1、项目背景
在当前的IT运维环境中,我们的业务系统日益复杂,特别是针对特定的业务逻辑和定制化需求,传统的通用监控工具往往难以覆盖所有的监控场景。例如,考虑到一个复杂的电商平台,除了基础的服务器性能、网络状况等基础设施监控外,我们还迫切需要对特定业务指标进行监控,比如DNS解析成功率、API响应延迟、特定业务流程的错误率等,这些都是直接影响用户体验和业务连续性的关键因素。
面对这样的需求,虽然Prometheus官方提供了一系列标准的Exporter,如node_exporter和snmp_exporter,它们在基础监控层面表现优秀,但对于上述提到的业务逻辑相关的监控需求却鞭长莫及。为了弥补这一空白,我们需要自定义一个专为业务定制的Prometheus Exporter,以实现对这些特定业务指标的精准监控。
为此,我们选择使用Go语言(Golang)来编写这个Exporter,原因在于Go语言天生对并发友好,适合编写高性能的网络服务,且官方提供了成熟的Prometheus客户端库,便于快速集成和开发
下面的代码地址:https://github.com/nangongchengfeng/Prometheus-Go-Template
2、开发环境搭建
-
安装Go语言:确保机器上安装了Go语言(1.20版本以上)并配置了GOPATH。
curl -L https://go.dev/dl/go1.21.3.linux-amd64.tar.gz -o ./go-linux-amd64.tar.gz 解压 sudo tar -zxvf go-linux-amd64.tar.gz -C /usr/local/lib/ 下面语句是给所有用户创建环境变量 # 下面内容需要多行复制 sudo tee -a ~/.bashrc << EOF export GOROOT=/usr/local/lib/go/ export GOPATH=/home/${USER}/sdk/go export PATH=\$PATH:\$GOROOT/bin:\$GOPATH/bin EOF # 单行 source ~/.bashrc -
下载Prometheus包:通过
go get命令下载client_golang包。go get github.com/prometheus/client_golang/prometheus go get github.com/prometheus/client_golang/prometheus/promhttp -
开启Go模块代理
go env -w GO111MODULE=on go env -w GOPROXY=https://goproxy.cn,direct 如果不行,请修改 如下设置: set GOPRIVATE=gitlab.xx.com set GOPROXY=https://goproxy.cn set GONOPROXY=gitlab.xx.com set GONOSUMDB=gitlab.xx.com
3、编写Exporter基础代码
- 创建HTTP服务:使用Go的
http模块创建一个服务,指定/metrics路径,并使用promhttp.Handler()作为处理器。 - 启动服务:通过
