前言:最近我在整理过往笔记时,发现涉及到了 UTF-8、Unicode
的相关内容,相信大家中的很多人和之前的我一样,在过去的很长一段时间里,并没有搞清楚什么是 Unicode、什么是
UTF-8,于是就有了这篇文章,我将带大家梳理一下关于 Unicode 码的诞生与实现,用正确的姿势学习认识 Unicode 和
UTF-8。
文章目录
- 1、ASCII 码
- 2、Unicode 码
- 3、UTF-8
- 3.1、Unicode 码和 UTF-8 的关系
- 3.2、UTF-8 具体实现
- 3.3、UTF-8 具体实现的详细解读
- 3.4、问题 1 : 为什么第 n+1 位是 0 呢 ?
- 3.5、问题 2 : 为什么 2 字节及以上包括的 UTF-8 编码 ,低字节的高 2 位始终是固定的 10 呢 ?
1、ASCII 码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准 ISO/IEC 646。ASCII 第一次以规范标准的类型发表是在 1967 年,最后一次更新则是在 1986 年,到目前为止共定义了 128个 字符。
由于计算机最开始就是由欧美国家发明使用的,所以在计算机发展早期,需要显示在电脑屏幕的字符并不多,也就是英文字母、数字、标点符号和一些特殊符号、特殊字符就完全可以满足使用上的需求,总共加起来一个字节足矣表示完。因此就出现了 ASCII 码。
ASCII 码是从零开始编号,一直到 127 号,用于表示完上述所有的字符。其中 0~31 及 127(共 33 个)是控制字符或通信专用字符(其余为可显示字符):
- 控制符: LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;
- 通信专用字符: SOH(文头)、EOT(文尾)、ACK(确认)等。
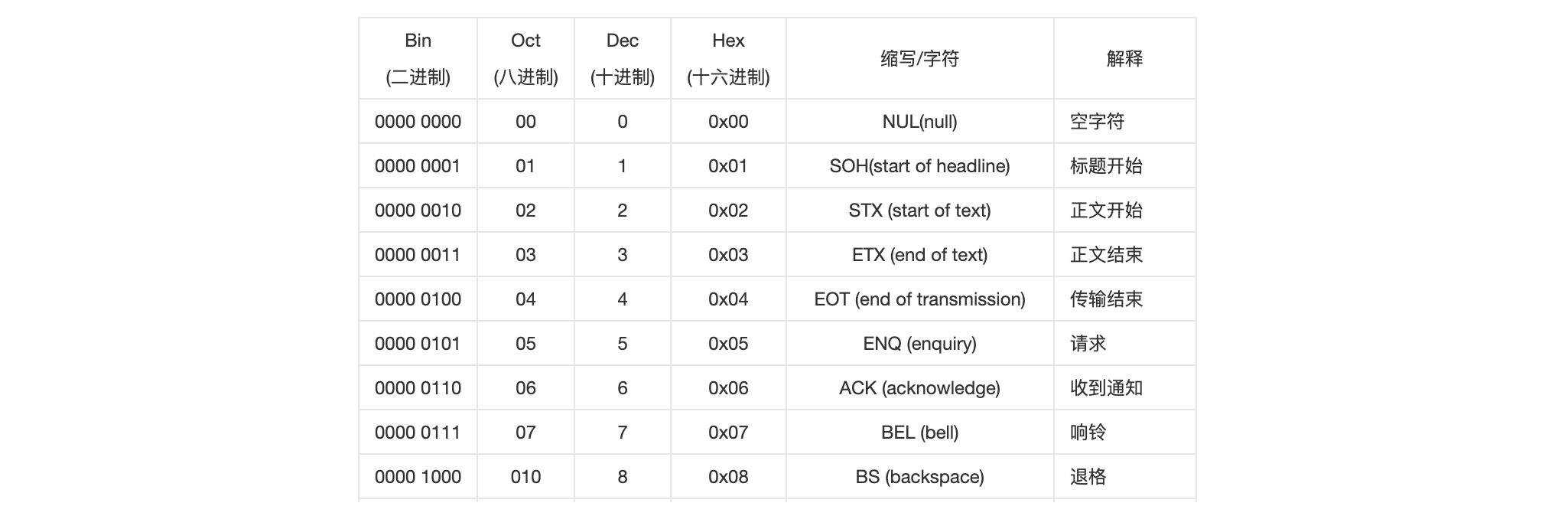
32~126(共 95 个)是字符(32 是空格),其中 48~57 为 0 到 9 十个阿拉伯数字。65~90 为 26 个大写英文字母,97~122 号为 26 个小写英文字母,其余为一些标点符号、运算符号等。
这就是 ASCII 码。
2、Unicode 码
随着计算机在全世界的发展和流行,越来越多的国家开始接触和使用到了计算机,此时的 ASCII 码便开始不再适用,因为对于很多非英语国家来说,即使计算机界面再人性化,不能使用自己看得懂的语言,也是无济于事。
因此 Unicode 码就诞生了。
Unicode(Universal Multiple-Octet Coded Character Set,通用多八位编码字符集),简称 UCS,国际标准编号 ISO/IEC 10646,是由 ISO 和 IEC 两家国际标准组织联合成立的工作组设计的一套新的统一字符集项目,目的与 Unicode 联盟一样致力于开发一款全世界通用的编码集。
早在 1984 年 ISO 和 IEC 两家组织就成立了一个联合工作组来设计一套新的统一字符集标准,但是这两个组织都不知道对方的存在,直到 Unicode 联盟 1988 年发布了 Unicode 草案(UCS 草案 1989 年发布),才发现大家在做同一件事,没有必要搞两套标准所以后面又考虑合并。
ISO 规定,必须用两个字节,也就是 16 位二进制来统一的表示所有的字符。这 16 位二进制的数值就被称为 “code point”,也就是码点,说白了就是每个字符的编号而已,这个和 ASCII 码的编号是一样的概念,只是换了个名字而已。就比如,码点 0x41 就表示大写字母 ‘A’。
最初的 ASCII 码是 7 位的,后来发展成了 8 位,因此 ASCII 码的范围就是 0x00 ~ 0xFF。Unicode 是 16 位的,范围就是 0x0000 ~ 0xFFFF,也就是四位十六进制表示这一个 Unicode 字符的,比如 “汉” 的 Unicode 码点是 Ox6C49。
