为什么使用embedding
计算机只能处理数字,但我们希望它能够理解文字、图片或其他形式的数据。这就是embedding的作用。它将这些复杂的数据转换成数字表示,就像给它们贴上了标签一样。这些数字表示不仅保留了原始数据的重要信息,还能在计算机世界中更容易被处理和比较。
嵌入有点像字典,可以把不同的词、图片或对象转换成独特的数字编码。这样,我们就能用这些数字来进行计算、分类或做出预测。通过embedding,计算机可以变得更智能,因为它学会了如何用数字来理解和处理各种各样的数据。
例如,我们可以用一个三百维的数字向量(x1,x2,x3…x300)来表示一个词,这里每一个数字就是这个词在一个意义上的坐标。
举例来说,我们表述“猫”这个词,可以是(1,0.8,-2,0,1.5…),“狗”可以表示为(0.5,1.1,-1.8,0.4,2.2…)。
然后,我们可以通过这些数字的距离计算“猫”和“狗”的语义关系有多近。因为它们在某些数字上会更接近。而与“桌子”的向量距离就会更远一些。通过这种方法,embedding让词汇有了数学上的表示,计算机可以分析词汇间的关系了。
MTEB榜单
判断哪些文本嵌入模型效果较好,通常需要一个评估指标来进行比较,MTEB就是一个海量文本嵌入模型的评估基准。
MTEB: Massive Text Embedding Benchmark(海量文本嵌入基准)
论文地址:https://arxiv.org/abs/2210.07316
github地址:https://github.com/embeddings-benchmark/mteb#leaderboard
论文摘要如下
文本嵌入通常在单个任务的一小部分数据集上进行评估,而不包括它们在其他任务中的可能应用。目前尚不清楚最新的语义文本相似性嵌入(STS)是否可以同样很好地应用于其他任务,如聚类或重新排序。这使得该领域的进展难以跟踪,因为各种模型不断被提出而没有得到适当的评估。为了解决这个问题,我们引入了海量文本语义向量基准测试(MTEB)。MTEB包含8个语义向量任务,涵盖58个数据集和112种语言。通过在MTEB上对33个模型进行基准测试,我们建立了迄今为止最全面的文本嵌入基准。我们发现没有特定的文本嵌入方法在所有任务中都占主导地位。这表明该领域尚未集中在一个通用的文本嵌入方法上,并将其扩展到足以在所有嵌入任务上提供最先进的结果。
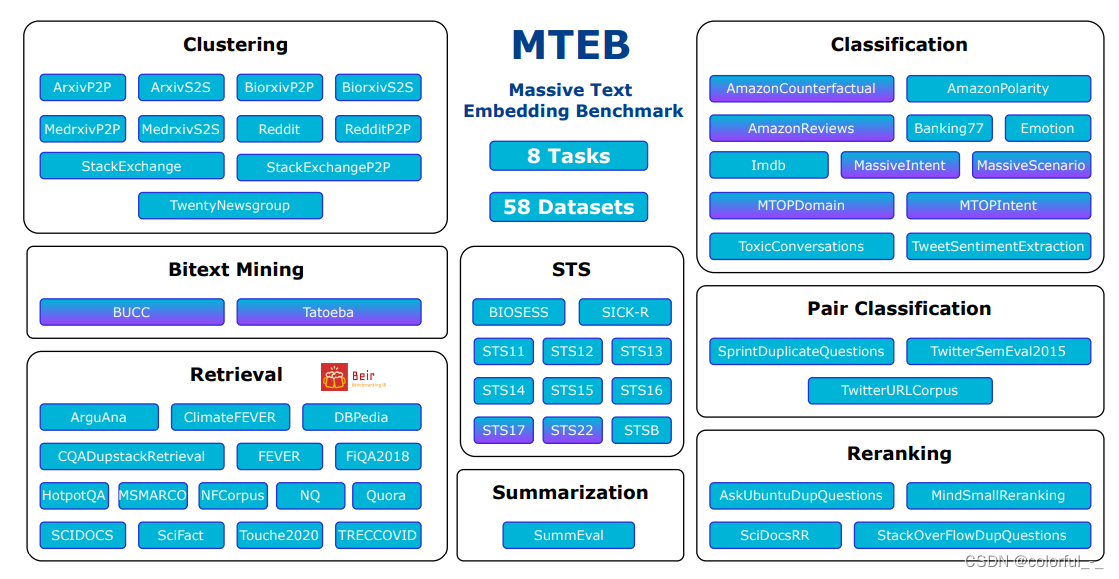
榜单地址:https://huggingface.co/spaces/mteb/leaderboard

8个嵌入任务
- Bitext Mining(双语文本挖掘):输入是来自两种不同语言的两组句子。对于第一组中的每个句子,需要在第二组中找到最佳匹配。匹配通常是翻译。所提供的模型用于嵌入每个句子,并通过余弦相似度找到最接近的对。
- Classification(分类):训练和测试集均使用所提供的模型进行文本嵌入表示。训练集用于训练逻辑回归分类器(如最大迭代100次),在测试集中进行评分。
- Clustering(聚类):给定一组句子或段落,目标是将它们分组成有意义的类。
- Pair Classification(句子对分类):提供一对文本输入,并需要分配一个标签。标签通常是表示重复或释义对的二进制变量。两个文本通过模型嵌入,它们的距离用各种度量来计算(余弦相似度,点积,欧氏距离,曼哈顿距离)。
- Reranking(重新排序):输入是一个查询query和文本的列表(列表中是与query相关或不相关的文本)。其目的是根据与查询的相关性对结果进行排序。文本和query通过模型进行嵌入,然后使用余弦相似度将其与查询进行比较。对每个查询进行评分,并在所有查询中取平均值。指标是平均MRR@k和MAP,后者是主要指标。
- Retrieval (检索):每个数据集由语料库、查询query和每个查询到语料库中相关文档的映射组成。目的是找到这些相关文件。所提供的模型用于嵌入所有查询和所有语料库文档,并使用余弦相似度计算相似度分数。根据分数对每个查询的语料库文档进行排序后,分别计算nDCG@k, MRR@k,MAP@k、precision@k和recall@k。nDCG@10作为主要度量。