http.ListenAndServe启动HTTP服务监听8080端口。
package main
import (
"log"
"net/http"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(":8080", nil))
}
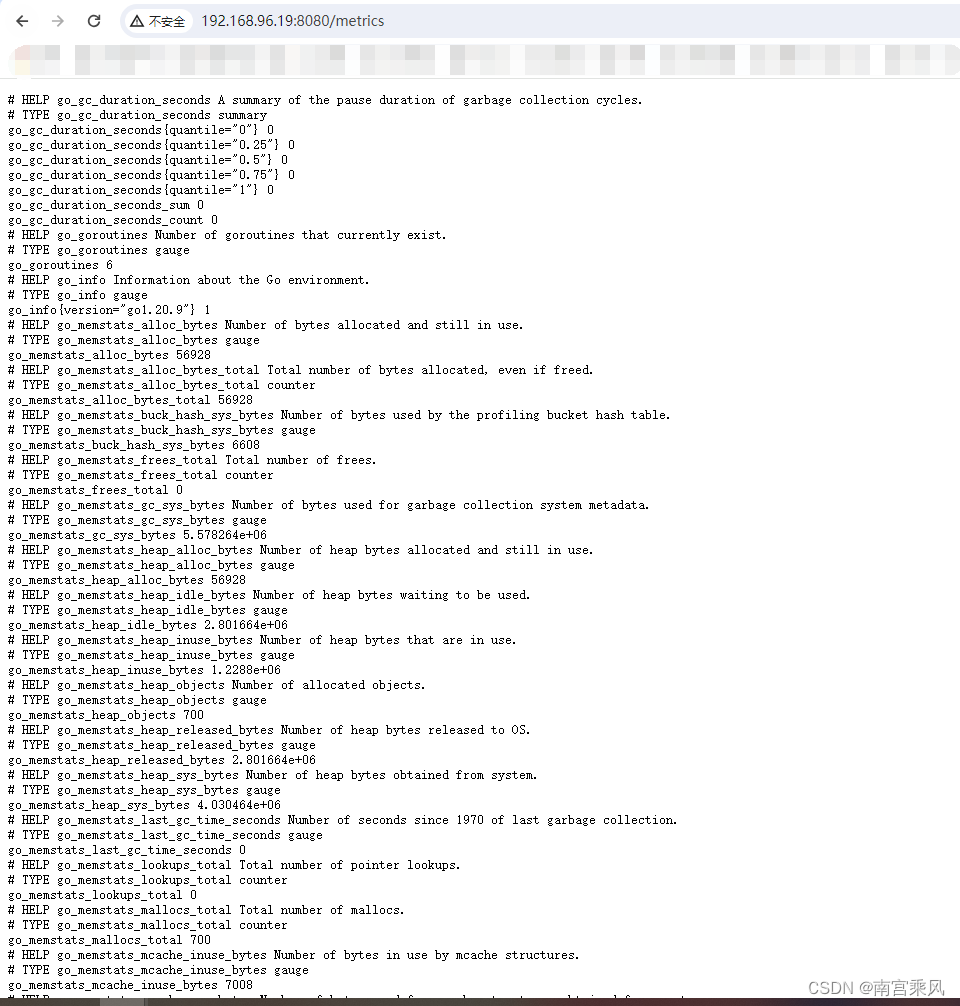
访问:ip+端口:/metrics 会出现如下页面,Go模块自带的监控项,仅仅展示了一个默认的采集器,并且通过接口调用隐藏了太多实施细节
4、理解Prometheus指标
-
指标类型:Prometheus支持四种主要的指标类型:
- Counter(累加指标)
- Gauge(测量指标)
- Summary(概略图)
- Histogram(直方图)
1. Counter(累加指标)
什么是Counter?
- Counter是一种只能增加的指标。它用来记录一些只会累加的数值,例如处理的请求数量、完成的任务数量等。
通俗解释:
- 想象一个只能加法不能减法的计数器。每当你完成一个任务,就按一次加号,这个数字会一直增加,不会减少。
例子:
- 记录一个网站的访问次数,每次有新的访问时,计数器增加1。
2. Gauge(测量指标)
什么是Gauge?
- Gauge是一种可以任意增减的指标。它用来记录一些瞬时的数值,例如当前的温度、CPU使用率等。
通俗解释:
- 想象一个温度计,温度可以升高也可以降低。它反映的是当前的状态,而不是累积的数值。
例子:
- 记录服务器当前的内存使用量,这个数值会随着时间的推移而增加或减少。
3. Summary(概略图)
什么是Summary?
- Summary是一种用来记录一系列数值的分布情况的指标。它会统计这些数值的分位数(例如中位数、90%分位数等)。
通俗解释:
- 想象你有一堆考试成绩,你想知道这些成绩的中位数是多少,90%的成绩在哪个分数以上。这种指标会帮助你了解一组数据的分布情况。
例子:
- 记录API响应时间,通过Summary可以知道大多数请求的响应时间情况,比如中位数响应时间、90%请求的响应时间等。
4. Histogram(直方图)
什么是Histogram?
- Histogram也是一种记录数值分布的指标,但它会把数值划分到不同的区间(桶)中,统计每个区间的数量。
通俗解释:
- 想象你有一堆不同高度的孩子,你把他们分成不同的身高区间,比如1米到1米1,1米1到1米2等,然后统计每个区间有多少孩子。Histogram会帮助你知道数据在不同区间的分布情况。
例子:
- 记录API响应时间,通过Histogram可以知道不同响应时间范围内的请求数量,比如0到100ms有多少请求,100到200ms有多少请求等。
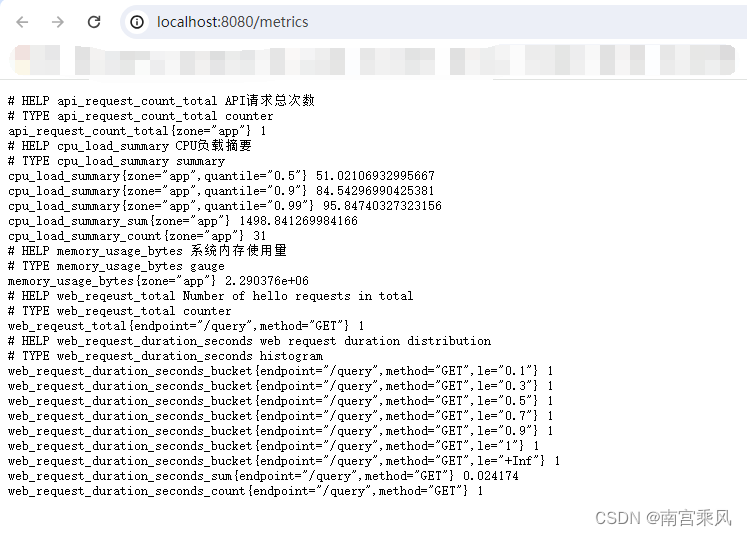
可以理解为柱状图,典型的应用如:请求持续时间,响应大小。可以对观察结果采样,分组及统计。例如设置一个name为web_request_duration_seconds的Histogram 的metrics,并设置区间值为[0.1,0.5,1]会对区间点生成一条统计数据.
