1. HDFS
HDFS(Hadoop Distributed File System)–Hadoop分布式文件存储系统
源自于Google的GFS论文,HDFS是GFS的克隆版
HDFS是Hadoop中数据存储和管理的基础
他是一个高容错的系统,能够自动解决硬件故障,eg:硬盘损坏,HDFS可以自动修复,可以运行于低成本的通用硬件上(低廉的硬盘,4TB是1200元左右)
【Hadoop是一个由Apache基金会所开发的分布式系统基础架构。】
2. YARN
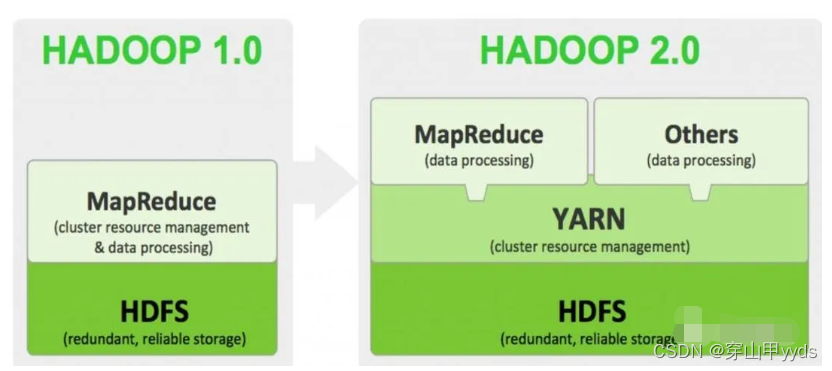
Hadoop中另一个核心组件YARN,这个组件对Hadoop的发展起到了至关重要的作用。YARN (Yet Another Resource Negotiator,另一种资源协调者),Hadoop2中新增加的一种资源管理器。
YARN是一种通用资源管理系统和调度平台,可以为上层应用提供统一的资源管理和调度。
YARN的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大的好处。
hadoop1.0中的资源调度管理由MapReduce来负责,为了降低MR的工作复杂度,在2.0中新增了YARN组件,来专门负责资源的调度和管理。
另一个搜索结果:
Yarn 是一个软件包管理器,还可以作为项目管理工具。无论你是小型项目还是大型单体仓库(monorepos),无论是业余爱好者还是企业用户,Yarn 都能满足你的需求。
npm(Node Package Manager)和 yarn 是两个常用的包管理工具,用于在 Node.js 项目中安装、管理和更新依赖项。
npm(全称 Node Package Manager)是一个软件包管理系统,专门管理用 JavaScript 编写的软件包。可以免费下载别人写好的 js软件包,并用到项目中,当然也可以上传共享自己写的 js软件包。安装及使用,看这里!
yarn 也是一个软件包管理系统,同样用于管理 用 JavaScript 编写的软件包,yarn 的出现是为了弥补 npm 的一些缺陷。
3. hive
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。
最初,Hive是由Facebook开发,后来移交由Apache软件基金会开发,并作为一个Apache开源项目。
4. HBase
Hbase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java。它是Apache软件基金会Hadoop项目的一部分,运行于HDFS文件系统之上,为Hadoop提供类似于BigTable规模的服务。
HBase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。HBase 底层存储基于 HDFS 实现,集群的管理基于 ZooKeeper 实现。
5.ZooKeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
简单来说,zookeeper = 文件系统 + 监听通知机制
6.Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
7.Flink
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性。
