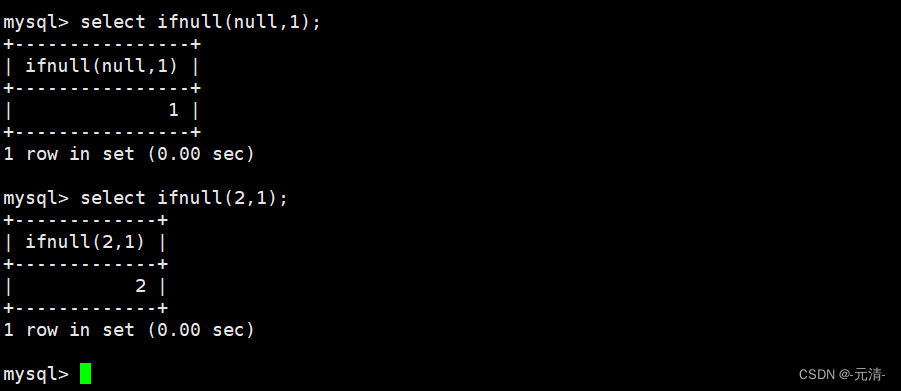
1.motivation
早期传统方法首先抽取实体再抽取它们之间的关系,但是忽略了两个任务之间的关联。而后期采取的联合模型都存在着一个严重问题:训练时,真实值作为上下文传入训练;推理时,模型自身生成的值作为上下文传入;造成训练和推理存在偏差。
2.method
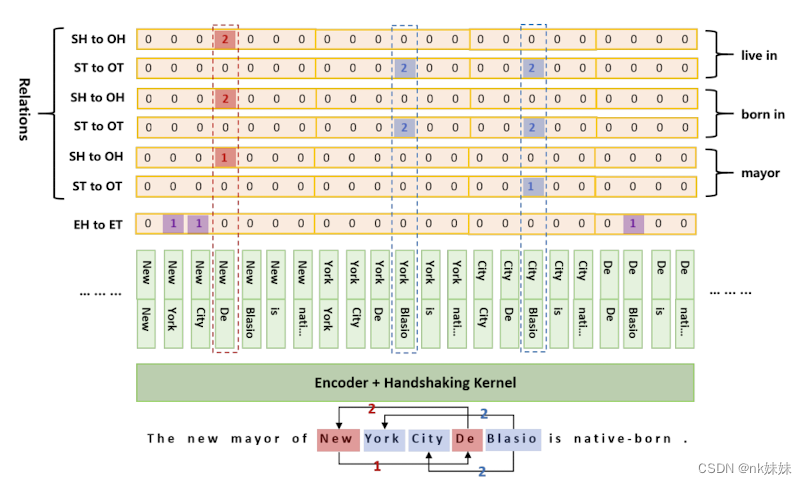
给定一段文本,两个位置p1、p2和一个关系r,模型要回答三个问题:p1和p2是否分别是同一实体的开始和结束位置、p1和p2分别是具有关系r的两个实体的起始位置、p1和p2是否分别是具有r关系的两个实体的结束位置。
模型为每个关系创建了三个矩阵来回答这三个问题,这三个矩阵被用来解码不同的标注结果。模型不包括相互依赖的提取步骤,从而避免了再训练时对真实值的依赖。
定义了三种标记方式:实体头到实体尾EH-ET(紫色标记)、主体实体头到客体实体头SH-OH(橙色标记)、主体实体尾到客体实体尾ST-OT(蓝色标记)。由于实体头不可能出现在实体尾后面,因此下三角区域后产生浪费,但是主体有概率出现在客体后,下三角会存在一些有用信息。如图右侧所示,将下三角区域映射到上三角。
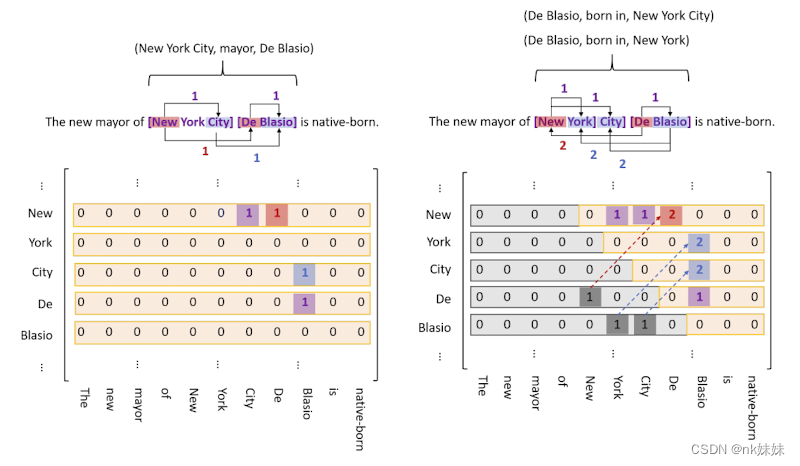
为了张量的计算,将矩阵展平成一个序列如下图所示。联合抽取任务被定义为2n+1个序列(n表示预定义的关系数目),每个序列长度为(m*m+m)/2 (m表示句子的长度 序列长度即上三角元素的个数)。
3.train
首先将一个句子通过tokenizer分为不同的token向量(w1,w2,…,wn),然后再进行编码(h1,h2,…,hn)(猜测hi的维度是预先定义关系的个数),之后对于生成每个token对(wi,wj)的向量表示:
hij = tanh(W*[hi,hj] + b)
利用统一的框架对EH-ET、SH-OH、ST-OT三个序列进行标记后,两个实体之间的关系通过以下两个公式来预测。
Pij = softmax(W*hij + b)
link(wi,wj) = arg maxP(yij = l)