从此音尘各悄然
春山如黛草如烟
目录
list 的结点设计
list 的迭代器
list 的部分框架
迭代器的实现
容量相关相关函数
实现 insert 在指定位置插入 val
实现 push_back 在尾部进行插入
实现 erase 在指定位置删除
实现 pop_back 在尾部进行删除
实现 list 的头插、头删
实现 list 的访问首末元素
实现 list 的清空 clear
实现 list 的迭代器构造
list 的拷贝构造
list 的赋值构造
list 的链式构造
list 的 n 个 val 构造
全部代码展示:


契子✨
上篇我们已经实现了 vector 的部分接口,相较于 vector 的连续空间,list 就显得复杂的多。主要体现在其迭代器的实现上
我们知道 vector 的空间是连续的,所以我们可以直接对原生指针进行操作,例如只需 ++ 就可以访问当前空间的下一个位置。而 list 因为空间是不连续的,所以我们不能直接使用 ++ 等迭代器的相关操作,必须对迭代器进行重新封装
list 的优点:每次安插或者删除一个元素,就配置或者释放一个元素的空间。因此 list 对空间的利用率有绝对的精华,一点都不浪费。而且对任何位置的元素安插或者元素移除,list 永远都是常数时间
list 的结点设计
学过数据结构的我们知道:list 的本身与 list 的结点是不同的结点,需要分开设计:
就是以下的设计:设置一个节点的前驱与后继指针、数据域
因为 list 支持所有类型,所以我们使用模板即可 ~
由于我们想要实现默认构造,可以由匿名对象 T() 来实现这个效果
T() 如果是自定义类的变量就会自动调用 T类型 的构造函数创造一个匿名对象,并用其为给引用 val 做初始化。因为 val 是一个 const 类的引用,所以它可以延长匿名对象的生命周期,简单来说 const 与 非const 对象都可以使用
template<class T>
struct ListNode
{
ListNode(const T& data = T())
:_prev(nullptr),_next(nullptr),_data(data)
{}
ListNode<T>* _prev;
ListNode<T>* _next;
T _data;
};✨ 关于这里为什么用 struct 而不用我们 C++ 常用的 class,因为 struct 没有类域的限制,外部能够直接访问,而 class 默认就是 private 修饰,外部不能直接访问。但是我们 list 的操作需要频繁访问类中成员,比如修改结点指向、访问数据域等。虽然我们 calss 可以用 public 进行修饰,但是我们 C++ 的编程习惯就是需要频繁访问的类,直接用 struct 就可以了 -- 直接访问