# 响应时间小于0.1s的请求有5次
web_request_duration_seconds_bucket{endpoint="/query",method="GET",le="0.1"} 3
# 响应时间小于0.5s的请求有次
web_request_duration_seconds_bucket{endpoint="/query",method="GET",le="0.5"} 5
# 响应时间小于1s的请求有7次
web_request_duration_seconds_bucket{endpoint="/query",method="GET",le="1"} 7
# 总共7次请求
web_request_duration_seconds_bucket{endpoint="/query",method="GET",le="+Inf"} 7
# 7次请求duration的总和
web_request_duration_seconds_sum{endpoint="/query",method="GET"} 2.7190880529999997
5. Summary 和 Histogram 的区别
在使用 Prometheus 进行监控时,Summary 和 Histogram 都是用于测量和分析数据分布的强大工具,但它们在细节和应用场景上有所不同。下面将从两者的定义、使用场景和特点来详细阐述它们的区别。
Summary
Summary 用于提供一组数据的概述信息,它能够计算数据的分位数(例如中位数、90%分位数等)。这种指标特别适合需要了解整体数据分布情况但不需要精细区间划分的场景。
特点:
- 分位数计算:可以直接计算出指定分位数,例如中位数、90%分位数等。
- 适合样本量大时:当你需要了解大量请求的整体响应时间分布时,Summary 是非常有用的工具。
- 无需预定义桶:Summary 通过算法动态计算分位数,而无需提前划分数据区间(桶)。
使用场景:
- API 响应时间分析:需要知道绝大多数请求的响应时间情况,例如中位数响应时间和90%的请求响应时间。
- 整体性能评估:适合评估系统的整体性能,而不需要详细的区间数据。
Histogram
Histogram 则是将数据划分到不同的区间(桶)中,统计每个区间的数据量。它适合需要详细了解数据在不同范围内分布情况的场景。
特点:
- 区间划分:将数据划分到不同的区间(桶)中,每个区间统计数据量。
- 精细数据分析:适合需要详细了解数据分布情况的场景,可以明确知道数据在不同区间的分布。
- 需要预定义桶:在使用前需要定义数据的区间(桶),适合事先已知数据范围的情况。
使用场景:
- 详细响应时间分析:需要知道在不同响应时间范围内的请求数量,比如0-100ms、100-200ms等。
- 资源使用情况监控:可以用来监控系统资源使用情况的分布,例如内存使用量在不同范围内的分布。
5、定义和注册指标

-
引入依赖库:通过
go get命令获取prometheus库。import ( "github.com/prometheus/client_golang/prometheus" "sync/atomic" ) -
定义指标:创建Counter类型的指标,例如API请求次数的监控
// APIRequestCounter 结构体,用于管理API请求次数的监控 type APIRequestCounter struct { Zone string APIRequestDesc *prometheus.Desc requestCount uint64 } -
注册指标:使用
prometheus.MustRegister将指标注册到默认的Registry中。apiRequestCounter := collector.NewAPIRequestCounter(*metricsNamespace) // 创建一个新的Prometheus指标注册表 registry := prometheus.NewRegistry() // 注册APIRequestCounter实例到Prometheus注册表 registry.MustRegister(apiRequestCounter)
6、实现自定义数据采集
-
实现Collector接口:创建自定义的Collector结构体来实现数据采集。
// APIRequestCounter 结构体,用于管理API请求次数的监控 type APIRequestCounter struct { Zone string APIRequestDesc *prometheus.Desc requestCount uint64 } -
定义指标描述符:使用
