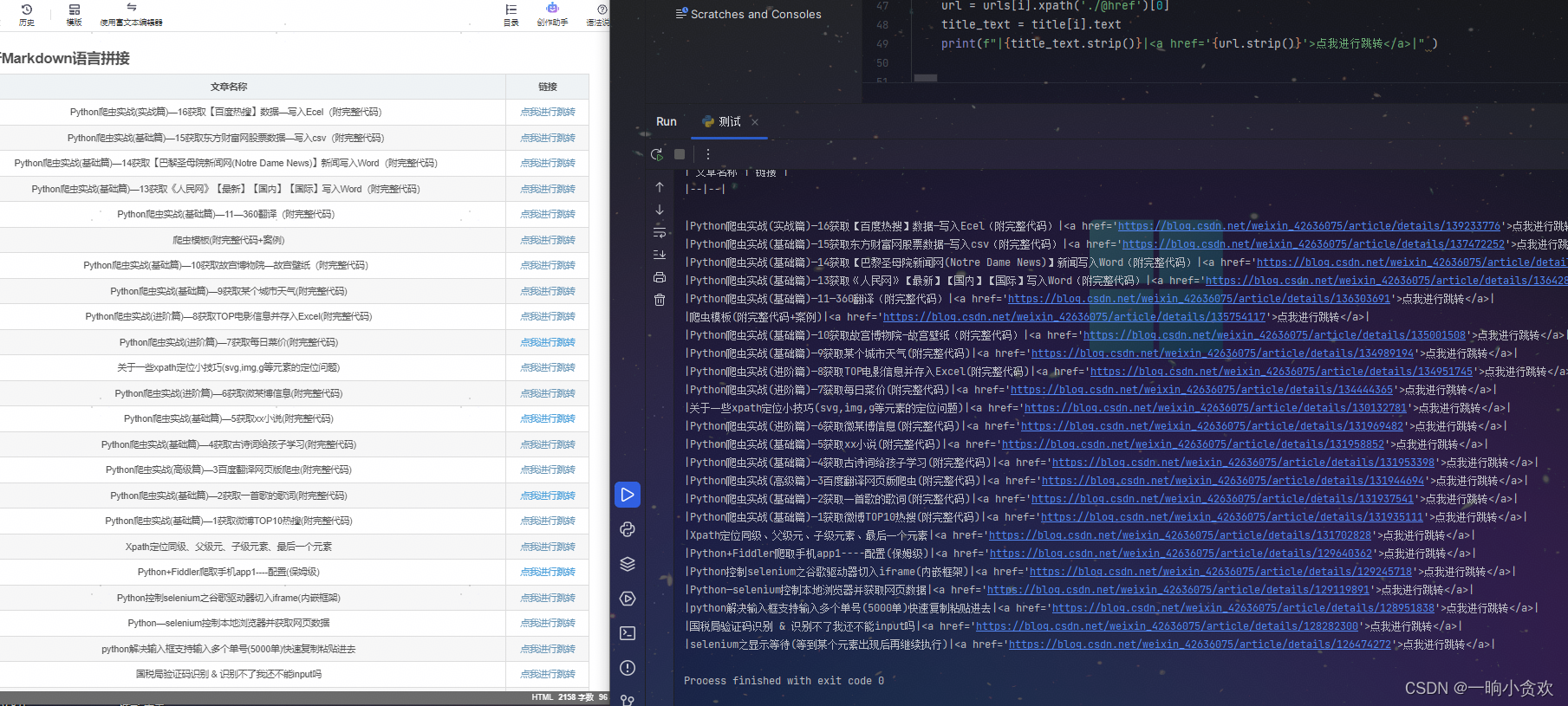
数据集简介
两个数据集
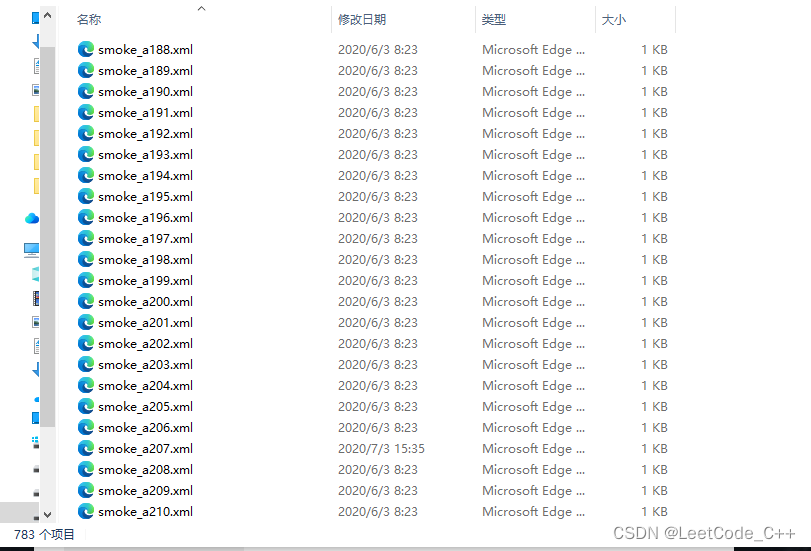
一个是783张图片+对应的xml文件
一个是2482张图片+对应的xml文件
如下图所示:
部分代码:
# 测试数据读取
def test_data_loader(datadir, batch_size= 10, test_image_size=608, mode='test'):
"""
加载测试用的图片,测试数据没有groundtruth标签
"""
image_names = os.listdir(datadir)
def reader():
batch_data = []
img_size = test_image_size
for image_name in image_names:
file_path = os.path.join(datadir, image_name)
img = cv2.imread(file_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
H = img.shape[0]
W = img.shape[1]
img = cv2.resize(img, (img_size, img_size))
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape((1, 1, -1))
std = np.array(std).reshape((1, 1, -1))
out_img = (img / 255.0 - mean) / std
out_img = out_img.astype('float32').transpose((2, 0, 1))
img = out_img #np.transpose(out_img, (2,0,1))
im_shape = [H, W]
batch_data.append((image_name.split('.')[0], img, im_shape))
if len(batch_data) == batch_size:
yield make_test_array(batch_data)
batch_data = []
if len(batch_data) > 0:
yield make_test_array(batch_data)
return reader# 读取数据
import paddle
reader = paddle.io.DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=1, drop_last=True)
img, gt_boxes, gt_labels, im_shape = next(reader())
img, gt_boxes, gt_labels, im_shape = img.numpy(), gt_boxes.numpy(), gt_labels.numpy(), im_shape.numpy()
# 计算出锚框对应的标签
label_objectness, label_location, label_classification, scale_location = get_objectness_label(img,
gt_boxes, gt_labels,
iou_threshold = 0.7,
anchors = [116, 90, 156, 198, 373, 326],
num_classes=7, downsample=32)