文章目录
树
概念及结构
二叉树
概念及结构
特殊的二叉树
完全二叉树
满二叉树
性质
储存
顺序存储
链式储存
堆
概念及结构
小堆
大堆
建堆
向上调整建堆
向下调整建堆
TOPK问题
法一:
法二:
树
概念及结构
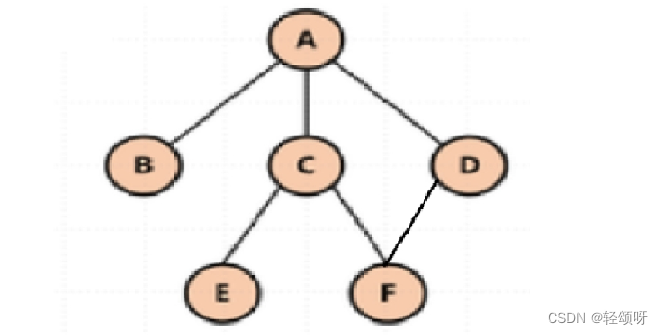
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树。
- 树的第一个结点被称为根结点。
- 除根结点外,其余结点被分成M(M>0)个互不相交的集合T1、T2.....、Tm,其中每一个集合Ti(1<=i<=m)又是一颗结构与树类似的子树。所以树是用递归定义的。
下面是树的常见相关概念
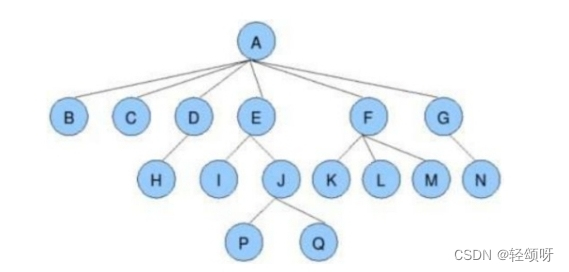
- 度:一个结点含有的子树的个数称为该结点的度。如上图:A的度为6。
- 叶结点:度为0的节点称为叶结点。如上图:P是叶结点。
- 子结点:一个结点含有的子树的根结点称为该结点的子结点。如上图:B是A的子结点。
- 父结点:若一个结点含有子结点,则这个结点称为父结点。如上图:A是B的父结点。
- 树的高度或深度:树中节点的最大层次。如上图:该树的高度是4。
注意:子树之间不能有交集(F只能有一个父结点)。
二叉树
概念及结构
二叉树是一种特殊的树,其特点是每个结点最多只能有两棵子树,且有左右之分。所以二叉树是有序树。
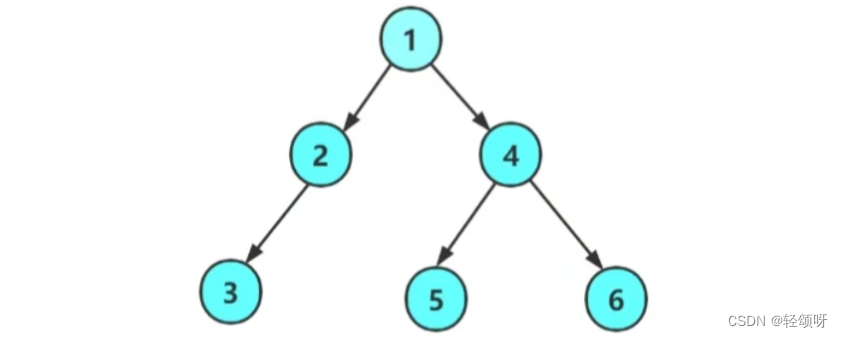
