随着人工智能技术的飞速发展,多模态大型语言模型(LLMs)在理解和生成文本方面取得了显著成就。然而,这些模型在核心视觉感知任务上的表现仍远落后于人类。本文介绍了Blink基准测试,这是一套针对多模态LLMs的视觉感知能力的新测试,旨在评估那些在其他评估中未被充分测试的能力。即使是最先进的模型,如GPT-4V和Gemini,在Blink上的表现也远低于人类水平,这表明当前的多模态LLMs在视觉感知方面还有很大的提升空间。
 上图展示了Blink基准测试的概览,包含14个视觉感知任务的示例,这些任务对人类来说可以迅速解决,但对当前的多模态LLMs构成挑战。这些任务受经典计算机视觉问题的启发,并被重新构为多项选择题,供多模态LLMs回答。
上图展示了Blink基准测试的概览,包含14个视觉感知任务的示例,这些任务对人类来说可以迅速解决,但对当前的多模态LLMs构成挑战。这些任务受经典计算机视觉问题的启发,并被重新构为多项选择题,供多模态LLMs回答。
Blink基准测试的设计初衷是评估多模态LLMs在核心视觉感知任务上的表现,这些任务通常对人类来说易如反掌,但对机器来说却颇具挑战。Blink的独特之处在于其多样化的视觉提示,它不仅仅局限于文本提示,还包括了圆形、方框和遮罩等多种视觉元素,这些视觉提示有助于模型集中注意力并深入理解图像的特定区域。
Blink的另一个显著特点是其超越了单纯的视觉识别能力,它涵盖了3D推理、几何理解、功能推理等一系列复杂的视觉感知能力。这些能力对于机器来说至关重要,因为它们涉及到对场景的深入理解和解释。
Blink中的问题被设计为不需要特定领域知识即可解答,这些问题对人类而言是“视觉常识”,可以在几秒内解决。这样的设计使得Blink能够直接评估机器与人类在视觉感知方面的基础差异。
Blink采用了交错的图像-文本格式,问题和选项可以是图像或文本形式,这种多样性要求模型真正理解问题并推动了模型解释能力的边界。

上图对比了Blink和其他现有基准测试的特点。展示了Blink在视觉提示、感知能力评估、常识问题以及图像-文本格式方面的新颖性:
- 多样化的视觉提示:Blink 包含多种视觉提示,如圆形、方框和图像遮罩,而以前的基准测试只有文本问题和答案。
- 全面评估视觉感知能力:Blink 评估了更广泛的视觉感知能力,如多视图推理、深度估计和反射率估计。相比之下,先前的基准测试通常更侧重于基于识别的视觉问答(VQA)。
- 视觉常识问题:Blink 包含了人类可以在几秒钟内回答的“视觉”常识问题,而以前的一些基准测试(如文献[87])需要领域知识。
Blink的数据来源非常广泛,它包括了从室内家居场景到室外城市或自然环境的多样化图像。这些图像既有抽象的图表,也有合成图像和真实照片,确保了评估的全面性。
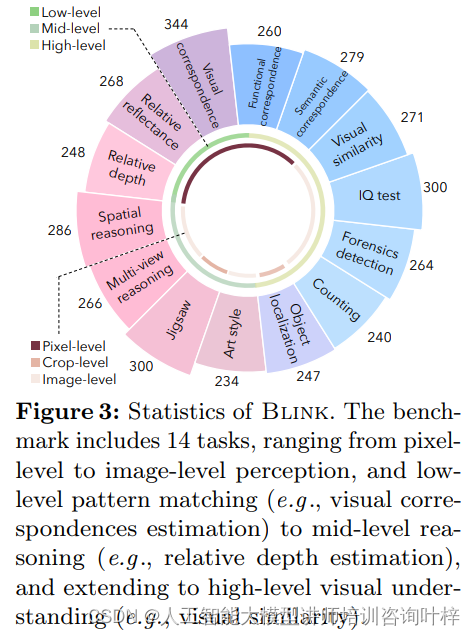
上图展示Blink 基准测试中包含的14个任务的统计数据。Blink基准测试中的14个任务是从经典的计算机视觉问题中提取并重新构想为多项选择题。这些任务覆盖了从像素级别的模式匹配到图像级别的高级视觉理解。例如,视觉对应任务评估模型理解和识别不同视角、光照条件或时间下相同场景点的能力;相对反射率任务则评估模型对材料属性及其与光相互作用的理解。
为了构建Blink,研究者们从多个现有视觉数据集中提取图像,并收集了新的数据。他们精心挑选了图像,确保所有测试样本都具有独特的图像。这些图像和问题来源于不同的数据集,或由人类手动编写,以确保问题的多样性和挑战性。
在数据质量控制方面,研究者们手动检查了所有收集的数据,并筛选出了不明确的数据,以保证Blink数据集的质量。这个过程确保了Blink基准测试能够提供准确和有意义的评估。通过Blink,研究者们可以更深入地了解现有模型的局限性,并探索提高机器视觉感知能力的新途径。
实验中所选用的多模态LLMs是当前技术前沿的代表,它们包括但不限于GPT-4V和Gemini Pro等模型。这些模型的规模不同,从几亿参数到几十亿参数不等,旨在探索模型规模与视觉感知能力之间的关系。评估协议遵循了标准化的流程,确保了实验结果的可比性和公正性。数据集方面,Blink基准测试采用了精心挑选和设计的图像和问题。这些问题被构造为多项选择题,以便模型能够从中选择最合适的答案。图像和问题的设计覆盖了广泛的视觉感知任务,确保了评估的全面性和挑战性。
实验的过程开始于将这些多模态LLMs暴露于Blink基准测试的数据集之中。模型需要处理图像、理解问题,并从给定的选项中选择最合适的答案。这一过程模拟了人类在面对视觉信息时的快速决策和理解能力。在实验中,模型的性能通过准确率来衡量,即模型选择正确答案的频率。为了确保评估的严谨性,实验重复了多次,并采用了不同的图像和问题组合。
实验结果显示,尽管人类在Blink基准测试上的平均准确率高达95.70%,但现有的多模态LLMs在这些任务上的表现却远未达到人类的水平。例如,即使是表现最好的GPT-4V模型,其准确率也仅为51.26%,仅比随机猜测的准确率高出13.17%。这一结果揭示了现有模型在视觉感知方面存在的显著差距。

