上篇讲述了list.forEach()和list.stream().forEach() 异同点
谈到了并行流的概念,本篇则从源码出发,了解一下其原理。
一、流的初始操作流程
jdk8中 将Collection中加入了转换流的概念。
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
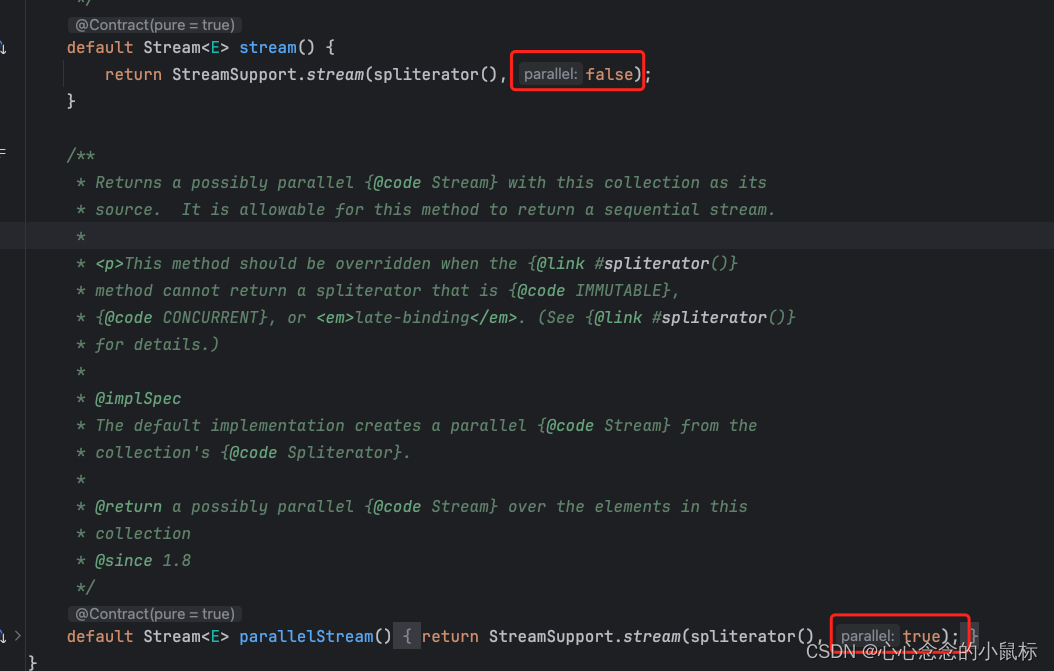
目前看到的两者是一个参数的区别。
//boolean parallel 是否为并行流
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
//用于检查传入的spliterator是否为空
Objects.requireNonNull(spliterator);
//ReferencePipeline.Head 表示流的开始,根据spliterator以及parallel创建对应的流操作链
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
//该构造方法用于初始化Head类的实例
Head(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
ReferencePipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
//super关键字调用父类的构造方法,完成对父类的初始化工作
super(source, sourceFlags, parallel);
}
//按照给定的参数初始化AbstractPipeline类的实例
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this; //当前阶段作为源操作
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE; //左移一位取反操作
this.depth = 0;
this.parallel = parallel; //当前流水线是否支持并行操作
}
二、forEach操作

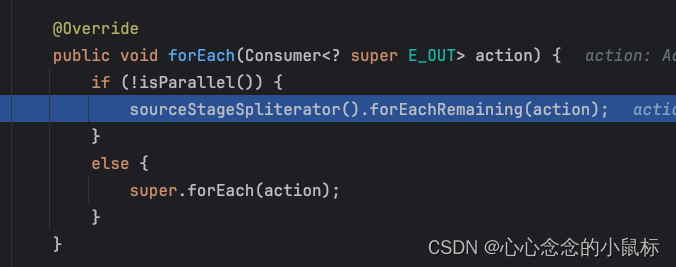
@Override
public void forEach(Consumer<? super E_OUT> action) {
if (!isParallel()) {
//串行流执行
sourceStageSpliterator().forEachRemaining(action);
}
else {
//并行流执行
super.forEach(action);
}
}
1)串行流
demo debug add操作,看为何会报错?
