首先部署prometheus
首先是pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-data-pvc
namespace: monitor
spec:
accessModes:
- ReadWriteMany
storageClassName: "data-nfs-storage"
resources:
requests:
storage: 10Gi
然后接着 cluster-role 这里给了cluster-admin权限
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus2
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus2
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: prometheus2
namespace: monitor
由于用的是istio 所以这里的ingress用vs替代
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
cluster: "kubernetes"
alerting:
alertmanagers:
- static_configs:
- targets: ["aalertmanager:9093"]
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: kubelet
metrics_path: /metrics/cadvisor
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace
- job_name: k8s-state-metrics
kubernetes_sd_configs: # k8s service discovery conf 服务发现配置
- role: endpoints # 去k8s的APIServer里拿取endpoints资源清单
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_kubernetes_io_name]
regex: kube-state-metrics
action: keep
- source_labels: [__meta_kubernetes_pod_ip]
regex: (.+)
target_label: __address__
replacement: ${1}:8080
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace
- job_name: ingress
metrics_path: /metrics/cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__address__]
regex: '(.+):10250'
target_label: __address__
replacement: ${1}:10254
- job_name: jx-mysql-master-37
static_configs:
- targets: ['10.0.40.3:9104']
labels:
instance: jx-mysql-master-36
############ 指定告警规则文件路径位置 ###################
rule_files:
- /etc/prometheus/rules/*.rules
---
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: monitor
data:
node-exporter.rules: |
groups:
- name: NodeExporter
rules:
- alert: HostOutOfMemory
expr: '(node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host out of memory (instance {{ $labels.instance }})
description: "Node memory is filling up (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostMemoryUnderMemoryPressure
expr: '(rate(node_vmstat_pgmajfault[1m]) > 1000) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host memory under memory pressure (instance {{ $labels.instance }})
description: "The node is under heavy memory pressure. High rate of major page faults\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostMemoryIsUnderutilized
expr: '(100 - (rate(node_memory_MemAvailable_bytes[30m]) / node_memory_MemTotal_bytes * 100) < 20) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 1w
labels:
severity: info
annotations:
summary: Host Memory is underutilized (instance {{ $labels.instance }})
description: "Node memory is < 20% for 1 week. Consider reducing memory space. (instance {{ $labels.instance }})\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostUnusualNetworkThroughputIn
expr: '(sum by (instance) (rate(node_network_receive_bytes_total[2m])) / 1024 / 1024 > 100) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 5m
labels:
severity: warning
annotations:
summary: Host unusual network throughput in (instance {{ $labels.instance }})
description: "Host network interfaces are probably receiving too much data (> 100 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostUnusualNetworkThroughputOut
expr: '(sum by (instance) (rate(node_network_transmit_bytes_total[2m])) / 1024 / 1024 > 100) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 5m
labels:
severity: warning
annotations:
summary: Host unusual network throughput out (instance {{ $labels.instance }})
description: "Host network interfaces are probably sending too much data (> 100 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostUnusualDiskReadRate
expr: '(sum by (instance) (rate(node_disk_read_bytes_total[2m])) / 1024 / 1024 > 50) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 5m
labels:
severity: warning
annotations:
summary: Host unusual disk read rate (instance {{ $labels.instance }})
description: "Disk is probably reading too much data (> 50 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostUnusualDiskWriteRate
expr: '(sum by (instance) (rate(node_disk_written_bytes_total[2m])) / 1024 / 1024 > 50) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host unusual disk write rate (instance {{ $labels.instance }})
description: "Disk is probably writing too much data (> 50 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostOutOfDiskSpace
expr: '((node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host out of disk space (instance {{ $labels.instance }})
description: "Disk is almost full (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostDiskWillFillIn24Hours
expr: '((node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs"}[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly == 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host disk will fill in 24 hours (instance {{ $labels.instance }})
description: "Filesystem is predicted to run out of space within the next 24 hours at current write rate\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostOutOfInodes
expr: '(node_filesystem_files_free / node_filesystem_files * 100 < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host out of inodes (instance {{ $labels.instance }})
description: "Disk is almost running out of available inodes (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostFilesystemDeviceError
expr: 'node_filesystem_device_error == 1'
for: 0m
labels:
severity: critical
annotations:
summary: Host filesystem device error (instance {{ $labels.instance }})
description: "{{ $labels.instance }}: Device error with the {{ $labels.mountpoint }} filesystem\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostInodesWillFillIn24Hours
expr: '(node_filesystem_files_free / node_filesystem_files * 100 < 10 and predict_linear(node_filesystem_files_free[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly == 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host inodes will fill in 24 hours (instance {{ $labels.instance }})
description: "Filesystem is predicted to run out of inodes within the next 24 hours at current write rate\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostUnusualDiskReadLatency
expr: '(rate(node_disk_read_time_seconds_total[1m]) / rate(node_disk_reads_completed_total[1m]) > 0.1 and rate(node_disk_reads_completed_total[1m]) > 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host unusual disk read latency (instance {{ $labels.instance }})
description: "Disk latency is growing (read operations > 100ms)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostUnusualDiskWriteLatency
expr: '(rate(node_disk_write_time_seconds_total[1m]) / rate(node_disk_writes_completed_total[1m]) > 0.1 and rate(node_disk_writes_completed_total[1m]) > 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host unusual disk write latency (instance {{ $labels.instance }})
description: "Disk latency is growing (write operations > 100ms)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostHighCpuLoad
expr: '(sum by (instance) (avg by (mode, instance) (rate(node_cpu_seconds_total{mode!="idle"}[2m]))) > 0.8) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 10m
labels:
severity: warning
annotations:
summary: Host high CPU load (instance {{ $labels.instance }})
description: "CPU load is > 80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostCpuIsUnderutilized
expr: '(100 - (rate(node_cpu_seconds_total{mode="idle"}[30m]) * 100) < 20) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 1w
labels:
severity: info
annotations:
summary: Host CPU is underutilized (instance {{ $labels.instance }})
description: "CPU load is < 20% for 1 week. Consider reducing the number of CPUs.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostCpuStealNoisyNeighbor
expr: '(avg by(instance) (rate(node_cpu_seconds_total{mode="steal"}[5m])) * 100 > 10) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 0m
labels:
severity: warning
annotations:
summary: Host CPU steal noisy neighbor (instance {{ $labels.instance }})
description: "CPU steal is > 10%. A noisy neighbor is killing VM performances or a spot instance may be out of credit.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostCpuHighIowait
expr: '(avg by (instance) (rate(node_cpu_seconds_total{mode="iowait"}[5m])) * 100 > 10) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 0m
labels:
severity: warning
annotations:
summary: Host CPU high iowait (instance {{ $labels.instance }})
description: "CPU iowait > 10%. A high iowait means that you are disk or network bound.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostUnusualDiskIo
expr: '(rate(node_disk_io_time_seconds_total[1m]) > 0.5) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 5m
labels:
severity: warning
annotations:
summary: Host unusual disk IO (instance {{ $labels.instance }})
description: "Time spent in IO is too high on {{ $labels.instance }}. Check storage for issues.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostContextSwitching
expr: '((rate(node_context_switches_total[5m])) / (count without(cpu, mode) (node_cpu_seconds_total{mode="idle"})) > 10000) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 0m
labels:
severity: warning
annotations:
summary: Host context switching (instance {{ $labels.instance }})
