1.往期回顾
-
一个简单实用的循环buffer,用于缓冲数据!测试500M数据,耗时1.3秒。
-
C语言版本的循环buffer比C++版本的速度更快!测试500M数据0.5秒,达9.25Gbps左右!
-
C 语言免拷贝版本循环 buffer 比拷贝版本快了近 10 倍!
之前分享过一些循环buffer缓冲区的实现,有C++版本的、C语言版本的、C语言免拷贝版本的,本质上都是基于环形缓冲区思想实现的"一写一读"循环buffer,今天给大家分享一个"一写多读"版本的循环buffer。
2. 简介
”一写多读“循环buffer即一个写者往循环buffer缓冲区写入数据,多个读者从循环buffer缓冲区读取数据,通过管理各种读写指针的位置进行数据保护。通过这种机制实现一份数据共享给不同模块使用且互不干扰,隔离模块,降低耦合。
”一写多读“循环buffer的示意图如下所示,本例中有3个读指针,1个写指针,所有指针顺时针方向移动。红色区域是写指针写入数据,暂无读者读取数据;绿色区域是部分读者未读完数据的区域;黄色区域是所有读者都读完数据的区域。
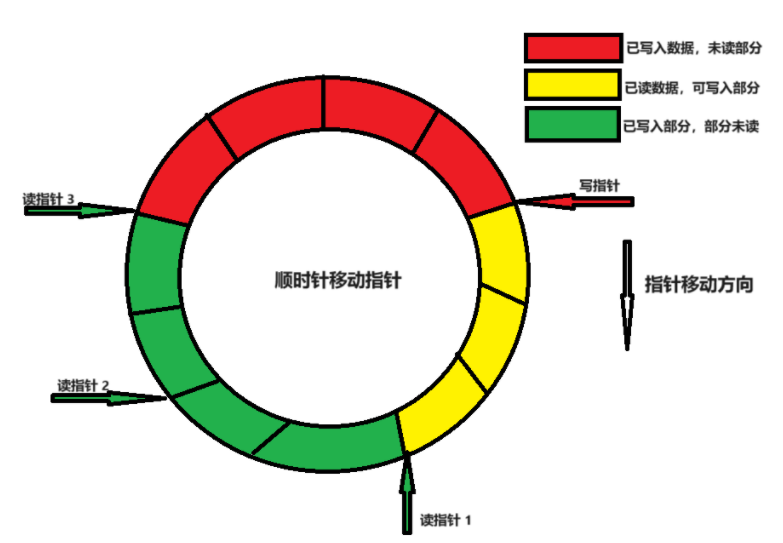
图1 "一写多读"循环buffer 示意图
3. 设计思想
要想实现读写指针流动且访问数据不冲突,即把握两点:对照下图
-
写指针不能追上超过最后一个读指针,即本例中的读指针1,此时对于写指针来讲,可写入数据的空间为黄色部分。
-
所有读者不能追上超过写指针。本例中读指针3此时可读取数据的区域为红色部分;读指针2此时可读取数据区域是蓝色+红色区域;读指针3此时可读取数据区域是绿色+蓝色+红色区域。
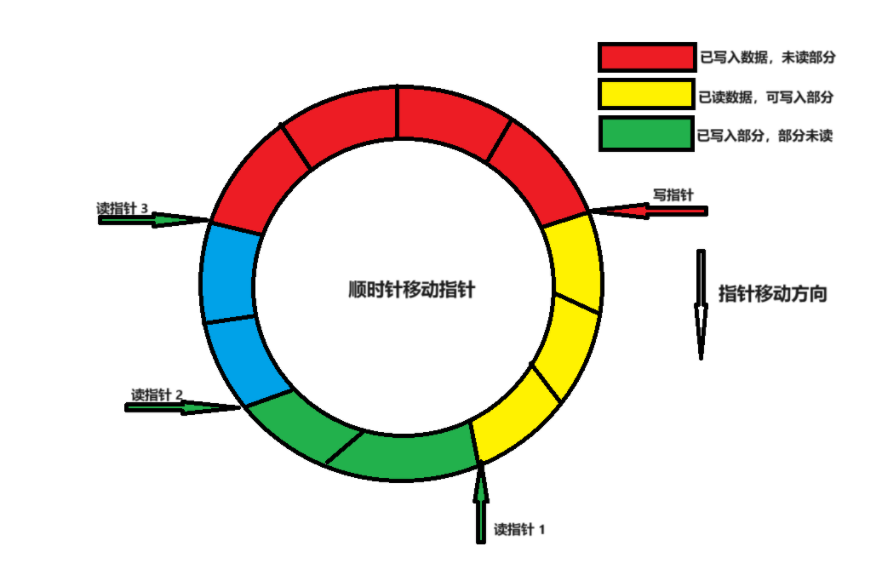
图2 "一写多读循环buffer 指针标识图
4. 设计实现
循环缓冲区本质是一块连续的内存空间,通过管理读写指针位置实现数据共享,如下图所示。当指针到达右边边界即buffer结束地址,通过取余的方式讲指针回环到左边对应位置,实现循环流动。
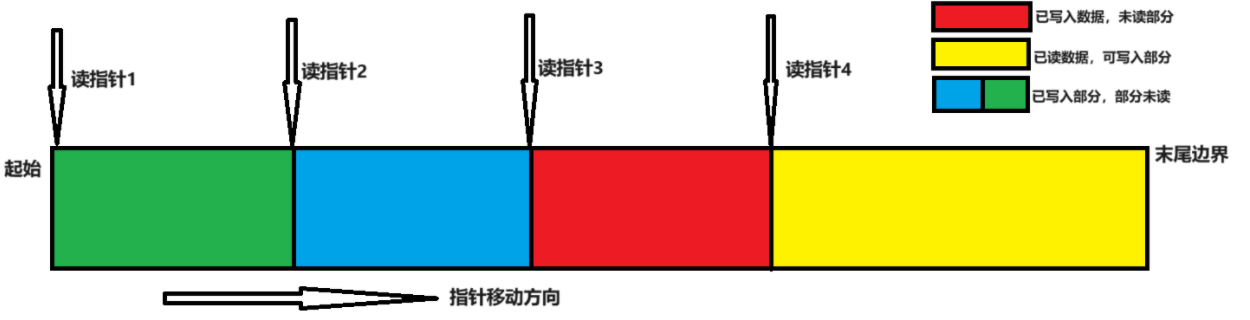
图3 "一写多读"循环buffer 内存布局
结构体设计及函数设计如下,包含写指针,读者数组,因为读者数目可配置。add函数指针实现添加读者,read实现读取数据,write实现向缓冲区写入数据。
typedef struct m_ringbuffer
{
struct readpos_t *arr_pos[MAX_READ_NUM];/* 读者信息数组 */
volatile int w_pos; /* 写入数据指针位置 */
int read_cnt; /* 读者数量 */
int rb_overflow_cnt; /* 记录缓冲区溢出的次数 */
int rb_size, rb_size_mask; /* 缓冲区空间大小 */
uint8_t* rb_buffer; /* 缓存数据空间 */
int (*add)(void* pthis); /* 向循环buffer添加一个读者 */
