流程:
1.Python爬虫采集物流数据等存入mysql和.csv文件;
2.使用pandas+numpy或者MapReduce对上面的数据集进行数据清洗生成最终上传到hdfs;
3.使用hive数据仓库完成建库建表导入.csv数据集;
4.使用hive之hive_sql进行离线计算,使用spark之scala进行实时计算;
5.将计算指标使用sqoop工具导入mysql;
6.使用Flask+echarts进行可视化大屏实现、数据查询表格实现、含预测算法;








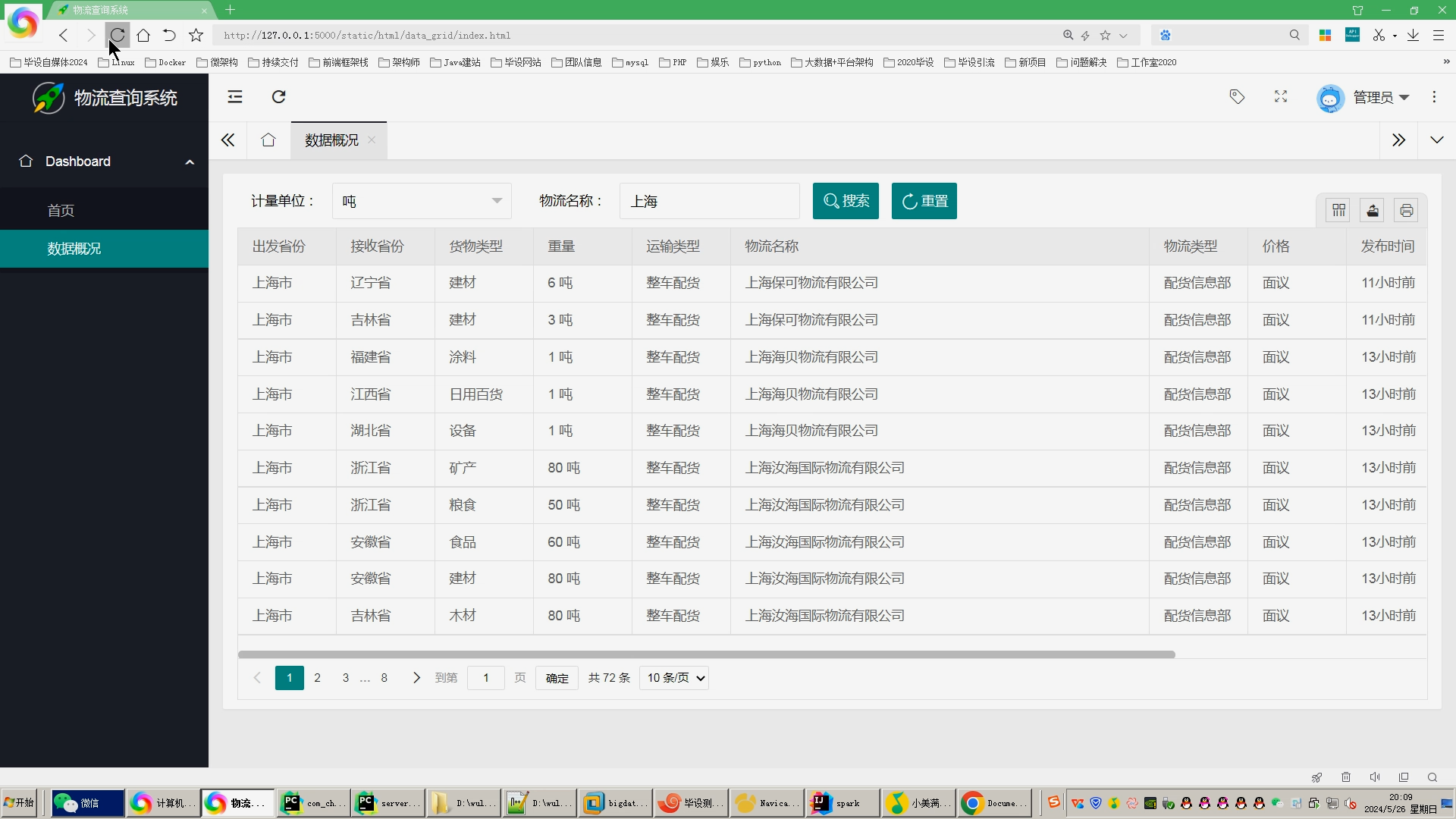
核心算法代码分享如下:
package com.car.process
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object Table01 {
def main(args: Array[String]): Unit = {
// 创建spark入口 读取hive的元数据 查询hive中ods层的表
val hiveSession: SparkSession = SparkSession.builder()
.appName("table01")
.master("local")
.config("spark.hadoop.hive.metastore.uris", "thrift://bigdata:9083")
.enableHiveSupport()
.getOrCreate();
/**
* insert overwrite table tables01
* select province,count(1) num
* from ods_comments
* group by province
*/
// 网友分布中国地图
val dataFrame: DataFrame = hiveSession.sql(
"""
|select from_province,count(1) num
|from hive_chinawutong.ods_chinawutong
|group by from_province
|""".stripMargin)
dataFrame.show()
// 写入到mysql中
dataFrame
.write
.format("jdbc")
.option("url", "jdbc:mysql://bigdata:3306/hive_chinawutong?useSSL=false")
.option("user", "root")
.option("password", "123456")
.option("driver", "com.mysql.jdbc.Driver")
.option("dbtable", "table01")
.mode(SaveMode.Overwrite)
.save()
}
}