文章目录
- 第1讲 什么是生成式人工智慧?
- 第2讲 今日的生成式人工智慧厉害在哪里?
- 第3-5讲 训练不了人工智慧,你可以训练你自己(在不训练模型的情况下强化语言模型的方法)
- 第6讲 大模型修炼史——第一阶段 自我学习 累计实力
第1讲 什么是生成式人工智慧?
- 生成式人工智慧的目的不是进行做有结果的分类,而是使机器生成复杂有结构的物件。今天的生成式人工智慧多以深度学习构成。
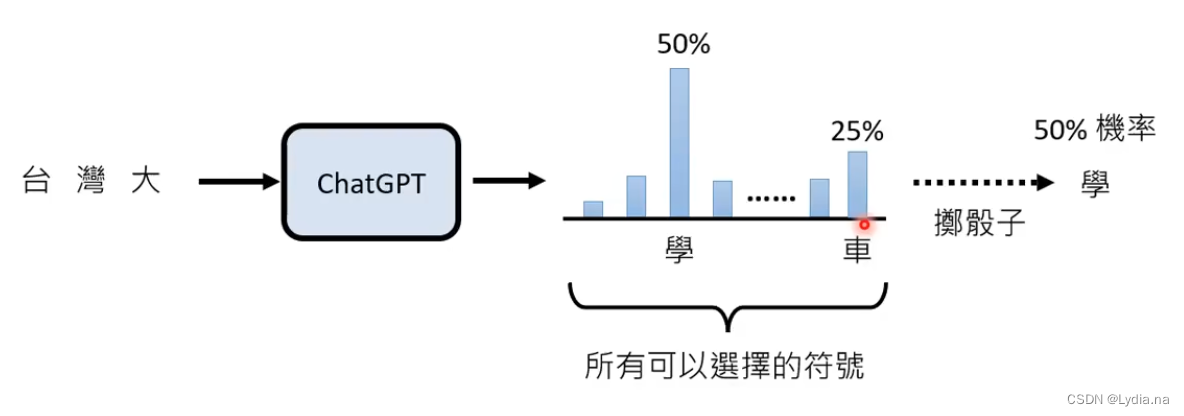
- 以现如今流通最广泛的ChatGPT为例,GPT可以看作一个函数,输入图片、语音或者文字等,“创造性”地输出结果。这里的“创造性”的实现是将问题拆解成一连串的文字进行接龙,转化为分类问题。对于每个结果都有概率,在这个概率的基础上掷骰子,进行输出。
- 如下图所示有百分之五十的概率输出“学”字。那么问题来了,如果每次输出概率最大的不行吗?回答是不行的,因为如果每次输出概率最大的token的话,可能会导致输出重复混乱,所以采用掷骰子的方法。
第2讲 今日的生成式人工智慧厉害在哪里?
如今的GPT能够通过人类下的指示prompt,灵活地完成任务,而不是只有某些特定的功能。
现在人工智慧已经从「工具」进化成「工具人」,那么我还能做什么呢?
