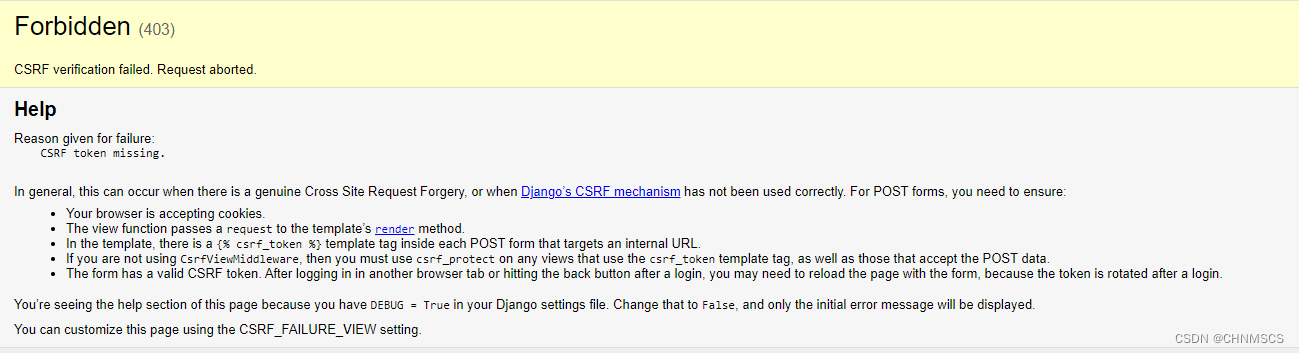
一、 开发板简介
OrangePi AIpro开发板是香橙派联合华为精心打造的高性能 AI 开发板,其搭载了昇腾 AI 处理器,可提供 8TOPS INT8 的计算能力,内存提供了 8GB 和 16GB两种版本。可以实现图像、视频等多种数据分析与推理计算,可广泛用于教育、机器人、无人机等场景。
下面让我们来具体看看吧:
1.1 开发板全貌
首先看一眼产品的全貌:


(不得不说,颜值还是很nice的)
1.2 硬件规格
(1)昇腾AI处理器: 搭配华为昇腾310NPU,4核64位Arm处理器+AI处理器
(2)AI算力: 支持半精度(FP16):4 TFLOPS 和 整数精度(INT8):8 TOPS
(3)内存: 8GB 或 16GB
(4)存储: 板载32MB的SPI Flash,提供Micro SD卡插槽和eMMC插座
(5)接口: 接口配置丰富,包括USB3.0、USB Type-C 3.0、Micro USB、HDMI、CSI、DSI、以太网口、40pin扩展口等多种接口
(6)Wifi+蓝牙: 支持2.4G和5G双频WIFI、BT 4.2
(7)操作系统: 支持Ubuntu 22.04 和 openEuler 22.03
(8)外观规格: 107*68mm、82kg
输入npu-smi info 再看一下芯片信息:

1.3 接口和引脚图
接口:

引脚:

二、 开机和使用
2.1 开机准备
由于获得的Orange Pi AIpro 已经烧录了ubuntu的镜像到TF卡,因此选择使用TF卡的启动方式。
而开发板支持从 TF 卡、eMMC 和 SSD(支持 NVMe SSD 和 SATA SSD)启动,通过背面的两个拨码开关(BOOT1和BOOT2)控制

两个拨码开关都支持左右两种设置状态,共4种状态,目前开发板使用了其中的3种,不同状态的启动设备如下表所示:
| 拨码开关BOOT1 | 拨码开关BOOT2 | 对应的启动设备 |
|---|---|---|
| 左 | 左 | 未使用 |
| 右 | 左 | SATA SSD和NVMe SSD |
| 左 | 右 | eMMC |
| 右 | 右 | TF卡 |
SATA SSD和NVMe SSD通过M2_TYPE引脚的电平自动区分。此外切换拨码开关需要重新插拔电源使启动设备选项生效,复位键不行。
2.2 开机
使用 HDMI0 连接屏幕,如图所示,上电等待一会儿后即自动开机,输入密码:Mind@123进入 ubuntu 系统