public static void main(String[] args) {
List<String> list= new ArrayList<>();
list.add("Sunday");
list.add("Monday");
list.add("Tuesday");
list.add("Wednesday");
list.add("Thursday");
list.add("Friday");
list.add("Saturday");
list.stream().forEach(d->{
System.out.println("value="+d);
if (d.equals("Thursday")){
list.add(d);
}
});
}
//如果此管道截断是源阶段,则获取源阶段拆分器。调用此方法并成功返回后,将消耗管道
final Spliterator<E_OUT> sourceStageSpliterator() {
if (this != sourceStage)
throw new IllegalStateException();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
if (sourceStage.sourceSpliterator != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
return s;
}
else if (sourceStage.sourceSupplier != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = (Spliterator<E_OUT>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
return s;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
}
forEachRemaining实现方法
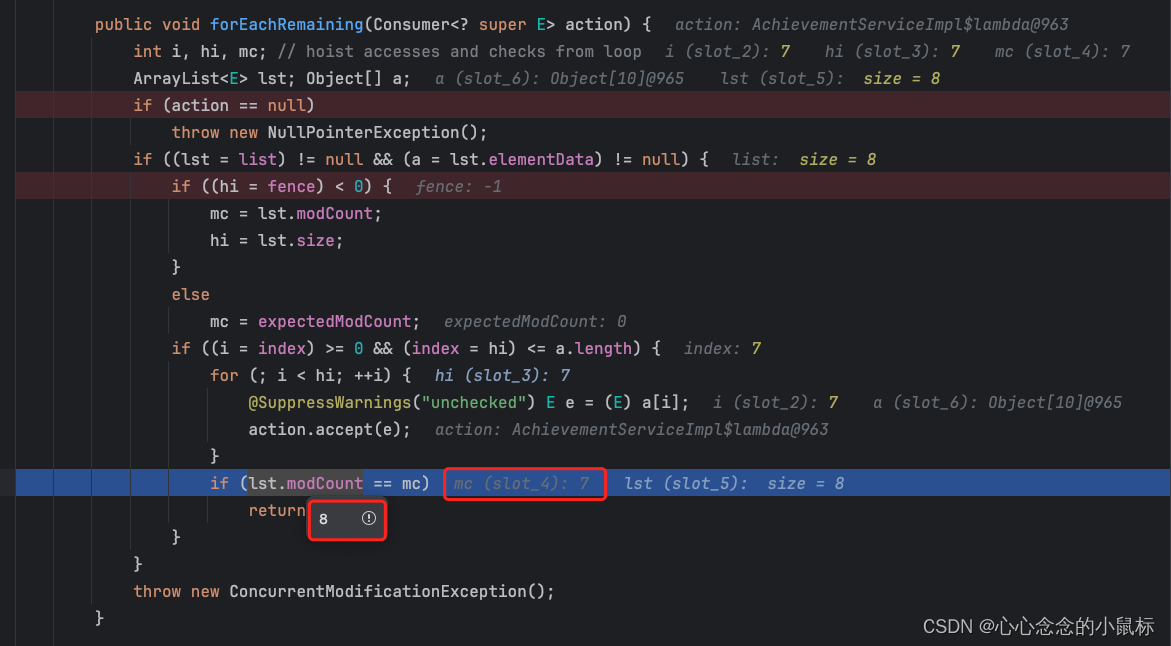
return未走,直接走了异常返回 throw new ConcurrentModificationException();
public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList<E> lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
//i表示开始迭代的位置
//i=index index表示上次迭代的位置,将上次迭代器正在迭代的位置复制给i
//(i=index)>=0 保证当前迭代的下标大于等于0
//表示最大迭代到hi,设置最大的hi=a.length