- Semantic Textual Similarity(STS)(语义文本相似度):给定一对句子,目的是确定它们的相似度。标签是连续得分,数字越高表示句子越相似。所提供的模型用于嵌入句子,并使用各种距离度量来计算句子的相似度。距离的基准是使用Pearson和Spearman相关性的真实相似度。基于余弦相似度的Spearman相关作为主要度量。
- Summarization(摘要):提供了一组人工编写和机器生成的摘要。目的是给机器生成的摘要进行打分。所提供的模型首先用于嵌入所有摘要。
对每个机器生成的摘要嵌入,计算与所有人类摘要嵌入的距离。
最接近的分数(例如,最高余弦相似度)被保留并用作单个机器生成摘要的模型分数。
三种数据集类别
为了进一步提高MTEB的多样性,还包括了不同文本长度的数据集。所有数据集分为三类:
- 句子对句子(S2S):一个句子与另一个句子比较。S2S的一个例子是MTEB中所有当前的STS任务,其中评估两个句子之间的相似性。适用任务:文本相似度匹配,重复问题检测,文本分类等;
- 段落到段落(P2P):将一个段落与另一个段落进行比较。MTEB对输入长度没有限制,在必要时由模型截断。一些聚类任务为S2S和P2P任务。前者只比较标题,后者包括标题和内容。例如,对于ArxivClustering,在P2P设置下,摘要被连接到标题。适用任务:聚类。
- 句子到段落(S2P):在S2P设置中混合了几个检索数据集。这里的查询是一个句子,而文档是由多个句子组成的长段落。适用任务:文本检索。
OpenAI的text-embedding模型
text-embedding-ada-002
模型简介
text-embedding-ada-002是OpenAI于2022年12月提供的一个embedding模型,但需要调用接口付费使用。其具有如下特点:
- 统一能力:OpenAI通过将五个独立的模型(文本相似性、文本搜索-查询、文本搜索-文档、代码搜索-文本和代码搜索-代码)合并为一个新的模型
在一系列不同的文本搜索、句子相似性和代码搜索基准中,这个单一的表述比以前的嵌入模型表现得更好 - 上下文:上下文长度为8192,使得它在处理长文档时更加方便
- 嵌入尺寸:只有1536个维度,是davinci-001嵌入尺寸的八分之一,使新的嵌入在处理矢量数据库时更具成本效益
模型使用
以下是OpenAI官方文档中给出的用于文本搜索的代码实例
from openai.embeddings_utils import get_embedding, cosine_similarity
def search_reviews(df, product_description, n=3, pprint=True):
embedding = get_embedding(product_description, model='text-embedding-ada-002')
df['similarities'] = df.ada_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
return res
res = search_reviews(df, 'delicious beans', n=3)
M3E模型
M3E是Moka Massive Mixed Embedding的简称,解释一下
- Moka,表示模型由MokaAI训练,开源和评测,训练脚本使用uniem ,评测BenchMark使用 MTEB-zh
- Massive,表示此模型通过千万级(2200w+)的中文句对数据集进行训练
- Mixed,表示此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
其有多个版本,分为m3e-small、m3e-base、m3e-large,m3e
GitHub地址:https://github.com/wangyingdong/m3e-base,其