list 的迭代器
list 不能够像 vector 一样以原生指针作为迭代器,因为其结点不保证在存储空间中连续存在。而 list 迭代器必须具备指向 list 结点,并有能力做正确的自增、自减、取值、成员取用等操作。简单来讲就是自增时指向下一个结点,自减时指向上一个结点,取值时就是访问当前结点的数据域 data 相当于(*),成员取用相当于(->)
那么我们该如何实现这样看起来很复杂的迭代器呢?
我们可以对 list 迭代器的性质进行分装💞
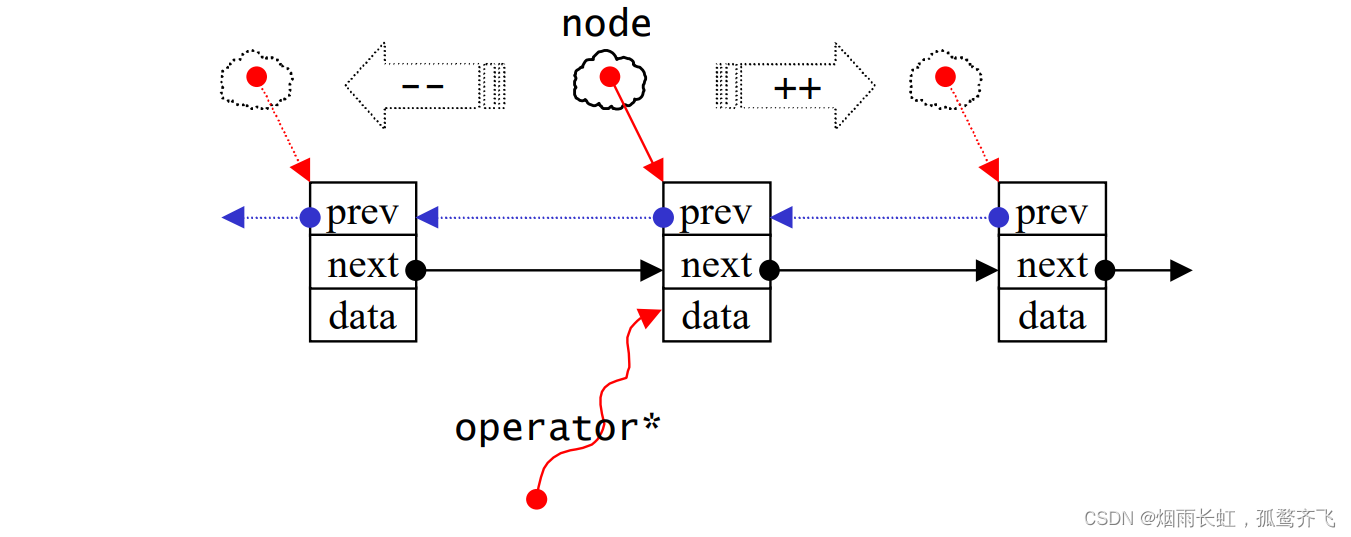
迭代器的性质:在 vector 中我们知道顺序表扩容会导致迭代器失效,因为 vector 会导致空间的重新配置。而我们的 list 的扩容操作相当于插入结点,这样并不会导致迭代器失效哦 ~ 例如:push_back、insert 等操作。但是注意:list 的删除操作(erase),也只有 [被指向删除元素] 的那个迭代器失效,其他迭代器不受影响 ~

废话不多说 ~ 让我们看看怎么实现的:
template<class T, class Ref, class Ptr>
struct ListIterator
{
typedef ListNode<T> Node;
typedef ListIterator<T, Ref, Ptr> self;
Node* _node; //迭代器內部当然要有一个原生指针,指向 list 的结点
ListIterator(Node* node)
:_node(node)
{}
bool operator==(const self& x)
{
return _node == x._node;
}
bool operator!=(const self& x)
{
return _node != x._node;
}
//取节点的资料--数据域
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &(_node->_data);
}
//自增就是访问下一个结点
self& operator++()
{
_node = _node->_next;
return *this;
}
self operator++(int)
{
self tmp = *this;
++*this;
return tmp;
}
//自减就是回退到上一个结点
self& operator--()
{
_node = _node->_prev;
