欢迎访问
什么是索引?
提高查询效率的一种数据结构,索引是数据的目录
索引的分类
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引、二级索引。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引(复合索引)。
按数据结构分类
为什么 MySQL InnoDB 选择 B+tree 作为索引的数据结构?
1、B+Tree vs B Tree
-
B+Tree 只在叶子节点存储数据,而 B 树 的非叶子节点也要存储数据,所以 B+Tree 的单个节点的数据量更小,在相同的磁盘 I/O 次数下,就能查询更多的节点。
-
B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;
-
另外,B+Tree 叶子节点采用的是双链表连接,适合 MySQL 中常见的基于范围的顺序查找,而 B 树无法做到这一点。
2、B+Tree vs 二叉树
- B+树的节点相对较大,能够存储更多的索引项,从而减少了树的高度,降低了访问磁盘的次数(矮胖)
- B+树的节点相对较大,一个节点可以存储多个关键字,这意味着在进行磁盘IO时,可以一次性读取更多的索引项到内存中,利用了局部性原理,减少了IO的开销(局部性)
- B+树的节点相对较大,树的高度低,节点分裂和合并等平衡操作相对较少,在插入和删除操作时,B+树通常能够更加高效地维持树的平衡性,而不需要频繁地进行平衡调整操作
- B+树的叶子节点形成了一个有序链表,便于范围查询
3、B+Tree vs Hash
Hash 在做等值查询的时候效率贼快,搜索复杂度为 O(1)。
但是 Hash 表不适合做范围查询,它更适合做等值的查询,这也是 B+Tree 索引要比 Hash 表索引有着更广泛的适用场景的原因。
按物理存储分类
分为聚簇索引和二级索引
在查询时使用了二级索引,如果查询的数据能在二级索引里查询的到,那么就不需要回表,这个过程就是覆盖索引。如果查询的数据不在二级索引里,就会先检索二级索引,找到对应的叶子节点,获取到主键值后,然后再检索主键索引,就能查询到数据了,这个过程就是回表
按字段特性分类
分为主键索引、唯一索引、普通索引、前缀索引
主键索引
通常在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值
唯一索引
一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值
普通索引
既不要求字段为主键,也不要求字段为 UNIQUE
前缀索引
前缀索引是指对字符类型字段的前几个字符建立的索引,使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率
普通索引和唯一索引,应该怎么选择?
查询过程:
- 对于普通索引来说,查找到满足条件的第一个记录 (5,500) 后,需要查找下一个记录,直到碰到第一个不满足 k=5 条件的记录。
- 对于唯一索引来说,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索。
更新过程:
第一种情况是,这个记录要更新的目标页在内存中。这时,InnoDB 的处理流程如下:
- 对于唯一索引来说,找到 3 和 5 之间的位置,判断到没有冲突,插入这个值,语句执行结束;
- 对于普通索引来说,找到 3 和 5 之间的位置,插入这个值,语句执行结束。
这样看来,普通索引和唯一索引对更新语句性能影响的差别,只是一个判断,只会耗费微小的 CPU 时间。
但,这不是我们关注的重点。
第二种情况是,这个记录要更新的目标页不在内存中。这时,InnoDB 的处理流程如下:
- 对于唯一索引来说,需要将数据页读入内存,判断到没有冲突,插入这个值,语句执行结束;
- 对于普通索引来说,则是将更新记录在 change buffer,语句执行就结束了。
将数据从磁盘读入内存涉及随机 IO 的访问,是数据库里面成本最高的操作之一。change buffer 因为减少了随机磁盘访问,所以对更新性能的提升是会很明显的。(因此,对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时 change buffer 的使用效果最好)
按字段个数分类
分为单列索引、联合索引(复合索引)
使用联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效
联合索引范围查询
联合索引的最左匹配原则,在遇到范围查询(如 >、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。注意,对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配,因为等于的时候可以用到索引
select * from t_table where a >= 1 and b = 2 //a=1等于时,b有序
索引下推
对于联合索引(a, b),在执行 select * from table where a > 1 and b = 2 语句的时候,只有 a 字段能用到索引
对于b=2的判断:
- 在 MySQL 5.6 之前,回表之后判断
- 而 MySQL 5.6 引入的索引下推优化(index condition pushdown),在搜索引擎判断,符合再回表
索引区分度
建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。
区分度=不同的列/总列数
性别的区分度就很小,不适合建立索引或不适合排在联合索引列的靠前的位置,而 UUID 这类字段就比较适合做索引或排在联合索引列的靠前的位置
联合索引进行排序
这里出一个题目,针对针对下面这条 SQL,你怎么通过索引来提高查询效率呢?
select * from order where status = 1 order by create_time asc
给 status 和 create_time 列建立一个联合索引
什么时候需要 / 不需要创建索引?