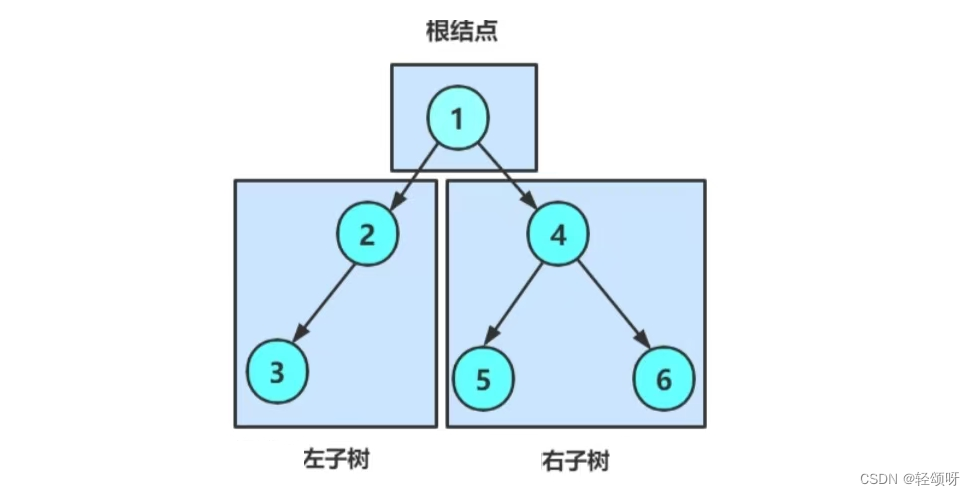
一般称左边的树为左子树,右边为右子树最上边的结点是根结点。
特殊的二叉树
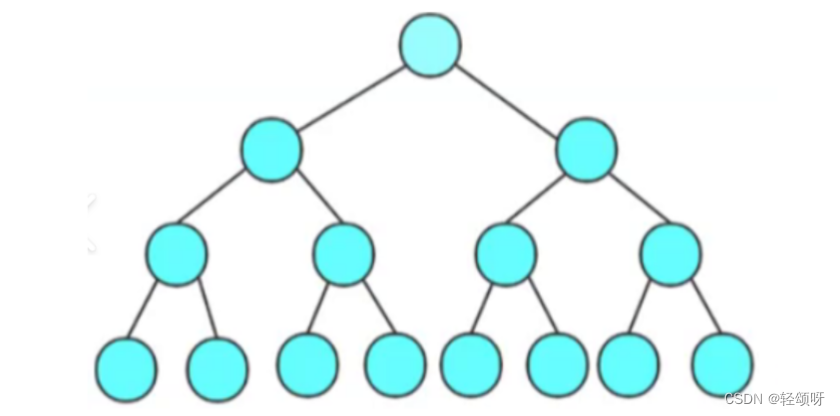
完全二叉树
假设该树有h层,则前h-1层的结点数都达到了最大,第h层结点连续集中在左边。
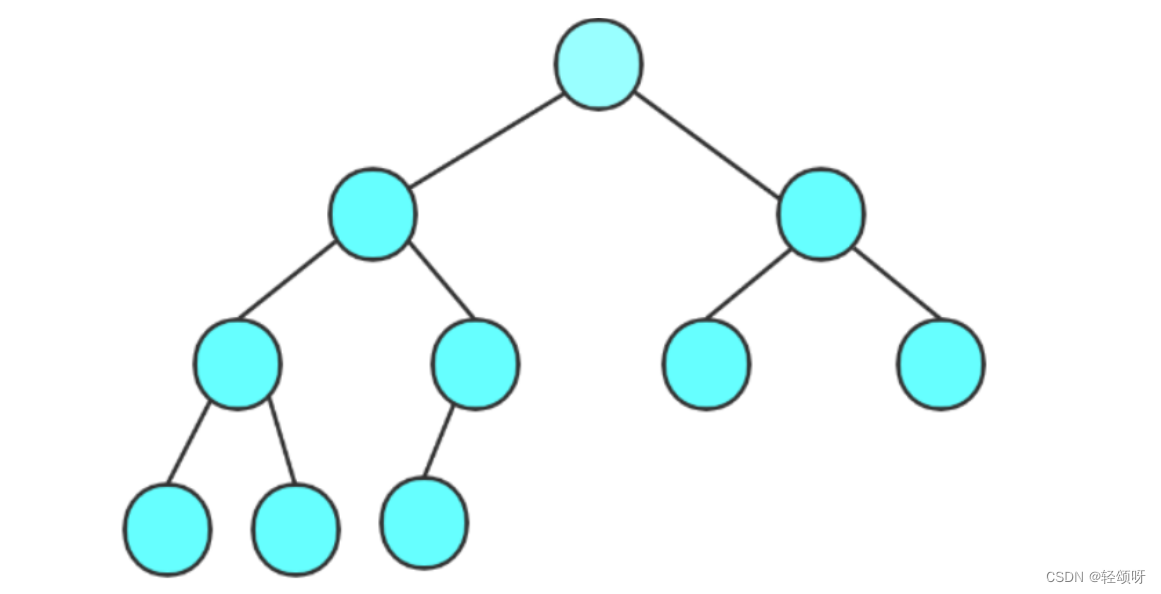
满二叉树
如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。
满二叉树是属于完全二叉树的。
性质
1.若规定根结点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1)个结点。
2. 若规定根结点的层数为1,则深度为h的二叉树的最大结点数是 2^h-1。
3. 对任何一棵二叉树, 如果度为0其叶结点个数为N0 , 度为2的分支结点个数为N2 ,则有N0 = N2+1。
4. 若规定根结点的层数为1,具有n个结点的满二叉树的深度,h= log2(n+1)。(log以2为底,n+1为对数)
5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有结点从0开始编号,则对于下标i的结点有:
(1)若i>0,i位置结点的父结点序号:(i-1)/2;若i=0,i为根结点无父结点。
(2)若2*i+1<n,左孩子序号:2i+1,若2*i+1>=n否则无左孩子。
(3)若2*i+2<n,右孩子序号:2i+2,若2*i+2>=n否则无右孩子。