return *this;
}
self operator--(int)
{
self tmp = *this;
--*this;
return tmp;
}
};可能有老铁会问 ~ 为什么我们的模板有三个参数
template<class T, class Ref, class Ptr>因为我们要设置两个迭代器 const 与 非const
一个模板参数来写的话,可以这样 ~
template<class T>
struct ListIterator
{
typedef ListNode<T> Node;
typedef ListIterator<T> Self;
Node* _node;
ListIterator(Node* node)
:_node(node)
{}
Self& operator++()
{
_node = _node->_next;
return *this;
}
Self& operator--()
{
_node = _node->_prev;
return *this;
}
Self operator++(int)
{
Self tmp(*this);
_node = _node->_next;
return tmp;
}
Self& operator--(int)
{
Self tmp(*this);
_node = _node->_prev;
return tmp;
}
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
bool operator!=(const Self& it)
{
return _node != it._node;
}
bool operator==(const Self& it)
{
return _node == it._node;
}
};不过还需在写一个 const 的版本,不过我们用三个模板参数就可以避免这个问题
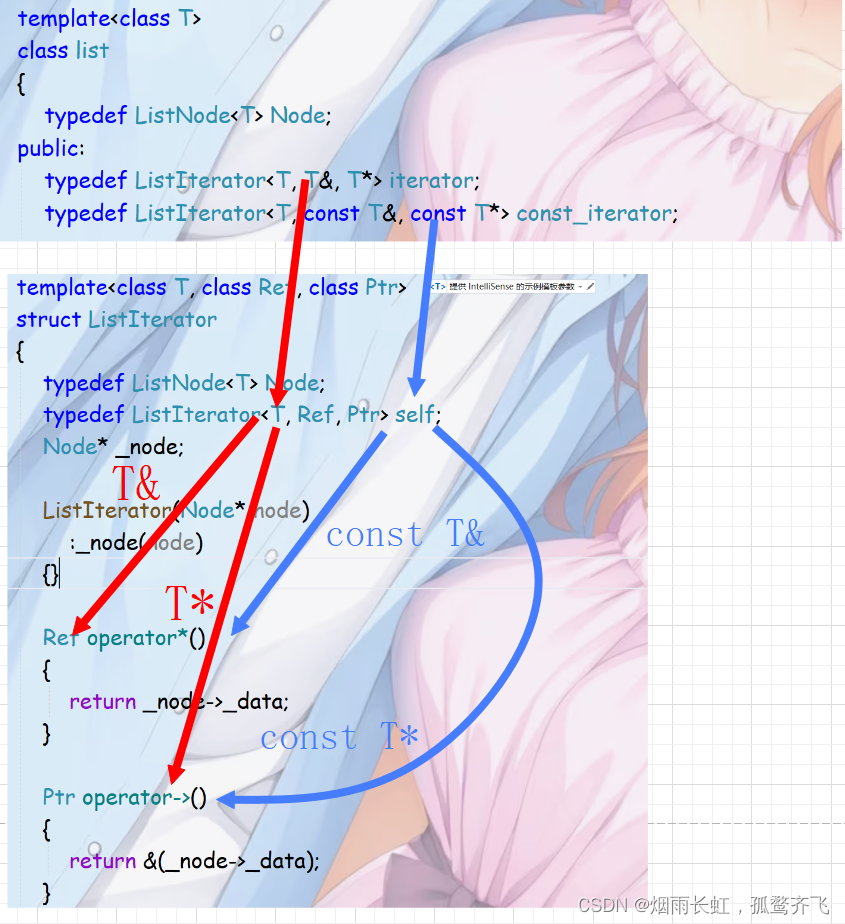
因为只有(*)、(->)这两种运算符重载需要的返回值不同,所以我们只需要针对这两个返回值设置两个模板进行替换即可,就像以上操作

这样我们的迭代器已经封装好了,接下来我们在具体实现 list 的功能了
list 的部分框架
因为 list 不仅是一个单向的串列,而是一个环状单向串列(双向链表),所以它只需一个指标 _head 便可以完整的表示整个串列
template<class T>
class list
{
typedef ListNode<T> Node;
public:
typedef ListIterator<T, T&, T*> iterator;