(注意:使用时天线不能贴到板子上,同时天线的导电布也不能挨着板子,否则可能会烧坏板子)

鼠标和键盘插到两个usb 3.0的接口中都可以正常使用!
2.3 SSH连接
直接用MobaXterm软件连接,下面VNC也是,填上ip地址,username可以填HwHiAiUser或者root,密码:Mind@123

登陆成功后显示:

2.4 VNC远程连接
由于我的屏幕有点拉闸,所以我选择vnc远程连接
输入ip和 端口,默认是5901,密码:Mind@123

说明:
打开终端后,请执行bash激活命令行。
在命令行开启远程桌面服务(执行以后重启,可使用VNC登录图形桌面。默认已开启,无需配置。)
sudo systemctl enable vncserver@1.service
reboot
在命令行关闭远程桌面服务(执行以后重启,不可使用VNC登录图形桌面,且系统会释放相应内存。)
sudo systemctl disable vncserver@1.service
reboot
在命令行修改VNC登录密码(修改密码之后,使用VNC登陆远程桌面需要重新输入密码。)
vncpasswd
成功连接后桌面:

若始终无法连接:
如果你不小心重新配置了vnc,导致始终无法连接的话,可以参考以下方法。
(1)输入 cd ~/.vnc进入 .vnc 文件夹
(2)输入 gedit xstartup修改 xstartup 文件
#!/bin/sh
unset SESSION_MANAGER
unset DBUS_SESSION_BUS_ADDRESS
exec startxfce4
(3)输入 chmod u+x ~/.vnc/xstartup 加上权限
(4)最后输入:
vncserver -localhost no
vncserver
即可启动vnc,此时再重新连接
三、 样例和接口测试
3.1 登录Jupyter Lab
(1)首先进入保存AI样例的目录:
cd samples/notebooks/
(2)执行 start_notebook.sh 启动Jupyter Lab
./start_notebook.sh
(3)进入Jupyter Lab的网址,直接用火狐浏览器打开即可

进入后,即可看到左侧有9个样例的文件夹

下面我就挑选几个样例进行测试一下!
3.2 yolov5目标检测
到 样例运行 部分,可以切换视频、图片和摄像头三种模式运行
infer_mode = 'video'
infer_mode = 'image'
infer_mode = 'camera'



def infer_frame_with_vis(image, model, labels_dict, cfg, bgr2rgb=True):
# 数据预处理
img, scale_ratio, pad_size = preprocess_image(image, cfg, bgr2rgb)
# 模型推理
output = model.infer([img])[0]
output = torch.tensor(output)
# 非极大值抑制
boxout = nms(output, conf_thres=cfg["conf_thres"], iou_thres=cfg["iou_thres"])
pred_all = boxout[0].numpy()
# 预测坐标转换
scale_coords(cfg['input_shape'], pred_all[:, :4], image.shape, ratio_pad=(scale_ratio, pad_size))
# 图片预测结果可视化
img_vis = draw_bbox(pred_all, image, (0, 255, 0), 2, labels_dict)
return img_vis
从这里的推理框架来看,我们可以将我们训练好模型转换成om模型后直接使用,只要对数据的输入做好前处理,推理后,再做好后处理即可。

3.3 卡通图像生成
该样例使用 cartoonGAN 模型对输入图片进行卡通化处理。在样例中已经包含转换后的om模型和测试图片。
main 如下:
def main():
MODEL_PATH = "cartoonization.om"
MODEL_WIDTH = 256
MODEL_HEIGHT = 256
acl_resource = AclLiteResource() # 初始化acl资源
acl_resource.init()
# instantiation Cartoonization object
cartoonization = Cartoonization(MODEL_PATH, MODEL_WIDTH, MODEL_HEIGHT) # 构造模型对象
# init
ret = cartoonization.init() # 初始化模型类变量
utils.check_ret("Cartoonization.init ", ret)
image_file = 'img.jpg'
# read image
image = AclLiteImage(image_file) # 构造 AclLiteImage ,方便利用 dvpp 进行前处理
print('===================')
print(image)
# preprocess
crop_and_paste_image = cartoonization.pre_process(image) # 前处理
# inference
result = cartoonization.inference([crop_and_paste_image, ]) # 推理
# postprocess
cartoonization.post_process(result, image_file, image) # 后处理
从代码逻辑中可以看到,整套代码:
(1)首先初始化了acl资源,也就是对AscendCL进行初始化;
(2)创建了一个Cartoonization类,定义了前处理、推理和后处理函数;
(3)构造AclLiteImage类型数据,并转换图片格式为模型需要的yuv格式;
(4)进行推理;
(5)进行后处理。