上图展示了多模态大型语言模型(LLMs)在 Blink 测试集上的准确率。

上图展示了 Blink 基准测试的定性结果。在这个图表中,研究者比较了不同的多模态大型语言模型(LLMs)如 LLaVA v1.6-34B、Qwen-VL-Max、Gemini Pro、GPT-4V 以及人类在各项任务中的表现。图中的红色选择表示正确答案或地面真实情况(ground truth)。为了可视化的目的,标记被特意放大,并且一些图像被嵌入以节省空间。对于智商测试(IQ test),第三张图像是通过叠加第一张和第二张图像来构建的。
实验结果还揭示了不同模型在不同任务上的表现差异。一些模型在特定任务上表现出了相对的优势,如在空间推理或艺术风格识别任务上。然而,在像素级别和图像区域级别的任务上,所有模型都面临了更大的挑战。
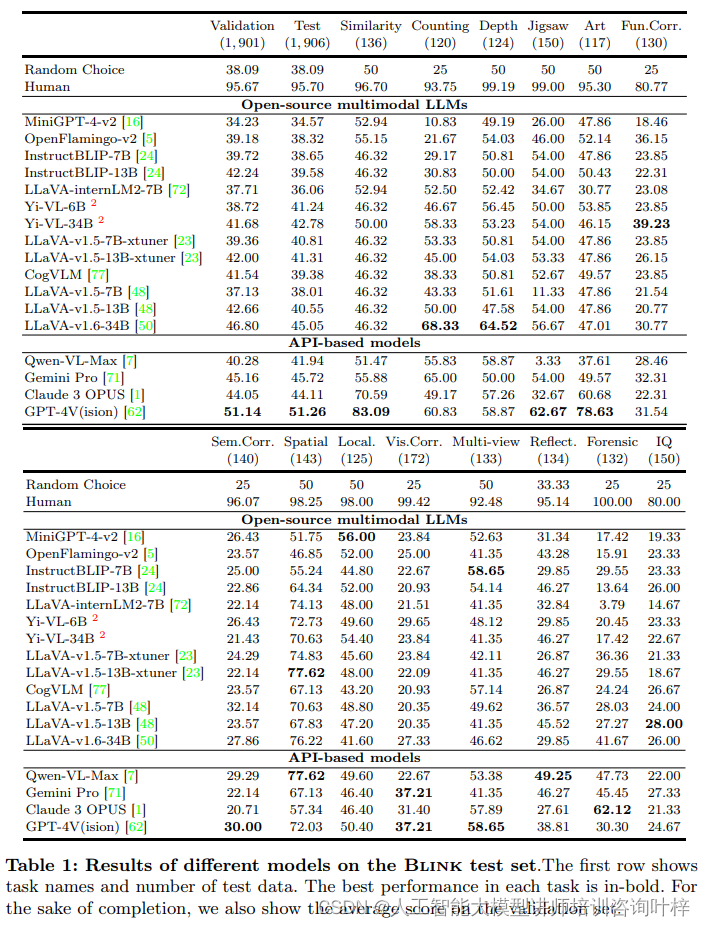
上表提供了不同模型在Blink测试集上的性能结果,包括随机选择、人类表现以及不同模型的准确率。
结果表明,尽管这些模型在某些视觉任务上取得了进展,但它们在理解和处理复杂视觉信息方面仍有很大的提升空间。这一发现为未来的研究提供了明确的方向,即需要进一步改进模型的感知能力,以便它们能够更好地模拟人类的快速和准确的视觉处理能力。
Blink基准测试为多模态LLMs提供了一个简单而有效的测试平台,以评估和提升其视觉感知能力。通过这一基准测试,我们期望能够激发社区的进一步研究,帮助多模态LLMs逐步达到人类级的视觉感知水平。
论文链接:https://arxiv.org/abs/2404.12390
项目地址:https://zeyofu.github.io/blink/