目录
前言:
MQ可靠性:
数据持久化:
Lazy Queue:
消费者可靠性:
消费者确认机制:
消费失败处理:
MQ保证幂等性:
方法一:
总结:
前言:
在上一篇文章中,我们介绍了如何确保生产者的可靠性,确保消息一定可以到达MQ。
【从零开始学习RabbitMQ | 第一篇】如何确保生产者的可靠性-CSDN博客![]() https://liyuanxin.blog.csdn.net/article/details/139261125?spm=1001.2014.3001.5502
https://liyuanxin.blog.csdn.net/article/details/139261125?spm=1001.2014.3001.5502
但是MQ自己也是会丢失消息的,比如MQ的突然宕机或者消息过多造成的阻塞,因此我们这篇文章来介绍一下如何确保MQ的可靠性和消费者可靠性

默认情况下,RabbitMQ会把接收到的消息保存在内存中来降低消息收发的延迟,但这样会导致两个问题:
- 一旦MQ宕机,内存中的消息会丢失
- 内存空间有限,当消费者故障或者处理过慢的时候,会导致消息的积压,引发阻塞。
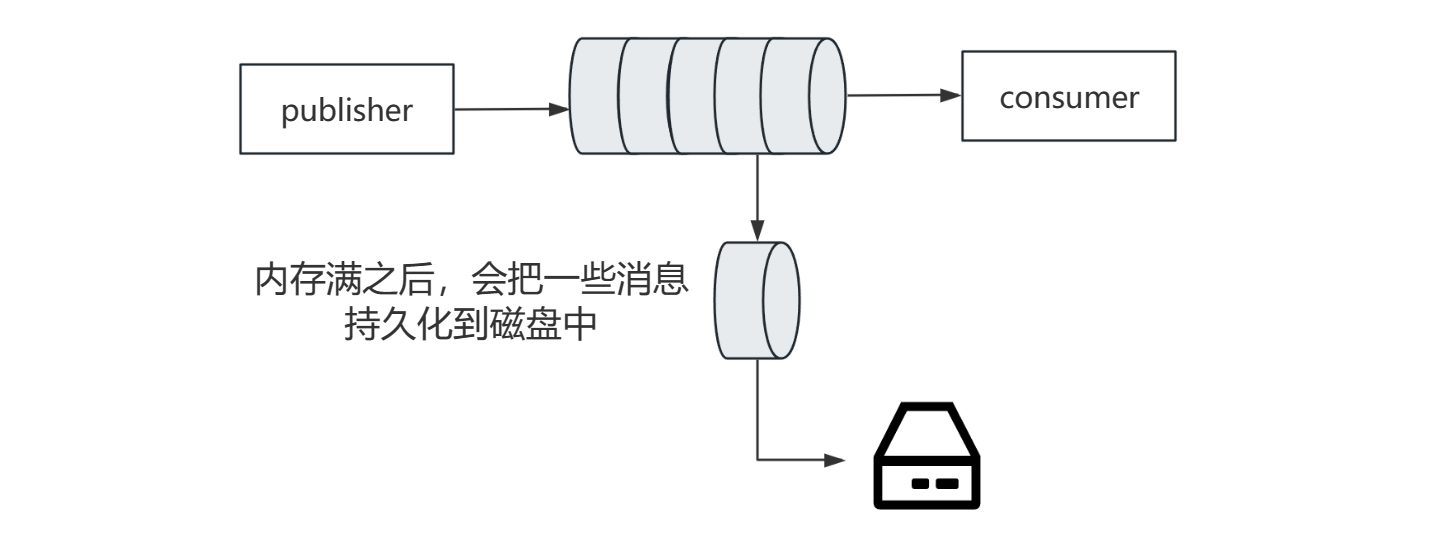
想要保证MQ的可靠性,主要依赖于两种方式:
- 数据持久化
- Lazy Queue
MQ可靠性:
数据持久化:
RabbitMQ实现持久化主要有三个部分:
-
持久化队列(Durable Queues): 持久化队列指的是队列本身被存储在磁盘上,这样即使RabbitMQ服务器重启,队列也不会丢失。要创建持久化队列,需要在声明队列时设置
durable属性为true。持久化队列中的消息默认不是持久化的,需要单独设置每条消息为持久化。 -
持久化消息(Persistent Messages): 持久化消息意味着消息本身被存储在磁盘上,因此即使RabbitMQ服务器重启,消息也不会丢失。在发送消息时,需要设置消息的
deliveryMode属性为2(即PERSISTENT),这样RabbitMQ就会将消息存储到磁盘上。 -
持久化交换机(Durable Exchanges): 持久化交换器与持久化队列类似,指的是交换器被存储在磁盘上,这样服务器重启后交换器依然存在。声明交换器时,也需要设置
durable属性为true。持久化交换器确保了消息路由的结构在服务器重启后能够保留。
当我们把消息持久化到磁盘中的时候,就避免了消息挤压造成的阻塞。但是当我们把消息持久化到磁盘中的时候,这个时候是不能接收新的消息的。
Lazy Queue:
因此实际上把消息持久化到磁盘中不是一个很好的解决方案,在RabbitMQ的3.6.0版本后,增加了Lazy Queue这个概念。其实就是懒惰队列:
懒惰队列的特性如下:
- 接收到消息后直接存入磁盘而不是内存(内存只保留最近的消息,默认2048条)。
- 消费者要消费消息的时候才会从磁盘中读取并加载到内存中。
- 支持数百万条的消息存储。
在3.12版本后,所有的队列都是Lazy Queue模式,无法更改。
消费者可靠性:
消费者确认机制:
为了确认消费者是否成功处理消息,RabbitMQ提供了消费者确认机制(Consumer Acknowledgement)。当消费者处理消息的结束之后,将会向RabbitMQ发送一个回执,告知自己消息的处理状态 ,消费者一共可以向Rabbitmq回执三种处理状态,分别是:
- ACK:成功处理消息,RabbitMQ从队列中删除该消息
- NACK:消息处理失败,RabbitMQ再次投递消息
- REJECT: 消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
而消费者确认机制并不用我们手写,Spring AMQP已经为我们实现了消费者消息确认机制,并允许我们通过配置文件的形式选择ACK处理方式,有三种:
- none:不处理,消息投递给消费者之后就会ack,消息会从MQ中删除,不安全
- manual:手动模式。需要自己调用api发送ack或者reject。
- auto:托管给Spring AMQP 利用 AOP实现消费者确认机制。当业务正常执行的时候返回ack
当业务异常的时候,根据异常不同返回不同的结果:
- 如果是业务异常,自动返回nack
- 如果是消息处理或者校验异常,自动返回reject

Spring AMQP的消费者确认机制默认开启auto。
消费失败处理:
如果我们把消费者确认机制配置为auto的时候,当消费者出现异常之后,消息会不断的重新入队到队列,再重新发送给消费者。同样的消息再次引发异常,再次入队,再次发送给消费者。
这样会导致MQ的消息处理数量飙升,带来不必要的压力,因此除了把处理失败的消息重新进行处理之外,我们还应该有其他的处理方案。
我们可以利用Spring 的retry机制,在消费者出现异常的时候使用本地重试,而不是无限制的requeue到MQ队列中。
listener:
simple:
prefetch: 1
retry:
enabled: true #开启超时重试机制
initial-interval: 1000ms #失败后的初始等待时间
multiplier: 1 #失败后下次等待时长倍数,下次等待时长= Initial - interval * multiplier
max-attempts: 3 #最大重试次数
stateless: true #true无状态,false有状态,如果业务中包含事务,就改为fasle当我们开启重试模式之后,如果重试次数耗尽并且消息依然失败,那么就需要有MessageRecoverer接口来处理,这个接口包含三种不同的实现:
- RejectAndDontRequeueRecoverer :重试耗尽之后,直接reject,丢弃消息。
- ImmedIateRequeueMessageRecoverer : 重试耗尽之后,返回nack,消息重新入队
- RepublishMessageRecoerer:重试耗尽之后,将失败消息投递到指定的交换机
如果消息丢失不会对业务产生重大影响,可以选择RejectAndDontRequeueRecoverer。
如果希望消息有机会被重新处理,可以选择ImmediateRequeueMessageRecoverer。
而RepublishMessageRecoverer则适用于需要对失败消息进行进一步分析或记录的情况。
MQ保证幂等性:
通过上述的各种保证措施,我们基本上可以确保业务至少被执行一次。那对于一些需要保证幂等性的业务,我们要如何保证这个消息只被消费一次呢?