description: "Context switching is growing on the node (> 10000 / s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostSwapIsFillingUp
expr: '((1 - (node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes)) * 100 > 80) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host swap is filling up (instance {{ $labels.instance }})
description: "Swap is filling up (>80%)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostSystemdServiceCrashed
expr: '(node_systemd_unit_state{state="failed"} == 1) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 0m
labels:
severity: warning
annotations:
summary: Host systemd service crashed (instance {{ $labels.instance }})
description: "systemd service crashed\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostPhysicalComponentTooHot
expr: '((node_hwmon_temp_celsius * ignoring(label) group_left(instance, job, node, sensor) node_hwmon_sensor_label{label!="tctl"} > 75)) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 5m
labels:
severity: warning
annotations:
summary: Host physical component too hot (instance {{ $labels.instance }})
description: "Physical hardware component too hot\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostNodeOvertemperatureAlarm
expr: '(node_hwmon_temp_crit_alarm_celsius == 1) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 0m
labels:
severity: critical
annotations:
summary: Host node overtemperature alarm (instance {{ $labels.instance }})
description: "Physical node temperature alarm triggered\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostRaidArrayGotInactive
expr: '(node_md_state{state="inactive"} > 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 0m
labels:
severity: critical
annotations:
summary: Host RAID array got inactive (instance {{ $labels.instance }})
description: "RAID array {{ $labels.device }} is in a degraded state due to one or more disk failures. The number of spare drives is insufficient to fix the issue automatically.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostRaidDiskFailure
expr: '(node_md_disks{state="failed"} > 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host RAID disk failure (instance {{ $labels.instance }})
description: "At least one device in RAID array on {{ $labels.instance }} failed. Array {{ $labels.md_device }} needs attention and possibly a disk swap\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostKernelVersionDeviations
expr: '(count(sum(label_replace(node_uname_info, "kernel", "$1", "release", "([0-9]+.[0-9]+.[0-9]+).*")) by (kernel)) > 1) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 6h
labels:
severity: warning
annotations:
summary: Host kernel version deviations (instance {{ $labels.instance }})
description: "Different kernel versions are running\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostOomKillDetected
expr: '(increase(node_vmstat_oom_kill[1m]) > 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 0m
labels:
severity: warning
annotations:
summary: Host OOM kill detected (instance {{ $labels.instance }})
description: "OOM kill detected\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostEdacCorrectableErrorsDetected
expr: '(increase(node_edac_correctable_errors_total[1m]) > 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 0m
labels:
severity: info
annotations:
summary: Host EDAC Correctable Errors detected (instance {{ $labels.instance }})
description: "Host {{ $labels.instance }} has had {{ printf \"%.0f\" $value }} correctable memory errors reported by EDAC in the last 5 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostEdacUncorrectableErrorsDetected
expr: '(node_edac_uncorrectable_errors_total > 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 0m
labels:
severity: warning
annotations:
summary: Host EDAC Uncorrectable Errors detected (instance {{ $labels.instance }})
description: "Host {{ $labels.instance }} has had {{ printf \"%.0f\" $value }} uncorrectable memory errors reported by EDAC in the last 5 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostNetworkReceiveErrors
expr: '(rate(node_network_receive_errs_total[2m]) / rate(node_network_receive_packets_total[2m]) > 0.01) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host Network Receive Errors (instance {{ $labels.instance }})
description: "Host {{ $labels.instance }} interface {{ $labels.device }} has encountered {{ printf \"%.0f\" $value }} receive errors in the last two minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostNetworkTransmitErrors
expr: '(rate(node_network_transmit_errs_total[2m]) / rate(node_network_transmit_packets_total[2m]) > 0.01) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host Network Transmit Errors (instance {{ $labels.instance }})
description: "Host {{ $labels.instance }} interface {{ $labels.device }} has encountered {{ printf \"%.0f\" $value }} transmit errors in the last two minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostNetworkInterfaceSaturated
expr: '((rate(node_network_receive_bytes_total{device!~"^tap.*|^vnet.*|^veth.*|^tun.*"}[1m]) + rate(node_network_transmit_bytes_total{device!~"^tap.*|^vnet.*|^veth.*|^tun.*"}[1m])) / node_network_speed_bytes{device!~"^tap.*|^vnet.*|^veth.*|^tun.*"} > 0.8 < 10000) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 1m
labels:
severity: warning
annotations:
summary: Host Network Interface Saturated (instance {{ $labels.instance }})
description: "The network interface \"{{ $labels.device }}\" on \"{{ $labels.instance }}\" is getting overloaded.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostNetworkBondDegraded
expr: '((node_bonding_active - node_bonding_slaves) != 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host Network Bond Degraded (instance {{ $labels.instance }})
description: "Bond \"{{ $labels.device }}\" degraded on \"{{ $labels.instance }}\".\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostConntrackLimit
expr: '(node_nf_conntrack_entries / node_nf_conntrack_entries_limit > 0.8) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 5m
labels:
severity: warning
annotations:
summary: Host conntrack limit (instance {{ $labels.instance }})
description: "The number of conntrack is approaching limit\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostClockSkew
expr: '((node_timex_offset_seconds > 0.05 and deriv(node_timex_offset_seconds[5m]) >= 0) or (node_timex_offset_seconds < -0.05 and deriv(node_timex_offset_seconds[5m]) <= 0)) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 10m
labels:
severity: warning
annotations:
summary: Host clock skew (instance {{ $labels.instance }})
description: "Clock skew detected. Clock is out of sync. Ensure NTP is configured correctly on this host.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostClockNotSynchronising
expr: '(min_over_time(node_timex_sync_status[1m]) == 0 and node_timex_maxerror_seconds >= 16) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 2m
labels:
severity: warning
annotations:
summary: Host clock not synchronising (instance {{ $labels.instance }})
description: "Clock not synchronising. Ensure NTP is configured on this host.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostRequiresReboot
expr: '(node_reboot_required > 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}'
for: 4h
labels:
severity: info
annotations:
summary: Host requires reboot (instance {{ $labels.instance }})
description: "{{ $labels.instance }} requires a reboot.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
volume.rules: |
groups:
- name: volume.rules
rules:
- alert: PersistentVolumeClaimLost
expr: |
sum by(namespace, persistentvolumeclaim) (kube_persistentvolumeclaim_status_phase{phase="Lost"}) == 1
for: 2m
labels:
severity: warning
annotations:
description: "PersistentVolumeClaim {{ $labels.namespace }}/{{ $labels.persistentvolumeclaim }} is lost!"
- alert: PersistentVolumeClaimPendig
expr: |
sum by(namespace, persistentvolumeclaim) (kube_persistentvolumeclaim_status_phase{phase="Pendig"}) == 1
for: 2m
labels:
severity: warning
annotations:
description: "PersistentVolumeClaim {{ $labels.namespace }}/{{ $labels.persistentvolumeclaim }} is pendig!"
- alert: PersistentVolume Failed
expr: |
sum(kube_persistentvolume_status_phase{phase="Failed",job="kubernetes-service-endpoints"}) by (persistentvolume) == 1
for: 2m
labels:
severity: warning
annotations:
description: "Persistent volume is failed state\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: PersistentVolume Pending
expr: |
sum(kube_persistentvolume_status_phase{phase="Pending",job="kubernetes-service-endpoints"}) by (persistentvolume) == 1
for: 2m
labels:
severity: warning
annotations:
description: "Persistent volume is pending state\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
prometheus.rules: |
groups:
- name: prometheus.rules
rules:
- alert: PrometheusErrorSendingAlertsToAnyAlertmanagers
expr: |
(rate(prometheus_notifications_errors_total{instance="localhost:9090", job="prometheus"}[5m]) / rate(prometheus_notifications_sent_total{instance="localhost:9090", job="prometheus"}[5m])) * 100 > 3
for: 5m
labels:
severity: warning
annotations:
description: '{{ printf "%.1f" $value }}% minimum errors while sending alerts from Prometheus {{$labels.namespace}}/{{$labels.pod}} to any Alertmanager.'