//(index = hi) <= a.length保证数组不跨界
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
//执行具体的迭代
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
2)并行流



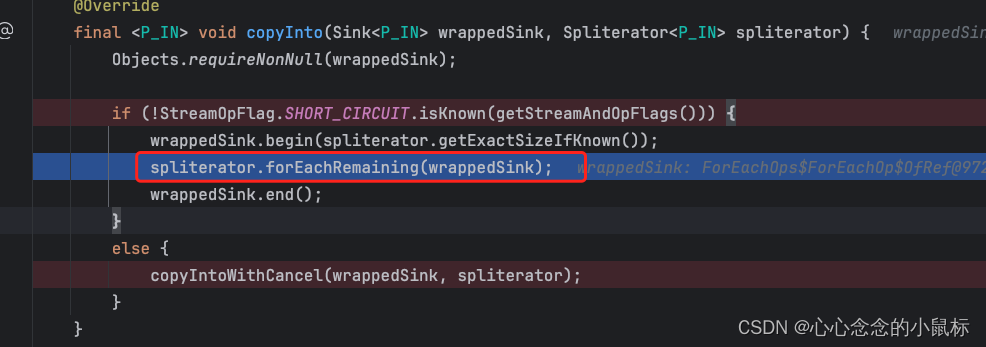
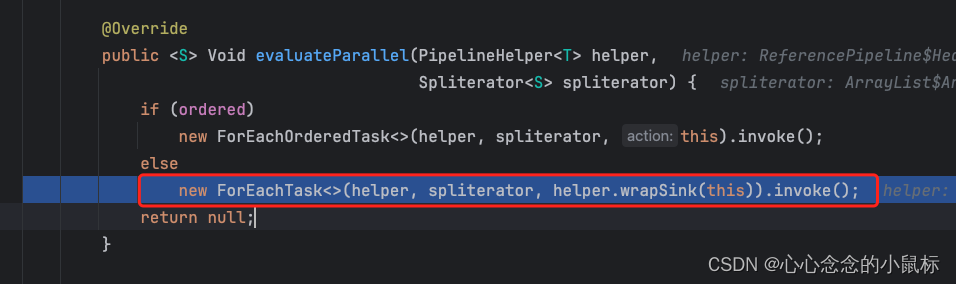
@Override
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
//构造一个 {@code TerminalOp},用于对流的每个元素执行操作。
//action,接收流所有元素的 {@code Consumer}
//ordered,是否请求有序遍历,因为是并行流,所以ordered未false
public static <T> TerminalOp<T, Void> makeRef(Consumer<? super T> action,
boolean ordered) {
Objects.requireNonNull(action);
return new ForEachOp.OfRef<>(action, ordered);
}
//使用终端操作评估管道以产生结果。
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
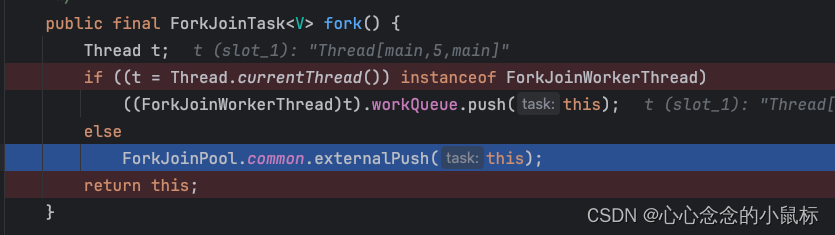
三、核心原理-ForkJoinPool
其核心原理则-ForkJoinPool
1)Diagrams
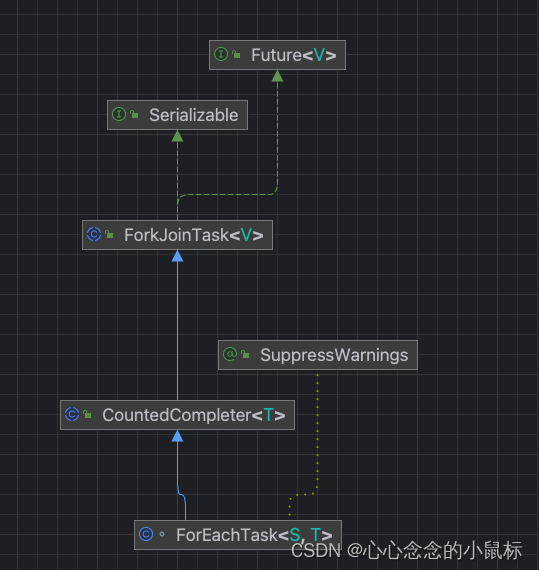
2)compute()
ForkJoin进行计算任务时,计算类是要继承ForkJoinTask并且重写compute方法的。
我们看一下ForkJoinTask内部类是如何重写compute()方法的。
//类似于 AbstractTask,但不需要跟踪子任务
public void compute() {
Spliterator<S> rightSplit = spliterator, leftSplit;
//先调用当前splititerator 方法的estimateSize 方法,预估这个分片中的数据量
long sizeEstimate = rightSplit.estimateSize(), sizeThreshold;
if ((sizeThreshold = targetSize) == 0L)
targetSize = sizeThreshold = AbstractTask.suggestTargetSize(sizeEstimate);
