目录
一、前期准备
1.1 标签数字化
1.2 加载数据
1.3 配置数据
二、其他
2.1 损失函数 categorical_crossentropy
2.2 plt.legend(loc=' ')
2.3 history.history
活动地址:CSDN21天学习挑战赛
学习:深度学习100例-卷积神经网络(CNN)识别验证码 | 第12天_K同学啊的博客-CSDN博客
一、前期准备
1.1 标签数字化
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
char_set = number + alphabet
char_set_len = len(char_set)
label_name_len = len(all_label_names[0])
# 将字符串数字化
def text2vec(text):
vector = np.zeros([label_name_len, char_set_len])
for i, c in enumerate(text):
idx = char_set.index(c)
vector[i][idx] = 1.0
return vector
all_labels = [text2vec(i) for i in all_label_names]
text 为 all_label_names 即标签名称的值,假设标签是 677g3,则一次输入进函数 text2vec:6、7、7、g、3
enumerate(text) 返回了text的 索引和值 给 i 和 c ,idx 为在 char_set 里找到的 c的索引值,所以新构建了一个全0 的二维数组,行数为标签的长度,列数为字符集合 char_set 的长度,转化结果即为,每i行的对应标签名称的第i个值对应的索引为1,其余为0
1.2 加载数据
AUTOTUNE = tf.data.experimental.AUTOTUNE
path_ds = tf.data.Dataset.from_tensor_slices(all_image_paths)
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
label_ds = tf.data.Dataset.from_tensor_slices(all_labels)
image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))
image_label_ds
tf.data.Dataset.from_tensor_slices_方如一的博客-CSDN博客
与 prefetch()使用类似,Dataset.map() 也可以利用多 GPU 资源,并行化地对数据项进行变换,从而提高效率。以前节的 MNIST 数据集为例,假设用于训练的计算机具有 2 核的 CPU,我们希望充分利用多核心的优势对数据进行并行化变换(比如 前节 的旋转 90 度函数 rot90 ),可以使用以下代码:
如代码:
1mnist_dataset = mnist_dataset.map(map_func=rot90, num_parallel_calls=2)
参考:TensorFlow 2.0 常用模块3:tf.data 流水线加速_zk_one的博客-CSDN博客
1.3 配置数据
prefetch() 功能详细介绍:CPU正在准备数据时,加速器处于空闲状态。相反,当加速器正在训练模型时,CPU处于空闲状态。因此,训练所用的时间是CPU预处理时间和加速器训练时间的总和。prefetch() 将训练步骤的预处理和模型执行过程重叠到一起。当加速器正在执行第N个训练步时,CPU正在准备第N+1步的数据。这样做不仅可以最大限度地缩短训练的单步用时(而不是总用时),而且可以缩短提取和转换数据所需的时间。如果不使用prefetch() , CPU和GPU/TPU在大部分时间都处于空闲状态:
BATCH_SIZE = 16
train_ds = train_ds.batch(BATCH_SIZE)
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.batch(BATCH_SIZE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
val_ds
二、其他
2.1 损失函数 categorical_crossentropy
model.compile(optimizer="adam",
loss='categorical_crossentropy',
metrics=['accuracy'])
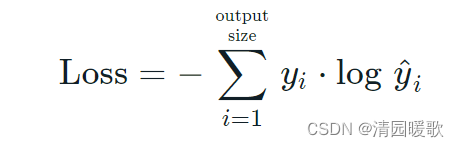
根据公式我们可以发现,因为yi,要么是0,要么是1。而当yi等于0时,结果就是0,当且仅当yi等于1时,才会有结果。也就是说categorical_crossentropy只专注与一个结果,因而它一般配合softmax做单标签分类。
详情参考:损失函数:categorical_crossentropy_Stealers的博客-CSDN博客_categorical_crossentropy
2.2 plt.legend(loc=' ')
plt.legend(loc=' '):设置图例的位置
plt.plot(),plt.scatter(),plt.legend函数的用法介绍_Sunny.T的博客-CSDN博客_plt.legend
plt.legend(loc='lower right')
plt.legend(loc='upper right')2.3 history.history
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])history:历史查看命令,可用来绘制训练过程中的损失和准确率