- alert: PrometheusNotConnectedToAlertmanagers
expr: |
max_over_time(prometheus_notifications_alertmanagers_discovered{instance="localhost:9090", job="prometheus"}[5m]) != 1
for: 5m
labels:
severity: critical
annotations:
description: "Prometheus {{$labels.namespace}}/{{$labels.pod}} 链接alertmanager异常!"
- alert: PrometheusRuleFailures
expr: |
increase(prometheus_rule_evaluation_failures_total{instance="localhost:9090", job="prometheus"}[5m]) > 0
for: 5m
labels:
severity: critical
annotations:
description: 'Prometheus {{$labels.namespace}}/{{$labels.pod}} 在5分钟执行失败的规则次数 {{ printf "%.0f" $value }}'
- alert: PrometheusRuleEvaluationFailures
expr: increase(prometheus_rule_evaluation_failures_total[3m]) > 0
for: 0m
labels:
severity: critical
annotations:
summary: Prometheus rule evaluation failures (instance {{ $labels.instance }})
description: "Prometheus 遇到规则 {{ $value }} 载入失败, 请及时检查."
- alert: PrometheusTsdbReloadFailures
expr: increase(prometheus_tsdb_reloads_failures_total[1m]) > 0
for: 0m
labels:
severity: critical
annotations:
summary: Prometheus TSDB reload failures (instance {{ $labels.instance }})
description: "Prometheus {{ $value }} TSDB 重载失败!"
- alert: PrometheusTsdbWalCorruptions
expr: increase(prometheus_tsdb_wal_corruptions_total[1m]) > 0
for: 0m
labels:
severity: critical
annotations:
summary: Prometheus TSDB WAL corruptions (instance {{ $labels.instance }})
description: "Prometheus {{ $value }} TSDB WAL 模块出现问题!"
website.rules: |
groups:
- name: website.rules
rules:
- alert: "ssl证书过期警告"
expr: (probe_ssl_earliest_cert_expiry - time())/86400 <30
for: 1h
labels:
severity: warning
annotations:
description: '域名{{$labels.instance}}的证书还有{{ printf "%.1f" $value }}天就过期了,请尽快更新证书'
summary: "ssl证书过期警告"
- alert: blackbox_network_stats
expr: probe_success == 0
for: 1m
labels:
severity: critical
pod: '{{$labels.instance}}'
namespace: '{{$labels.kubernetes_namespace}}'
annotations:
summary: "接口/主机/端口/域名 {{ $labels.instance }} 不能访问"
description: "接口/主机/端口/域名 {{ $labels.instance }} 不能访问,请尽快检测!"
- alert: curlHttpStatus
expr: probe_http_status_code{job="blackbox-http"} >= 422 and probe_success{job="blackbox-http"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: '业务报警: 网站不可访问'
description: '{{$labels.instance}} 不可访问,请及时查看,当前状态码为{{$value}}'
pod.rules: |
groups:
- name: pod.rules
rules:
- alert: PodCPUUsage
expr: |
sum(rate(container_cpu_usage_seconds_total{image!=""}[5m]) * 100) by (pod, namespace) > 90
for: 5m
labels:
severity: warning
pod: '{{$labels.pod}}'
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} CPU使用大于90% (当前值: {{ $value }})"
- alert: PodMemoryUsage
expr: |
sum(container_memory_rss{image!=""}) by(pod, namespace) / sum(container_spec_memory_limit_bytes{image!=""}) by(pod, namespace) * 100 != +inf > 85
for: 5m
labels:
severity: critical
pod: '{{$labels.pod}}'
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} 内存使用大于85% (当前值: {{ $value }})"
- alert: KubeDeploymentError
expr: |
kube_deployment_spec_replicas{job="kubernetes-service-endpoints"} != kube_deployment_status_replicas_available{job="kubernetes-service-endpoints"}
for: 3m
labels:
severity: warning
pod: '{{$labels.deployment}}'
annotations:
description: "Deployment {{ $labels.namespace }}/{{ $labels.deployment }}控制器与实际数量不相符 (当前值: {{ $value }})"
- alert: coreDnsError
expr: |
kube_pod_container_status_running{container="coredns"} == 0
for: 1m
labels:
severity: critical
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} coreDns服务异常 (当前值: {{ $value }})"
- alert: kubeProxyError
expr: |
kube_pod_container_status_running{container="kube-proxy"} == 0
for: 1m
labels:
severity: critical
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} kube-proxy服务异常 (当前值: {{ $value }})"
- alert: filebeatError
expr: |
kube_pod_container_status_running{container="filebeat"} == 0
for: 1m
labels:
severity: critical
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} filebeat服务异常 (当前值: {{ $value }})"
- alert: PodNetworkReceive
expr: |
sum(rate(container_network_receive_bytes_total{image!="",name=~"^k8s_.*"}[5m]) /1000) by (pod,namespace) > 60000
for: 5m
labels:
severity: warning
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} 入口流量大于60MB/s (当前值: {{ $value }}K/s)"
- alert: PodNetworkTransmit
expr: |
sum(rate(container_network_transmit_bytes_total{image!="",name=~"^k8s_.*"}[5m]) /1000) by (pod,namespace) > 60000
for: 5m
labels:
severity: warning
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} 出口流量大于60MB/s (当前值: {{ $value }}/K/s)"
- alert: PodRestart
expr: |
sum(changes(kube_pod_container_status_restarts_total[1m])) by (pod,namespace) > 1
for: 1m
labels:
severity: warning
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod重启 (当前值: {{ $value }})"
- alert: PodFailed
expr: |
sum(kube_pod_status_phase{phase="Failed"}) by (pod,namespace) > 0
for: 5s
labels:
severity: critical
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod状态Failed (当前值: {{ $value }})"
- alert: PodPending
expr: |
sum(kube_pod_status_phase{phase="Pending"}) by (pod,namespace) > 0
for: 30s
labels:
severity: critical
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod状态Pending (当前值: {{ $value }})"
- alert: PodErrImagePull
expr: |
sum by(namespace,pod) (kube_pod_container_status_waiting_reason{reason="ErrImagePull"}) == 1
for: 1m
labels:
severity: warning
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod状态ErrImagePull (当前值: {{ $value }})"
- alert: PodImagePullBackOff
expr: |
sum by(namespace,pod) (kube_pod_container_status_waiting_reason{reason="ImagePullBackOff"}) == 1
for: 1m
labels:
severity: warning
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod状态ImagePullBackOff (当前值: {{ $value }})"
- alert: PodCrashLoopBackOff
expr: |
sum by(namespace,pod) (kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"}) == 1
for: 1m
labels:
severity: warning
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod状态CrashLoopBackOff (当前值: {{ $value }})"
- alert: PodInvalidImageName
expr: |
sum by(namespace,pod) (kube_pod_container_status_waiting_reason{reason="InvalidImageName"}) == 1
for: 1m
labels:
severity: warning
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod状态InvalidImageName (当前值: {{ $value }})"
- alert: PodCreateContainerConfigError
expr: |
sum by(namespace,pod) (kube_pod_container_status_waiting_reason{reason="CreateContainerConfigError"}) == 1
for: 1m
labels:
severity: warning
annotations:
description: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod状态CreateContainerConfigError (当前值: {{ $value }})"
- alert: KubernetesContainerOomKiller
expr: (kube_pod_container_status_restarts_total - kube_pod_container_status_restarts_total offset 10m >= 1) and ignoring (reason) min_over_time(kube_pod_container_status_last_terminated_reason{reason="OOMKilled"}[10m]) == 1
for: 0m
labels:
severity: warning
annotations:
summary: Kubernetes container oom killer (instance {{ $labels.instance }})
description: "{{ $labels.namespace }}/{{ $labels.pod }} has been OOMKilled {{ $value }} times in the last 10 minutes!"