3.4 人像分割与背景替换
该样例使用了PortraitNet模型进行人像分割。
main函数如下所示:
def main():
"""推理主函数"""
os.makedirs(OUTPUT_DIR, exist_ok=True)
os.makedirs(MASK_DIR, exist_ok=True)
acl_resource = AclLiteResource()
acl_resource.init()
seg = Seg(MODEL_PATH, MODEL_WIDTH, MODEL_HEIGHT)
ret = seg.init()
utils.check_ret("seg.init ", ret)
images_list = [os.path.join(IMAGE_DIR, img)
for img in os.listdir(IMAGE_DIR)
if os.path.splitext(img)[1] in const.IMG_EXT]
for image_file in images_list:
image_name = os.path.basename(image_file)
if image_name != 'background.jpg':
print('====' + image_name + '====')
# read image
image = AclLiteImage(image_file)
# Preprocess the picture
resized_image = seg.pre_process(image)
# Inference
result = seg.inference([resized_image, ])
# Post-processing
mask = seg.post_process(result, image_name)
# Fusion of segmented portrait and background image
background_replace(os.path.join(IMAGE_DIR, 'background.jpg'), \
image_file, os.path.join(MASK_DIR, image_name))
可以看出代码逻辑都相似:
(1)首先初始化了acl资源;
(2)创建Seg类对象,定义前处理、推理和后处理函数;
(3)构造AclLiteImage类型图像数据并进行前处理;
(4)推理后得到分割结果进行后处理获得mask;
(5)进行背景替换

3.5 摄像头测试
上面开机时我们接了HDMI0的屏幕和USB的键盘、鼠标,都可以正常使用,下面我们试一下USB摄像头。
在昇腾论坛上,找到一位楼主部署了一个贪吃蛇的小游戏,我打算用这个案例来测试一下:
https://www.hiascend.com/forum/thread-0265146309613977027-1-1.html
首先接入摄像头,将代码下载到系统中,该套代码使用的Google的开源的MediaPipe手势识别库;
其次要安装相关的库:
pip install mediapipe
pip install cvzone
随后就可以直接运行代码:
python main.py

可见,效果还是不错的,但是有一点,用vnc连接时默认是虚拟桌面,虚拟桌面好像无法识别到摄像头,所以我还是用的hdmi屏幕。
3.6 串口通信测试
既然是开发板,那么有时候避免不了使用串口的吧,嘿嘿,所以这里对串口也进行了测试。
根据用户手册,可以找到uart设备节点和uart的对应关系:

也可以输入 ls /dev/ttyAMA* 来查看,需要注意的是,uart0默认设置为了调试串口功能

再看一下引脚图:

于是我用一个CH340 USB转TTL模块,选择使用uart7,也就是ttyAMA2,TX接GPIO7_07,RX接GPIO7_02

这里使用python的一个库:pyserial
输入:pip install pyserial 安装
import serial
import serial.tools.list_ports
ports_list = list(serial.tools.list_ports.comports()) # 获得所有串口设备实例
for port in ports_list: # 输出所有串口号
print(list(port)[0], list(port)[1]) #/dev/ttyAMA1、/dev/ttyAMA2
ser = serial.Serial("/dev/ttyAMA2", 115200) # 打开串口,设置波特率
if ser.isOpen(): # 判断是否打开
print("open success")
print(ser.name) # 输出串口号
else:
print("failed")
write_len = ser.write("OrangePi AIpro".encode('utf-8'))
ser.close() # 关闭串口
if ser.isOpen(): # 判断是否关闭串口
print("no closed")
else:
print("closed")
运行: sudo python3 serial_test.py,串口ttyAMA2发送 “OrangePi AIpro”,pc端通过串口调试助手也接收到了发送过来的数据


