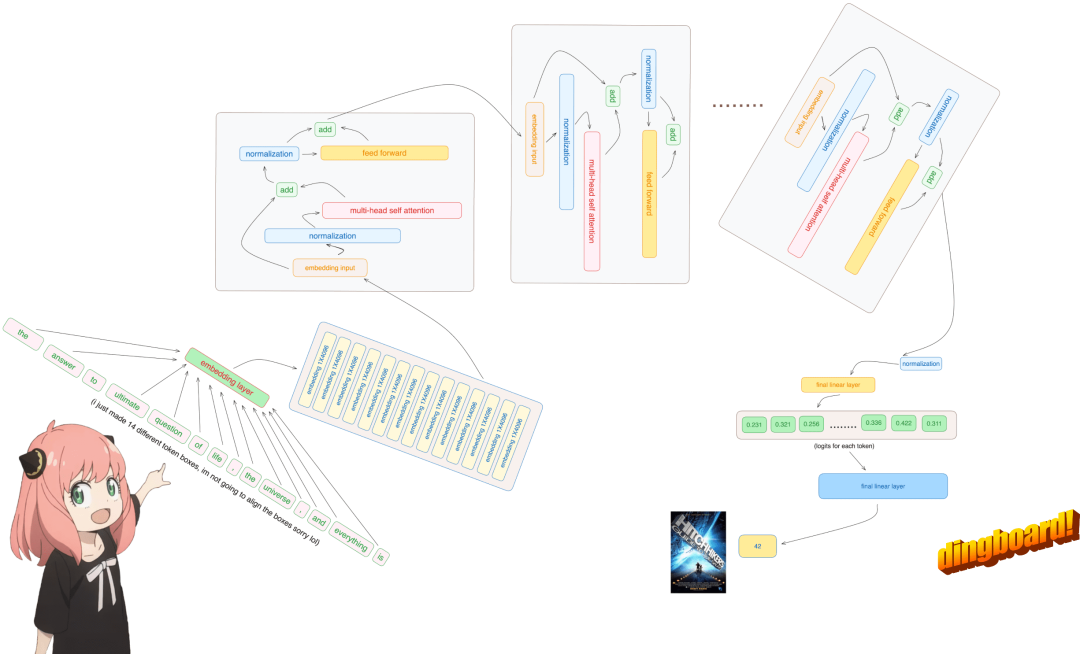
Whisper模型的核心是Transformer架构,包括编码器(Encoder)和解码器(Decoder)。该架构利用多头自注意力机制(Multi-Head Self-Attention)和位置编码(Positional Encoding)来处理音频信号,捕捉其时间动态和全局特征。
- 编码器(Encoder):负责接收和处理输入音频信号,将其转换为高维度的中间表示。编码器由多层自注意力和前馈神经网络组成。
- 解码器(Decoder):利用编码器生成的中间表示,结合上下文信息,生成目标输出(如转录文本)。解码器结构类似于编码器,同样由多层自注意力和前馈神经网络组成。
2. 自注意力机制
自注意力机制允许模型在处理音频信号时,动态地关注不同部分的信息,从而捕捉长程依赖关系。这种机制特别适用于音频信号处理,因为语音信息通常分布在整个序列中,需要全局视角进行建模。
3. 位置编码
由于音频信号是连续的时间序列数据,位置编码在Whisper模型中起着关键作用。位置编码通过为每个时间步添加唯一的位置信息,使得模型能够识别音频信号中的顺序和时间动态。
Whisper 模型的特性和优势
- 多语言支持:Whisper 支持多种语言的语音识别任务,能够处理不同语言的音频信号。
- 高准确性:得益于Transformer架构和自注意力机制,Whisper在多任务语音识别任务中表现出色,准确率高。
- 长程依赖建模:通过自注意力机制,Whisper能够捕捉音频信号中的长程依赖关系,处理长时间的语音数据更加有效。
- 灵活性和扩展性:Whisper可以通过预训练和微调,适应不同的语音识别任务和数据集。
Whisper 模型的应用
Whisper 可应用于多种语音识别和处理任务,包括:
- 实时语音转录:将实时语音输入转录为文本,用于字幕生成、会议记录等场景。
- 多语言翻译:实时翻译不同语言的语音输入,促进跨语言交流。
- 语音指令识别:用于智能设备和语音助手的语音指令识别,提高交互体验。







![[论文笔记]SELF-INSTRUCT](https://img-blog.csdnimg.cn/img_convert/cab333ffa08c70b7af890383f8783b19.png)