- alert: KubernetesPersistentvolumeError
expr: kube_persistentvolume_status_phase{phase=~"Failed|Pending", job="kube-state-metrics"} > 0
for: 0m
labels:
severity: critical
annotations:
summary: Kubernetes PersistentVolume error (instance {{ $labels.instance }})
description: "{{ $labels.instance }} Persistent volume is in bad state!"
- alert: KubernetesStatefulsetDown
expr: (kube_statefulset_status_replicas_ready / kube_statefulset_status_replicas_current) != 1
for: 1m
labels:
severity: critical
annotations:
summary: Kubernetes StatefulSet down (instance {{ $labels.instance }})
description: "{{ $labels.statefulset }} A StatefulSet went down!"
- alert: KubernetesStatefulsetReplicasMismatch
expr: kube_statefulset_status_replicas_ready != kube_statefulset_status_replicas
for: 10m
labels:
severity: warning
annotations:
summary: Kubernetes StatefulSet replicas mismatch (instance {{ $labels.instance }})
description: "{{ $labels.statefulset }} A StatefulSet does not match the expected number of replicas."
coredns.rules: |
groups:
- name: EmbeddedExporter
rules:
- alert: CorednsPanicCount
expr: 'increase(coredns_panics_total[1m]) > 0'
for: 0m
labels:
severity: critical
annotations:
summary: CoreDNS Panic Count (instance {{ $labels.instance }})
description: "Number of CoreDNS panics encountered\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
etcd.rules: |
groups:
- name: EmbeddedExporter
rules:
- alert: EtcdInsufficientMembers
expr: 'count(etcd_server_id) % 2 == 0'
for: 0m
labels:
severity: critical
annotations:
summary: Etcd insufficient Members (instance {{ $labels.instance }})
description: "Etcd cluster should have an odd number of members\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdNoLeader
expr: 'etcd_server_has_leader == 0'
for: 0m
labels:
severity: critical
annotations:
summary: Etcd no Leader (instance {{ $labels.instance }})
description: "Etcd cluster have no leader\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdHighNumberOfLeaderChanges
expr: 'increase(etcd_server_leader_changes_seen_total[10m]) > 2'
for: 0m
labels:
severity: warning
annotations:
summary: Etcd high number of leader changes (instance {{ $labels.instance }})
description: "Etcd leader changed more than 2 times during 10 minutes\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdHighNumberOfFailedGrpcRequests
expr: 'sum(rate(grpc_server_handled_total{grpc_code!="OK"}[1m])) BY (grpc_service, grpc_method) / sum(rate(grpc_server_handled_total[1m])) BY (grpc_service, grpc_method) > 0.01'
for: 2m
labels:
severity: warning
annotations:
summary: Etcd high number of failed GRPC requests (instance {{ $labels.instance }})
description: "More than 1% GRPC request failure detected in Etcd\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdHighNumberOfFailedGrpcRequests
expr: 'sum(rate(grpc_server_handled_total{grpc_code!="OK"}[1m])) BY (grpc_service, grpc_method) / sum(rate(grpc_server_handled_total[1m])) BY (grpc_service, grpc_method) > 0.05'
for: 2m
labels:
severity: critical
annotations:
summary: Etcd high number of failed GRPC requests (instance {{ $labels.instance }})
description: "More than 5% GRPC request failure detected in Etcd\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdGrpcRequestsSlow
expr: 'histogram_quantile(0.99, sum(rate(grpc_server_handling_seconds_bucket{grpc_type="unary"}[1m])) by (grpc_service, grpc_method, le)) > 0.15'
for: 2m
labels:
severity: warning
annotations:
summary: Etcd GRPC requests slow (instance {{ $labels.instance }})
description: "GRPC requests slowing down, 99th percentile is over 0.15s\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdHighNumberOfFailedHttpRequests
expr: 'sum(rate(etcd_http_failed_total[1m])) BY (method) / sum(rate(etcd_http_received_total[1m])) BY (method) > 0.01'
for: 2m
labels:
severity: warning
annotations:
summary: Etcd high number of failed HTTP requests (instance {{ $labels.instance }})
description: "More than 1% HTTP failure detected in Etcd\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdHighNumberOfFailedHttpRequests
expr: 'sum(rate(etcd_http_failed_total[1m])) BY (method) / sum(rate(etcd_http_received_total[1m])) BY (method) > 0.05'
for: 2m
labels:
severity: critical
annotations:
summary: Etcd high number of failed HTTP requests (instance {{ $labels.instance }})
description: "More than 5% HTTP failure detected in Etcd\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdHttpRequestsSlow
expr: 'histogram_quantile(0.99, rate(etcd_http_successful_duration_seconds_bucket[1m])) > 0.15'
for: 2m
labels:
severity: warning
annotations:
summary: Etcd HTTP requests slow (instance {{ $labels.instance }})
description: "HTTP requests slowing down, 99th percentile is over 0.15s\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdMemberCommunicationSlow
expr: 'histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[1m])) > 0.15'
for: 2m
labels:
severity: warning
annotations:
summary: Etcd member communication slow (instance {{ $labels.instance }})
description: "Etcd member communication slowing down, 99th percentile is over 0.15s\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdHighNumberOfFailedProposals
expr: 'increase(etcd_server_proposals_failed_total[1h]) > 5'
for: 2m
labels:
severity: warning
annotations:
summary: Etcd high number of failed proposals (instance {{ $labels.instance }})
description: "Etcd server got more than 5 failed proposals past hour\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdHighFsyncDurations
expr: 'histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket[1m])) > 0.5'
for: 2m
labels:
severity: warning
annotations:
summary: Etcd high fsync durations (instance {{ $labels.instance }})
description: "Etcd WAL fsync duration increasing, 99th percentile is over 0.5s\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: EtcdHighCommitDurations
expr: 'histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket[1m])) > 0.25'
for: 2m
labels:
severity: warning
annotations:
summary: Etcd high commit durations (instance {{ $labels.instance }})
description: "Etcd commit duration increasing, 99th percentile is over 0.25s\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
kubestate.rules: |
groups:
- name: KubestateExporter
rules:
- alert: KubernetesNodeNotReady
expr: 'kube_node_status_condition{condition="Ready",status="true"} == 0'
for: 10m
labels:
severity: critical
annotations:
summary: Kubernetes Node not ready (instance {{ $labels.instance }})
description: "Node {{ $labels.node }} has been unready for a long time\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesNodeMemoryPressure
expr: 'kube_node_status_condition{condition="MemoryPressure",status="true"} == 1'
for: 2m
labels:
severity: critical
annotations:
summary: Kubernetes Node memory pressure (instance {{ $labels.instance }})
description: "Node {{ $labels.node }} has MemoryPressure condition\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesNodeDiskPressure
expr: 'kube_node_status_condition{condition="DiskPressure",status="true"} == 1'
for: 2m
labels:
severity: critical
annotations:
summary: Kubernetes Node disk pressure (instance {{ $labels.instance }})
description: "Node {{ $labels.node }} has DiskPressure condition\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesNodeNetworkUnavailable
expr: 'kube_node_status_condition{condition="NetworkUnavailable",status="true"} == 1'
for: 2m
labels:
severity: critical
annotations:
summary: Kubernetes Node network unavailable (instance {{ $labels.instance }})
