面经记录【面试准备】
- 前言
- 版权
- 面经
- 【Java每日一题】Http协议和RPC协议有什么区别?
- 【Java每日一题】什么是微服务,说一下你对微服务的理解
- Java面试题:应用的线程数应该设置成多少
- 【Java面试】说一下HashMap的put方法
- 字节二面:MySQL中1000万条数据你是怎么查询的?查询非常慢如何优化 ?
- 京东二面:SpringBoot可以同时处理多少请求?直接就愣住了。。
- 自从掌握了这10个Lambda表达式,Java开发效率直线飙升!
- 腾讯二面:MySQL加索引的时候到底会不会锁表?傻傻分不清。。
- 12张表244个字段还要聚合你让我优化?
- 【Java面试】说说进程间的通信
- 【Java每日一题】说说你对Spring MVC的理解?
- 【Java每日一题】Kafka如何保证消息不丢失的?
- java面试题:什么是TCP的粘包拆包,如何解决
- 【Java面试】说说一条更新语句的执行过程
- 【Java面试】Spring如何解决循环依赖问题的?
- 最后
前言
2023-9-13 16:27:52
公开发布于
2024-5-21 13:18:55
以下内容源自《【面试准备】》
仅供学习交流使用
版权
禁止其他平台发布时删除以下此话
本文首次发布于CSDN平台
作者是CSDN@日星月云
博客主页是https://blog.csdn.net/qq_51625007
禁止其他平台发布时删除以上此话
面经
【Java每日一题】Http协议和RPC协议有什么区别?
【Java每日一题】Http协议和RPC协议有什么区别?
【Java每日一题】什么是微服务,说一下你对微服务的理解
【Java每日一题】什么是微服务,说一下你对微服务的理解
Java面试题:应用的线程数应该设置成多少
Java面试题:应用的线程数应该设置成多少
【Java面试】说一下HashMap的put方法
【Java面试】说一下HashMap的put方法
字节二面:MySQL中1000万条数据你是怎么查询的?查询非常慢如何优化 ?
字节二面:MySQL中1000万条数据你是怎么查询的?查询非常慢如何优化 ?
京东二面:SpringBoot可以同时处理多少请求?直接就愣住了。。
京东二面:SpringBoot可以同时处理多少请求?直接就愣住了。。
