目录
1、列存储的定义
1、默认创建列存表
3、指定创建列存表
4、指定创建列存行存冗余表
5、行、列存储查询测试
1、列存储的定义
- 行存储(Row-based Storage):行存储是以行为单位进行组织和存储数据。在这一模式下,数据库将一条记录的所有字段作为一个整体存储在一起,即每一行数据的所有信息连续存放。这种结构类似于我们在表格中看到的数据布局,每一行代表一个实体的完整信息。行式存储常见于传统的关系型数据库管理系统(RDBMS),如MySQL、Oracle、SQL Server等,它适合需要经常进行整行读写操作的场景,如事务处理系统(OLTP)。
- 列存储(Column-based Storage): 列存储则是以列为单位进行组织和存储数据。在这种模式下,数据库将表中同一列的所有数据放在一起存储,不同列的数据分开存放。这意味着,每一列的数据在物理上是连续的,而属于同一行的不同列数据则可能分布在不同的位置。列式存储非常适合于数据分析和数据仓库应用,因为它允许对单个或部分列进行高效的查询和压缩,仅需读取查询所涉及的列,从而大幅减少I/O操作和提升分析查询的性能。列式存储的代表有Druid、Kudu、ClickHouse等系统,它们在大数据分析和在线分析处理(OLAP)场景中表现优异。
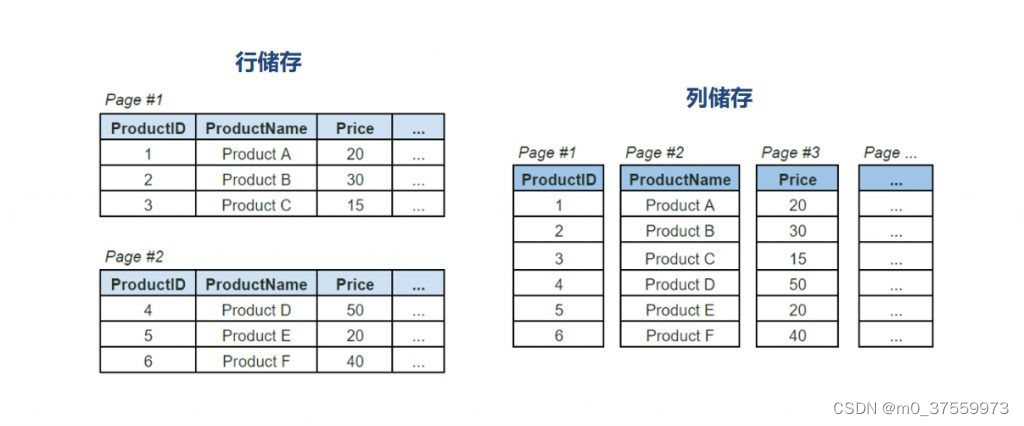
注:图片来源于网络
OceanBase 4.3 版本基于LSM-Tree 架构基础进行扩展,正式推出列存引擎,在一个架构、一个数据库上,实现了列存和行存数据存储一体化,兼顾 TP 和 AP 查询性能。
1、默认创建列存表
1) 修改表默认存储类型
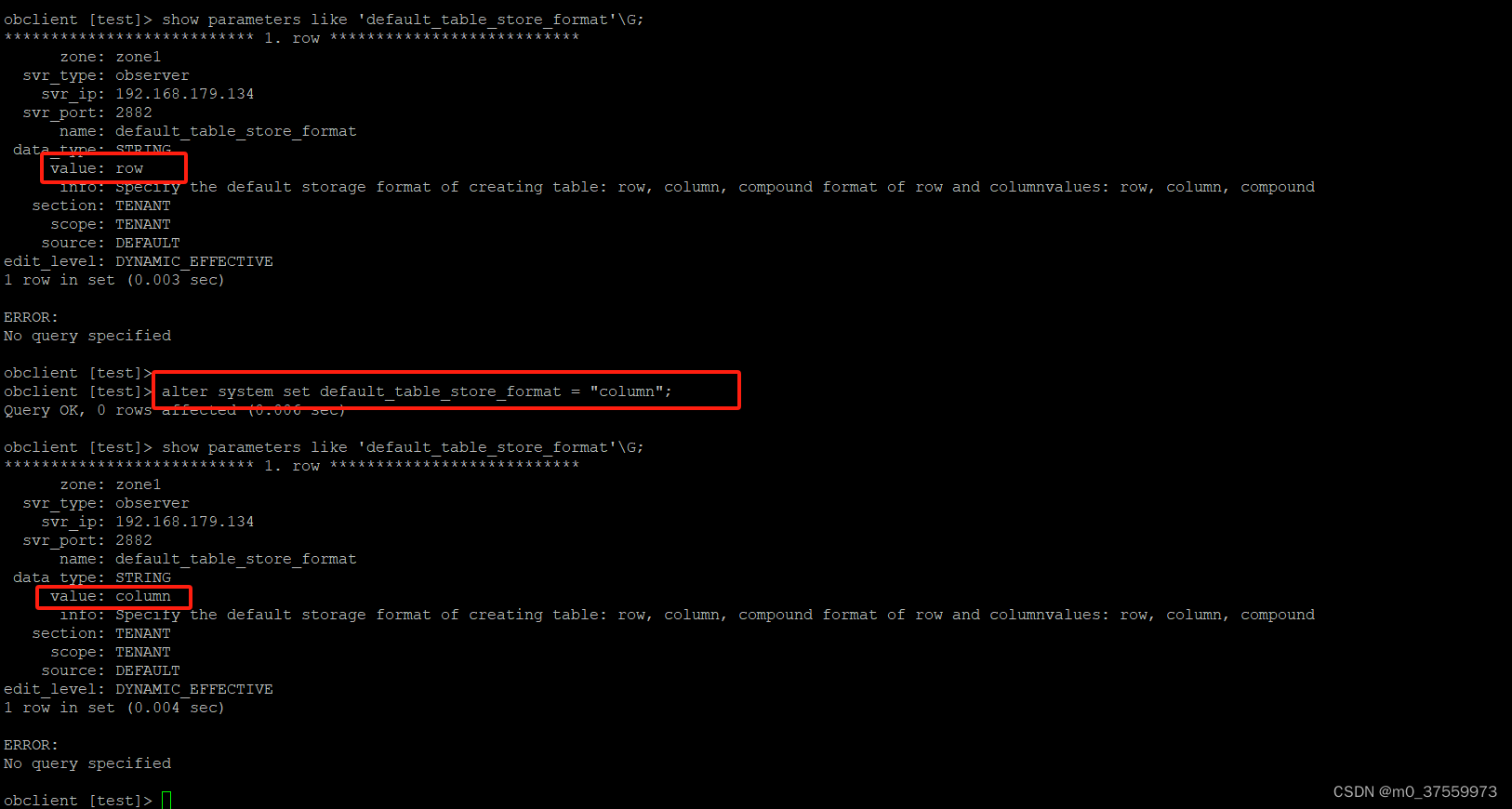
# 查看表默认存储类型
show parameters like 'default_table_store_format'\G;
# 修改表默认存储类型
alter system set default_table_store_format = "column";
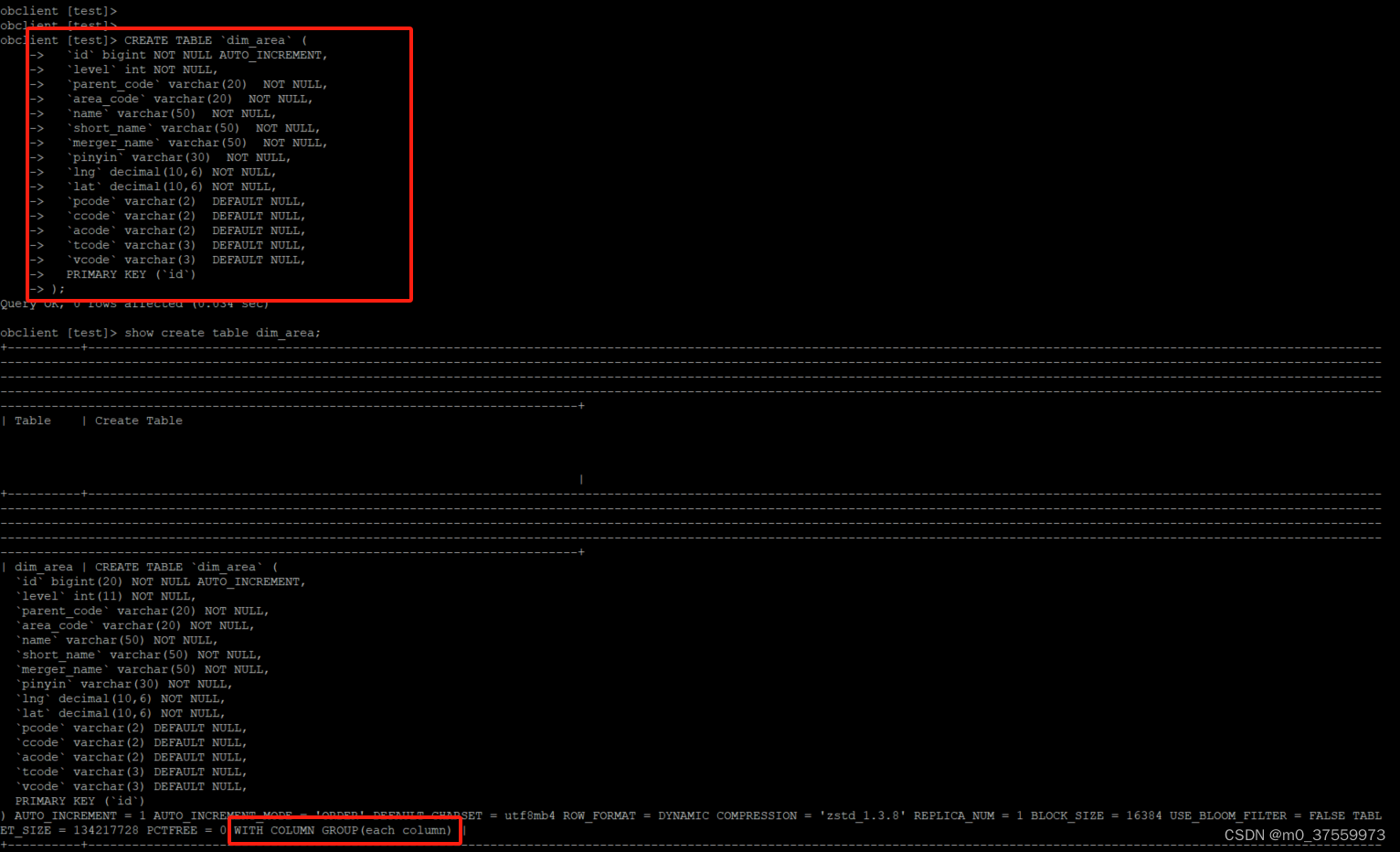
2)创建列存表
CREATE TABLE `dim_area` (