boolean isShortCircuit = StreamOpFlag.SHORT_CIRCUIT.isKnown(helper.getStreamAndOpFlags());
boolean forkRight = false;
Sink<S> taskSink = sink;
ForEachTask<S, T> task = this;
while (!isShortCircuit || !taskSink.cancellationRequested()) {
if (sizeEstimate <= sizeThreshold ||
(leftSplit = rightSplit.trySplit()) == null) {
task.helper.copyInto(taskSink, rightSplit);
break;
}
ForEachTask<S, T> leftTask = new ForEachTask<>(task, leftSplit);
task.addToPendingCount(1);
ForEachTask<S, T> taskToFork;
if (forkRight) {
forkRight = false;
rightSplit = leftSplit;
taskToFork = task;
task = leftTask;
}
else {
forkRight = true;
taskToFork = leftTask;
}
//根据预估的数据量获取最小处理单元的大小阈值,即当数据量已经小于这个阈值的时候进行计算,否则进行fork.fork方法中调用了ForkJoinPool线程池并行计算
taskToFork.fork();
//将任务划分成更小的数据块,进行求解
sizeEstimate = rightSplit.estimateSize();
}
task.spliterator = null;
task.propagateCompletion();
}
重写的compute()方法,当进行fork方法时,实际就是调用了ForkJoinPool线程池进行计算了,那么线程池本身是无顺序的,谁先计算完谁展示。
3)ForkJoinPool核心算法
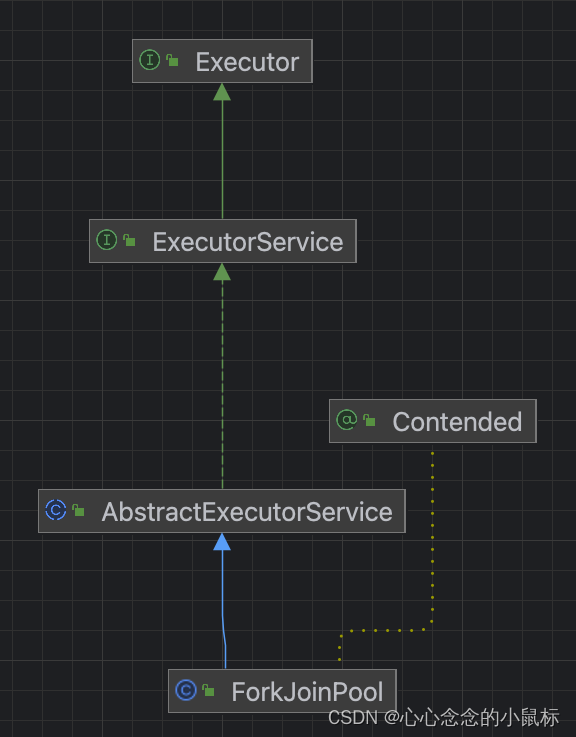
“工作窃取”(work-stealing)算法
ForkJoinPool的基本原理是基于“工作窃取”(work-stealing)算法。它维护着一个工作队列(WorkQueue)的数组,每个工作队列对应一个工作线程(WorkerThread)。当一个线程需要执行一个任务时,它会将任务添加到自己的工作队列中。当一个线程的工作队列为空时,它会从其他线程的工作队列中“窃取”一个任务来执行。这个“窃取”操作可以在不同的线程间实现任务的负载均衡。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