索引最大的好处是提高查询速度,但是索引也是有缺点**(空间、维护)**的,比如:
- 需要占用物理空间,数量越大,占用空间越大;
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增大;
- 会降低表的增删改的效率,因为每次增删改索引,B+ 树为了维护索引有序性,都需要进行动态维护。
什么时候适用索引?
唯一、常查、排序
- 字段有唯一性限制的,比如商品编码;
- 经常用于
WHERE查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。 - 经常用于
GROUP BY和ORDER BY的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的
什么时候不需要创建索引?
不查不排、重复数据、数据量小、常更新
WHERE条件,GROUP BY,ORDER BY里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。- 字段中存在大量重复数据;
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,比如不要对电商项目的用户余额建立索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么就需要频繁的重建索引,这个过程是会影响数据库性能的。
索引选择
首先,看MySQL 执行过程:
MySQL 数据库由 Server 层和 Engine 层组成:
- Server 层有 SQL 分析器、SQL优化器、SQL 执行器,用于负责 SQL 语句的具体执行过程;
- Engine 层负责存储具体的数据,如最常使用的 InnoDB 存储引擎,还有用于在内存中存储临时结果集的 TempTable 引擎。
SQL 优化器会分析所有可能的执行计划,选择成本最低的执行,这种优化器称之为:CBO(Cost-based Optimizer,基于成本的优化器)。
而在 MySQL中,一条 SQL 的计算成本计算如下所示:
Cost = Server Cost + Engine Cost
= CPU Cost + IO Cost
其中,CPU Cost 表示计算的开销,比如索引键值的比较、记录值的比较、结果集的排序……这些操作都在 Server 层完成;
IO Cost 表示引擎层 IO 的开销,MySQL 8.0 可以通过区分一张表的数据是否在内存中,分别计算读取内存 IO 开销以及读取磁盘 IO 的开销。
总结来说:
- MySQL 优化器是 CBO 的,MySQL 会选择成本最低的执行计划,你可以通过 EXPLAIN 命令查看每个 SQL 的成本;
- 一般只对高选择度的字段和字段组合创建索引,低选择度的字段如性别,不创建索引;
- 低选择性,但是数据存在倾斜,通过索引找出少部分数据,可以考虑创建索引。若数据存在倾斜,可以创建直方图,让优化器知道索引中数据的分布,进一步校准执行计划。
有什么优化索引的方法?
几种常见优化索引的方法:
- 前缀索引优化;
- 覆盖索引优化;
- 主键索引最好是自增的;
- 防止索引失效;
前缀索引优化
使用某个字段中字符串的前几个字符建立索引,减小索引字段大小,可以增加一个索引页中存储的索引值,有效提高索引的查询速度。
不过,前缀索引有一定的局限性,例如:
- order by 就无法使用前缀索引;
- 无法把前缀索引用作覆盖索引;
覆盖索引优化
查询的数据能在二级索引里查询的到,不需要通过主键索引查询获得,可以避免回表的操作
假设我们只需要查询商品的名称、价格,有什么方式可以避免回表呢?
我们可以建立一个联合索引,即「商品ID、名称、价格」作为一个联合索引。如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。
所以,使用覆盖索引的好处就是,不需要查询出包含整行记录的所有信息,也就减少了大量的 I/O 操作。
主键索引最好是自增的
我们在建表的时候,都会默认将主键索引设置为自增的,具体为什么要这样做呢?又什么好处?