description: "Node {{ $labels.node }} has NetworkUnavailable condition\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesNodeOutOfPodCapacity
expr: 'sum by (node) ((kube_pod_status_phase{phase="Running"} == 1) + on(uid) group_left(node) (0 * kube_pod_info{pod_template_hash=""})) / sum by (node) (kube_node_status_allocatable{resource="pods"}) * 100 > 90'
for: 2m
labels:
severity: warning
annotations:
summary: Kubernetes Node out of pod capacity (instance {{ $labels.instance }})
description: "Node {{ $labels.node }} is out of pod capacity\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesContainerOomKiller
expr: '(kube_pod_container_status_restarts_total - kube_pod_container_status_restarts_total offset 10m >= 1) and ignoring (reason) min_over_time(kube_pod_container_status_last_terminated_reason{reason="OOMKilled"}[10m]) == 1'
for: 0m
labels:
severity: warning
annotations:
summary: Kubernetes Container oom killer (instance {{ $labels.instance }})
description: "Container {{ $labels.container }} in pod {{ $labels.namespace }}/{{ $labels.pod }} has been OOMKilled {{ $value }} times in the last 10 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesJobFailed
expr: 'kube_job_status_failed > 0'
for: 0m
labels:
severity: warning
annotations:
summary: Kubernetes Job failed (instance {{ $labels.instance }})
description: "Job {{ $labels.namespace }}/{{ $labels.job_name }} failed to complete\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesCronjobSuspended
expr: 'kube_cronjob_spec_suspend != 0'
for: 0m
labels:
severity: warning
annotations:
summary: Kubernetes CronJob suspended (instance {{ $labels.instance }})
description: "CronJob {{ $labels.namespace }}/{{ $labels.cronjob }} is suspended\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesPersistentvolumeclaimPending
expr: 'kube_persistentvolumeclaim_status_phase{phase="Pending"} == 1'
for: 2m
labels:
severity: warning
annotations:
summary: Kubernetes PersistentVolumeClaim pending (instance {{ $labels.instance }})
description: "PersistentVolumeClaim {{ $labels.namespace }}/{{ $labels.persistentvolumeclaim }} is pending\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesVolumeOutOfDiskSpace
expr: 'kubelet_volume_stats_available_bytes / kubelet_volume_stats_capacity_bytes * 100 < 10'
for: 2m
labels:
severity: warning
annotations:
summary: Kubernetes Volume out of disk space (instance {{ $labels.instance }})
description: "Volume is almost full (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesVolumeFullInFourDays
expr: 'predict_linear(kubelet_volume_stats_available_bytes[6h:5m], 4 * 24 * 3600) < 0'
for: 0m
labels:
severity: critical
annotations:
summary: Kubernetes Volume full in four days (instance {{ $labels.instance }})
description: "Volume under {{ $labels.namespace }}/{{ $labels.persistentvolumeclaim }} is expected to fill up within four days. Currently {{ $value | humanize }}% is available.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesPersistentvolumeError
expr: 'kube_persistentvolume_status_phase{phase=~"Failed|Pending", job="kube-state-metrics"} > 0'
for: 0m
labels:
severity: critical
annotations:
summary: Kubernetes PersistentVolume error (instance {{ $labels.instance }})
description: "Persistent volume {{ $labels.persistentvolume }} is in bad state\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesStatefulsetDown
expr: 'kube_statefulset_replicas != kube_statefulset_status_replicas_ready > 0'
for: 1m
labels:
severity: critical
annotations:
summary: Kubernetes StatefulSet down (instance {{ $labels.instance }})
description: "StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }} went down\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesHpaScaleInability
expr: 'kube_horizontalpodautoscaler_status_condition{status="false", condition="AbleToScale"} == 1'
for: 2m
labels:
severity: warning
annotations:
summary: Kubernetes HPA scale inability (instance {{ $labels.instance }})
description: "HPA {{ $labels.namespace }}/{{ $labels.horizontalpodautoscaler }} is unable to scale\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesHpaMetricsUnavailability
expr: 'kube_horizontalpodautoscaler_status_condition{status="false", condition="ScalingActive"} == 1'
for: 0m
labels:
severity: warning
annotations:
summary: Kubernetes HPA metrics unavailability (instance {{ $labels.instance }})
description: "HPA {{ $labels.namespace }}/{{ $labels.horizontalpodautoscaler }} is unable to collect metrics\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesHpaScaleMaximum
expr: 'kube_horizontalpodautoscaler_status_desired_replicas >= kube_horizontalpodautoscaler_spec_max_replicas'
for: 2m
labels:
severity: info
annotations:
summary: Kubernetes HPA scale maximum (instance {{ $labels.instance }})
description: "HPA {{ $labels.namespace }}/{{ $labels.horizontalpodautoscaler }} has hit maximum number of desired pods\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesHpaUnderutilized
expr: 'max(quantile_over_time(0.5, kube_horizontalpodautoscaler_status_desired_replicas[1d]) == kube_horizontalpodautoscaler_spec_min_replicas) by (horizontalpodautoscaler) > 3'
for: 0m
labels:
severity: info
annotations:
summary: Kubernetes HPA underutilized (instance {{ $labels.instance }})
description: "HPA {{ $labels.namespace }}/{{ $labels.horizontalpodautoscaler }} is constantly at minimum replicas for 50% of the time. Potential cost saving here.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesPodNotHealthy
expr: 'sum by (namespace, pod) (kube_pod_status_phase{phase=~"Pending|Unknown|Failed"}) > 0'
for: 15m
labels:
severity: critical
annotations:
summary: Kubernetes Pod not healthy (instance {{ $labels.instance }})
description: "Pod {{ $labels.namespace }}/{{ $labels.pod }} has been in a non-running state for longer than 15 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesPodCrashLooping
expr: 'increase(kube_pod_container_status_restarts_total[1m]) > 3'
for: 2m
labels:
severity: warning
annotations:
summary: Kubernetes pod crash looping (instance {{ $labels.instance }})
description: "Pod {{ $labels.namespace }}/{{ $labels.pod }} is crash looping\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesReplicasetReplicasMismatch
expr: 'kube_replicaset_spec_replicas != kube_replicaset_status_ready_replicas'
for: 10m
labels:
severity: warning
annotations:
summary: Kubernetes ReplicaSet replicas mismatch (instance {{ $labels.instance }})
description: "ReplicaSet {{ $labels.namespace }}/{{ $labels.replicaset }} replicas mismatch\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesDeploymentReplicasMismatch
expr: 'kube_deployment_spec_replicas != kube_deployment_status_replicas_available'
for: 10m
labels:
severity: warning
annotations:
summary: Kubernetes Deployment replicas mismatch (instance {{ $labels.instance }})
description: "Deployment {{ $labels.namespace }}/{{ $labels.deployment }} replicas mismatch\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesStatefulsetReplicasMismatch
expr: 'kube_statefulset_status_replicas_ready != kube_statefulset_status_replicas'
for: 10m
labels:
severity: warning
annotations:
summary: Kubernetes StatefulSet replicas mismatch (instance {{ $labels.instance }})
description: "StatefulSet does not match the expected number of replicas.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesDeploymentGenerationMismatch
expr: 'kube_deployment_status_observed_generation != kube_deployment_metadata_generation'
for: 10m
labels:
severity: critical
annotations:
summary: Kubernetes Deployment generation mismatch (instance {{ $labels.instance }})
description: "Deployment {{ $labels.namespace }}/{{ $labels.deployment }} has failed but has not been rolled back.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesStatefulsetGenerationMismatch
expr: 'kube_statefulset_status_observed_generation != kube_statefulset_metadata_generation'
for: 10m
labels:
severity: critical
annotations:
summary: Kubernetes StatefulSet generation mismatch (instance {{ $labels.instance }})
description: "StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }} has failed but has not been rolled back.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesStatefulsetUpdateNotRolledOut
expr: 'max without (revision) (kube_statefulset_status_current_revision unless kube_statefulset_status_update_revision) * (kube_statefulset_replicas != kube_statefulset_status_replicas_updated)'
for: 10m
labels:
severity: warning
annotations:
summary: Kubernetes StatefulSet update not rolled out (instance {{ $labels.instance }})
description: "StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }} update has not been rolled out.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesDaemonsetRolloutStuck
expr: 'kube_daemonset_status_number_ready / kube_daemonset_status_desired_number_scheduled * 100 < 100 or kube_daemonset_status_desired_number_scheduled - kube_daemonset_status_current_number_scheduled > 0'
for: 10m
labels:
severity: warning
annotations:
summary: Kubernetes DaemonSet rollout stuck (instance {{ $labels.instance }})
description: "Some Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} are not scheduled or not ready\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesDaemonsetMisscheduled
expr: 'kube_daemonset_status_number_misscheduled > 0'
for: 1m
labels:
severity: critical
annotations:
summary: Kubernetes DaemonSet misscheduled (instance {{ $labels.instance }})
description: "Some Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} are running where they are not supposed to run\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesCronjobTooLong
expr: 'time() - kube_cronjob_next_schedule_time > 3600'
for: 0m
labels:
severity: warning
annotations:
summary: Kubernetes CronJob too long (instance {{ $labels.instance }})
description: "CronJob {{ $labels.namespace }}/{{ $labels.cronjob }} is taking more than 1h to complete.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesJobSlowCompletion
expr: 'kube_job_spec_completions - kube_job_status_succeeded - kube_job_status_failed > 0'
for: 12h
labels:
severity: critical
annotations:
summary: Kubernetes Job slow completion (instance {{ $labels.instance }})
description: "Kubernetes Job {{ $labels.namespace }}/{{ $labels.job_name }} did not complete in time.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesApiServerErrors
expr: 'sum(rate(apiserver_request_total{job="apiserver",code=~"^(?:5..)$"}[1m])) / sum(rate(apiserver_request_total{job="apiserver"}[1m])) * 100 > 3'
for: 2m
labels:
severity: critical
annotations:
summary: Kubernetes API server errors (instance {{ $labels.instance }})
description: "Kubernetes API server is experiencing high error rate\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesApiClientErrors
expr: '(sum(rate(rest_client_requests_total{code=~"(4|5).."}[1m])) by (instance, job) / sum(rate(rest_client_requests_total[1m])) by (instance, job)) * 100 > 1'
for: 2m
labels:
severity: critical
annotations:
summary: Kubernetes API client errors (instance {{ $labels.instance }})
description: "Kubernetes API client is experiencing high error rate\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesClientCertificateExpiresNextWeek
expr: 'apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0 and histogram_quantile(0.01, sum by (job, le) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 7*24*60*60'
for: 0m
labels:
severity: warning
annotations:
summary: Kubernetes client certificate expires next week (instance {{ $labels.instance }})
description: "A client certificate used to authenticate to the apiserver is expiring next week.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesClientCertificateExpiresSoon
expr: 'apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0 and histogram_quantile(0.01, sum by (job, le) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 24*60*60'
for: 0m
labels:
severity: critical
annotations:
summary: Kubernetes client certificate expires soon (instance {{ $labels.instance }})
description: "A client certificate used to authenticate to the apiserver is expiring in less than 24.0 hours.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: KubernetesApiServerLatency
expr: 'histogram_quantile(0.99, sum(rate(apiserver_request_latencies_bucket{subresource!="log",verb!~"^(?:CONNECT|WATCHLIST|WATCH|PROXY)$"} [10m])) WITHOUT (instance, resource)) / 1e+06 > 1'
for: 2m
labels:
severity: warning
annotations:
summary: Kubernetes API server latency (instance {{ $labels.instance }})
description: "Kubernetes API server has a 99th percentile latency of {{ $value }} seconds for {{ $labels.verb }} {{ $labels.resource }}.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
mysql.rules: |
groups:
- name: MysqldExporter
rules:
- alert: MysqlDown
expr: 'mysql_up == 0'
for: 0m
labels:
severity: critical
annotations:
summary: MySQL down (instance {{ $labels.instance }})
description: "MySQL instance is down on {{ $labels.instance }}\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: MysqlTooManyConnections(>80%)
expr: 'max_over_time(mysql_global_status_threads_connected[1m]) / mysql_global_variables_max_connections * 100 > 80'
for: 2m
labels:
severity: warning
annotations:
summary: MySQL too many connections (> 80%) (instance {{ $labels.instance }})
description: "More than 80% of MySQL connections are in use on {{ $labels.instance }}\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: MysqlHighThreadsRunning
expr: 'max_over_time(mysql_global_status_threads_running[1m]) / mysql_global_variables_max_connections * 100 > 60'
for: 2m
labels:
severity: warning
annotations:
summary: MySQL high threads running (instance {{ $labels.instance }})
description: "More than 60% of MySQL connections are in running state on {{ $labels.instance }}\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: MysqlSlaveIoThreadNotRunning
expr: '( mysql_slave_status_slave_io_running and ON (instance) mysql_slave_status_master_server_id > 0 ) == 0'
for: 0m
labels:
severity: critical
annotations:
summary: MySQL Slave IO thread not running (instance {{ $labels.instance }})
description: "MySQL Slave IO thread not running on {{ $labels.instance }}\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: MysqlSlaveSqlThreadNotRunning
expr: '( mysql_slave_status_slave_sql_running and ON (instance) mysql_slave_status_master_server_id > 0) == 0'
for: 0m
labels:
severity: critical
annotations:
summary: MySQL Slave SQL thread not running (instance {{ $labels.instance }})
description: "MySQL Slave SQL thread not running on {{ $labels.instance }}\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: MysqlSlaveReplicationLag
expr: '( (mysql_slave_status_seconds_behind_master - mysql_slave_status_sql_delay) and ON (instance) mysql_slave_status_master_server_id > 0 ) > 30'
for: 1m
labels:
severity: critical
annotations:
summary: MySQL Slave replication lag (instance {{ $labels.instance }})
description: "MySQL replication lag on {{ $labels.instance }}\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: MysqlSlowQueries