Ps: 需要注意的一点是,这里用两个字节来表示一个 Unicode 字符,并不是说实际存储也是用两个字节来进行存储一个字符的。并不是这样的。在存储的时候,可以用大于两个字节的空间去存储它,就像在 32 位电脑上用四个字节去存储一个整数 1,尽管是用一位就够了。
3、UTF-8
UTF-8(Universal Character Set/Unicode Transformation Format,8 位元)是针对 Unicode 的一种可变长度字符编码。它可以用来表示 Unicode 标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理 ASCII 字符的软件无须或只进行少部分修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。
3.1、Unicode 码和 UTF-8 的关系
通过 ISO(国际标准化组织)这个组织的名字也看得出来,它是一个专门制定标准的组织,就例如著名的 ISO 网络七层模型,这网络七层模型就是 ISO 制定出来的网络通讯标准,但是呢,大家也知道,实际上我们真正网络的实现上,并没有完全套用那七层模型,而是我们熟知的 TCP/IP 的四层模型。这里就出现了刚提到的实现和制定的标准上的差异。
至于为什么会出现这样的差异问题,这就是理论和实践的不同导致的,虽然很多理论看起来说起来是十分完美的,但是真正运用到生活中的结果缺不得而知,我们知道时间是检验真理的唯一标准,UTF(Unicode Transformation Format,Unicode 转换格式) 就是这样的产物。
UTF-8 就是专门对 Unicode 这套理论标准的一种具体实现。UTF-8 是参照 Unicode 标注而做出来的真正能用于实际生活的一套东西。说白了就是:Unicode 是一套方案,是理论知识,而 UTF-8 是具体实现。而 Unicode 的实现也很多,UTF-8 是 Unicode的具体实现之一,此外还包括,UTF-16 和 UTF-32。
3.2、UTF-8 具体实现
Unicode 虽然能容纳上百万数量的字符 ,但它只是一个巨大的字符集而已,仅仅规定了每个符号的二进制代码表示,然鹅并没有制定具体的存储规则,因此它仅限于概念,没有具体落实到底该怎么去实现。因此到目前为止还只是纸上谈兵。这导致 Unicode 有不少问题,比如当用 3 个字节存储一个 Unicode 字符的时候,它同时也可以被理解为存储了 3 个大小为 1字节的ASCII码,这是具有二义性的。 另外,我们之前知道 ASCII 码只需要一个字节,但是,如果 Unicode 规定每个字符都用 3 个字节来存储的话,那岂不是活生生浪费了两个字节的空间?所有这些未经细化的问题都将导致 Unicode的 不一致性, 因此导致 Unicode 在很长一段时间内无法推广。
UTF 的出现,就解决了上述提到的 Unicode 问题,而 UTF-8 实现方式又是最通用和常见的一种方式了。因此我们在这里将介绍 UTF-8 的具体实现,让你真正认识到什么是 UTF-8.
UTF-8 最大的一个特征就是变长存储的编码方式。它可以使用1 ~ 4个字节去存储不同的字符,根据不同的字符选择最合适的字节长度去进行存储。这样就起到了合理利用存储空间的作用。
UTF-8 的编码规则很简单,只有两条:
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语宇母, UTF-8 编码和 ASCII 码是相同的;
- 对于 n 字节的符号(n>1),第 一个字节的前 n 位都设为 1,第 n+1 位设为 0,后面字节的前两位一律设为 10(注意这里说的是二进制10)。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码.