四、AscendCL快速入门
下面我们具体来看一下AscendCL要如何应用?
AscendCL(Ascend Computing Language)是一套用于在昇腾平台上开发深度神经网络应用的C语言API库,提供运行资源管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理等API,能够实现利用昇腾硬件计算资源、在昇腾CANN平台上进行深度学习推理计算、图形图像预处理、单算子加速计算等能力。简单来说,就是统一的API框架,实现对所有资源的调用。
而AscendCL结构调用的基本流程可分下面几个步骤:
(1)AscendCL初始化
(2)运行管理资源申请
(3)模型推理/单算子调用/媒体数据处理
(4)运行管理资源释放
(5)AscendCL去初始化
下面我们通过一个简单的狗狗图像分类的应用快速了解AscendCL接口(C语言接口)开发应用的基本过程:

首先进入到昇腾开源仓库:Ascend: 昇腾万里,让智能无所不及
进入samples\cplusplus\level2_simple_inference\1_classification\resnet50_firstapp目录下:
(1)直接git整个仓库,或者下载zip,将resnet50_firstapp上传到ubuntu中
(2)下载测试需要的文件:
a)下载模型文件(*.prototxt):
https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/resnet50/resnet50.prototxt
放到resnet50_firstapp/model目录下
b)下载权重文件(*.caffemodel):
https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/resnet50/resnet50.caffemodel
放到resnet50_firstapp/model目录下
c)下载测试的输入图片:
https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/aclsample/dog1_1024_683.jpg
放到resnet50_firstapp/data目录下

(3)使用ATC工具进行模型转换
执行:
atc --model=model/resnet50.prototxt --weight=model/resnet50.caffemodel --framework=0 --output=model/resnet50 --soc_version=Ascend310B4
将原始模型转换为昇腾AI处理器能识别的*.om模型文件
● --model: ResNet-50网络的模型文件(.prototxt)的路径。
● --weight: ResNet-50网络的预训练模型文件(.caffemodel)的路径。
● --framework: 原始框架类型。0:Caffe; 1:MindSpore; 3:Tensorflow; 5:Onnx
● --output: resnet50.om模型文件的路径。请注意,记录保存该om模型文件的路径,后续开发应用时需要使用。
● --soc_version: 昇腾AI处理器的版本。进入“CANN软件安装目录/compiler/data/platform_config”目录,".ini"文件的文件名即为昇腾AI处理器的版本,请根据实际情况选择。实际目录可参考:
./usr/local/Ascend/ascend-toolkit/7.0.0/compiler/data/platform_config
(我这里是通过命令npu-smi info指令这里选择的版本)

成功后输出如下所示:

转模型有可能会遇到下述问题:


在昇腾论坛找到了解决方案https://www.hiascend.com/forum/thread-0239142592318174023-1-1.html,总结就是:
转om模型时内存不足,开发板cpu核数较少,atc过程中使用的最大并行进程数默认是服务器的配置,可以使用环境变量减少atc过程中的进程数来减少内存消耗。
·减小算子最大并行编译进程数
export TE_PARALLEL_COMPILER=1
·减少图编译时可用的CPU核数
export MAX_COMPILE_CORE_NUMBER=1
之后就可以成功转换om模型啦!
(4)对输入图片进行处理
由于我们下载的.jpg的输入图片,与模型要求的输入不同,模型要求输入图片是rgb的且大小为224*224,所以这里直接运行resnet50_firstapp/script/transferPic.py脚本进行数据处理
(5)执行编译脚本
给编译脚本执行权限:
chmod +x sample_build.sh
添加环境变量:
export APP_SOURCE_PATH=/home/HwHiAiUser/samples/test_samples/resnet50_firstapp
export DDK_PATH=/usr/local/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=${DDK_PATH}/runtime/lib64/stub
执行编译脚本:
./sample_build.sh