expr: 'increase(mysql_global_status_slow_queries[1m]) > 0'
for: 2m
labels:
severity: warning
annotations:
summary: MySQL slow queries (instance {{ $labels.instance }})
description: "MySQL server mysql has some new slow query.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: MysqlInnodbLogWaits
expr: 'rate(mysql_global_status_innodb_log_waits[15m]) > 10'
for: 0m
labels:
severity: warning
annotations:
summary: MySQL InnoDB log waits (instance {{ $labels.instance }})
description: "MySQL innodb log writes stalling\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: MysqlRestarted
expr: 'mysql_global_status_uptime < 60'
for: 0m
labels:
severity: info
annotations:
summary: MySQL restarted (instance {{ $labels.instance }})
description: "MySQL has just been restarted, less than one minute ago on {{ $labels.instance }}.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: prometheus-vs
spec:
hosts:
- "p.cctest"
gateways:
- cc-gw
http:
- match:
- uri:
prefix: /
route:
- destination:
port:
number: 9090
host: prometheus.monitor.svc.cluster.local
---
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor
labels:
k8s-app: prometheus
spec:
type: ClusterIP
ports:
- name: http
port: 9090
targetPort: 9090
selector:
k8s-app: prometheus
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitor
labels:
k8s-app: prometheus
spec:
replicas: 1
selector:
matchLabels:
k8s-app: prometheus
template:
metadata:
labels:
k8s-app: prometheus
spec:
serviceAccountName: super-user
containers:
- name: prometheus
image: prom/prometheus:v2.36.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 9090
securityContext:
runAsUser: 65534
privileged: true
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--web.enable-lifecycle"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention.time=10d"
- "--web.console.libraries=/etc/prometheus/console_libraries"
- "--web.console.templates=/etc/prometheus/consoles"
resources:
limits:
cpu: 2000m
memory: 2048Mi
requests:
cpu: 1000m
memory: 512Mi
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 5
timeoutSeconds: 10
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: data
mountPath: /prometheus
subPath: prometheus
- name: config
mountPath: /etc/prometheus
- name: prometheus-rules
mountPath: /etc/prometheus/rules
- name: configmap-reload
image: jimmidyson/configmap-reload:v0.5.0
imagePullPolicy: IfNotPresent
args:
- "--volume-dir=/etc/config"
- "--webhook-url=http://localhost:9090/-/reload"
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 10m
memory: 10Mi
volumeMounts:
- name: config
mountPath: /etc/config
readOnly: true
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus-data-pvc
- name: prometheus-rules
configMap:
name: prometheus-rules
- name: config
configMap:
name: prometheus-config
AlertManager
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: monitor
data:
alertmanager.yml: |-
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:25' # 邮箱服务器的SMTP主机配置
smtp_from: 'laoyang1df@163.com' # 发件人
smtp_auth_username: 'laoyang1df@163.com' # 登录用户名
smtp_auth_password: 'ZGYMAPQJDEYOZFVD' # 此处的auth password是邮箱的第三方登录授权密码,而非用户密码
smtp_require_tls: false # 有些邮箱需要开启此配置,这里使用的是企微邮箱,仅做测试,不需要开启此功能。
templates:
- '/etc/alertmanager/*.tmpl'
route:
group_by: ['env','instance','type','group','job','alertname','cluster'] # 报警分组
group_wait: 5s # 在组内等待所配置的时间,如果同组内,5秒内出现相同报警,在一个组内出现。
group_interval: 1m # 如果组内内容不变化,合并为一条警报信息,2m后发送。
repeat_interval: 2m # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
receiver: 'email'
routes:
- receiver: 'devops'
match:
severity: critical22
group_wait: 5s
group_interval: 5m
repeat_interval: 30m
receivers:
- name: 'email'
email_configs:
- to: '553069938@qq.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
- name: 'devops'
email_configs:
- to: '553069938@qq.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
inhibit_rules: # 抑制规则
- source_match: # 源标签警报触发时抑制含有目标标签的警报,在当前警报匹配 servrity: 'critical'
severity: 'critical'
target_match:
severity: 'warning' # 目标标签值正则匹配,可以是正则表达式如: ".*MySQL.*"
equal: ['alertname', 'dev', 'instance'] # 确保这个配置下的标签内容相同才会抑制,也就是说警报中必须有这三个标签值才会被抑制。
wechat.tmpl: |-
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 告警恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
email.tmpl: |-
{{ define "email.from" }}xxx.com{{ end }}
{{ define "email.to" }}xxx.com{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{ range .Alerts }}
========= 监控报警 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{ range .Alerts }}
========= 告警恢复 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- end }}
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: monitor
labels:
k8s-app: alertmanager
spec:
type: ClusterIP
ports:
- name: http
port: 9093
targetPort: 9093
selector:
k8s-app: alertmanager
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitor
labels:
k8s-app: alertmanager
spec:
replicas: 1
selector:
matchLabels:
k8s-app: alertmanager
template:
metadata:
labels:
k8s-app: alertmanager
spec:
containers:
- name: alertmanager
image: prom/alertmanager:v0.24.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 9093
args:
## 指定容器中AlertManager配置文件存放地址 (Docker容器中的绝对位置)
- "--config.file=/etc/alertmanager/alertmanager.yml"
## 指定AlertManager管理界面地址,用于在发生的告警信息中,附加AlertManager告警信息页面地址
- "--web.external-url=https://alert.jxit.net.cn"
## 指定监听的地址及端口
- '--cluster.advertise-address=0.0.0.0:9093'
## 指定数据存储位置 (Docker容器中的绝对位置)
- "--storage.path=/alertmanager"
resources:
limits:
cpu: 1000m
memory: 512Mi
requests:
cpu: 1000m
memory: 512Mi
readinessProbe:
httpGet:
path: /-/ready
port: 9093
initialDelaySeconds: 5
timeoutSeconds: 10
livenessProbe:
httpGet:
path: /-/healthy
port: 9093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: data
mountPath: /alertmanager
- name: config
mountPath: /etc/alertmanager
- name: configmap-reload
image: jimmidyson/configmap-reload:v0.7.1
args:
- "--volume-dir=/etc/config"
- "--webhook-url=http://localhost:9093/-/reload"
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/config
readOnly: true
volumes:
- name: data
persistentVolumeClaim:
claimName: alertmanager-pvc
- name: config
configMap:
name: alertmanager-config
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: monitor
name: alertmanager-ingress
spec:
ingressClassName: nginx
rules:
- host: alert.jxit.net.cn
http:
paths:
- pathType: Prefix
backend:
service:
name: alertmanager
port:
number: 9093
path: /
Grafana pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-data-pvc
namespace: monitor
spec:
accessModes:
- ReadWriteMany
storageClassName: "data-nfs-storage"
resources:
requests:
storage: 10Gi
Grafana
apiVersion: v1
kind: ConfigMap
metadata:
name: grafana-config
namespace: monitor
data:
grafana.ini: |
[server]
root_url = http://grafana.kubernets.cn
[smtp]
enabled = false
host = smtp.exmail.qq.com:465
user = devops@xxxx.com
password = aDhUcxxxxyecE
skip_verify = true
from_address = devops@xxxx.com
[alerting]
enabled = false
execute_alerts = false
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitor
labels:
app: grafana
component: core
spec:
type: ClusterIP
ports:
- port: 3000
selector:
app: grafana
component: core
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-core
namespace: monitor
labels:
app: grafana
component: core
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
component: core
spec:
containers:
- name: grafana-core
image: grafana/grafana:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- name: storage
subPath: grafana
mountPath: /var/lib/grafana
# env:
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 500m
memory: 1Gi
requests:
cpu: 100m
memory: 500Mi
env: #配置环境变量,设置Grafana 的默认管理员用户名/密码
# The following env variables set up basic auth twith the default admin user and admin password.
- name: GF_AUTH_BASIC_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "false"
# - name: GF_AUTH_ANONYMOUS_ORG_ROLE
# value: Admin
# does not really work, because of template variables in exported dashboards:
# - name: GF_DASHBOARDS_JSON_ENABLED
# value: "true"
readinessProbe:
httpGet:
path: /login
port: 3000
# initialDelaySeconds: 30
# timeoutSeconds: 1
volumeMounts:
- name: data
subPath: grafana
mountPath: /var/lib/grafana
- name: grafana-config
mountPath: /etc/grafana
readOnly: true
securityContext: #容器安全策略,设置运行容器使用的归属组与用户
fsGroup: 472
runAsUser: 472
volumes:
- name: data
persistentVolumeClaim:
claimName: grafana-data-pvc
- name: grafana-config
configMap:
name: grafana-config
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: prometheus-vs
spec:
hosts:
- "g.cc-test"
gateways:
- cctest-gw
http:
- match:
- uri:
prefix: /
route:
- destination:
port:
number: 3000
host: grafana.monitor.svc.cluster.local
---
这些yaml文件其实已经做好了一些基本组件的监控 但是如果要监控外部比如mysql
举个例子吧
监控mysql
我们用独立部署exporter方式来做监控 避免对k8s侵入过多
# 下载
curl http://stu.jxit.net.cn:88/k8s/mysqld_exporter-0.14.0.linux-amd64.tar.gz -o a.tar.gz
# 解压
tar -xvf a.tar.gz
创建mysql监控账号
CREATE USER 'exporter'@'<安装Prometheus的主机IP>' IDENTIFIED BY '<your password>';
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'<安装Prometheus的主机IP>';
flush privileges;
my.cnf
cat <<E0F>> my.cnf
[client]
host = xxxx
port = xxxx
user = xxxxx
password= xxxx
启动mysql exporter
nohup ./mysqld_exporter --config.my-cnf=my.cnf &
最后在grafana的web界面中 点击import 输入 15757 15759 对应的k8s基本信息监控 和节点基本信息监控
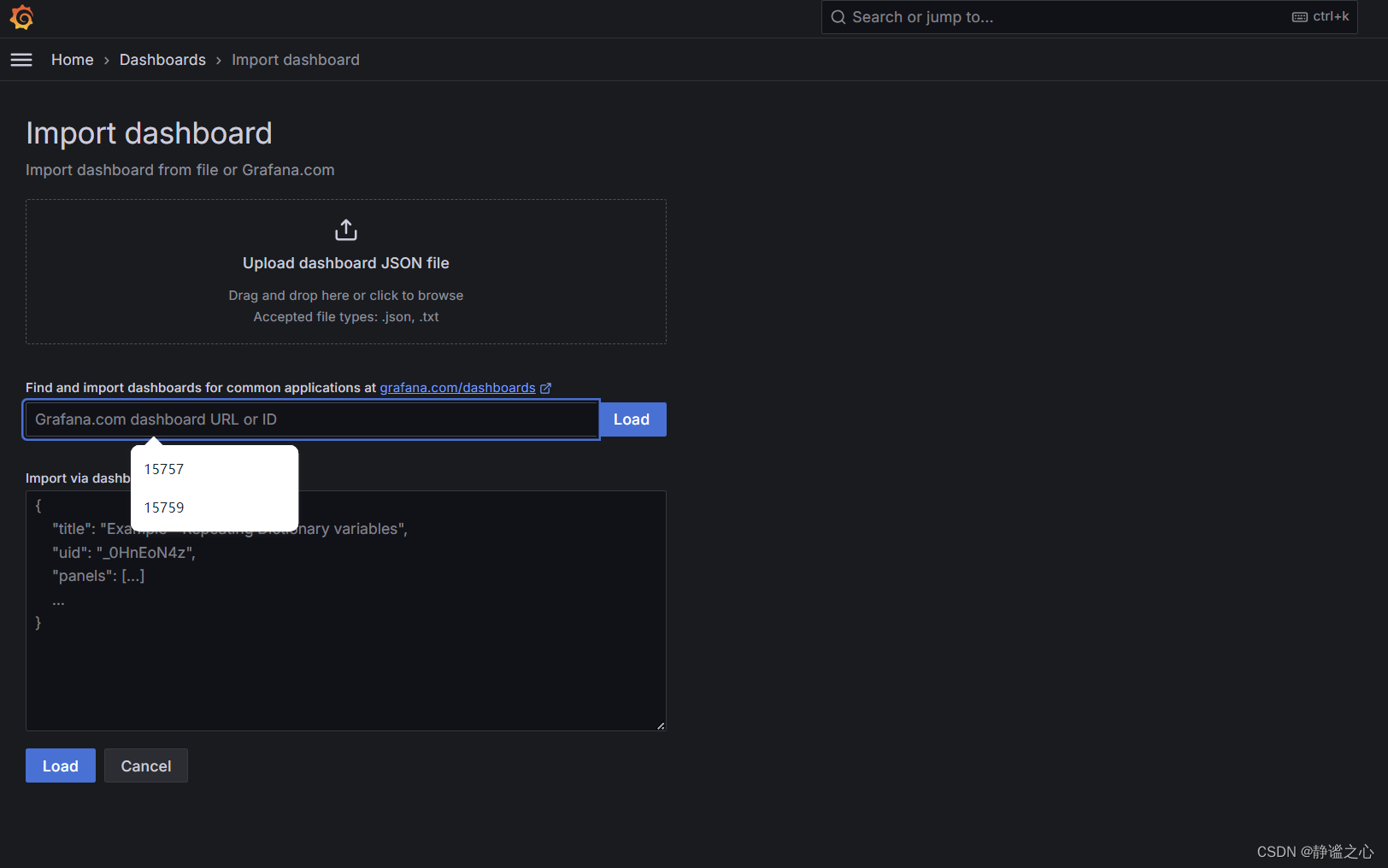
效果如下
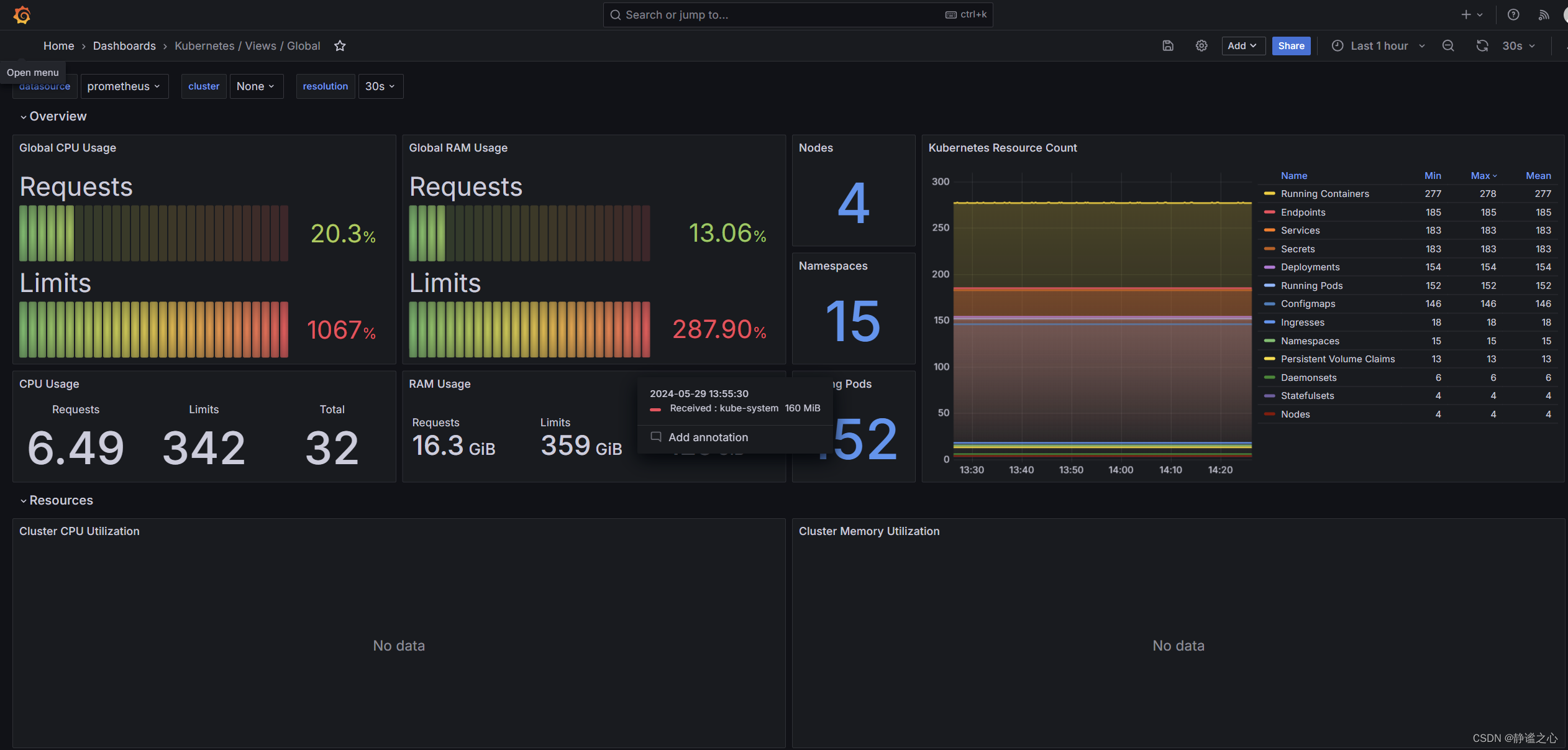
最后想说一句话
不要局限于组件本身 比如这一套组件
要目标导向的去找组件 比如我想监控什么metric