prometheus.NewDesc创建指标描述符。// NewAPIRequestCounter 创建一个新的APIRequestCounter实例 func NewAPIRequestCounter(zone string) *APIRequestCounter { return &APIRequestCounter{ Zone: zone, APIRequestDesc: prometheus.NewDesc( "api_request_count_total", "API请求总次数", nil, prometheus.Labels{"zone": zone}, ), } } -
实现Describe和Collect方法:
Describe方法发送指标描述符到channel,Collect方法执行数据采集并返回数据。// Describe 向Prometheus描述收集的指标 func (c *APIRequestCounter) Describe(ch chan<- *prometheus.Desc) { ch <- c.APIRequestDesc } // Collect 收集指标数据并发送到Prometheus func (c *APIRequestCounter) Collect(ch chan<- prometheus.Metric) { count := atomic.LoadUint64(&c.requestCount) ch <- prometheus.MustNewConstMetric( c.APIRequestDesc, prometheus.CounterValue, float64(count), ) }
7、实现数据采集逻辑
-
自定义数据采集函数:实现一个函数来模拟或获取系统状态数据。
// IncrementRequestCount 增加API请求计数 func (c *APIRequestCounter) IncrementRequestCount() { atomic.AddUint64(&c.requestCount, 1) } -
收集数据:在
Collect方法中调用数据采集函数,并使用MustNewConstMetric创建指标数据。
8、集成和测试
- 创建自定义Collector实例:根据需要创建多个Collector实例。
- 注册到Registry:使用
NewPedanticRegistry创建一个新的Registry,并注册自定义Collector。 - 设置HTTP Handler:使用
promhttp.HandlerFor创建一个HTTP Handler,用于处理/metrics路径的请求并返回指标数据。
var (
// Set during go build
// version string
// gitCommit string
// 命令行参数
listenAddr = flag.String("web.listen-port", "8080", "An port to listen on for web interface and telemetry.")
metricsPath = flag.String("web.telemetry-path", "/metrics", "A path under which to expose metrics.")
metricsNamespace = flag.String("metric.namespace", "app", "Prometheus metrics namespace, as the prefix of metrics name")
)
func main() {
// 解析命令行参数
flag.Parse()
apiRequestCounter := collector.NewAPIRequestCounter(*metricsNamespace)
// 创建一个新的Prometheus指标注册表
registry := prometheus.NewRegistry()
// 注册APIRequestCounter实例到Prometheus注册表
registry.MustRegister(apiRequestCounter)
// 设置HTTP服务器以处理Prometheus指标的HTTP请求
http.Handle(*metricsPath, promhttp.HandlerFor(registry, promhttp.HandlerOpts{}))
// 设置根路径的处理函数,用于返回一个简单的HTML页面,包含指向指标页面的链接
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte(`<html>
<head><title>A Prometheus Exporter</title></head>
<body>