8.Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,是一种高吞吐量的分布式发布订阅消息系统,由Scala和Java编写。
Kafka可以处理消费者在网站中的所有动作流数据,这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素,这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案,Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。Kafka具有高吞吐量,支持通过kafka服务器和消费机集群来分区消息,支持 Hadoop并行数据加载等特点。
9.ELK
ELK是三个软件的统称,即Elasticsearch、Logstash和Kibana三个开源软件的缩写。这三款软件都是开源软件,通常配合使用,并且都先后归于Elastic.co企业名下,故被简称为ELK协议栈。ELK主要用于部署在企业架构中,收集多台设备上多个服务的日志信息,并将其统一整合后提供给用户。ELK官网网址如下:https://www.elastic.co/cn/
10.ansible
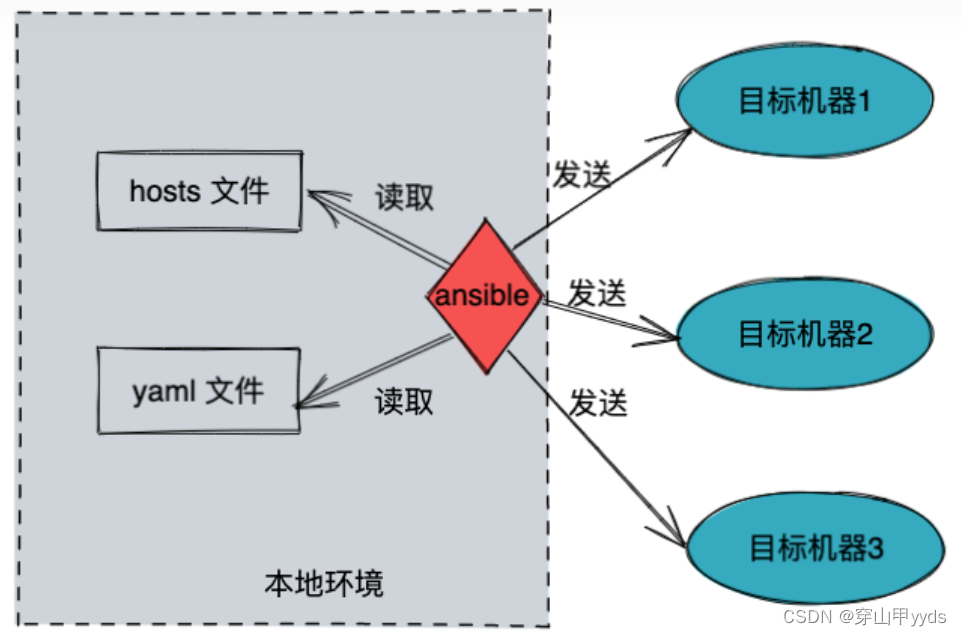
ansible是新出现的自动化运维工具,基于Python开发。ansible是基于模块工作的,本身没有批量部署的能力。真正具有批量部署的是ansible所运行的模块,ansible只是提供一种框架。https://zhuanlan.zhihu.com/p/387360214
hadoop的概念
网上会经常遇到各种hadoop的概念,Hive,HBase,Hdfs都各是什么呢?
首先从hdfs说起,hdfs是分布式文件系统,它把集群当作单机一样做文件操作,文件可能存在于多个机器上,具体的存储细节会对使用者隐藏。
map_reduce是一个计算框架,google提出的,用于大规模数据计算,它们的主要思想,是从函数式编程中借来的特性。
hdfs和map_reduce统称为我们常说的Hadoop架构,这个架构能存储PB级别的数据,也能进行成千上万的独立计算。
好,现在已经有了这个框架了,这个框架包含了底层的存储结构,但是却并不是那么好用,我们大家还是擅长于使用sql语句来进行数据精炼,查询和分析的。这个时候,就出现了Hive。Hive的功能是把sql语句解析成map_reduce的计算任务,当然这样的拆分会导致查询变慢,可能一个sql查询需要分钟甚至小时级别的,不像mysql那样秒级以内查询出结果。
基于Hadoop框架,Powerset公司提出了另外一种非关系行分布式数据库HBase。它是使用JAVA实现的,最大的特点是基于列存储的。列存储的好处是什么?列存储就是把不同行相同的数据存储在一起,这样比如有的行没有的属性,在行存储中还需要留空余空间,但是在列存储中就完全不需要。列存储也能把相同属性的字段存储在一起,这样对数据压缩也有好处。所以列存储很适合大数据领域。
我们经常看到文章比较HBase和Hive,一般都是比较他们的查询效率,其实他们并不是一个维度的东西。HBase的查询效率会优于Hive,而Hive一般用于做离线的数据分析。
本文转自轩脉刃博客园博客,原文链接:http://www.cnblogs.com/yjf512/p/5166296.html,如需转载请自行联系原作者