- 使用in-batch负采样的对比学习的方式在句对数据集进行训练,为了保证in-batch负采样的效果,使用A100来最大化batch-size,并在共计2200W+的句对数据集(包含中文百科,金融,医疗,法律,新闻,学术等多个领域)训练;
- 使用了指令数据集,M3E 使用了300W+的指令微调数据集,这使得 M3E 对文本编码的时候可以遵从指令,这部分的工作主要被启发于 instructor-embedding;
- 基础模型,M3E 使用 Roberta 系列模型进行训练,目前提供 small 和 base 两个版本。
M3E模型与OpenAI向量模型对比
M3E Models 是使用千万级 (2200w+) 的中文句对数据集进行训练的 Embedding 模型,在文本分类和文本检索的任务上都超越了 openai-ada-002 模型(ChatGPT 官方的模型)。
| 模型 | 参数数量 | 维度 | 中文 | 英文 | s2s | s2p | s2c | 开源 | 兼容性 | s2s Acc | s2p ndcg@10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| m3e-small | 24M | 512 | 是 | 否 | 是 | 否 | 否 | 是 | 优 | 0.5834 | 0.7262 |
| m3e-base | 110M | 768 | 是 | 是 | 是 | 是 | 否 | 是 | 优 | 0.6157 | 0.8004 |
| text2vec | 110M | 768 | 是 | 否 | 是 | 否 | 否 | 是 | 优 | 0.5755 | 0.6346 |
| openai-ada-002 | 未知 | 1536 | 是 | 是 | 是 | 是 | 是 | 否 | 优 | 0.5956 | 0.7786 |
说明:
- s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
- s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
- s2c, 即sentence to code ,代表了自然语言和程序语言之间的嵌入能力,适用任务:代码检索
- 兼容性,代表了模型在开源社区中各种项目被支持的程度,由于 m3e 和 text2vec 都可以直接通过
- sentence-transformers 直接使用,所以和 openai 在社区的支持度上相当
Tips:
- 使用场景主要是中文,少量英文的情况,建议使用 m3e 系列的模型
- 多语言使用场景,并且不介意数据隐私的话,建议使用 openai text-embedding-ada-002
- 代码检索场景,推荐使用 openai text-embedding-ada-002
- 文本检索场景,请使用具备文本检索能力的模型,只在 S2S 上训练的文本嵌入模型,没有办法完成文本检索任务。
bge模型
项目地址:https://github.com/FlagOpen/FlagEmbedding
博客链接:https://zhuanlan.zhihu.com/p/648448793
BGE 模型链接:https://huggingface.co/BAAI/
BGE是北京智源人工智能研究院发布的中英文语义向量模型。在中英文语义检索精度与整体语义表征能力均超越了社区所有同类模型(后来又被其他模型超越),如OpenAI 的text embedding 002等。此外,BGE 保持了同等参数量级模型中的最小向量维度,使用成本更低。
BGE的技术亮点:
- 高效预训练和大规模文本微调;
- 在两个大规模语料集上采用了RetroMAE预训练算法,进一步增强了模型的语义表征能力;
- 通过负采样和难负样例挖掘,增强了语义向量的判别力;
- 借鉴Instruction Tuning的策略,增强了在多任务场景下的通用能力。











![[leetcode hot 150]第五十六题,合并区间](https://img-blog.csdnimg.cn/direct/a0b5bbedfefc4f6abd29eb76d6c55f24.png)