3.3、UTF-8 具体实现的详细解读
一个字节的时候: UTF-8 遇到一个字节的时候,为了做到兼容 ASCII 码,它的做法就很干脆,就把最高位设为 0,后七位直接使用 ASCII码 编码规则来进行存储。这样做完美做到了兼容 ASCII 码;

当大于一个字节的时候: 由于 UTF-8 编码是变长的,因此就出现了一个亟待解决的问题,就是,怎么知道当前的一个 UTF-8 编码到底占用几个字节空间?因此就必须得有一种方式来标记当前的 UTF-8 编码占用了多少个字节。
大于一个字节的时候,我们把第一个字节称为 “高字节”,其余的所有字节都称之为 “低字节”。
当此编码用几个字节存储,那么它的高字节的前几位就为 1,然后紧接着的一位设置为 0。其余所有低字节的高两位固定为 10。为了叙述方便,我们把高字节和低宇节中那些用以标识 UTF-8 特征的位(不能用于存储数据的位)暂称为标记位。如果一个 UTF-8 编码占用了 n 个字节,高字节的高 n 位就都是 1,第 n+1 位是 0。低字节的高位均以 10 开头。除了各字节高位的标记位之外的其他位才是真正存储数据的位,暂称为数据位。
3.4、问题 1 : 为什么第 n+1 位是 0 呢 ?
从上面我们知道,UTF-8 的高字节的决定了当前编码占据多少字节。在读取的时候是怎么确定当前编码占据多少字节的呢 ?就是从高字节的最高位开始读取,发现是当前位是 1,就加一个字节,那么,怎么知道高字节中的标记位在什么时候结束呢 ?我们也知道,数据位也是能存储1的,那么怎么知道在读取高字节的位数数值的时候,当前位是数据位还是标记位呢 ?那么,为了解决这个问题,最好的解决方法就是在标记位的所有 1 的后面紧跟着一个 0 就行了,在读取数值的时候,从最高位开始读取,当读取到第一个 0 的时候,就认定当前的标记位读取结束,这时候读取到多少个 1,就说明当前编码占用多少个字节。就此完美解决这个问题。
3.5、问题 2 : 为什么 2 字节及以上包括的 UTF-8 编码 ,低字节的高 2 位始终是固定的 10 呢 ?
我们上面提到过 UTF-8 会去兼容 ASCII 码,但是 UTF-8 的编码规则和 ASCII 不同,必须要特殊处理 ASCII 码。 任何编码在底层上都是二进制字节流 ,解码器在获得 1 字节的二进制数据时,如何知道这是 ASCII 码,还是 UTF-8 编码的高字节或低字节呢?所以 UTF-8 首先要做的是在二进制字节上必须与 ASCII 区分开来,即在这 1 字节数据上做标记,通过标记就知道这是 UTF-8编码还是 ASCII 码。ASCII 是单字节,2 字节以上的数据用 UTF-8 编码才有意义,否则 1 个字节就够用的话就直接用 ASCII 了。
ASCII 码范围是 0 ~ 127, 因此其最高位是 0,而 2 字节以上的 UTF-8 编码其高字节最高位是 1,这样高字节己经可以和 ASCII 区分了,那么低字节如何和 ASCII 区分呢?你可能会说,只要 UTF-8 编码中低字节最高位也不为 0 就可以了,即只要是 1 就行 。
其实不然,仅仅最高位为 1 是区分不了的。因为如果只要求最高位是 1,那么就有可能和高字节混淆,比如二进制 11001101,这是 UTF-8 的高字节还是低字节?
没有办法区分。那么,最不可能成为 UTF-8 高字节标记位的就是 10,我们假设 10 是高字节的标记位,按照 UTF-8 编码规则,说明 UTF-8 编码只用了 1字节,显然这是矛盾的,因为在 UTF-8 中 1 字节的字符用其兼容的 ASCII 码表示,最高位是 0,而不是 1,因此 UTF-8 至少要 2 字节以上才有意义,1 字节纯粹是为了兼容 ASCII 码,所以采用 10 作为低字节的标识位才是最合适的。既然标识位 10 只能出现在低字节的高 2 位 ,那么反过来说, UTF-8 编码中以 10 开头的都是低字节。低字节有了这个特性便具备了校验的能力,比如读取 UTF-8编 码的高字节后,确保后面的低字节必须以 10 开头才是正确的 UTF-8 编码。
结语: 我们现在已经知道了,Unicode 和 UTF-8到底是什么了。并且我们也能够知道,当当前的 UTF-8 编码是两个字节的时候,实际上,用于存储数据的位数是没有满满的两个字节(16位),而是 11 位。为什么呢?因为高字节的前三位110是标志位,低字节的前两位 10 是标志位,因此总共的标志位就有 5 位,剩余的存储为只有11位了。同理,我们也能通过存储占用的空间大小来反推出 UTF-8 编码占据多少字节。





![【错误记录】HarmonyOS 运行报错 ( Failure[MSG_ERR_INSTALL_FAILED_VERIFY_APP_PKCS7_FAIL] )](https://img-blog.csdnimg.cn/direct/4a74204e8b4d41dd89b74bcbc527154c.png)