自从掌握了这10个Lambda表达式,Java开发效率直线飙升!
自从掌握了这10个Lambda表达式,Java开发效率直线飙升!
腾讯二面:MySQL加索引的时候到底会不会锁表?傻傻分不清。。
腾讯二面:MySQL加索引的时候到底会不会锁表?傻傻分不清。。
12张表244个字段还要聚合你让我优化?
12张表244个字段还要聚合你让我优化?
【Java面试】说说进程间的通信
【Java面试】说说进程间的通信
【Java每日一题】说说你对Spring MVC的理解?
【Java每日一题】说说你对Spring MVC的理解?
【Java每日一题】Kafka如何保证消息不丢失的?
【Java每日一题】Kafka如何保证消息不丢失的?
Kafka是一个用来实现异步消息通讯的一个中间件
它的整个架构是由Producer、Consumer和Broker组成
所以对于Kafka如何保证消息不丢失的这个问题,可以从三个方面考虑和实现
首先是Producer端,确保消息能够到达Broker端,并且实现消息的存储
在这个层面上有可能会出现网络问题,导致消息发送失败,
所以能针对Producer端可以通过两种方法来避免消息的丢失
第一个,Producer默认是异步发送消息的,那么这种情况下要确保消息是发送成功的
那么这里面有两个方法
1把异步发送改成同步发送,这样producer就能实时知道消息发送的结果
2添加异步回调函数来监听消息发送的结果。如果发送失败。可以在回调中重试
第二个,Producer本事提供一个重试参数,叫retries,
如果因为网络问题或者Broker端故障导致发送失败,那么Producer会自动重试
然后是Broker端,Broker端需要确保Producer发送过来消息是不会丢失的,也就是说只要去把这个消息持久化到磁盘就可以了
但是Kafka为了提升性能采用了异步批量刷盘的实现机制,也就是说,按照一定的消息量和时间间隔去刷盘
而最终刷新到磁盘这个动作,是由操作系统来调度的,所以如果在刷盘之前系统崩溃了,就会导致数据的丢失
Kafka并没有提供同步刷盘的一个实现机制,所以针对这个问题
需要通过Partition的副本机制和acks机制来解决
我简单说一下Partition副本机制,它是针对每个数据分区的高可用策略