typedef ListIterator<T, const T&, const T*> const_iterator;
void empty_initialize()
{
_head = new Node();
_head->_prev = _head;
_head->_next = _head;
}
//构造函数
list()
{
empty_initialize();
}
//析构函数
~list()
{
Node* cur = _head;
while (cur != _head)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
delete _head;
cur = _head = nullptr;
}
private:
Node* _head;
};
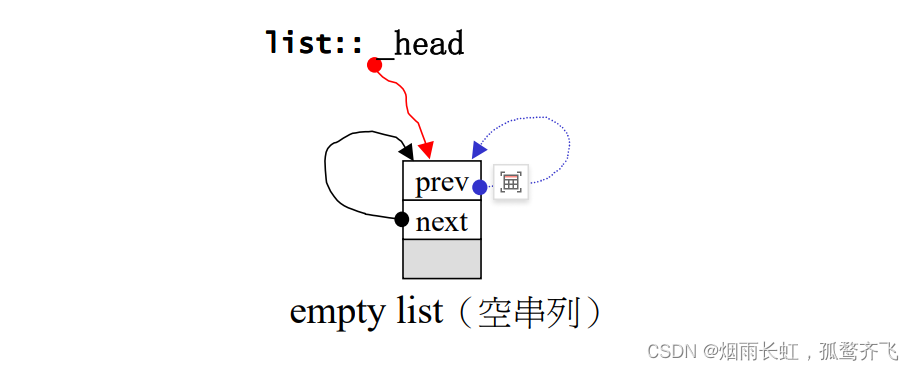
可能有老铁会问 ~ 为什么我们要用一个函数 empty_initialize() 进行构造,原因是我们以后还需要复用,所以写成一个函数效率高
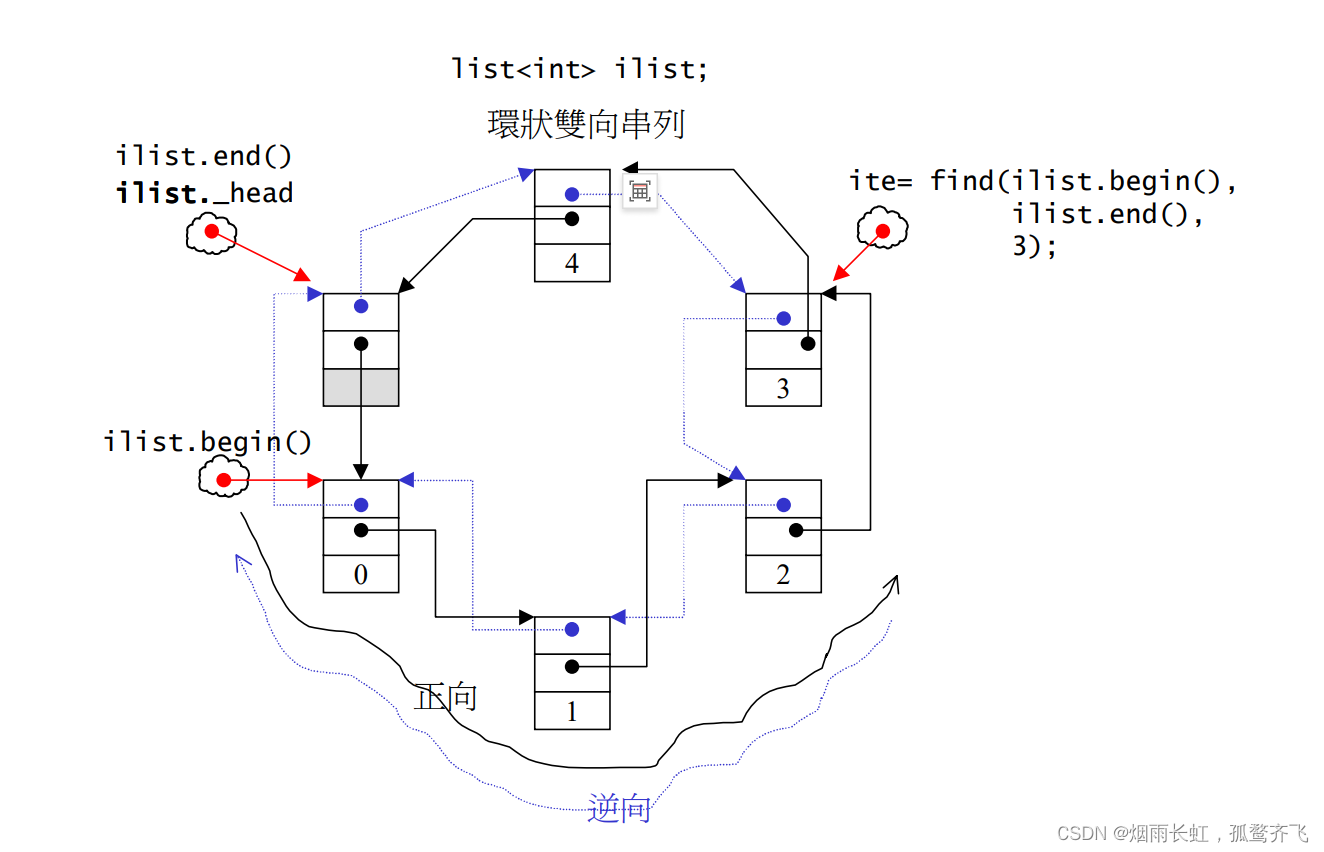
指针 _head 相当于我们双向循环链表的(哨兵位),我们只要让它刻意的指向尾端的一个空白结点,便能符合 STL 对 [前闭后开] 的区间要求,成为 end() 迭代器,而只需从 _head 的下一个结点开始就可以成为 begin() 迭代器
迭代器的实现
iterator begin()
{
return iterator(_head->_next);
}
const_iterator begin() const
{
return const_iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
const_iterator end() const
{
return const_iterator(_head);
}
然后一些 ~ 相关的接口函数就一并写在这里:
容量相关函数
bool empty() const
{
return _head->_next == _head;
}
size_t size() const
{
size_t count = 0;
Node* cur = _head->_next;
while (cur!=_head)
{
cur = cur->_next;
++count;
}
return count;
}
 怎么样 ~ 学到这里有没有难住各位老铁们呢?
怎么样 ~ 学到这里有没有难住各位老铁们呢?