储存
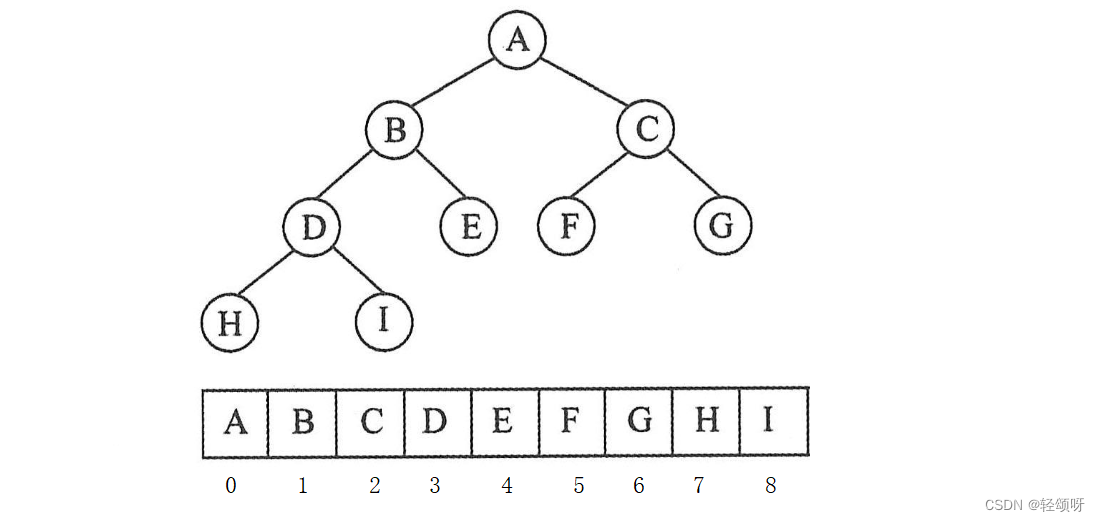
顺序存储
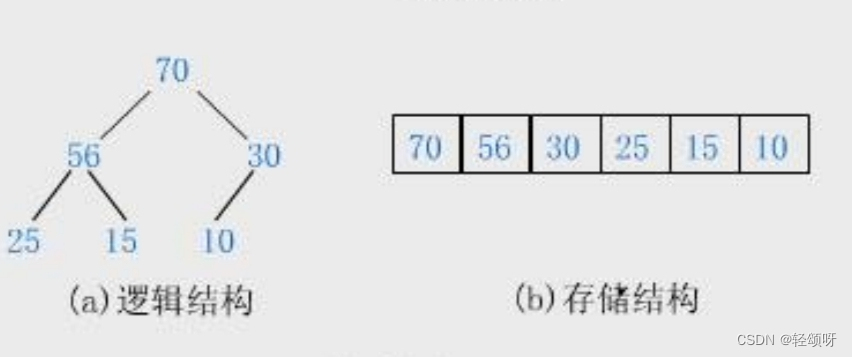
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。
在物理上是数组,在逻辑上是二叉树。
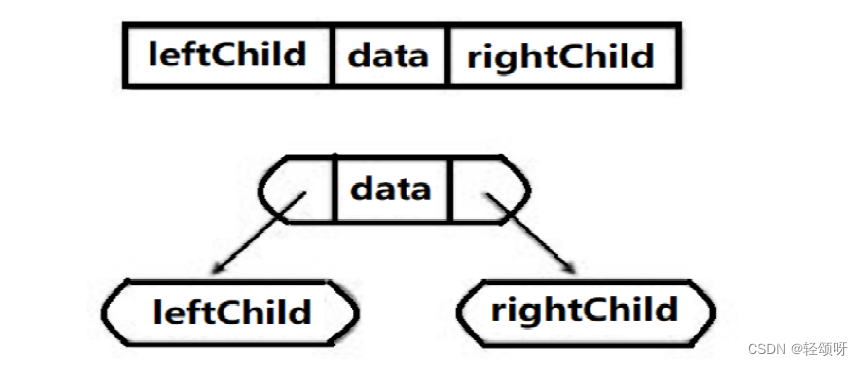
链式储存
链式结构存储就是用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。每个结点通常有三个域,数据域和左右指针域。
堆
概念及结构
堆是一种特殊的树形数据结构,通常表现为一棵完全二叉树,是用二叉树的顺序存储方式来存储元素的。
堆分为小堆和大堆
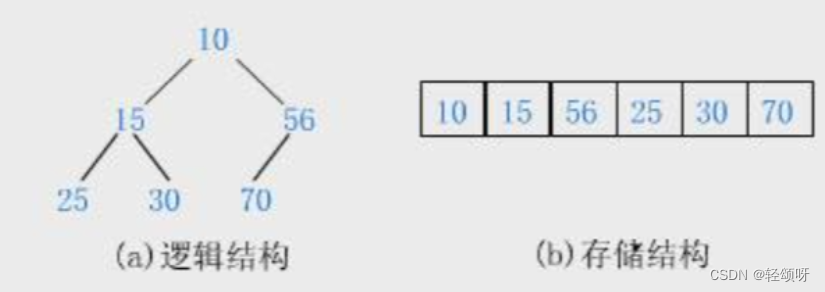
小堆
父结点小于子结点,但是父结点下面的两个子结点没大小区分。
大堆
父结点大于子结点,但是父结点下面的两个子结点没大小区分。
建堆
以下均为建小堆
向上调整建堆
适用于一边插入一边建堆的情况。
找到该孩子的父结点(利用上面性质5),在让父结点与它进行比较如果小于它则退出,如果大于则交换位置,重复上述操作直至循环结束或跳出循环。
void AdjustUp(int* arr, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] < arr[parent])//将<改为>即建大堆
{
Swap(&arr[child], &arr[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}注:Swap是交换位置函数。
void Swap(int* p1, int* p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}向下调整建堆
适用于对根节点进行调整。
找到它的两孩子中小的那个,在让这个小的孩子与它进行比较如果孩子大于它则退出,如果小于则交换位置,重复上述操作直至循环结束或跳出循环。
void AdjustDown(int* arr, int n, int parent)
{
int child = (parent * 2) + 1;
while (child < n)
{
if (child + 1 < n && arr[child + 1] < arr[child])//child + 1 < n防止非法访问,将后面的<改为>即建大堆
{
child++;
}
if (arr[parent] > arr[child])//将<改为>即建大堆
{
Swap(&arr[parent], &arr[child]);
parent = child;
child = (parent * 2) + 1;
}
else
break;
}
}
//以上两个大小号均需要更改才能是建大堆TOPK问题
TOPK问题:即求数据结合中前K个最大的元素或者最小的元素。一般来说数据量比较大。
如果有一个数组,数组里有N个数据,我们要找最大的前K个数据,要怎么做呢?