- 思路一:我改不了模型,那我改变我自己——给更清楚的指令、提供额外资讯(Prompt Engineering)
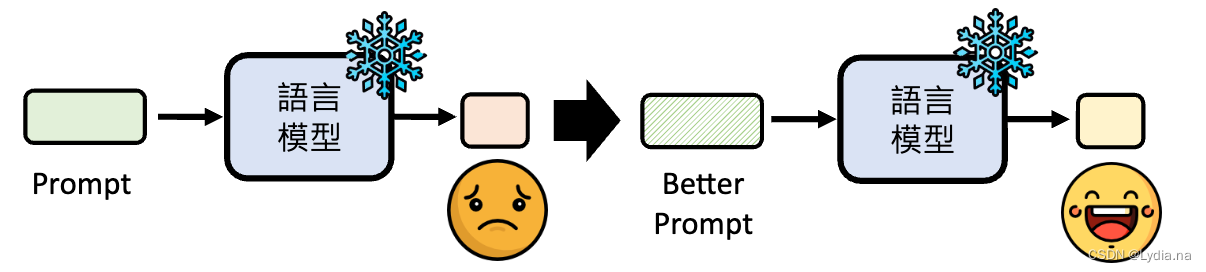
- 思路二:我要自己训练模型

第3-5讲 训练不了人工智慧,你可以训练你自己(在不训练模型的情况下强化语言模型的方法)
按照今天语言模型的能力,只需要把要完成的任务描述清楚即可。
有些在不训练模型的情况下可以训练语言模型的方法:
- 神奇咒语:叫模型一步一步思考
- 提供额外资讯:把前提讲清楚
- 提供生成式AI不清楚的咨询/范例:如文本等信息。In-context Learning
- 拆解任务:把一个大任务,拆解成小任务让GPT逐步完成
- 让语言模型检查自己的错误
- 使用工具:
- 使用搜索引擎:在网络或资料库中搜索额外的信息给语言模型最后输出结果,这个方法又称为Retrieval Augmented Generation(RAG)
- 写代码:解决部分问题时,使用代码进行解决,而不是可能出现错误的文字接龙,这个方法叫做Program of Thought(PoT)
- 文生图AI(DALL-E)
- 除了上述三种工具之外,还有很多GPT插件待探索和发现。
- 语言模型彼此合作:
- 未来不需要打造全能的模型,语言模型可以彼此分工,不同团队可以专注打造专业领域的模型。
- 另外,为了降低模型的成本,可以训练一个模型,选择不同的模型做合适的事情。比如,简单的问题并不需要使用高昂的GPT4进行回答,当训练一个模型可以选择回答模型的时候,简单问题就可以选择GPT3.5进行回答,根据不同问题难度选择不同把成本的模型。
- 让模型彼此讨论得到的结果,对结果进行修正,这样比模型自己反省得到的结果优秀。多模型讨论的方法称做Exchange of Thought。但是现在模型讨论面临的问题时,讨论结束太快,所有在加prompt的时候最好加上:不一定要同意其他人的观点,自己思考如何得到正确的观点。
- 引入不同的角色:根据不同任务引入不同的角色,每个角色给除自己以外的打分,分数太低的就不参与工作。
第6讲 大模型修炼史——第一阶段 自我学习 累计实力
大模型训练的第一阶段:Pre-tain。大模型在第一阶段中从网络中搜寻大量的文字资料进行Self-supervised learing 自监督式学习。
那么需要多少个文字资料才能够让机器学习到足够的知识呢?对于语言知识,大概1亿个资料就足够,但是对于世界知识,1亿个资料是远远不够的,因为世界知识过于庞杂,层次过多,即使到30亿的训练资料也不够学习。(如下图所示)
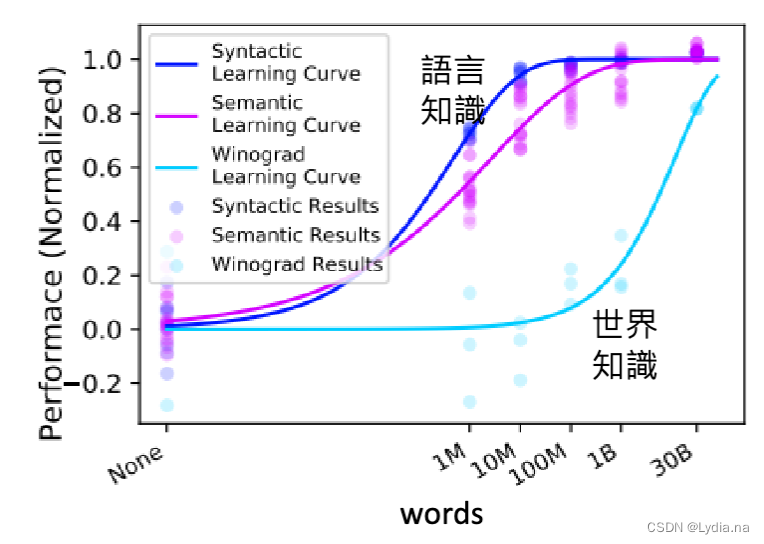
在网络上搜寻资料时也不是随便搜寻,也是要进行资料清理的:(以GPT-3/The Pile/PaLM使用的资料品质分类器所示)




![mysql 8 [HY000][1114] The table ‘/tmp/#sql4c3_3e5a0_2‘ is full](https://img-blog.csdnimg.cn/direct/70ff6e8339ba425192fe99e894f3d46e.png)