`id` bigint NOT NULL AUTO_INCREMENT,
`level` int NOT NULL,
`parent_code` varchar(20) NOT NULL,
`area_code` varchar(20) NOT NULL,
`name` varchar(50) NOT NULL,
`short_name` varchar(50) NOT NULL,
`merger_name` varchar(50) NOT NULL,
`pinyin` varchar(30) NOT NULL,
`lng` decimal(10,6) NOT NULL,
`lat` decimal(10,6) NOT NULL,
`pcode` varchar(2) DEFAULT NULL,
`ccode` varchar(2) DEFAULT NULL,
`acode` varchar(2) DEFAULT NULL,
`tcode` varchar(3) DEFAULT NULL,
`vcode` varchar(3) DEFAULT NULL,
PRIMARY KEY (`id`)
);
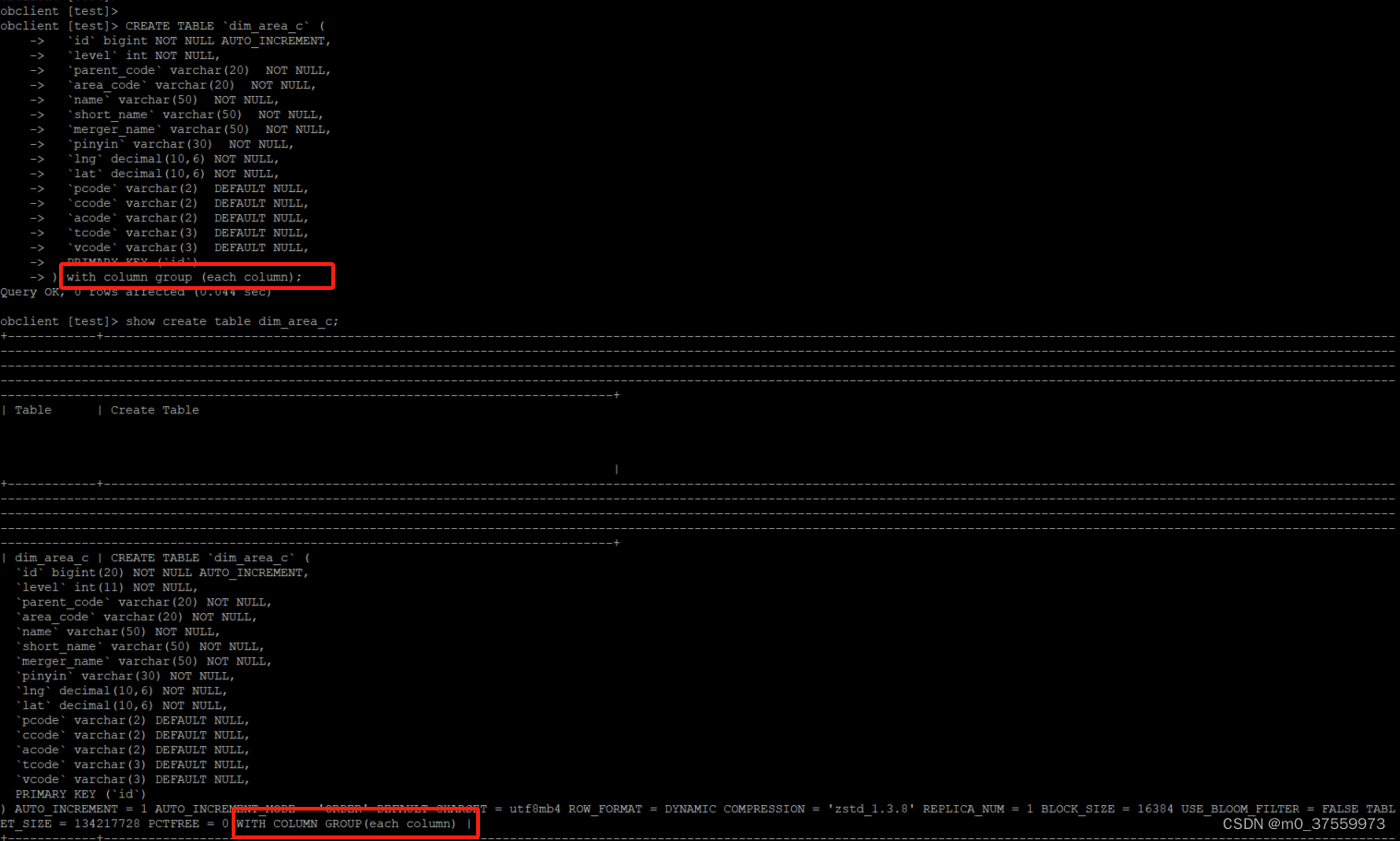
3、指定创建列存表
通过with column group 指定创建列存表:
CREATE TABLE `dim_area_c` (
`id` bigint NOT NULL AUTO_INCREMENT,
`level` int NOT NULL,
`parent_code` varchar(20) NOT NULL,
`area_code` varchar(20) NOT NULL,
`name` varchar(50) NOT NULL,
`short_name` varchar(50) NOT NULL,
`merger_name` varchar(50) NOT NULL,
`pinyin` varchar(30) NOT NULL,
`lng` decimal(10,6) NOT NULL,
`lat` decimal(10,6) NOT NULL,
`pcode` varchar(2) DEFAULT NULL,