InnoDB 创建主键索引默认为聚簇索引,数据被存放在了 B+Tree 的叶子节点上。也就是说,同一个叶子节点内的各个数据是按主键顺序存放的,因此,每当有一条新的数据插入时,数据库会根据主键将其插入到对应的叶子节点中。
如果我们使用自增主键,那么每次插入的新数据就会按顺序添加到当前索引节点的位置,不需要移动已有的数据,当页面写满,就会自动开辟一个新页面。因为每次插入一条新记录,都是追加操作,不需要重新移动数据,因此这种插入数据的方法效率非常高。
如果我们使用非自增主键,由于每次插入主键的索引值都是随机的,因此每次插入新的数据时,就可能会插入到现有数据页中间的某个位置,这将不得不移动其它数据来满足新数据的插入,甚至需要从一个页面复制数据到另外一个页面,我们通常将这种情况称为页分裂。页分裂还有可能会造成大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。
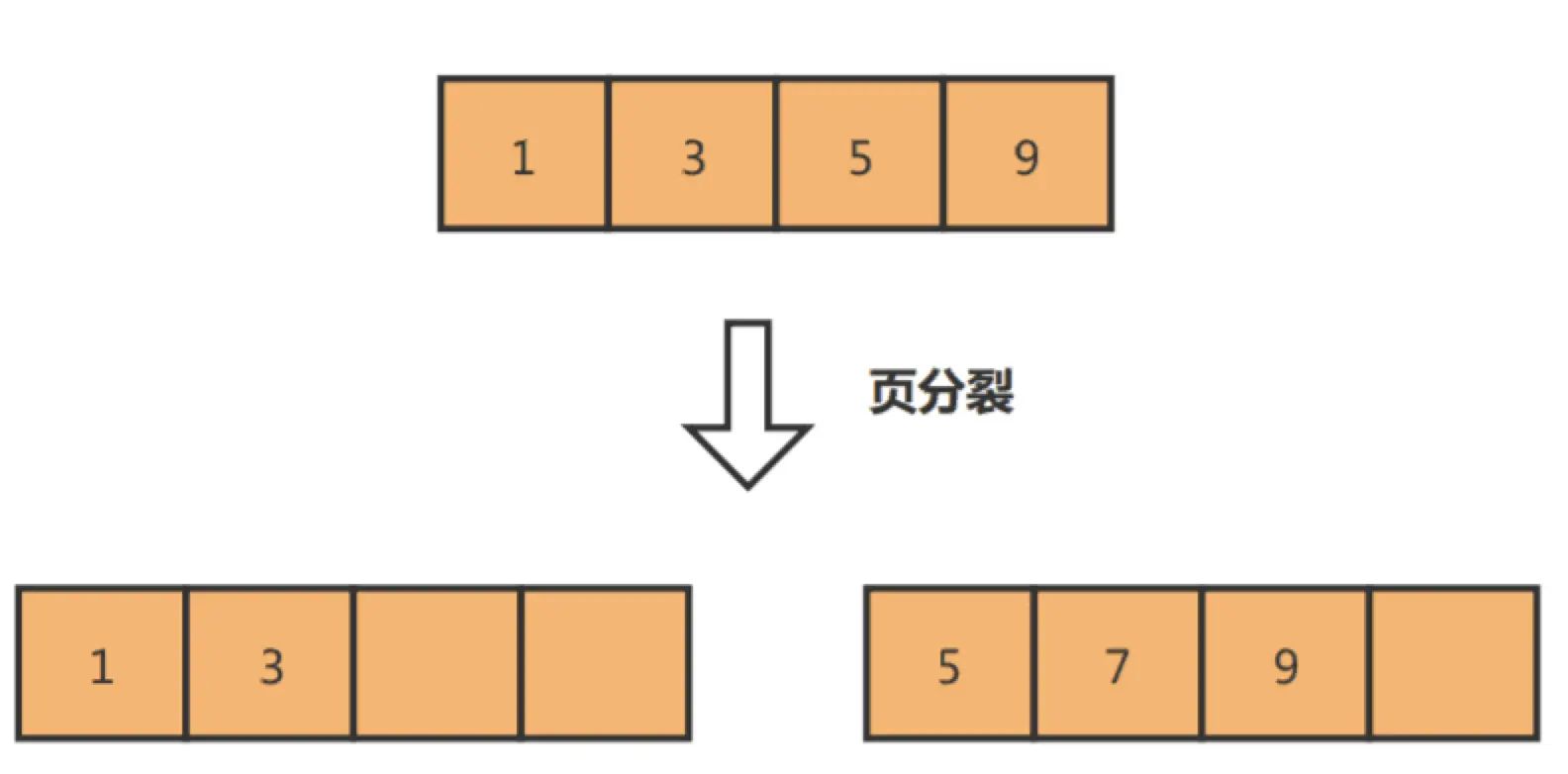
而如果记录是顺序插入的,例如插入数据11,则只需开辟新的数据页,也就不会发生页分裂:

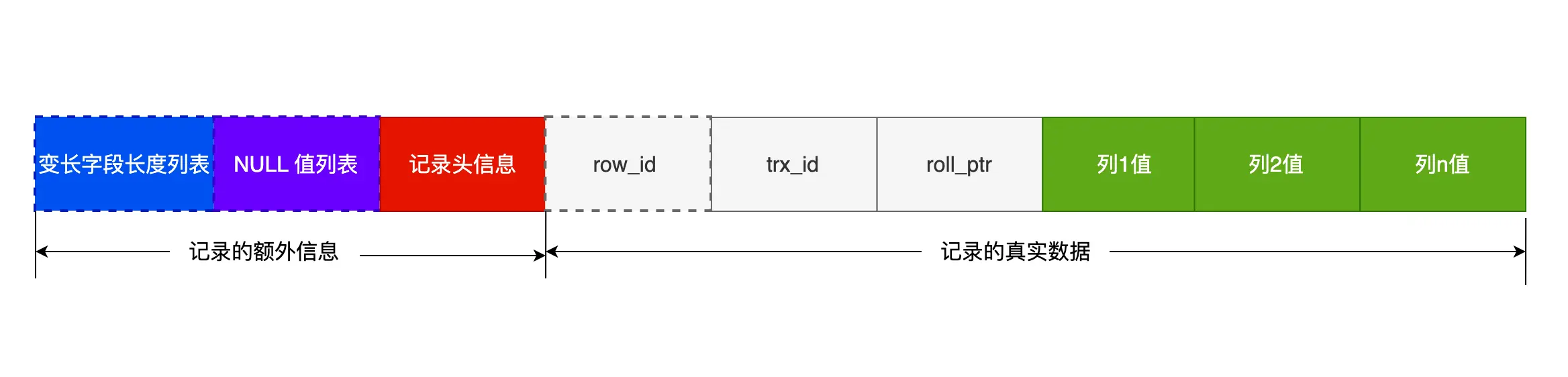
索引最好设置为 NOT NULL
为了更好的利用索引,索引列要设置为 NOT NULL 约束。有两个原因:(优化器选择复杂,NULL有NULL值表占用空间)
- 第一原因:索引列存在 NULL 就会导致优化器在做索引选择的时候更加复杂,更加难以优化,因为可为 NULL 的列会使索引、索引统计和值比较都更复杂,比如进行索引统计时,count 会省略值为NULL 的行。
- 第二个原因:NULL 值是一个没意义的值,但是它会占用物理空间,所以会带来的存储空间的问题,因为 InnoDB 存储记录的时候,如果表中存在允许为 NULL 的字段,那么行格式中至少会用 1 字节空间存储 NULL 值列表,如下图的紫色部分
防止索引失效
发生索引失效的情况:
like和联合没有左匹配,函数,or
- 当我们使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效; - 当我们在查询条件中对索引列做了计算、函数、类型转换操作,这些情况下都会造成索引失效;
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。

问题自测
1.为什么索引能提⾼查询速度?
索引是提高查询效率的一种数据结构,索引是数据的目录,索引的底层为B+树实现,B+Tree 只在叶子节点存储数据,单个节点的数据量小,且B+树矮胖,磁盘IO少
通过使用索引,数据库系统可以直接跳到存储数据的位置,而不必逐行查找
2.聚集索引和⾮聚集索引的区别?⾮聚集索引⼀定回表查询吗?