此时在out/main下生成了一个名为main的可执行文件
(6)执行运行脚本
给执行脚本执行权限:
chmod +x sample_run.sh
执行运行脚本:
./sampele_run.sh

因为模型使用imagenet数据集训练的,所以标签可以imagenet数据集处查看:https://blog.csdn.net/u013491950/article/details/83927968

五、YOLOv8移植测试
虽然官方提供了yolov5的样例,但还是想体验一把部署自己模型的感觉,恰恰又对yolo系列更为熟悉,所以就还是选择以yolov8为例啦
5.1 模型转换
首先我们git下yolov8的源码:https://github.com/ultralytics/ultralytics,下载一下模型,这里我选择下载yolov8s.pt

用简单的代码转换成onnx模型:
from ultralytics import YOLO
model = YOLO('yolov8s.pt', 'detect')
model.export(format='onnx', opset=11, simplify=True)
输出如下:

注意这里的输出是三个尺度的。
将onnx模型放到ubuntu系统中后,转换成om模型:
export TE_PARALLEL_COMPILER=1
export MAX_COMPILE_CORE_NUMBER=1
atc --model=yolov8s.onnx --framework=5 --output=yolov8s --soc_version=Ascend310B4 --input_format=NCHW --input_shape="images:1,3,640,640" --output_type="FP32" --log=error
–framework: 选择5,即onnx模型
–output: 为输出的名称,会自动加上.om后缀
–input_format: 输入格式为NCHW
–input_shape: 设置模型输入的格式
–output_type: 输出格式,可以自己选择