每个Partition副本集,会包含唯一的一个Leader和多个Follower
Leader专门处理事务类型的请求,而Follower负责同步Leader的数据
那么在这样一个机制的基础上呢,Kafka提供了一个acks的参数,
Producer可以去设置acks参数,去结合Broker的副本机制来共同保证数据的可靠性
acks这个参数的值呢有几个选择
第一个是acks=0,表示Producer不需要等待Broker的响应,就认为消息就发送成功了,那么这种情况下会存在消息丢失
第二个是acks=1,表示Broker中的Leader Partition,受到消息之后,不等待其他的Follower Partition的同步,就给Producer返回了一个确认。这种情况下,假设Leader Partition挂了,就会存在数据丢失,
第二个是acks=-1,表示Broker中的Leader Partition,受到消息之后,并且等待ISR列表中的所有Follower同步完成,在去给Producer返回了一个确认。这样的一个配置是可以保证数据的一个可靠性的。
最后,就是Consumer端,必须要能够消费的这个消息,
实际上我认为,只要Producer和Broker端的消息可靠性得到保障,那么消费端是不太可能出现消息无法消费的问题的。除非是Consumer没有消费完这个消息,就已经提交了这样offset。但是即便是出现这样一个情况,我们也可以通过重新调整offset的值,来实现重新消费
以上就是我对于这个问题的理解。
java面试题:什么是TCP的粘包拆包,如何解决
java面试题:什么是TCP的粘包拆包,如何解决
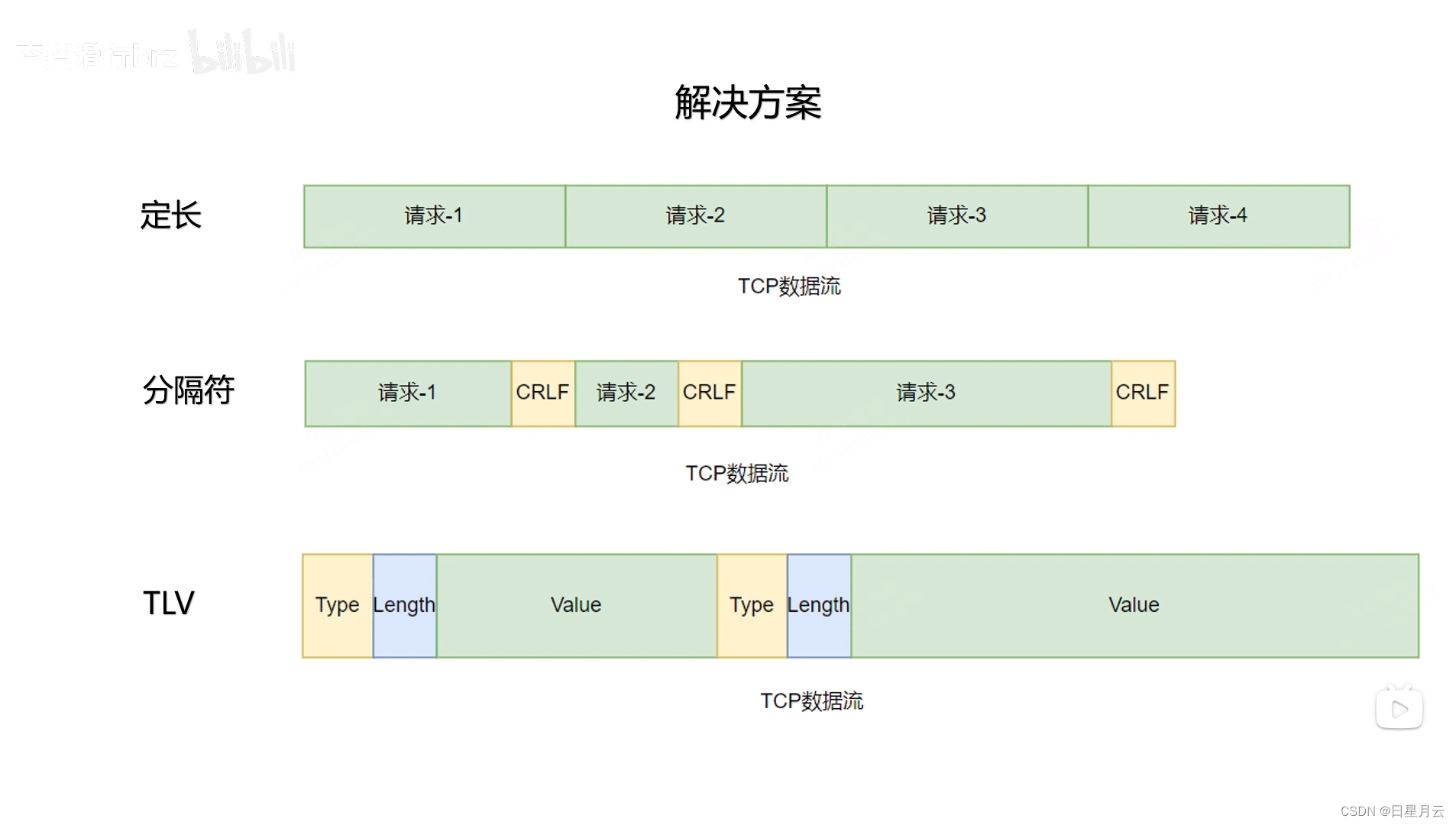
三种方法
定长 :FTP
分割符:SMTP
两个连续的换行+回车
长度头部:
HTTP1.1的Content-Length
WebSocket

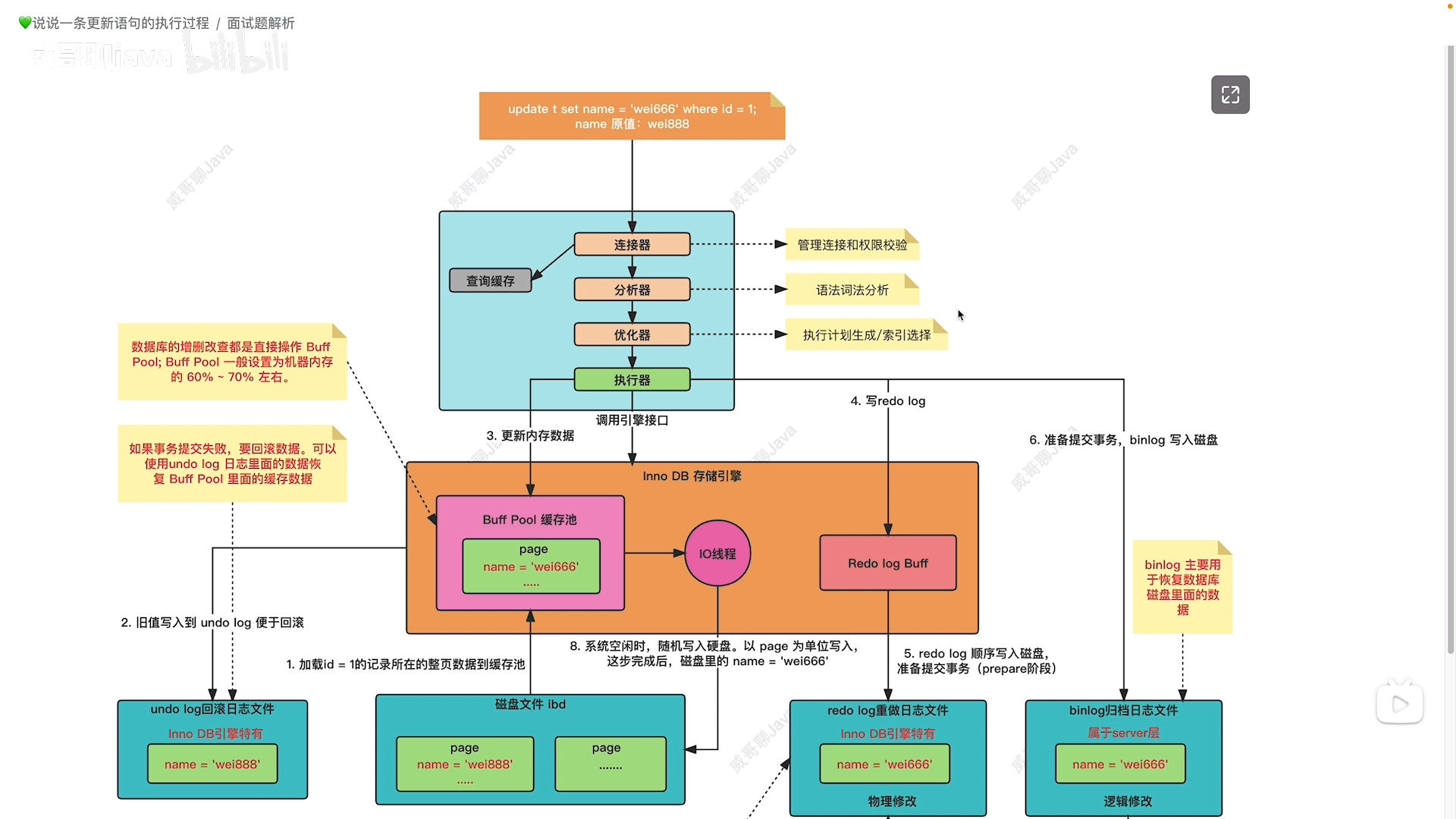
【Java面试】说说一条更新语句的执行过程
【Java面试】说说一条更新语句的执行过程
【Java面试】Spring如何解决循环依赖问题的?
【Java面试】Spring如何解决循环依赖问题的?
最后
我们都有光明的未来
祝大家考研上岸
祝大家工作顺利
祝大家得偿所愿
祝大家如愿以偿
点赞收藏关注哦