- 聚集索引(Clustered Index):
- 聚集索引中,表的行数据按照索引的顺序进行存储,而且每张表只能有一个聚集索引
- 因为数据行按照索引的顺序存储,所以聚集索引可以加速范围查询和排序操作,但是插入和更新操作可能会导致数据的重新排序,因此对于频繁进行这些操作的表来说,可能会影响性能。
- 非聚集索引(Non-Clustered Index):
- 非聚集索引中,索引的叶子节点并不包含实际的数据行,而是包含指向数据行的指针(或者称为引用)。
- 表可以有多个非聚集索引,这些索引可以加速检索
在查询时使用了二级索引,如果查询的数据能在二级索引里查询的到,那么就不需要回表,这个过程就是覆盖索引。如果查询的数据不在二级索引里,就会先检索二级索引,找到对应的叶子节点,获取到主键值后,然后再检索主键索引,就能查询到数据了,这个过程就是回表
3.索引这么多优点,为什么不对表中的每⼀个列创建⼀个索引呢?(使⽤索引⼀定能提⾼查 询性能吗?)
索引最大的好处是提高查询速度,但是索引也是有缺点**(空间、维护)**的,比如:
- 需要占用物理空间,数量越大,占用空间越大;
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增大;
- 会降低表的增删改的效率,因为每次增删改索引,B+ 树为了维护索引有序性,都需要进行动态维护。
什么时候适用索引?
唯一、常查、排序
- 字段有唯一性限制的,比如商品编码;
- 经常用于
WHERE查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。 - 经常用于
GROUP BY和ORDER BY的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的
什么时候不需要创建索引?
不查不排、重复数据、数据量小、常更新
WHERE条件,GROUP BY,ORDER BY里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。- 字段中存在大量重复数据;
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,比如不要对电商项目的用户余额建立索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么就需要频繁的重建索引,这个过程是会影响数据库性能的。
4.索引底层的数据结构了解么?Hash 索引和 B+树索引优劣分析
Hash 在做等值查询的时候效率贼快,搜索复杂度为 O(1)。
但是 Hash 表不适合做范围查询,它更适合做等值的查询,这也是 B+Tree 索引要比 Hash 表索引有着更广泛的适用场景的原因。
5.B+树做索引⽐红⿊树好在哪⾥?
红黑树通常用于实现内存中的数据结构,例如C++的STL中的map和set。它是一种高度平衡的二叉搜索树,对于内存中的数据结构来说,维护起来比较简单。
B+树则更适合用于实现磁盘存储上的索引结构:
- 2、B+Tree vs 二叉树
- B+树的节点相对较大,能够存储更多的索引项,从而减少了树的高度,降低了访问磁盘的次数(矮胖)
- B+树的节点相对较大,一个节点可以存储多个关键字,这意味着在进行磁盘IO时,可以一次性读取更多的索引项到内存中,利用了局部性原理,减少了IO的开销(局部性)
- B+树的节点相对较大,树的高度低,节点分裂和合并等平衡操作相对较少,在插入和删除操作时,B+树通常能够更加高效地维持树的平衡性,而不需要频繁地进行平衡调整操作
- B+树的叶子节点形成了一个有序链表,便于范围查询
6.最左前缀匹配原则了解么?
联合索引要按照最左优先的方式进行索引的匹配
比如,如果创建了一个 (a, b, c) 联合索引,如果查询条件是以下这几种,就可以匹配上联合索引:
- where a=1;
- where a=1 and b=2 and c=3;
- where a=1 and b=2;
需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。
但是,如果查询条件是以下这几种,因为不符合最左匹配原则,所以就无法匹配上联合索引,联合索引就会失效:
- where b=2;
- where c=3;
- where b=2 and c=3;
为什么联合索引不遵循最左匹配原则就会失效?
原因是,在联合索引的情况下,数据是按照索引第一列排序,第一列数据相同时才会按照第二列排序
7.什么是覆盖索引
查询的数据能在二级索引里查询的到,不需要通过主键索引查询获得,可以避免回表的操作
假设我们只需要查询商品的名称、价格,有什么方式可以避免回表呢?
我们可以建立一个联合索引,即「商品ID、名称、价格」作为一个联合索引。如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。
8.如何查看某条 SQL 语句是否⽤到了索引?[待完善]
在这个查询前加上 EXPLAIN 来查看执行计划:
EXPLAIN SELECT * FROM my_table WHERE column_name = 'value';
这将会返回一个执行计划,其中包含了MySQL执行这个查询时使用的索引信息。如果在 Extra 列中看到 Using index 或者 Using where; Using index,那么表示查询使用了索引。如果没有使用索引,可能会看到 Using where 或者 Using filesort 等