实现 insert 在指定位置插入 val
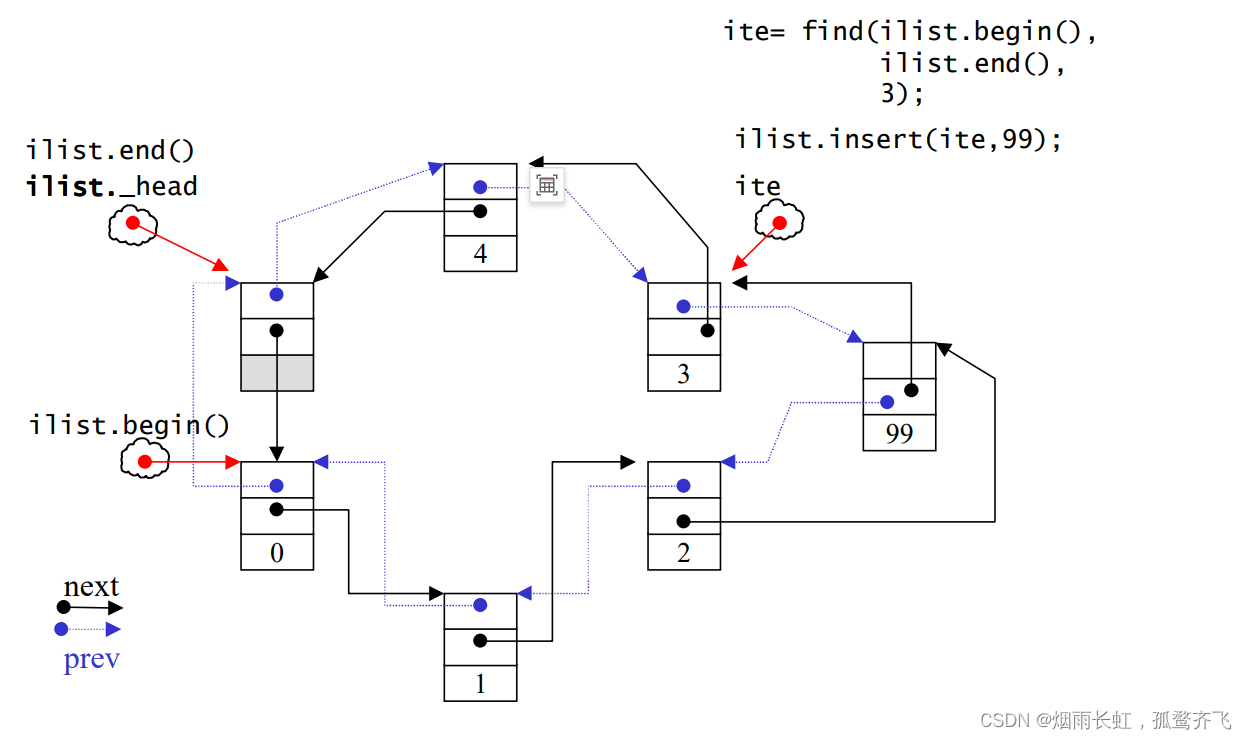
上图模拟了安插 新结点99 在 结点3 的位置上,简单来说 insert 就是插入指定位置之前的位置
虽然我们之前说过 insert 的操作并不会使迭代器失效,但是为了使 STL 其中的容器接口统一,还是要更新一下迭代器的位置
iterator insert(iterator pos, const T& val)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newNode = new Node(val);
prev->_next = newNode;
newNode->_next = cur;
newNode->_prev = prev;
cur->_prev = newNode;
return newNode;
}既然写出来了,那么最好的验证方法就是测试以下:(先来测试以下以上的案例)

但是呢 ~ 我们的迭代器不支持 + 哦(STL库没有提供)

不过呢,我们可以借助 find()
不过这个 find() 需要我们自己在库中实现呢:
iterator find(iterator first, iterator last, const T& val)
{
while (first != last)
{
if (*first == val) return first;
++first;
}
return last;
}给两个迭代器的区间范围进行查找,并返回查找位置的迭代器即可
我们再来测试一下:
void Test_List()
{
list<int> str;
str.push_back(0);
str.push_back(1);
str.push_back(2);
str.push_back(3);
str.push_back(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
list<int>::iterator it = str.find(str.begin(), str.end(), 3);
if(it != str.end())
str.insert(it, 99);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
}
实现 push_back 在尾部进行插入
因为我们的 insert() 已经完成啦 ~ 所以这里就可以选择直接复用
void push_back(const T& val)
{
insert(end(), val);
}当然你想自己写也可以 ~
void push_back(const T& val)
{
Node* newNode = new Node(val);
Node* tail = _head->_prev;
tail->_next = newNode;
newNode->_prev = tail;
_head->_prev = newNode;
newNode->_next = _head;
}代码测试:
void Test_List()
{
list<int> str;
str.push_back(0);
str.push_back(1);
str.push_back(2);
str.push_back(3);
str.push_back(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
}
实现 erase 在指定位置删除
移除元素对于我们来说还是比较简单的,就如下图移除 结点元素1 一样,只需找到删除当前的前驱与后继结点,然后两个结点相互(牵手)并与删除结点断掉联系,然后 delete 掉删除结点即可
注意:需要好好的断言一下哦 ~ 不要删到最后出现乱码

因为 erase 操作导致被删除的那个结点的迭代器失效了,为了保证迭代器的正确性,我们需要提供被删除结点的下一个位置的迭代器 -- 才能使迭代器完好
iterator erase(iterator pos)
{
assert(pos != end());
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* next = cur->_next;
prev->_next = next;
next->_prev = prev;
delete cur;
cur = nullptr;
return next;
}代码测试:
void Test_List()
{
list<int> str;
str.push_back(0);
str.push_back(1);
str.push_back(2);
str.push_back(3);
str.push_back(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
list<int>::iterator it = str.find(str.begin(), str.end(), 1);
if (it != str.end())
str.erase(it);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
}
实现 pop_back 在尾部进行删除
既然我们已经写好 erase 那么们能复用就复用吧
void pop_back()
{
erase(--end());
}代码测试:
void Test_List()
{
list<int> str;
str.push_back(0);
str.push_back(1);
str.push_back(2);