<h1>A Prometheus Exporter</h1>
<p><a href='/metrics'>Metrics</a></p>
</body>
</html>`))
})
// 模拟API请求的处理函数
http.HandleFunc("/api", func(w http.ResponseWriter, r *http.Request) {
apiRequestCounter.IncrementRequestCount()
// 模拟API处理时间
w.Write([]byte("API请求处理成功"))
})
// 记录启动日志并启动HTTP服务器监听
log.Printf("Starting Server at http://localhost:%s%s", *listenAddr, *metricsPath)
log.Fatal(http.ListenAndServe(":"+*listenAddr, nil))
}
9、启动服务并测试
请下载:https://github.com/nangongchengfeng/Prometheus-Go-Template.git 启动测试
- 启动HTTP服务:启动服务并监听8080端口。
- 访问指标数据:通过浏览器访问
http://localhost:8080/metrics查看指标数据。
测试接口
http://localhost:8080/api
http://localhost:8080/query
10、原理
1、Prometheus 监控总结
在使用 Prometheus 进行监控时,理解指标的采集方式和不同指标类型的应用场景至关重要。以下是对相关概念的总结:
-
指标采集:
Exporter 定期采集指标数据,并通过 HTTP 接口暴露。这些数据可以由 Prometheus 服务进行抓取和存储,便于后续的分析和展示。 -
指标类型:
- Counter:适用于持续增长的指标,例如请求计数、任务完成次数等。它只会递增,不会减少。
- Gauge:适用于可能增减的指标,例如当前内存使用量、CPU 使用率等。它既可以递增,也可以递减。
- Histogram:适用于需要聚合和统计数据分布的场景,例如请求响应时间分布。它将数据划分到不同的区间(桶)中,并统计每个区间的数据量。
- Summary:同样适用于需要聚合和统计分布的场景,但它通过计算分位数来描述数据分布情况,例如中位数、90% 分位数等。
-
数据聚合:
Histogram 和 Summary 这两种类型的指标专注于数据的聚合和统计分布。它们能够提供关于数据分布的详细信息,便于深入分析系统性能和行为。 -
自定义 Collector:
开发者可以通过实现Collector接口来自定义数据采集逻辑,以满足特定的监控需求。自定义 Collector 需要实现describe和collect两个方法,以便将自定义逻辑集成到 Prometheus 的数据采集流程中。
2、Golang 中的监控器逻辑解析
在 Golang 中使用 Prometheus 进行监控时,了解监控器的逻辑和工作原理至关重要。下面将简要总结一下监控器的基本逻辑:
-
监控器初始化:
默认情况下,当引入registry包时,会触发对gocollect这个采集器的初始化,这是因为registry在初始化时会调用describe接口,而gocollect正是实现了这个接口。 -
数据采集流程:
当有 HTTP 请求到达时,http.handle会调用registry的gather函数。在gather函数内部,会调用具体采集器的collect接口,这个实现就是gocollect中的collect函数。这一流程确保了数据的采集和处理。 -
多类型处理:
上述流程仅是一种特殊情况,实际上,对于四种不同类型的监控器(Counter、Gauge、Histogram 和 Summary),都有对应的结构体继承了基本函数接口,并实现了相应的接口。每种监控器都有自己独特的逻辑和实现方式,但整体流程大致相同。 -
自定义监控器:
如果需要实现自定义的监控器逻辑,可以新建一个结构体作为监控器,实现describe和collect接口。这样,就可以根据自己的需求实现特定的监控逻辑。最终,这些自定义监控器的实现原理也是调用了四种不同类型监控器的相关函数,以实现数据的采集和处理。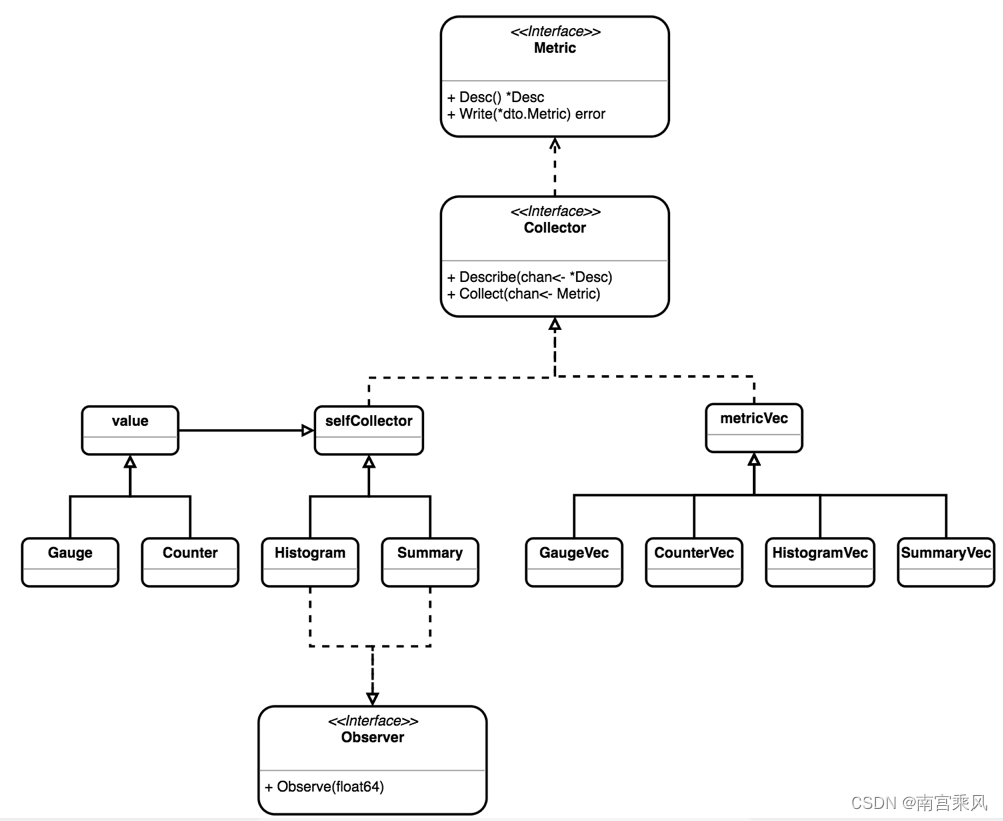
参考项目和文档:
https://github.com/crockitwood/go-prometheus-example.git
Prometheus四种指标详细解释
https://kingjcy.github.io/post/monitor/metrics/prometheus/library/client_golang/