找最大的前K个元素建大堆。
找最小的前K个元素建小堆。
法一:
先建一个大堆,然后让第一个结点的数据与最后一个结点交换,拿出最后的那个结点,然后再让根结点向下调整。重复上述操作K次。
void Heapsort(int* a, int n)
{
int k = 0;
scanf("%d", &k);
for (int i = 0; i < n; i++)
{
AdjustUp(a, i);
}
while (k--)
{
Swap(&a[n - 1], &a[0]);
AdjustDown(a, n - 1, 0);
n--;
}
}搞完后,数值大的数据都在数组的后面。我在这里没有拿出来。
法二:
先建一个K个数据的小堆,然后让后面的N-K个数据跟该小堆的根结点进行比较,如果大于则进行交换,然后向下调整。最后拿出该堆即可。
void Heapsort(int* a, int n)
{
int k = 0;
scanf("%d", &k);
for (int i = (k - 2) / 2; i >= 0; i--)
{
AdjustDown(a, k, i);
}
for (int i = k; i < n; i++)
{
if (a[i] > a[0])
{
Swap(&a[i], &a[0]);
AdjustDown(a, k, 0);
}
}
}大家应该注意到了哈,这次建堆的方式有点不一样,这是先找到树的最后一个根结点(画四角星的是树的最后一个根结点)
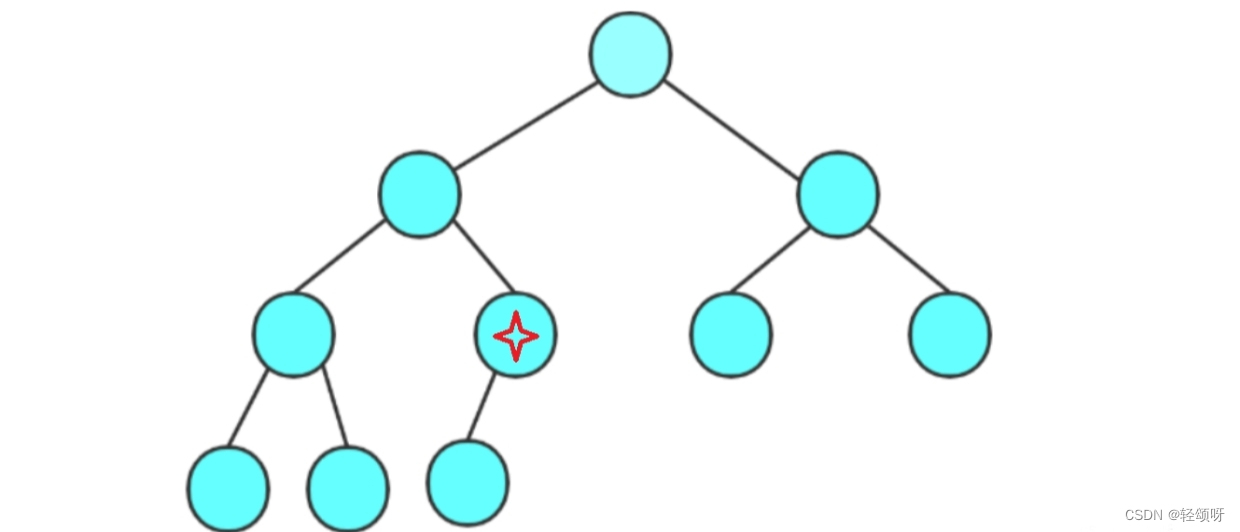
然后向下调整建堆,然后遍历最后一个根结点之前的结点建堆。使用这种方式建堆会更方便时间复杂度为N,使用上面建堆方式时间复杂度是NlogN。
总的来说法二要比法一要更优,因为当数据比较多时法一把所有的数据建堆就有点浪费时间了。
在下篇中我会介绍二叉树的链式结构实现。