我这里为了方便后处理直接使用一个转换好的onnx模型,输出为(1, 84, 8400),大家可以自取,免费下载:https://download.csdn.net/download/qq_47941078/89365245
5.2 推理
获得om模型后,就要自己写一下推理代码啦
import cv2
import torch
import numpy as np
import time
import random
from numpy import ndarray
from typing import List, Tuple
from ais_bench.infer.interface import InferSession
# 类别名称
CLASS_NAMES = ('person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat',
'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot',
'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop',
'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush')
# 预处理
def preprocess_warpAffine(image, dst_width=640, dst_height=640):
scale = min((dst_width / image.shape[1], dst_height / image.shape[0]))
ox = (dst_width - scale * image.shape[1]) / 2
oy = (dst_height - scale * image.shape[0]) / 2
M = np.array([
[scale, 0, ox],
[0, scale, oy]
], dtype=np.float32)
img_pre = cv2.warpAffine(image, M, (dst_width, dst_height), flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT, borderValue=(114, 114, 114))
IM = cv2.invertAffineTransform(M)
img_pre = (img_pre[...,::-1] / 255.0).astype(np.float32)
img_pre = img_pre.transpose(2, 0, 1)[None]
img_pre = torch.from_numpy(img_pre)
return img_pre, IM
# 计算iou
def iou(box1, box2):
def area_box(box):
return (box[2] - box[0]) * (box[3] - box[1])
left = max(box1[0], box2[0])
top = max(box1[1], box2[1])
right = min(box1[2], box2[2])
bottom = min(box1[3], box2[3])
cross = max((right-left), 0) * max((bottom-top), 0)
union = area_box(box1) + area_box(box2) - cross
if cross == 0 or union == 0:
return 0
return cross / union
# nms非极大值抑制
def NMS(boxes, iou_thres):
remove_flags = [False] * len(boxes)
keep_boxes = []
for i, ibox in enumerate(boxes):
if remove_flags[i]:
continue
keep_boxes.append(ibox)
for j in range(i + 1, len(boxes)):
if remove_flags[j]:
continue
jbox = boxes[j]
if(ibox[5] != jbox[5]):
continue
if iou(ibox, jbox) > iou_thres:
remove_flags[j] = True
return keep_boxes
# 后处理
def postprocess(pred, IM=[], conf_thres=0.25, iou_thres=0.45):
# 1,8400,84 [cx,cy,w,h,class*80]
boxes = []
for item in pred[0]:
cx, cy, w, h = item[:4]
label = item[4:].argmax()
confidence = item[4 + label]
if confidence < conf_thres:
continue
left = cx - w * 0.5
top = cy - h * 0.5
right = cx + w * 0.5
bottom = cy + h * 0.5
boxes.append([left, top, right, bottom, confidence, label])
boxes = np.array(boxes)
lr = boxes[:,[0, 2]]
tb = boxes[:,[1, 3]]
boxes[:,[0,2]] = IM[0][0] * lr + IM[0][2]
boxes[:,[1,3]] = IM[1][1] * tb + IM[1][2]
boxes = sorted(boxes.tolist(), key=lambda x:x[4], reverse=True)
return NMS(boxes, iou_thres)
def hsv2bgr(h, s, v):
h_i = int(h * 6)
f = h * 6 - h_i
p = v * (1 - s)
q = v * (1 - f * s)
t = v * (1 - (1 - f) * s)
r, g, b = 0, 0, 0
if h_i == 0:
r, g, b = v, t, p
elif h_i == 1:
r, g, b = q, v, p
elif h_i == 2:
r, g, b = p, v, t
elif h_i == 3:
r, g, b = p, q, v
elif h_i == 4:
r, g, b = t, p, v
elif h_i == 5:
r, g, b = v, p, q
return int(b * 255), int(g * 255), int(r * 255)
def random_color(id):
h_plane = (((id << 2) ^ 0x937151) % 100) / 100.0
s_plane = (((id << 3) ^ 0x315793) % 100) / 100.0
return hsv2bgr(h_plane, s_plane, 1)
if __name__ == "__main__":
model_path = 'yolov8s2.om'
img_path = 'bus.jpg'
img = cv2.imread(img_path)
img22 = cv2.imread(img_path)
# img_pre = preprocess_letterbox(img)
img_pre, IM = preprocess_warpAffine(img)
# model = AutoBackend(weights="yolov8s.pt")
model = InferSession(0, model_path)
# names = model.names
names = CLASS_NAMES
img = np.ascontiguousarray(img_pre, dtype=np.float32)
start = time.perf_counter()
result = model.infer([img])
print(np.array(result).shape) # (1, 1, 84, 8400)
result = np.array(result).transpose(0, 1, 3, 2).squeeze()[np.newaxis]
print(np.array(result).shape) # (1, 8400, 84)
result = list(result)
end = time.perf_counter()
print(f'Inference FPS: {1 / (end - start)}')
boxes = postprocess(result, IM)
for obj in boxes:
left, top, right, bottom = int(obj[0]), int(obj[1]), int(obj[2]), int(obj[3])
confidence = obj[4]
label = int(obj[5])
color = random_color(label)
cv2.rectangle(img22, (left, top), (right, bottom), color=color ,thickness=2, lineType=cv2.LINE_AA)
caption = f"{names[label]} {confidence:.2f}"
print("caption:", caption)
w, h = cv2.getTextSize(caption, 0, 1, 2)[0]
cv2.rectangle(img22, (left - 3, top - 33), (left + w + 10, top), color, -1)
cv2.putText(img22, caption, (left, top - 5), 0, 1, (0, 0, 0), 2, 16)
print("img22:", img22.shape)
#img22 = img22.transpose(1, 2, 0)
#print("img22:", img22.shape)
cv2.imwrite("infer.jpg", img22)
print("save done")
输出打印:

保存的推理图片为:

可以看到精度还是很高的,并没有什么损失!
六、 总结
OrangePi AIpro是一款非常优秀的AI开发板,结合了高性能处理器和专用的AI加速硬件,算力强大,完全满足正常的视频流推理的需求,又有着非常丰富的接口,给开发者提供了一个强大且灵活的平台来用于深度学习、目标检测等AI应用的开发和部署。
同时,关于OrangePi AIpro有着非常丰富详细的资料,用户手册完全可以帮助快速使用开发板;各种开源仓库也提供了多种测试样例;此外还有论坛,用户活跃,各种问题都可以相互讨论交流,比如我在模型转换时遇到了内存不足的问题便是在论坛上找到的解决方案;社区还提供了详细的开发指南,从文本教程到视频教程,对开发者都是非常有帮助的,本次体验非常愉快!