str.push_back(3);
str.push_back(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
str.pop_back();
str.pop_back();
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
}
实现 list 的头插、头删

有道是
能复用绝不会自己写
void push_front(const T& val)
{
insert(begin(), val);
}
void pop_front()
{
erase(begin());
}
push_front、pop_front 完全可以借助我们前面的 insert、erase 的操作,可以偷懒何乐而不为呢?
代码测试:
void Test_List()
{
list<int> str;
str.push_front(0);
str.push_front(1);
str.push_front(2);
str.push_front(3);
str.push_front(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
str.pop_front();
str.pop_front();
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
}

实现 list 的访问首末元素
list 底层使用的空间是不连续的,因此不能像 vector 那样能依靠下标直接访问空间中的元素, list 中只有首元素和尾元素可以直接访问,因为他们都是和头结点直接接触的,而其他结点的访问需要遍历链表,因此 C++ 中只给出了首元素和尾元素的访问函数,如果要访问其他元素,则需要用户自己去遍历
获取首元素 front:
T& front()
{
assert(size() != 0);
return _head->_next->_data;
}
const T& front()const
{
assert(size() != 0);
return _head->_next->_data;
}获取末元素 back:
T& back()
{
assert(size() != 0);
return _head->_prev->_data;
}
const T& back()const
{
assert(size() != 0);
return _head->_prev->_data;
}代码测试:
void Test_List()
{
list<int> str;
str.push_back(0);
str.push_back(1);
str.push_back(2);
str.push_back(3);
str.push_back(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
cout << str.front() << endl;
cout << str.back() << endl;
}
实现 list 的清空 clear
学过之前的知识我们都知道 clear 具有清空的功能,而我们链表可以循环删除来实现这个操作,不过要注意更新迭代器哦 ~
void clear()
{
auto it = begin();
while (it != end())
{
it = erase(it);
}
}代码测试:
void Test_List()
{
list<int> str;
str.push_back(0);
str.push_back(1);
str.push_back(2);
str.push_back(3);
str.push_back(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
str.clear();
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
}
我们的 clear 操作也可以运用到我们的析构函数中
~list()
{
clear();
delete _head;
_head = nullptr;
}实现 list 的迭代器构造
与我们之前写的 vector 一样都有一个迭代器构造,简单来说也就是说对于一个已经由 list 实例化的 str 可以通过迭代器区间帮助还未初始化的 arr 初始化
首先构造一个 list 的对象,再将已知对象的迭代器区间结点尾插到我们需要初始化的对象上
template <class Iterator>
list(Iterator first, Iterator last)
{
empty_initialize();
while (first != last)
{
push_back(*first);
++first;
}
}我们浅浅的测试一下:
void Test_List()
{
list<int> str;
str.push_back(0);
str.push_back(1);
str.push_back(2);
str.push_back(3);
str.push_back(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
list<int> arr(++str.begin(), --str.end());
for (auto i : arr)
{
cout << i << " ";
}
cout << endl;
}
list 的拷贝构造
在写 list 之前呢 ~ 我们先来实现一下 swap 交换函数吧 !