`ccode` varchar(2) DEFAULT NULL,
`acode` varchar(2) DEFAULT NULL,
`tcode` varchar(3) DEFAULT NULL,
`vcode` varchar(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) with column group (each column);
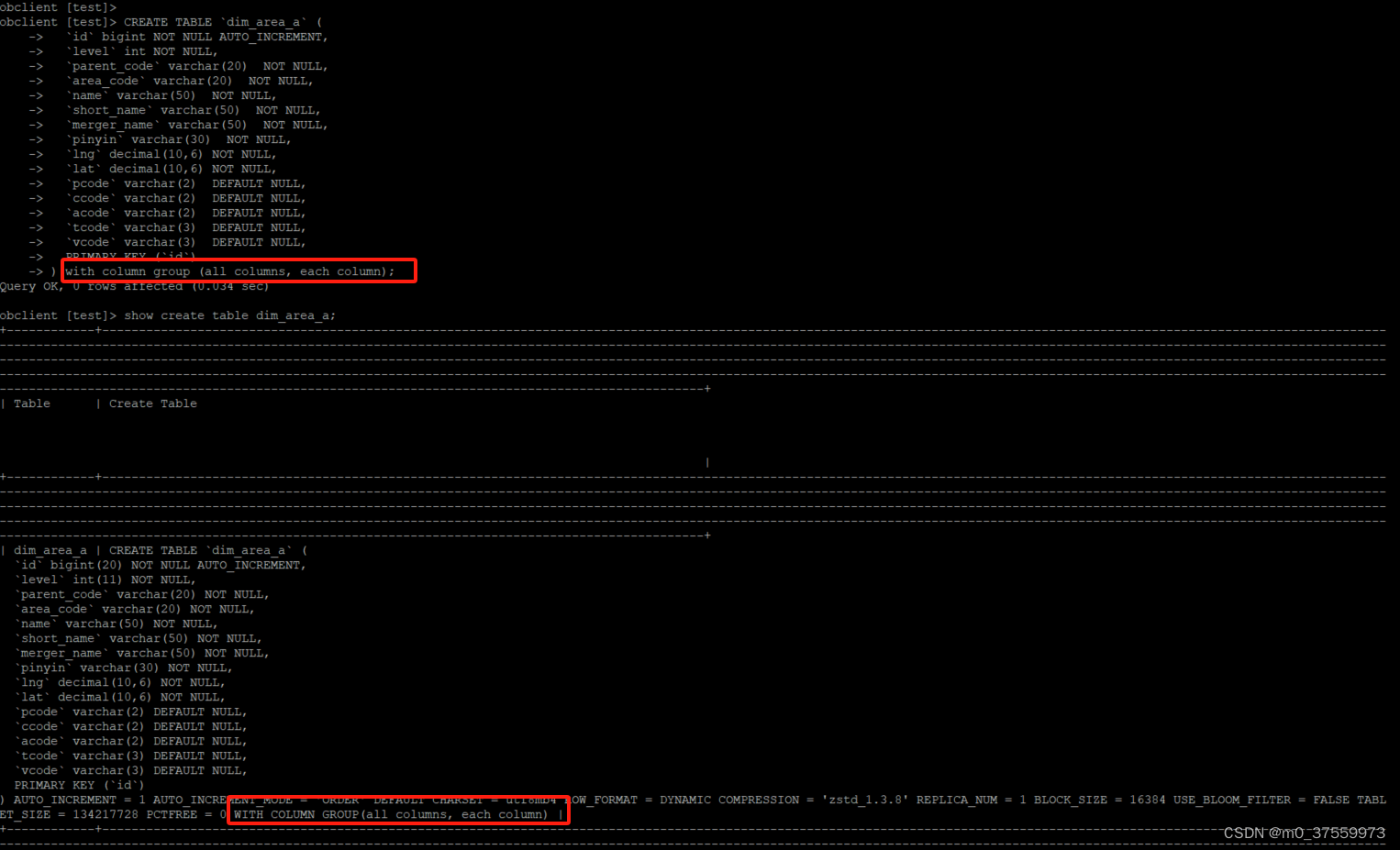
4、指定创建列存行存冗余表
在某些场景下,用户可以容忍一定程度的数据冗余,以满足 AP/TP 业务场景的双重需求。此时,可以增加行存数据的冗余,通过 `with column group` 语法增加指定 `all columns` 即可实现。
CREATE TABLE `dim_area_a` (
`id` bigint NOT NULL AUTO_INCREMENT,
`level` int NOT NULL,
`parent_code` varchar(20) NOT NULL,