“分治法”(Divide-and-Conquer Algorithm)
分治法-典型的应用比如快速排序算法。使用分治法来实现任务的并行执行。分治法是一种将大问题划分成小问题,并通过递归地解决小问题来解决大问题的方法。
四、结果无顺序
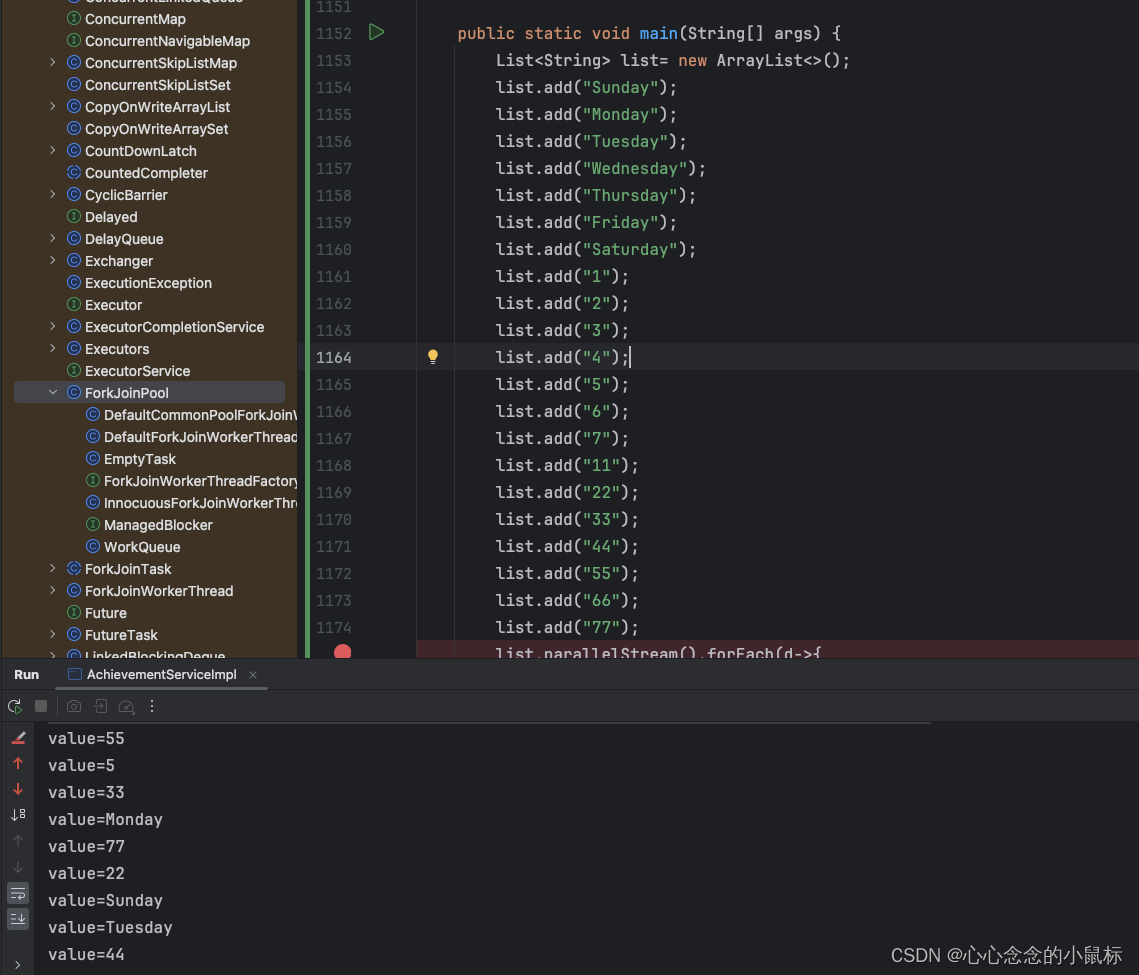
1)若想并行且有顺序,用.forEachOrdered替代
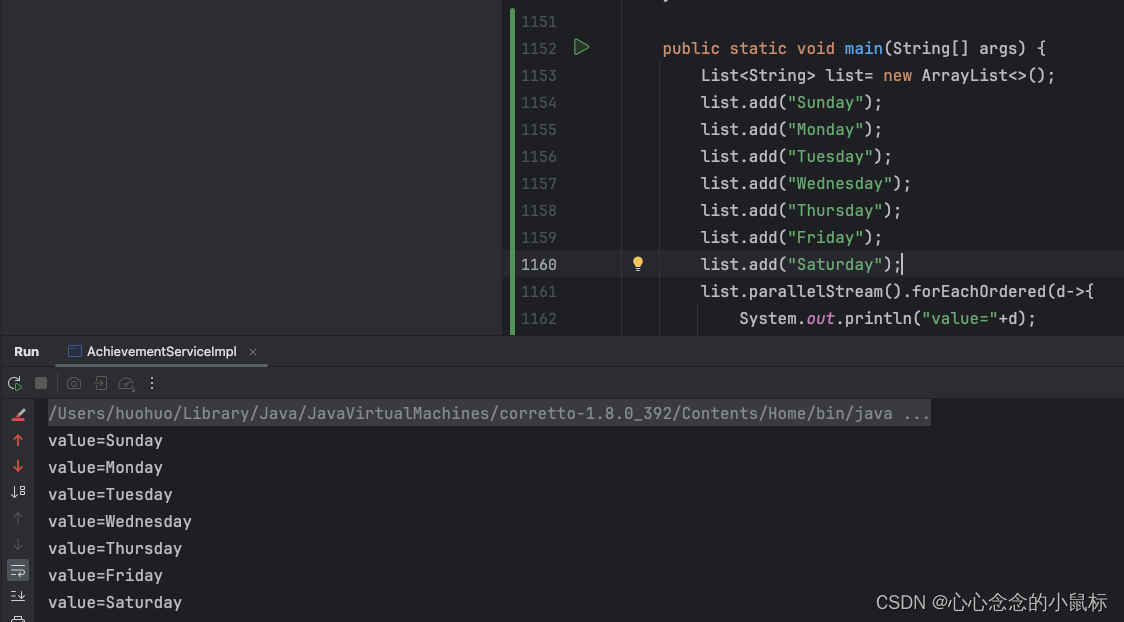
2).forEachOrdered是如何保证有序的?
private static <S, T> void doCompute(ForEachOrderedTask<S, T> task) {
Spliterator<S> rightSplit = task.spliterator, leftSplit;
long sizeThreshold = task.targetSize;
boolean forkRight = false;
while (rightSplit.estimateSize() > sizeThreshold &&
(leftSplit = rightSplit.trySplit()) != null) {
ForEachOrderedTask<S, T> leftChild =
new ForEachOrderedTask<>(task, leftSplit, task.leftPredecessor);
ForEachOrderedTask<S, T> rightChild =
new ForEachOrderedTask<>(task, rightSplit, leftChild);
// 分叉父任务 完成左右子项 “发生在”父项完成之前
task.addToPendingCount(1);
// 完成左边的孩子“发生在”完成右边的孩子之前
rightChild.addToPendingCount(1);
task.completionMap.put(leftChild, rightChild);
// If task is not on the left spine
if (task.leftPredecessor != null) {
/*
* Completion of left-predecessor, or left subtree,
* "happens-before" completion of left-most leaf node of
* right subtree.
* The left child's pending count needs to be updated before
* it is associated in the completion map, otherwise the
* left child can complete prematurely and violate the
* "happens-before" constraint.
*/
leftChild.addToPendingCount(1);
// Update association of left-predecessor to left-most
// leaf node of right subtree
if (task.completionMap.replace(task.leftPredecessor, task, leftChild)) {
// If replaced, adjust the pending count of the parent
// to complete when its children complete
task.addToPendingCount(-1);
} else {
// Left-predecessor has already completed, parent's
// pending count is adjusted by left-predecessor;
// left child is ready to complete
leftChild.addToPendingCount(-1);
}
}
ForEachOrderedTask<S, T> taskToFork;
if (forkRight) {
forkRight = false;
rightSplit = leftSplit;
task = leftChild;
taskToFork = rightChild;
}
else {
forkRight = true;
task = rightChild;
taskToFork = leftChild;
}
taskToFork.fork();
}
/*
* Task's pending count is either 0 or 1. If 1 then the completion
* map will contain a value that is task, and two calls to
* tryComplete are required for completion, one below and one
* triggered by the completion of task's left-predecessor in
* onCompletion. Therefore there is no data race within the if
* block.