void swap(list<T>& li)
{
std::swap(li._head, _head);
}我们实现 list 的拷贝一般都是深拷贝(拷贝的空间地址与原空间不一样)
所以先构造一个对象,在复用我们的迭代器构造,最后让我们的 *this 与之交换即可
list(const list<T>& li)
{
empty_initialize();
list<T> tmp(li.begin(), li.end());
swap(tmp);
}代码测试:
void Test_List()
{
list<int> str;
str.push_back(0);
str.push_back(1);
str.push_back(2);
str.push_back(3);
str.push_back(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
list<int> arr(str);
for (auto i : arr)
{
cout << i << " ";
}
cout << endl;
} 通过调试我们可以看到:两块空间的地址是不一样的(说明我们的深拷贝是没有问题的)
通过调试我们可以看到:两块空间的地址是不一样的(说明我们的深拷贝是没有问题的)
老铁们学废了吗

list 的赋值构造
list<T>& operator=(list<T> li)
{
swap(li);
return *this;
}
赋值拷贝呢 -- 我们可以通过传值的技巧来解决,传值传参调用拷贝构造,构造出一个临时对象,然后将我们的 *this 与之交换即可
代码测试:
void Test_List()
{
list<int> str;
str.push_back(0);
str.push_back(1);
str.push_back(2);
str.push_back(3);
str.push_back(4);
for (auto i : str)
{
cout << i << " ";
}
cout << endl;
list<int> arr;
arr = str;
for (auto i : arr)
{
cout << i << " ";
}
cout << endl;
}
list 的链式构造
list(initializer_list<T> il)
{
empty_initialize();
for (const auto& i : il)
{
push_back(i);
}
}代码测试:
void Test_List()
{
list<int> arr = { 1,2,3,4,5,6 };
for (auto i : arr)
{
cout << i << " ";
}
cout << endl;
}
list 的 n 个 val 构造
list(size_t n, const T& val = T())
{
empty_initialize();
for (size_t i = 0; i < n; i++)
{
push_back(val);
}
}
list(int n, const T& val = T())
{
empty_initialize();
for (size_t i = 0; i < n; i++)
{
push_back(val);
}
}关于我们为什么要写 int 类型的重载可以看看我的上篇文章:
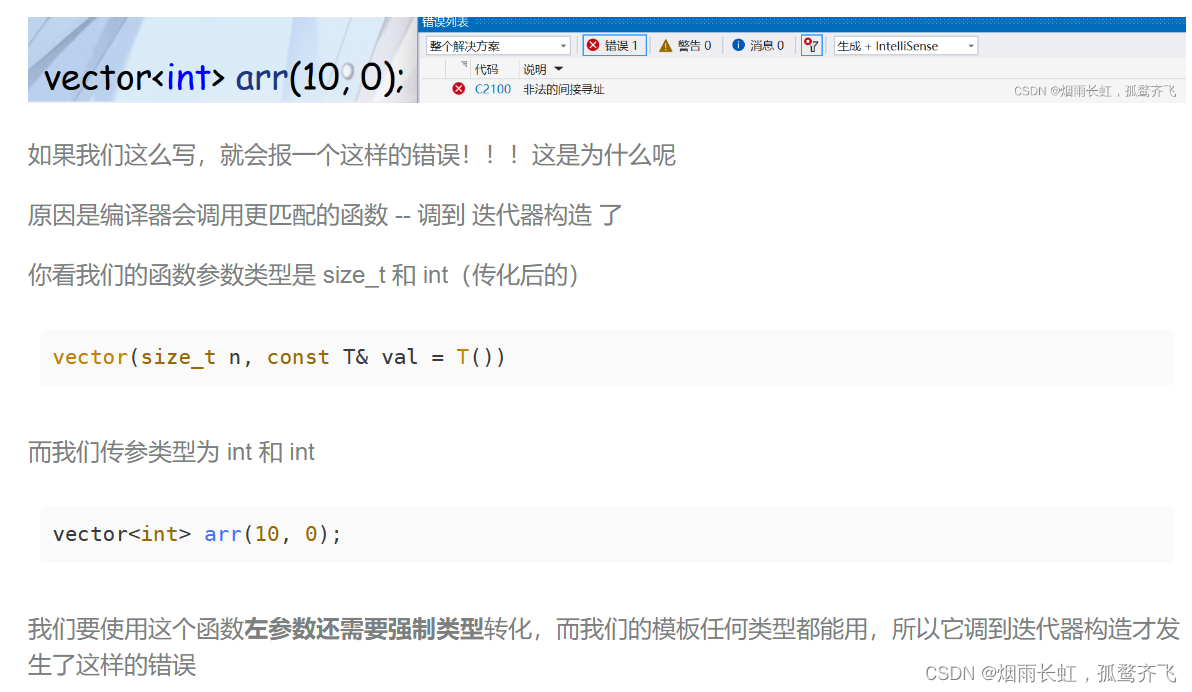
因为编译器会调用更匹配的函数 ~ 比如那个迭代器的构造就很合适,为了避免这种情况,我们选择重载 int
代码测试:
void Test_List()
{
list<int> arr(10, 1);
for (auto i : arr)
{
cout << i << " ";
}
cout << endl;
}
list 的结构除了迭代器以外
其实与 vector 蛮相似的

全部代码展示:
#include<assert.h>
#include<list>
using std::initializer_list;
namespace Mack
{
template<class T>
struct ListNode
{
ListNode(const T& data = T())
:_prev(nullptr),_next(nullptr),_data(data)
{}
ListNode<T>* _prev;
ListNode<T>* _next;
T _data;
};
template<class T, class Ref, class Ptr>
struct ListIterator
{
typedef ListNode<T> Node;
typedef ListIterator<T, Ref, Ptr> self;
Node* _node;
ListIterator(Node* node)
:_node(node)
{}
bool operator==(const self& x)
{
return _node == x._node;
}
bool operator!=(const self& x)
{
return _node != x._node;
}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &(_node->_data);
}
self& operator++()
{
_node = _node->_next;
return *this;
}
self operator++(int)
{
self tmp = *this;
++*this;
return tmp;
}
self& operator--()
{
_node = _node->_prev;
return *this;
}
self operator--(int)
{
self tmp = *this;
--*this;
return tmp;
