早期CPU访问内存结构
UMA1(Uniform Memory Access, 一致性内存访问 )
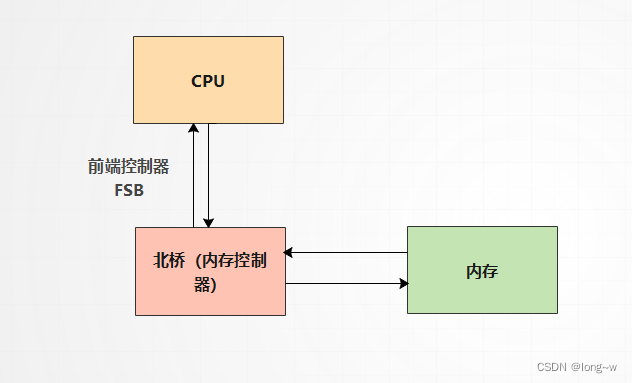
早期的计算机,内存控制器还没有整合进 CPU,所有的内存访问都需要经过北桥芯片来完成。
在 UMA 架构下,CPU 和内存之间的通信全部都要通过前端总线。而提高性能的方式,就是不断地提高 CPU、前端总线和内存的工作频率。
总线模型保证了 CPU 的所有内存访问都是一致的,不必考虑不同内存地址之间的差异。
而随着计算机的发展,CPU 性能的提升开始从提高主频转向增加 CPU 数量(多核、多 CPU)。
但是由于CPU核数过多,而每核访问内存时都要通过前端总线,而前端总线只有一个,造成的问题是,很多CPU同时竞争总线,这样的话,前端总线就成为了性能屏障。
NUMA2(Non-Uniform Memory Access, 非一致性内存访问)
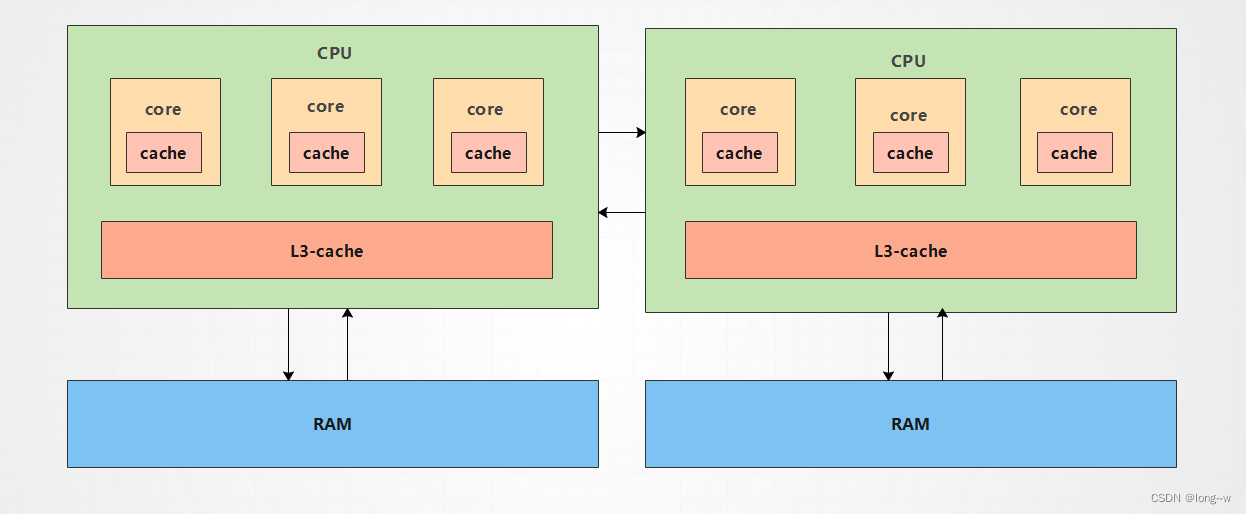
上图就是两个NUMA节点(Node),每个节点直接连接一部分内存,两个节点之间有专门的的inter-connect通道。各节点直接访问自己管理的内存叫本地内存(Local Access),通过inter-connect通道访问其他分厂管理的内存叫做**远程内存(**Remote Access)。很显然,前者的访问速度要比后者快得多,所以这也是这项技术名字的由来:非一致性内存访问。
在有了NUMA技术后,因为每个线程对应CPU中的一个core,所以操作系统的线程调度管理部门调度线程时尽量一直在一个NUMA节点,要不然的话建立的缓存就很容易失效。
而为了能得到更快的内存访问速度,操作系统的内存管理部门制定了一个内存分配策略,线程在哪个NUMA节点内执行,那就把内存分配到那个节点直接连接的内存中,避免跨节点的内存访问(访问远程内存比较慢)。







![[从零开始]用python制作识图翻译器·三](https://img-blog.csdnimg.cn/cc58a5ff935c41a6b615e1552c3d888a.png)