int (*write)(void* pthis, const uint8_t* buffer, int len); /* 写数据函数 */
int (*read)(void* pthis, int readid, uint8_t **buffer, int len); /* 读数据函数 */
}m_ringbuffer_t;
/**
* @brief 从循环buffer空间读取数据
* @param pthis 循环buffer句柄
* @param readid 读者的id,区分读者
* @param buffer 要的数据指针的地址
* @param len 要读取数据的长度
* @return -1:参数错误 -2:可读空间不够 len:读取的数据长度
*/
static int mrb_read(void* pthis, int readid, uint8_t **buffer, int len);
/**
* @brief 向循环buffer空间写入数据
* @param pthis 循环buffer句柄
* @param buffer 要写入的数据
* @param len 要写入数据的长度
* @return -1:参数错误 -2:可写空间不够 0:写入成功
*/
int mrb_write(void* pthis, const uint8_t* buffer, int len);
/**
* @brief 向循环buffer添加读者
* @param pthis 循环buffer句柄
* @return -1:添加失败 id:读者ID
*/
static int mrb_add(void* pthis);
5. 使用示例
int ret, len, data_len, id;
uint8_t *buf;
//创建缓冲区
m_ringbuffer_t* rb = create_muti_ringbuffer(50*1024);
//添加读者
id = rb->add(rb);
//往循环buffer中写数据
ret = rb->write(rb, buf, data_len);
//从缓冲区读取数据
rb->read(rb, read_id, &buf, data_len);
完整工程代码见:https://github.com/young-1-code/data_structure.git取代码的小伙伴请帮忙点一个star吧~感谢~
编译平台:Linux系统 编译工具:GCC 编译:输入make进行编译,工程测试是读写文件进行的,所以需要给一个数据源路径,可参考往期循环buffer测试,见开篇链接。
图4 代码位置
6.总结
至此我们实现了”一写一读“、”一写多读“循环buffer,每一种实现版本都有它合适的应用场景,需要根据具体需求选择。实现不同的数据结构不是重点,本系列循环buffer有多种不同变体,本质上都是根据循环缓冲区设计实现的,所以重点是一种理解设计思想,通过迁移变换,设计不同数据结构满足不同需求场景。 欢迎大家一起交流学习,帮忙点赞、在看、转发吧~~