}
};
template<class T>
class list
{
typedef ListNode<T> Node;
public:
typedef ListIterator<T, T&, T*> iterator;
typedef ListIterator<T, const T&, const T*> const_iterator;
template <class Iterator>
list(Iterator first, Iterator last)
{
empty_initialize();
while (first != last)
{
push_back(*first);
++first;
}
}
void swap(list<T>& li)
{
std::swap(li._head, _head);
}
list(const list<T>& li)
{
empty_initialize();
list<T> tmp(li.begin(), li.end());
swap(tmp);
}
list<T>& operator=(list<T> li)
{
swap(li);
return *this;
}
void empty_initialize()
{
_head = new Node();
_head->_prev = _head;
_head->_next = _head;
}
list()
{
empty_initialize();
}
~list()
{
clear();
delete _head;
_head = nullptr;
}
list(initializer_list<T> il)
{
empty_initialize();
for (const auto& i : il)
{
push_back(i);
}
}
list(size_t n, const T& val = T())
{
empty_initialize();
for (size_t i = 0; i < n; i++)
{
push_back(val);
}
}
list(int n, const T& val = T())
{
empty_initialize();
for (size_t i = 0; i < n; i++)
{
push_back(val);
}
}
iterator begin()
{
return iterator(_head->_next);
}
const_iterator begin() const
{
return const_iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
const_iterator end() const
{
return const_iterator(_head);
}
void push_back(const T& val)
{
insert(end(), val);
}
iterator find(iterator first, iterator last, const T& val)
{
while (first != last)
{
if (*first == val) return first;
++first;
}
return last;
}
iterator insert(iterator pos, const T& val)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newNode = new Node(val);
prev->_next = newNode;
newNode->_next = cur;
newNode->_prev = prev;
cur->_prev = newNode;
return newNode;
}
void pop_back()
{
erase(--end());
}
iterator erase(iterator pos)
{
assert(pos != end());
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* next = cur->_next;
prev->_next = next;
next->_prev = prev;
delete cur;
cur = nullptr;
return next;
}
void push_front(const T& val)
{
insert(begin(), val);
}
void pop_front()
{
erase(begin());
}
bool empty() const
{
return _head->_next == _head;
}
size_t size() const
{
size_t count = 0;
Node* cur = _head->_next;
while (cur!=_head)
{
cur = cur->_next;
++count;
}
return count;
}
T& front()
{
assert(size() != 0);
return _head->_next->_data;
}
const T& front()const
{
assert(size() != 0);
return _head->_next->_data;
}
T& back()
{
assert(size() != 0);
return _head->_prev->_data;
}
const T& back()const
{
assert(size() != 0);
return _head->_prev->_data;
}
void clear()
{
auto it = begin();
while (it != end())
{
it = erase(it);
}
}
private:
Node* _head;
};
}有不对的地方欢迎指出 ~ ✨