*/
if (task.getPendingCount() > 0) {
// Cannot complete just yet so buffer elements into a Node
// for use when completion occurs
@SuppressWarnings("unchecked")
IntFunction<T[]> generator = size -> (T[]) new Object[size];
Node.Builder<T> nb = task.helper.makeNodeBuilder(
task.helper.exactOutputSizeIfKnown(rightSplit),
generator);
task.node = task.helper.wrapAndCopyInto(nb, rightSplit).build();
task.spliterator = null;
}
task.tryComplete();
}
看代码会大概得理解,此采用了“happens-before”原则,左子树需右子树之前完成,通过计数策略保证前后顺序的完成,继而保证了其有序性。最终执行依旧是ForkJoinPool线程池执行。
五、应用场景
1)并行的前提是需要硬件支持
前提是硬件支持, 如果单核 CPU, 只会存在并发处理, 而不会并行
2)demo 测试性能(本机测试)
测试配置:16 GB 2667 MHz DDR4
@Test
public void dateTest() {
System.out.println("数据汇总开始");
Long startTime = System.currentTimeMillis();
int count1 = adminTaskReceiveService.receiveCount();
int count2 = adminTaskReceiveService.inspectCount();
int count3=adminTaskReceiveService.constructCount();
int count4=adminTaskReceiveService.appointmentCount();
TestResult testResult = new TestResult();
testResult.setReceiveCount(count1);
testResult.setInspectCount(count2);
testResult.setConstructCount(count3);
testResult.setAppointmentCount(count4);
int count11 = adminTaskReceiveService.receiveCount1();
int count22 = adminTaskReceiveService.inspectCount1();
int count33=adminTaskReceiveService.constructCount1();
int count44=adminTaskReceiveService.appointmentCount1();
testResult.setReceiveCount1(count11);
testResult.setInspectCount1(count22);
testResult.setConstructCount1(count33);
testResult.setAppointmentCount1(count44);
System.out.println("数据汇总结束,result=" + testResult);
Long endTime = System.currentTimeMillis();
System.out.println("time=" + (endTime - startTime) + "毫秒");
}
@Test
public void dateTest1() {
System.out.println("数据汇总开始");
Long startTime = System.currentTimeMillis();
TestResult testResult = new TestResult();
List<Runnable> taskList = new ArrayList<Runnable>() {
{
add(() -> testResult.setReceiveCount(adminTaskReceiveService.receiveCount()));
add(() -> testResult.setInspectCount(adminTaskReceiveService.inspectCount()));
add(() -> testResult.setConstructCount(adminTaskReceiveService.constructCount()));
add(() -> testResult.setAppointmentCount(adminTaskReceiveService.appointmentCount()));
add(() -> testResult.setReceiveCount1(adminTaskReceiveService.receiveCount1()));
add(() -> testResult.setInspectCount1(adminTaskReceiveService.inspectCount1()));
add(() -> testResult.setConstructCount1(adminTaskReceiveService.constructCount1()));
add(() -> testResult.setAppointmentCount1(adminTaskReceiveService.appointmentCount1()));
}
};
taskList.parallelStream().forEach(Runnable::run);
System.out.println("数据汇总结束,result=" + testResult);
Long endTime = System.currentTimeMillis();
System.out.println("time=" + (endTime - startTime) + "毫秒");
}
一个单线程,一个并行,看结果:测试demo我是需要统计8个数量,由结果可见性能并没什么大区别。
由结果可知:并行处理并不总是能提高性能,特别是当任务规模较小或者任务之间依赖性较强时。此外,在使用并行流时,应该避免使用会修改原始集合的操作,因为这些操作可能会导致不可预测的结果。由于’foreach`操作是终端操作,它会阻塞主线程直到所有元素都被处理完毕,因此即使操作是并行的,它们仍然是按照顺序完成的。


3)最后总结
在数据量比较大的情况下,CPU负载本身不是很高,不要求顺序执行的时候,可以使用并行流。