`area_code` varchar(20) NOT NULL,
`name` varchar(50) NOT NULL,
`short_name` varchar(50) NOT NULL,
`merger_name` varchar(50) NOT NULL,
`pinyin` varchar(30) NOT NULL,
`lng` decimal(10,6) NOT NULL,
`lat` decimal(10,6) NOT NULL,
`pcode` varchar(2) DEFAULT NULL,
`ccode` varchar(2) DEFAULT NULL,
`acode` varchar(2) DEFAULT NULL,
`tcode` varchar(3) DEFAULT NULL,
`vcode` varchar(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) with column group (all columns, each column);
5、行、列存储查询测试
测试环境采用单机部署,同一个数据库中建两个相同结构的表,一个是行存储,一个是列存储,两个表的数据也是一样的,所有资源配置都是一样的,测试查询结果如下:
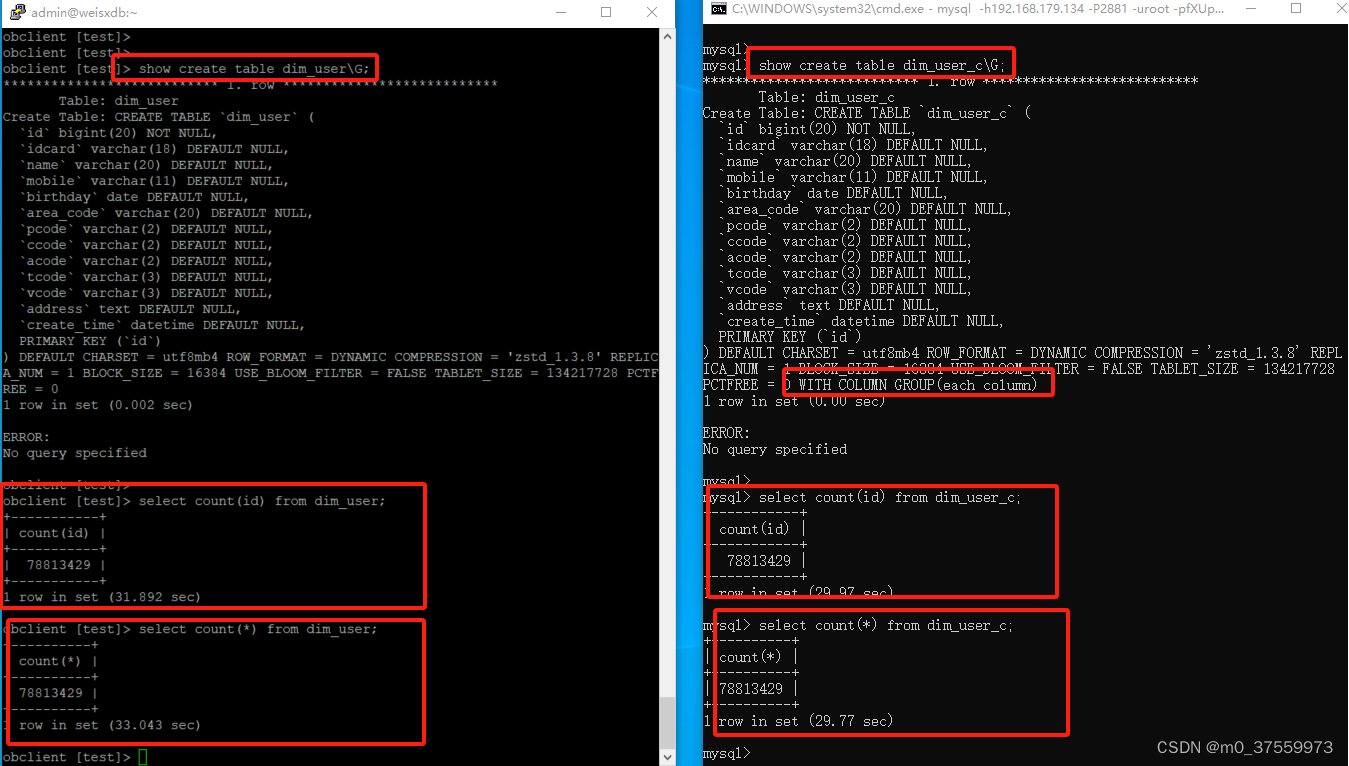
1)统计总记录数
#行存储
select count(id) from dim_user;
#列存储
select count(id) from dim_user_c;
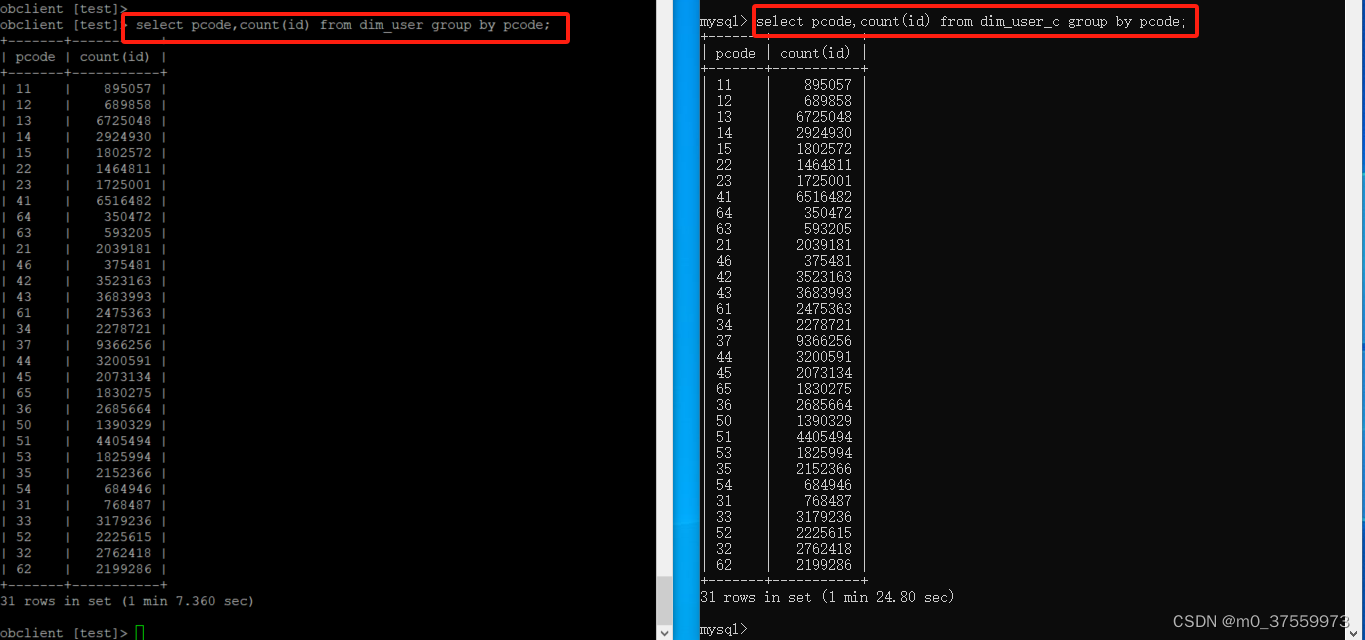
2)分组统计记录数
#行存储
select pcode,count(id) from dim_user group by pcode;
#列存储
select pcode,count(id) from dim_user_c group by pcode;







![[Linux]磁盘管理](https://img-blog.csdnimg.cn/direct/ad983f9944f041d0bd98ecbcb8ef146f.png)