【从零开始学习重要知识点 | 第一篇】快速了解什么是幂等性以及常见解决方案_幂等性问题如何解决分布式锁-CSDN博客![]() https://blog.csdn.net/fckbb/article/details/136331113?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171689607216777224421340%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=171689607216777224421340&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-136331113-null-null.142%5Ev100%5Epc_search_result_base1&utm_term=%E5%B9%82%E7%AD%89%E6%80%A7%20%E6%88%91%E6%98%AF%E4%B8%80%E7%9B%98%E7%89%9B%E8%82%89&spm=1018.2226.3001.4187
https://blog.csdn.net/fckbb/article/details/136331113?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171689607216777224421340%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=171689607216777224421340&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-136331113-null-null.142%5Ev100%5Epc_search_result_base1&utm_term=%E5%B9%82%E7%AD%89%E6%80%A7%20%E6%88%91%E6%98%AF%E4%B8%80%E7%9B%98%E7%89%9B%E8%82%89&spm=1018.2226.3001.4187
方法一:
给每一个消息都设置一个唯一ID,用ID区分是否被消费过。当我们消费一个消息的时候,先在数据库中查询是否存在这个数据的ID,如果不存在就消费。如果存在就说明这个消息之前被消费过。

其实他和我们上面黏贴的文章中介绍的token机制的思想很像。而在MQ中也不需要我们手动去设置唯一ID,可以在消费者的消息转换器中开启:

我们可以看一看这个setCreateMessageIds这个方法中是如何构造id的:
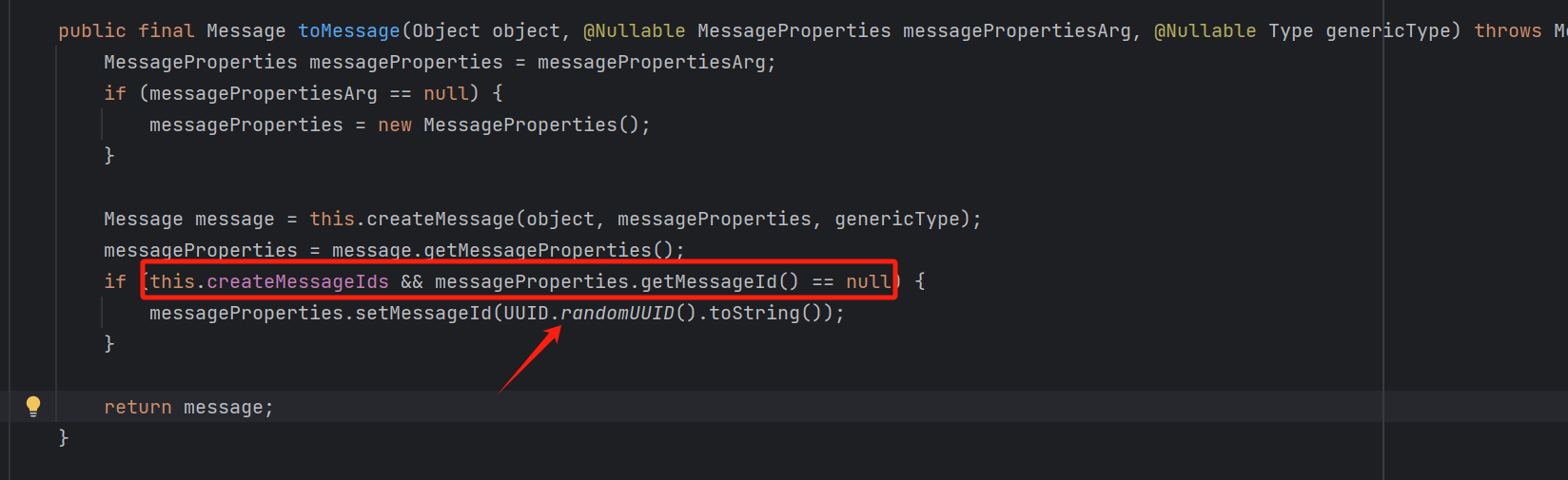
这里逻辑就很清晰了,实际上就是在发消息的时候做一个if判断,如果我们设置了构造id,并且当前消息配置类的id为空,我们就为这个消息构造一个id。
但是这种方法也有自己的缺点,也就是对业务逻辑有侵入性,而且还有额外的数据库操作。
总结:
在本文中,我们探讨了RabbitMQ作为领先的开源消息代理,如何通过一系列高级特性和策略来确保消息队列和消费者的高度可靠性。
首先,我们讨论了RabbitMQ的持久化机制,它允许消息和队列在服务器重启后依然保持不变。通过将消息标记为持久化,并在队列上启用持久化选项,我们可以确保关键数据不会因系统故障而丢失。
最后,我们介绍了消息确认机制,这是确保消息被成功处理的关键。消费者在处理完消息后发送确认回执,RabbitMQ只有在收到确认后才会从队列中移除消息。如果消费者在处理过程中失败,未确认的消息将重新入队,供其他消费者处理。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!